
- 1黑猴子的家:Redis 持久化 之 RDB_dump.rdb.bak
- 2重要一个设置 adb connect 由于目标计算机积极拒绝,无法连接。 (10061)_雷电模拟器 adb 连接 由于目标计算机积极拒绝,无法连接。 (10061)
- 3【ICML 2020】REALM: Retrieval-Augmented Language Model PreTraining
- 4「最新版」SpringBoot3.2.0官方教程实践01-构建一个RESTful Web服务_spring boot 3.2.0
- 5区块链和人工智能的关系以及经典案例_区块链和ai的关系
- 6通信算法之四十六:OFDM系统波形设计_shi算法 ofdm
- 7最新最详细的Python开发环境搭建以及PyCharm的安装配置教程【图+文】_pycharm最后的rebootnow
- 8Leetcode- 使字符串平衡的最小交换次数
- 9Vivado 3-8译码器 4-16译码器_4输入十六进制显示译码器vivado
- 10爬虫练习:Selenium使用案例
Squeeze-and-Excitation Networks论文翻译——中文版_squeeze-exictation ops
赞
踩
文章作者:Tyan
博客:noahsnail.com | CSDN | 简书
声明:作者翻译论文仅为学习,如有侵权请联系作者删除博文,谢谢!
翻译论文汇总:https://github.com/SnailTyan/deep-learning-papers-translation
Squeeze-and-Excitation Networks
摘要
卷积神经网络建立在卷积运算的基础上,通过融合局部感受野内的空间信息和通道信息来提取信息特征。为了提高网络的表示能力,许多现有的工作已经显示出增强空间编码的好处。在这项工作中,我们专注于通道,并提出了一种新颖的架构单元,我们称之为“Squeeze-and-Excitation”(SE)块,通过显式地建模通道之间的相互依赖关系,自适应地重新校准通道式的特征响应。通过将这些块堆叠在一起,我们证明了我们可以构建SENet架构,在具有挑战性的数据集中可以进行泛化地非常好。关键的是,我们发现SE块以微小的计算成本为现有的最先进的深层架构产生了显著的性能改进。SENets是我们ILSVRC 2017分类提交的基础,它赢得了第一名,并将top-5错误率显著减少到
1. 引言
卷积神经网络(CNNs)已被证明是解决各种视觉任务的有效模型[19,23,29,41]。对于每个卷积层,沿着输入通道学习一组滤波器来表达局部空间连接模式。换句话说,期望卷积滤波器通过融合空间信息和信道信息进行信息组合,而受限于局部感受野。通过叠加一系列非线性和下采样交织的卷积层,CNN能够捕获具有全局感受野的分层模式作为强大的图像描述。最近的工作已经证明,网络的性能可以通过显式地嵌入学习机制来改善,这种学习机制有助于捕捉空间相关性而不需要额外的监督。Inception架构推广了一种这样的方法[14,39],这表明网络可以通过在其模块中嵌入多尺度处理来取得有竞争力的准确度。最近的工作在寻找更好地模型空间依赖[1,27],结合空间注意力[17]。
与这些方法相反,通过引入新的架构单元,我们称之为“Squeeze-and-Excitation” (SE)块,我们研究了架构设计的一个不同方向——通道关系。我们的目标是通过显式地建模卷积特征通道之间的相互依赖性来提高网络的表示能力。为了达到这个目的,我们提出了一种机制,使网络能够执行特征重新校准,通过这种机制可以学习使用全局信息来选择性地强调信息特征并抑制不太有用的特征。
SE构建块的基本结构如图1所示。对于任何给定的变换
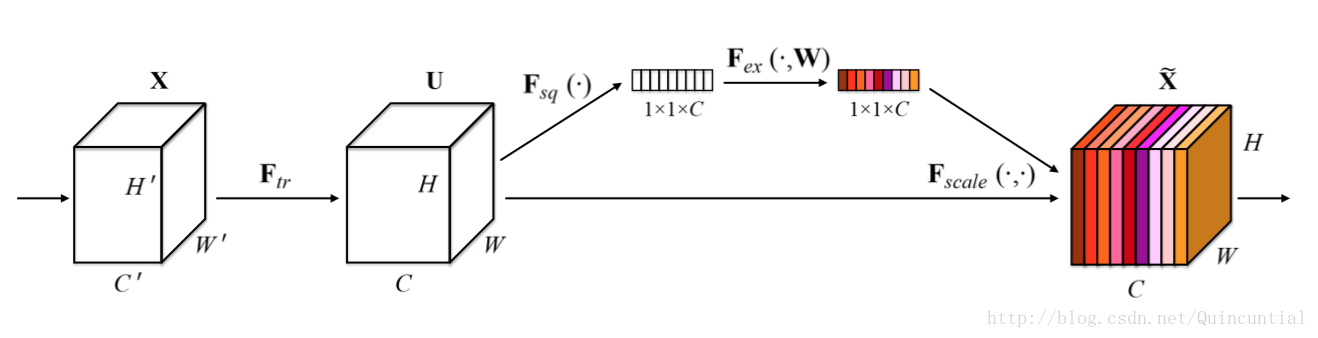
图1. Squeeze-and-Excitation块
SE网络可以通过简单地堆叠SE构建块的集合来生成。SE块也可以用作架构中任意深度的原始块的直接替换。然而,虽然构建块的模板是通用的,正如我们6.3节中展示的那样,但它在不同深度的作用适应于网络的需求。在前面的层中,它学习以类不可知的方式激发信息特征,增强共享的较低层表示的质量。在后面的层中,SE块越来越专业化,并以高度类特定的方式响应不同的输入。因此,SE块进行特征重新校准的好处可以通过整个网络进行累积。
新CNN架构的开发是一项具有挑战性的工程任务,通常涉及许多新的超参数和层配置的选择。相比之下,上面概述的SE块的设计是简单的,并且可以直接与现有的最新架构一起使用,其卷积层可以通过直接用对应的SE层来替换从而进行加强。另外,如第四节所示,SE块在计算上是轻量级的,并且在模型复杂性和计算负担方面仅稍微增加。为了支持这些声明,我们开发了一些SENets,即SE-ResNet,SE-Inception,SE-ResNeXt和SE-Inception-ResNet,并在ImageNet 2012数据集[30]上对SENets进行了广泛的评估。此外,为了证明SE块的一般适用性,我们还呈现了ImageNet之外的结果,表明所提出的方法不受限于特定的数据集或任务。
使用SENets,我们赢得了ILSVRC 2017分类竞赛的第一名。我们的表现最好的模型集合在测试集上达到了top-5错误率。与前一年的获奖者(top-5错误率)相比,这表示
2. 近期工作
深层架构。大量的工作已经表明,以易于学习深度特征的方式重构卷积神经网络的架构可以大大提高性能。VGGNets[35]和Inception模型[39]证明了深度增加可以获得的好处,明显超过了ILSVRC 2014之前的方法。批标准化(BN)[14]通过插入单元来调节层输入稳定学习过程,改善了通过深度网络的梯度传播,这使得可以用更深的深度进行进一步的实验。He等人[9,10]表明,通过重构架构来训练更深层次的网络是有效的,通过使用基于恒等映射的跳跃连接来学习残差函数,从而减少跨单元的信息流动。最近,网络层间连接的重新表示[5,12]已被证明可以进一步改善深度网络的学习和表征属性。
另一种研究方法探索了调整网络模块化组件功能形式的方法。可以用分组卷积来增加基数(一组变换的大小)[13,43]以学习更丰富的表示。多分支卷积可以解释为这个概念的概括,使得卷积算子可以更灵活的组合[14,38,39,40]。跨通道相关性通常被映射为新的特征组合,或者独立的空间结构[6,18],或者联合使用标准卷积滤波器[22]和
注意力和门机制。从广义上讲,可以将注意力视为一种工具,将可用处理资源的分配偏向于输入信号的信息最丰富的组成部分。这种机制的发展和理解一直是神经科学社区的一个长期研究领域[15,16,28],并且近年来作为一个强大补充,已经引起了深度神经网络的极大兴趣[20,25]。注意力已经被证明可以改善一系列任务的性能,从图像的定位和理解[3,17]到基于序列的模型[2,24]。它通常结合门功能(例如softmax或sigmoid)和序列技术来实现[11,37]。最近的研究表明,它适用于像图像标题[4,44]和口头阅读[7]等任务,其中利用它来有效地汇集多模态数据。在这些应用中,它通常用在表示较高级别抽象的一个或多个层的顶部,以用于模态之间的适应。高速网络[36]采用门机制来调节快捷连接,使得可以学习非常深的架构。王等人[42]受到语义分割成功的启发,引入了一个使用沙漏模块[27]的强大的trunk-and-mask注意力机制。这个高容量的单元被插入到中间阶段之间的深度残差网络中。相比之下,我们提出的SE块是一个轻量级的门机制,专门用于以计算有效的方式对通道关系进行建模,并设计用于增强整个网络中模块的表示能力。
3. Squeeze-and-Excitation块
Squeeze-and-Excitation块是一个计算单元,可以为任何给定的变换构建:
3.1. Squeeze:全局信息嵌入
为了解决利用通道依赖性的问题,我们首先考虑输出特征中每个通道的信号。每个学习到的滤波器都对局部感受野进行操作,因此变换输出
讨论。转换输出
3.2. Excitation:自适应重新校正
为了利用压缩操作中汇聚的信息,我们接下来通过第二个操作来全面捕获通道依赖性。为了实现这个目标,这个功能必须符合两个标准:第一,它必须是灵活的(特别是它必须能够学习通道之间的非线性交互);第二,它必须学习一个非互斥的关系,因为独热激活相反,这里允许强调多个通道。为了满足这些标准,我们选择采用一个简单的门机制,并使用sigmoid激活:
讨论。激活作为适应特定输入描述符
3.3. 模型:SE-Inception和SE-ResNet
SE块的灵活性意味着它可以直接应用于标准卷积之外的变换。为了说明这一点,我们通过将SE块集成到两个流行的网络架构系列Inception和ResNet中来开发SENets。通过将变换
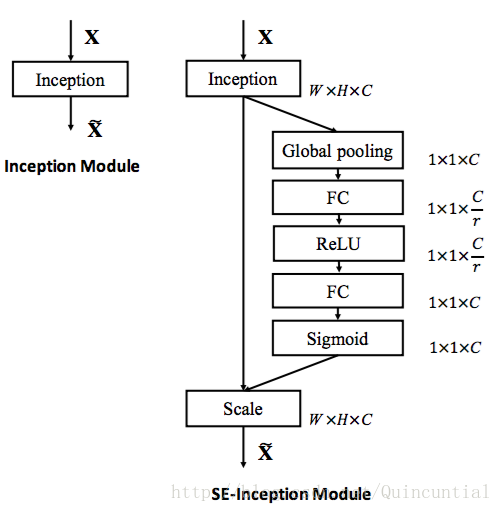
图2。最初的Inception模块架构(左)和SE-Inception模块(右)。
残留网络及其变种已经证明在学习深度表示方面非常有效。我们开发了一系列的SE块,分别与ResNet[9],ResNeXt[43]和Inception-ResNet[38]集成。图3描述了SE-ResNet模块的架构。在这里,SE块变换
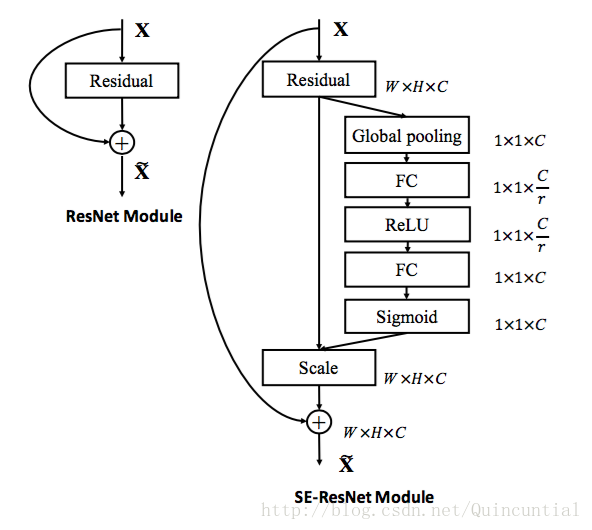
图3。 最初的Residual模块架构(左)和SE-ResNet模块架构(右)。
4. 模型和计算复杂度
SENet通过堆叠一组SE块来构建。实际上,它是通过用原始块的SE对应部分(即SE残差块)替换每个原始块(即残差块)而产生的。我们在表1中描述了SE-ResNet-50和SE-ResNeXt-50的架构。
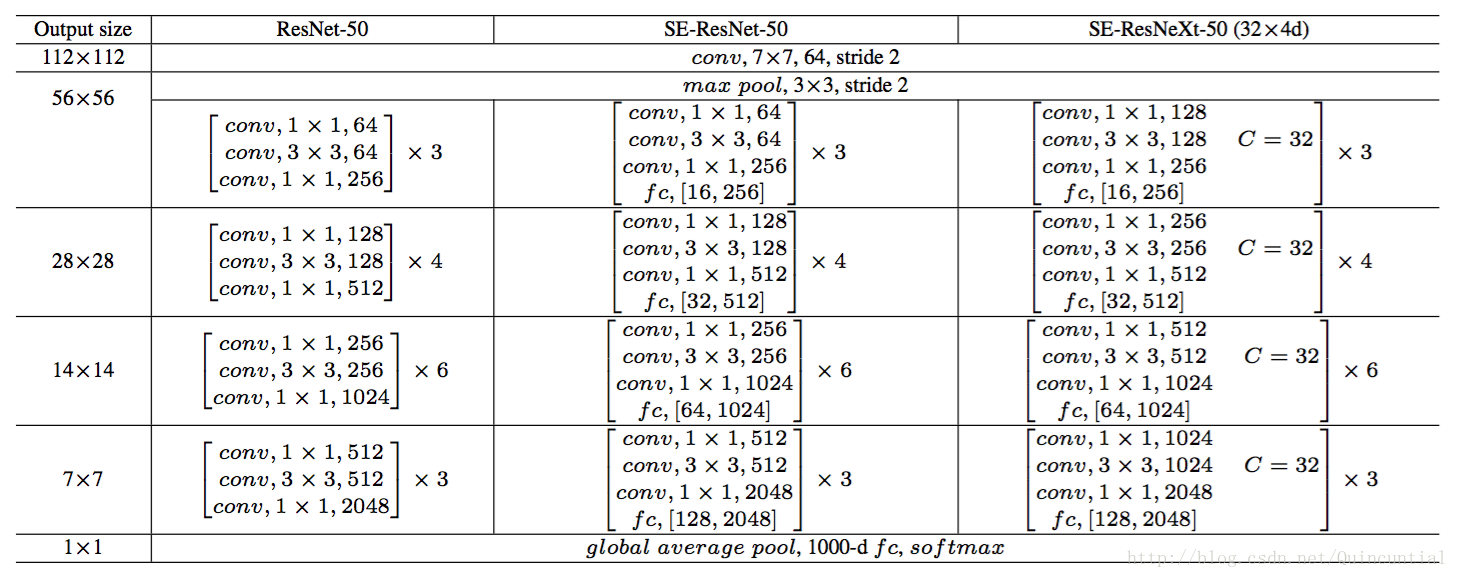
表1。(左)ResNet-50,(中)SE-ResNet-50,(右)具有
在实践中提出的SE块是可行的,它必须提供可接受的模型复杂度和计算开销,这对于可伸缩性是重要的。为了说明模块的成本,作为例子我们比较了ResNet-50和SE-ResNet-50,其中SE-ResNet-50的精确度明显优于ResNet-50,接近更深的ResNet-101网络(如表2所示)。对于
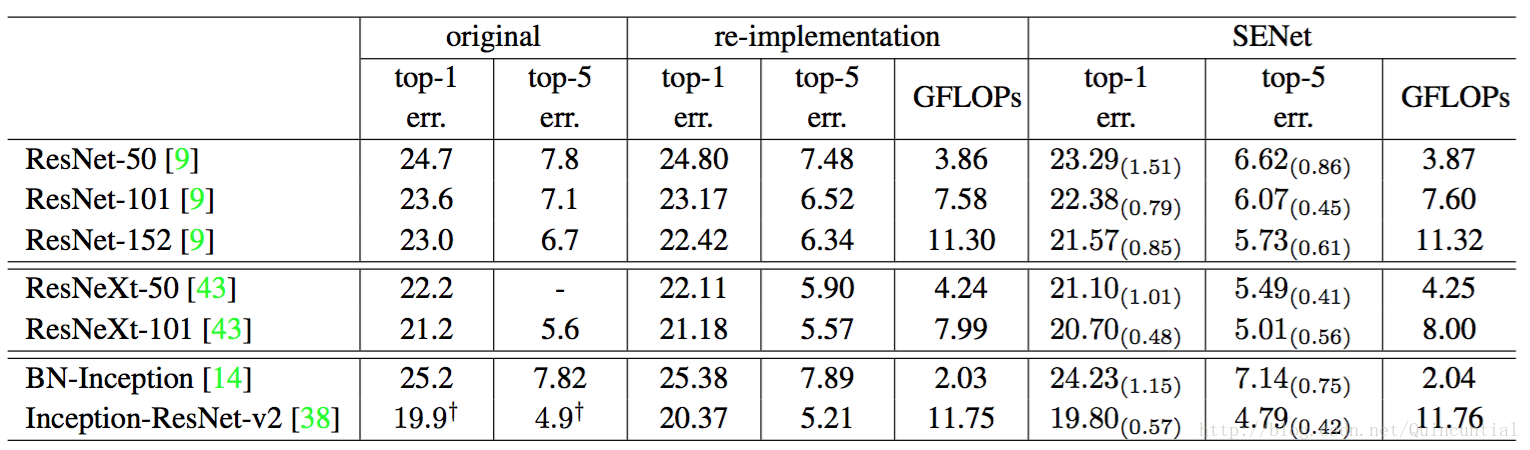
表2。ImageNet验证集上的单裁剪图像错误率(%)和复杂度比较。original列是指原始论文中报告的结果。为了进行公平比较,我们重新训练了基准模型,并在re-implementation列中报告分数。SENet列是指已添加SE块后对应的架构。括号内的数字表示与重新实现的基准数据相比的性能改善。†表示该模型已经在验证集的非黑名单子集上进行了评估(在[38]中有更详细的讨论),这可能稍微改善结果。
在实践中,训练的批数据大小为256张图像,ResNet-50的一次前向传播和反向传播花费
接下来,我们考虑所提出的块引入的附加参数。所有附加参数都包含在门机制的两个全连接层中,构成网络总容量的一小部分。更确切地说,引入的附加参数的数量由下式给出:
5. 实现
在训练过程中,我们遵循标准的做法,使用随机大小裁剪[39]到
6. 实验
在这一部分,我们在ImageNet 2012数据集上进行了大量的实验[30],其目的是:首先探索提出的SE块对不同深度基础网络的影响;其次,调查它与最先进的网络架构集成后的能力,旨在公平比较SENets和非SENets,而不是推动性能。接下来,我们将介绍ILSVRC 2017分类任务模型的结果和详细信息。此外,我们在Places365-Challenge场景分类数据集[48]上进行了实验,以研究SENets是否能够很好地泛化到其它数据集。最后,我们研究激励的作用,并根据实验现象给出了一些分析。
6.1. ImageNet分类
ImageNet 2012数据集包含来自1000个类别的128万张训练图像和5万张验证图像。我们在训练集上训练网络,并在验证集上使用中心裁剪图像评估来报告top-1和top-5错误率,其中每张图像短边首先归一化为256,然后从每张图像中裁剪出
网络深度。我们首先将SE-ResNet与一系列标准ResNet架构进行比较。每个ResNet及其相应的SE-ResNet都使用相同的优化方案进行训练。验证集上不同网络的性能如表2所示,表明SE块在不同深度上的网络上计算复杂度极小增加,始终提高性能。
值得注意的是,SE-ResNet-50实现了单裁剪图像top-5验证错误率,超过了ResNet-50(top-5错误率),且只有ResNet-101一半的计算开销(top-5错误率)不仅可以匹配,而且超过了更深的ResNet-152网络(top-5错误率)。图4分别描绘了SE-ResNets和ResNets的训练和验证曲线。虽然应该注意SE块本身增加了深度,但是它们的计算效率极高,即使在扩展的基础架构的深度达到收益递减的点上也能产生良好的回报。而且,我们看到通过对各种不同深度的训练,性能改进是一致的,这表明SE块引起的改进可以与增加基础架构更多深度结合使用。
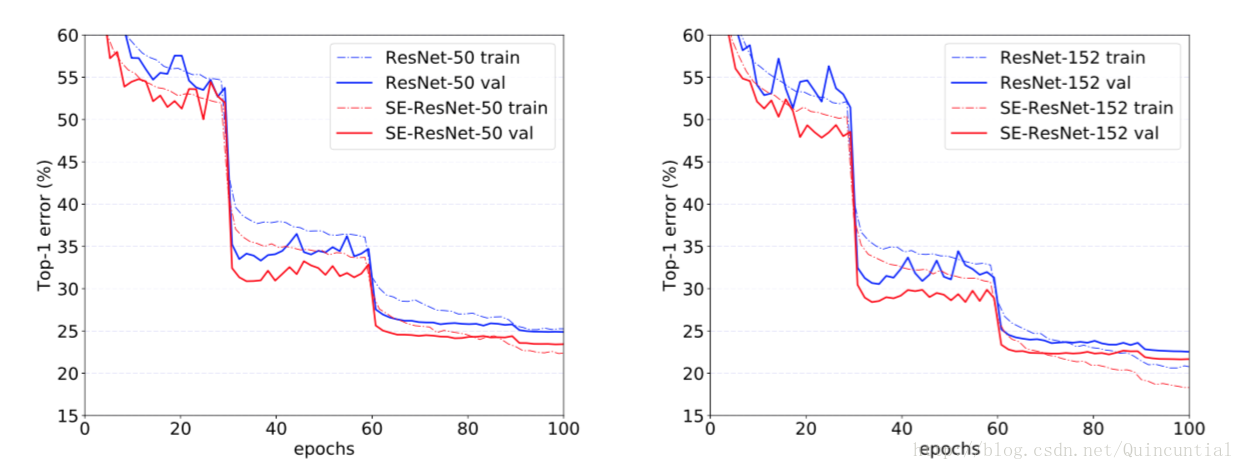
图4。ImageNet上的训练曲线。(左):ResNet-50和SE-ResNet-50;(右):ResNet-152和SE-ResNet-152。
与现代架构集成。接下来我们将研究SE块与另外两种最先进的架构Inception-ResNet-v2[38]和ResNeXt[43]的结合效果。Inception架构将卷积模块构造为分解滤波器的多分支组合,反映了Inception假设[6],可以独立映射空间相关性和跨通道相关性。相比之下,ResNeXt体架构断言,可以通过聚合稀疏连接(在通道维度中)卷积特征的组合来获得更丰富的表示。两种方法都在模块中引入了先前结构化的相关性。我们构造了这些网络的SENet等价物,SE-Inception-ResNet-v2和SE-ResNeXt(表1给出了SE-ResNeXt-50(
表2中给出的结果说明在将SE块引入到两种架构中会引起显著的性能改善。尤其是SE-ResNeXt-50的top-5错误率是top-5错误率)以及更深的ResNeXt-101(top-5错误率),这个模型几乎有两倍的参数和计算开销。对于Inception-ResNet-v2的实验,我们猜测可能是裁剪策略的差异导致了其报告结果与我们重新实现的结果之间的差距,因为它们的原始图像大小尚未在[38]中澄清,而我们从相对较大的图像(其中较短边被归一化为352)中裁剪出top-5错误率)比我们重新实现的Inception-ResNet-v2(top-5错误率)要低
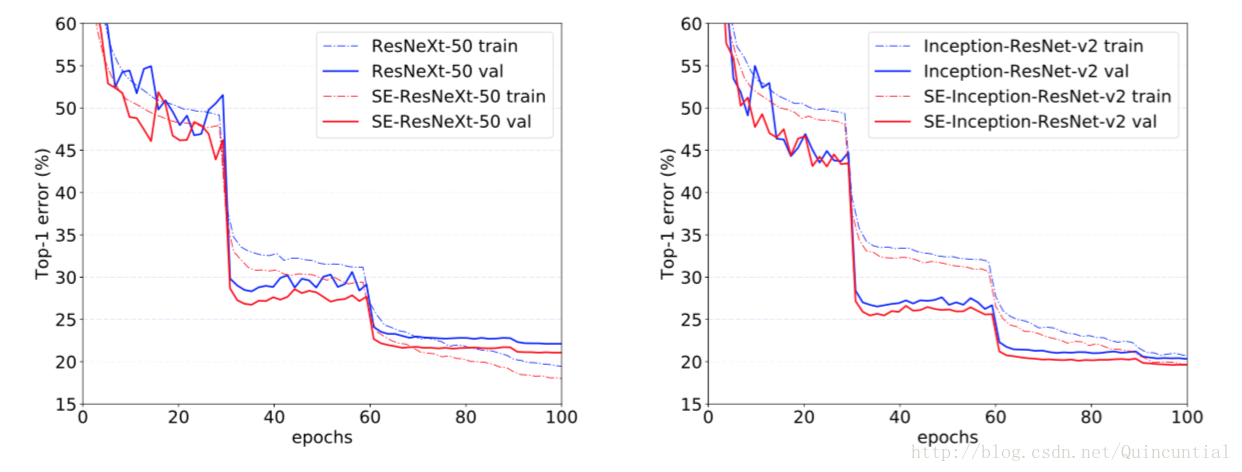
图5。ImageNet的训练曲线。(左): ResNeXt-50和SE-ResNeXt-50;(右):Inception-ResNet-v2和SE-Inception-ResNet-v2。
最后,我们通过对BN-Inception架构[14]进行实验来评估SE块在非残差网络上的效果,该架构在较低的模型复杂度下提供了良好的性能。比较结果如表2所示,训练曲线如图6所示,表现出的现象与残差架构中出现的现象一样。尤其是与BN-Inception top-5错误。这些实验表明SE块引起的改进可以与多种架构结合使用。而且,这个结果适用于残差和非残差基础。
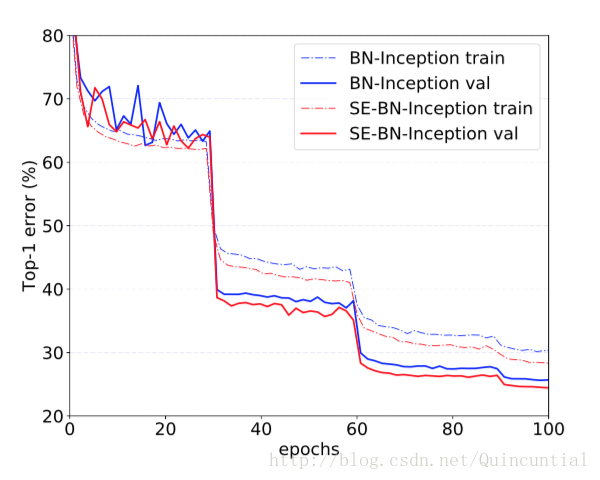
图6。BN-Inception和SE-BN-Inception在ImageNet上的训练曲线。
**ILSVRC 2017分类竞赛的结果。**ILSVRC[30]是一个年度计算机视觉竞赛,被证明是图像分类模型发展的沃土。ILSVRC 2017分类任务的训练和验证数据来自ImageNet 2012数据集,而测试集包含额外的未标记的10万张图像。为了竞争的目的,使用top-5错误率度量来对输入条目进行排序。
SENets是我们在挑战中赢得第一名的基础。我们的获胜输入由一小群SENets组成,它们采用标准的多尺度和多裁剪图像融合策略,在测试集上获得了top-5错误率。这个结果表示在2016年获胜输入(top-5错误率)的基础上相对改进了top-1错误率和top-5错误率。为了与以前的模型进行公平的比较,我们也提供了top-1(top-5(
表3。最新的CNNs在ImageNet验证集上单裁剪图像的错误率。测试的裁剪图像大小是
6.2. 场景分类
ImageNet数据集的大部分由单个对象支配的图像组成。为了在更多不同的场景下评估我们提出的模型,我们还在Places365-Challenge数据集[48]上对场景分类进行评估。该数据集包含800万张训练图像和365个类别的36500张验证图像。相对于分类,场景理解的任务可以更好地评估模型泛化和处理抽象的能力,因为它需要捕获更复杂的数据关联以及对更大程度外观变化的鲁棒性。
我们使用ResNet-152作为强大的基线来评估SE块的有效性,并遵循[33]中的评估协议。表4显示了针对给定任务训练ResNet-152模型和SE-ResNet-152的结果。具体而言,SE-ResNet-152(top-5错误率)取得了比ResNet-152(top-5错误率)更低的验证错误率,证明了SE块可以在不同的数据集上表现良好。这个SENet超过了先前的最先进的模型Places-365-CNN [33],它在这个任务上有top-5错误率。
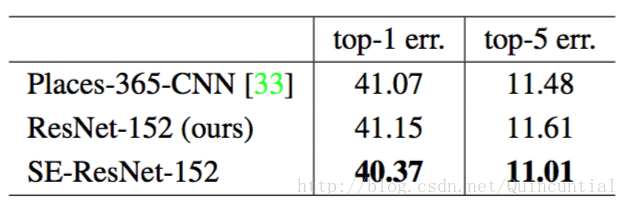
表4。Places365验证集上的单裁剪图像错误率(%)。
6.3. 分析和讨论
减少比率。公式(5)中引入的减少比率
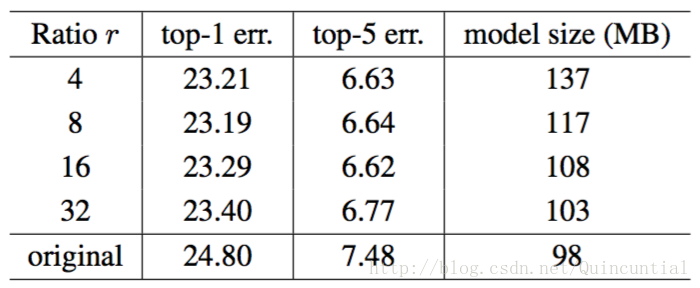
表5。 ImageNet验证集上单裁剪图像的错误率(%)和SE-ResNet-50架构在不同减少比率original指的是ResNet-50。
激励的作用。虽然SE块从经验上显示出其可以改善网络性能,但我们也想了解自门激励机制在实践中是如何运作的。为了更清楚地描述SE块的行为,本节我们研究SE-ResNet-50模型的样本激活,并考察它们在不同块不同类别下的分布情况。具体而言,我们从ImageNet数据集中抽取了四个类,这些类表现出语义和外观多样性,即金鱼,哈巴狗,刨和悬崖(图7中显示了这些类别的示例图像)。然后,我们从验证集中为每个类抽取50个样本,并计算每个阶段最后的SE块中50个均匀采样通道的平均激活(紧接在下采样之前),并在图8中绘制它们的分布。作为参考,我们也绘制所有1000个类的平均激活分布。

图7。ImageNet中四个类别的示例图像。
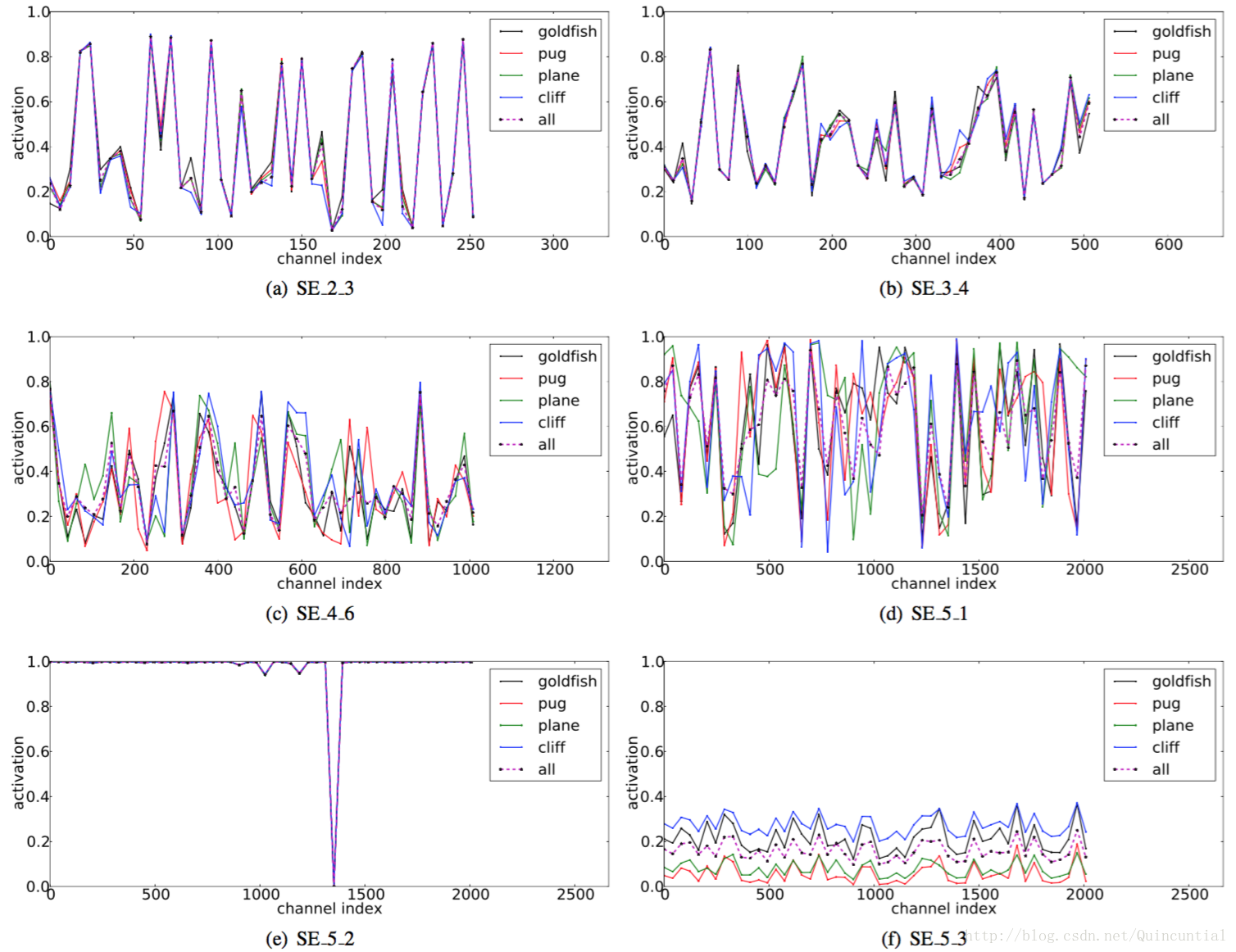
图8。SE-ResNet-50不同模块在ImageNet上由Excitation引起的激活。模块名为“SE stageID blockID”。
我们对SENets中Excitation的作用提出以下三点看法。首先,不同类别的分布在较低层中几乎相同,例如,SE_2_3。这表明在网络的最初阶段特征通道的重要性很可能由不同的类别共享。然而有趣的是,第二个观察结果是在更大的深度,每个通道的值变得更具类别特定性,因为不同类别对特征的判别性值具有不同的偏好。SE_4_6和SE_5_1。这两个观察结果与以前的研究结果一致[21,46],即低层特征通常更普遍(即分类中不可知的类别),而高层特征具有更高的特异性。因此,表示学习从SE块引起的重新校准中受益,其自适应地促进特征提取和专业化到所需要的程度。最后,我们在网络的最后阶段观察到一个有些不同的现象。SE_5_2呈现出朝向饱和状态的有趣趋势,其中大部分激活接近于1,其余激活接近于0。在所有激活值取1的点处,该块将成为标准残差块。在网络的末端SE_5_3中(在分类器之前紧接着是全局池化),类似的模式出现在不同的类别上,尺度上只有轻微的变化(可以通过分类器来调整)。这表明,SE_5_2和SE_5_3在为网络提供重新校准方面比前面的块更不重要。这一发现与第四节实证研究的结果是一致的,这表明,通过删除最后一个阶段的SE块,总体参数数量可以显著减少,性能只有一点损失(<top-1错误率)。
7. 结论
在本文中,我们提出了SE块,这是一种新颖的架构单元,旨在通过使网络能够执行动态通道特征重新校准来提高网络的表示能力。大量实验证明了SENets的有效性,其在多个数据集上取得了最先进的性能。此外,它们还提供了一些关于以前架构在建模通道特征依赖性上的局限性的洞察,我们希望可能证明SENets对其它需要强判别性特征的任务是有用的。最后,由SE块引起的特征重要性可能有助于相关领域,例如为了压缩的网络修剪。
致谢。我们要感谢Andrew Zisserman教授的有益评论,并感谢Samuel Albanie的讨论并校订论文。我们要感谢Chao Li在训练系统内存优化方面的贡献。Li Shen由国家情报总监(ODNI),先期研究计划中心(IARPA)资助,合同号为2014-14071600010。本文包含的观点和结论属于作者的观点和结论,不应理解为ODNI,IARPA或美国政府明示或暗示的官方政策或认可。尽管有任何版权注释,美国政府有权为政府目的复制和分发重印。
References
[1] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, 2016.
[2] T. Bluche. Joint line segmentation and transcription for end-to-end handwritten paragraph recognition. In NIPS, 2016.
[3] C.Cao, X.Liu, Y.Yang, Y.Yu, J.Wang, Z.Wang, Y.Huang, L. Wang, C. Huang, W. Xu, D. Ramanan, and T. S. Huang. Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks. In ICCV, 2015.
[4] L. Chen, H. Zhang, J. Xiao, L. Nie, J. Shao, W. Liu, and T. Chua. SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning. In CVPR, 2017.
[5] Y. Chen, J. Li, H. Xiao, X. Jin, S. Yan, and J. Feng. Dual path networks. arXiv:1707.01629, 2017.
[6] F. Chollet. Xception: Deep learning with depthwise separable convolutions. In CVPR, 2017.
[7] J. S. Chung, A. Senior, O. Vinyals, and A. Zisserman. Lip reading sentences in the wild. In CVPR, 2017.
[8] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In ICCV, 2015.
[9] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016.
[10] K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In ECCV, 2016.
[11] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural computation, 1997.
[12] G. Huang, Z. Liu, K. Q. Weinberger, and L. Maaten. Densely connected convolutional networks. In CVPR, 2017.
[13] Y. Ioannou, D. Robertson, R. Cipolla, and A. Criminisi. Deep roots: Improving CNN efficiency with hierarchical filter groups. In CVPR, 2017.
[14] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
[15] L. Itti and C. Koch. Computational modelling of visual attention. Nature reviews neuroscience, 2001.
[16] L. Itti, C. Koch, and E. Niebur. A model of saliency-based visual attention for rapid scene analysis. IEEE TPAMI, 1998.
[17] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. In NIPS, 2015.
[18] M. Jaderberg, A. Vedaldi, and A. Zisserman. Speeding up convolutional neural networks with low rank expansions. In BMVC, 2014.
[19] A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012.
[20] H. Larochelle and G. E. Hinton. Learning to combine foveal glimpses with a third-order boltzmann machine. In NIPS, 2010.
[21] H. Lee, R. Grosse, R. Ranganath, and A. Y. Ng. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In ICML, 2009.
[22] M. Lin, Q. Chen, and S. Yan. Network in network. arXiv:1312.4400, 2013.
[23] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
[24] A. Miech, I. Laptev, and J. Sivic. Learnable pooling with context gating for video classification. arXiv:1706.06905, 2017.
[25] V. Mnih, N. Heess, A. Graves, and K. Kavukcuoglu. Recurrent models of visual attention. In NIPS, 2014.
[26] V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In ICML, 2010.
[27] A. Newell, K. Yang, and J. Deng. Stacked hourglass networks for human pose estimation. In ECCV, 2016.
[28] B. A. Olshausen, C. H. Anderson, and D. C. V. Essen. A neurobiological model of visual attention and invariant pattern recognition based on dynamic routing of information. Journal of Neuroscience, 1993.
[29] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015.
[30] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet large scale visual recognition challenge. IJCV, 2015.
[31] J. Sanchez, F. Perronnin, T. Mensink, and J. Verbeek. Image classification with the fisher vector: Theory and practice. RR-8209, INRIA, 2013.
[32] L. Shen, Z. Lin, and Q. Huang. Relay backpropagation for effective learning of deep convolutional neural networks. In ECCV, 2016.
[33] L. Shen, Z. Lin, G. Sun, and J. Hu. Places401 and places365 models. https://github.com/lishen-shirley/ Places2-CNNs, 2016.
[34] L. Shen, G. Sun, Q. Huang, S. Wang, Z. Lin, and E. Wu. Multi-level discriminative dictionary learning with application to large scale image classification. IEEE TIP, 2015.
[35] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
[36] R. K. Srivastava, K. Greff, and J. Schmidhuber. Training very deep networks. In NIPS, 2015.
[37] M. F. Stollenga, J. Masci, F. Gomez, and J. Schmidhuber. Deep networks with internal selective attention through feedback connections. In NIPS, 2014.
[38] C.Szegedy, S.Ioffe, V.Vanhoucke, and A.Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv:1602.07261, 2016.
[39] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In CVPR, 2015.
[40] C.Szegedy, V.Vanhoucke, S.Ioffe, J.Shlens, and Z.Wojna. Rethinking the inception architecture for computer vision. In CVPR, 2016.
[41] A. Toshev and C. Szegedy. DeepPose: Human pose estimation via deep neural networks. In CVPR, 2014.
[42] F. Wang, M. Jiang, C. Qian, S. Yang, C. Li, H. Zhang, X. Wang, and X. Tang. Residual attention network for image classification. In CVPR, 2017.
[43] S. Xie, R. Girshick, P. Dollar, Z. Tu, and K. He. Aggregated residual transformations for deep neural networks. In CVPR, 2017.
[44] K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio. Show, attend and tell: Neural image caption generation with visual attention. In ICML, 2015.
[45] J. Yang, K. Yu, Y. Gong, and T. Huang. Linear spatial pyramid matching using sparse coding for image classification. In CVPR, 2009.
[46] J. Yosinski, J. Clune, Y. Bengio, and H. Lipson. How transferable are features in deep neural networks? In NIPS, 2014.
[47] X. Zhang, Z. Li, C. C. Loy, and D. Lin. Polynet: A pursuit of structural diversity in very deep networks. In CVPR, 2017.
[48] B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba. Places: A 10 million image database for scene recognition. IEEE TPAMI, 2017.
A. ILSVRC 2017 Classification Competition Entry Details
The SENet in Table 3 is constructed by integrating SE blocks to a modified version of the
A. ILSVRC 2017分类竞赛输入细节
表3中的SENet是通过将SE块集成到


