
热门标签
热门文章
- 1Django-Docker容器化部署:Django-Docker本地部署_djiango docker部署
- 2数据挖掘入门实验(weka)_low_ temp什么意思
- 3十、多模态大语言模型(MLLM)_具身多模态语言模型r3m模型
- 4Hive之set参数大全-18_hive set插入数据量大小
- 5docker导出镜像、容器打镜像_docker 导出镜像
- 6Spark-机器学习(8)分类学习之随机森林
- 7OpenCV 之交叉编译及ARM移植(二)_opencv 交叉编译
- 8探索FastAPI-MySQL-Generator:自动化数据库模型生成器
- 9基于深度学习的图像风格迁移发展总结
- 102021-03-11 php 获取文件/上传文 是否是图片格式(与后缀无关,取文件实际内容)_--enable-exif
当前位置: article > 正文
spark高可用, yarn_yarn spark.blockmanager.port
作者:从前慢现在也慢 | 2024-05-16 23:01:51
赞
踩
yarn spark.blockmanager.port
1.配置spark-env.sh
# 配置大哥;在二哥上面,MASTER_PORT=指的是自己
SPARK_MASTER_HOST=hadoop102
# 设置zookeepr,不能换行
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop101:2181,hadoop102:2181,hadoop103:2181 -Dspark.deploy.zookeeper.dir=/spark"
# 告诉Spark,hadoop放到哪里面了,前题是每一个Spark,的服务器上都装有hadoop
HADOOP_CONF_DIR=/data/hadoop/hadoop-3.2.1/etc/hadoop/
- 1
- 2
- 3
- 4
- 5
- 6
配置二哥MASTER_PORT=指的是自己
SPARK_MASTER_HOST=hadoop101
2.配置slaves
#配置的小弟
hadoop103
hadoop104
- 1
- 2
- 3
3.启动
- 启动zookeeper
bin/zkServer.sh
- 1
- 启动hadoop
sbin/start-all.sh
- 1
- 启动spark
sbin/start-all.sh
- 1
停止spark
sbin/stop-all.sh
- 1
注意查看spark的web端的时候,由于启动了zookeeper,spark的端口与zookeeper的端口冲突,spark会把端口改成8081,在logs日志中会显示
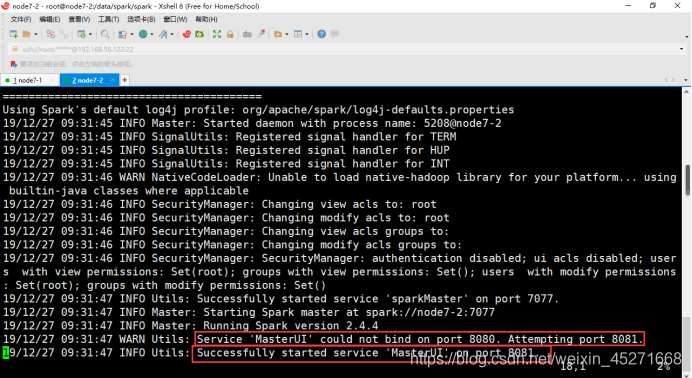
# 查看网络的状态;是zookeeper占用了8080端口
netstat -anp|grep 8080
- 1
- 2
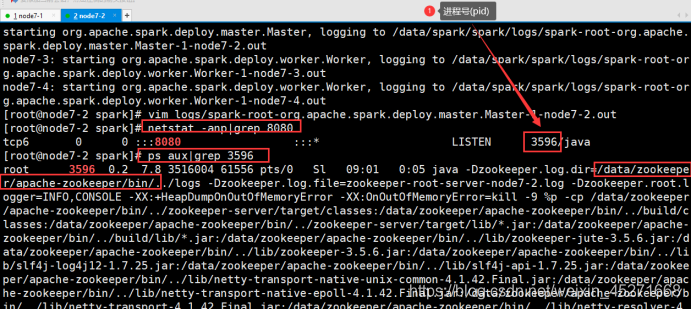
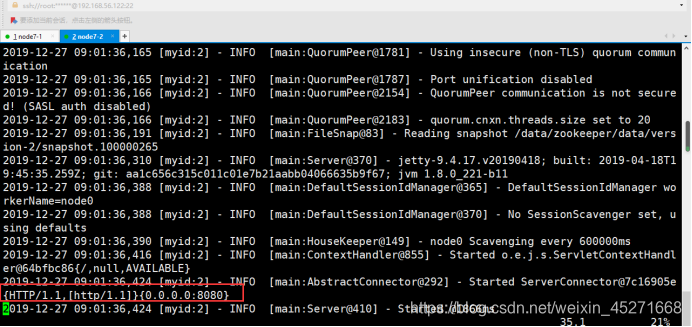
启动二哥在hadoop101上启动
sbin/start-master.sh
- 1
4.运行示例
# --master:把任务提交给大哥;
# --executor-memory:指定executor的内存;
# --executor-cores:指定executor的cpu,核心
bin/spark-submit \
--master spark://hadoop102:7077 \
--name myPi \
--executor-memory 500m \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
examples/jars/spark-examples_2.11-2.4.4.jar \
100000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
# --master:把任务提交给大哥;
# --executor-memory:指定executor的内存;(都是workder的,executor)
# --executor-cores:指定executor的cpu,核心(都是workder的,executor)
# --deploy-mode:部署模式
bin/spark-submit \
--master spark://hadoop102:7077 \
--name myPi \
--deploy-mode cluster \
--executor-memory 500m \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
examples/jars/spark-examples_2.11-2.4.4.jar \
10000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
# --driver-cores:适应于集群模式;2核
# --driver-memory:适应于集群模式;500m;
bin/spark-submit \
--master spark://hadoop102:7077 \
--name myPi \
--deploy-mode cluster \
--executor-memory 500m \
--total-executor-cores 2 \
--driver-cores 2 \
--driver-memory 500m \
--class org.apache.spark.examples.SparkPi \
examples/jars/spark-examples_2.11-2.4.4.jar \
100
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
# --master:把任务提交给大哥;
# --executor-memory:指定executor的内存;(都是workder的,executor)
# --executor-cores:指定executor的cpu,核心(都是workder的,executor)
# --deploy-mode:部署模式
bin/spark-submit \
--master yarn \
--name myPi \
--executor-memory 500m \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
examples/jars/spark-examples_2.11-2.4.4.jar \
10000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
集群提交
# --master:把任务提交给大哥;
# --executor-memory:指定executor的内存;(都是workder的,executor)
# --executor-cores:指定executor的cpu,核心(都是workder的,executor)
# --deploy-mode:部署模式
bin/spark-submit \
--master yarn \
--name myPi \
--deploy-mode cluster \
--executor-memory 500m \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
examples/jars/spark-examples_2.11-2.4.4.jar \
10000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/580811
推荐阅读
相关标签

