
- 1基于FPGA的CIC滤波器抽取内插滤波器数字上下变频多采样率信号处理_fpga 多路并行cic抽取器
- 2FPGA初学-调用IP核实现计数器_模200的二进制加法计数器ip核实现、
- 3使用 Docker 搭建 Hadoop 分布式环境_windows系统docker怎么搭建hadoop框架(1)
- 4windows安装mysql
- 5使用Python开发spark_spark python
- 6matlab 带参数二重积分,matlab 关于积分限带参数的二重积分没有数值解的问题
- 7Java连接Mysql报错:javax.net.ssl.SSLException: Received fatal alert: internal_error_at sun.reflect.generatedconstructoraccessor177.new
- 8基于springboot的校园社团活动管理系统【数据库设计、论文、毕设源码、开题报告】
- 9月薪9K!前台测试男生偷偷努力,工资翻倍转行5G网络优化工程师,“卷死”所有人!_5g网络优化测试赚钱吗
- 10Windows安装Mysql客户端_windows仅安装mysql客户端
后生可畏!中国军团称霸阅读理解竞赛RACE:微信AI称王,高中生力压腾讯康奈尔联队(附资料)...
赞
踩

本文经AI新媒体量子位(公众号ID:qbitai )授权转载,转载请联系出处
本文约4000字,建议阅读5分钟。
本文为你介绍了由CMU语言技术研究所发起RACE数据集活动中,中国军团雄霸天下的情况。
在初高中英文阅读理解这件事上,普通人类已经不是AI对手了。
这就是AI最新获得的成就。
在CMU语言技术研究所发起RACE数据集上,全球豪强纷纷一展身手。
最终,依然由中国军团雄霸天下。
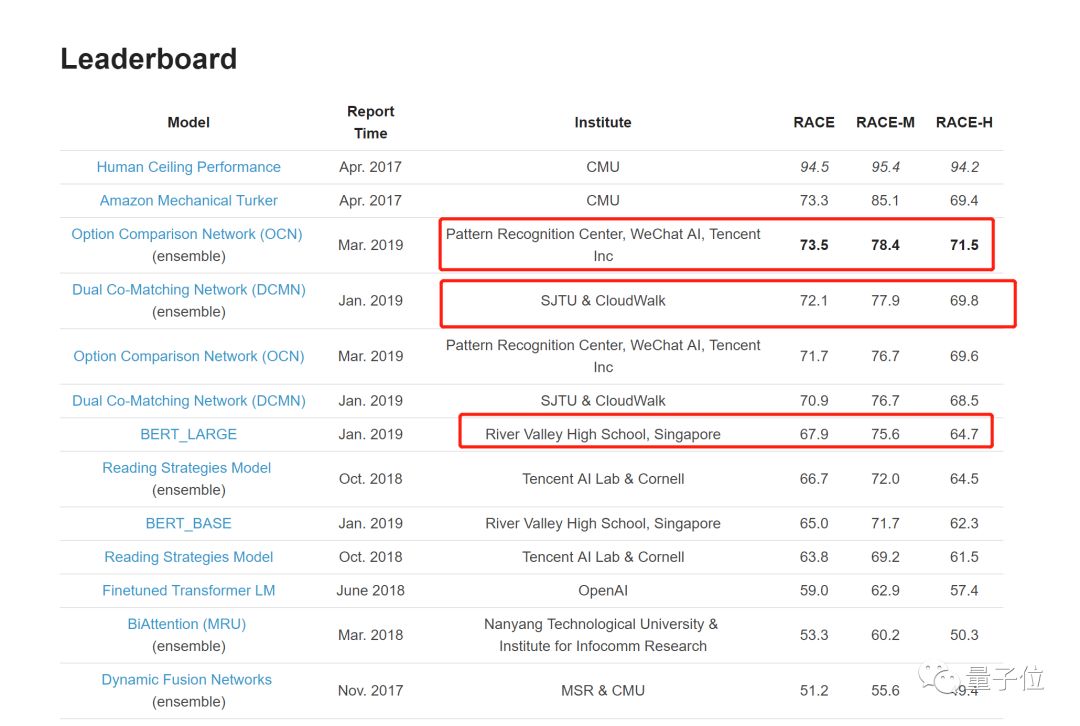
而且一位高中生,甚至单枪匹马力压腾讯和康奈尔联队。
此外,第一二名争夺也异常激烈且颇富戏剧性。
微信AI和云从交大,上演了一出生死时速的好戏。
怎样一回事?
中国AI军团雄霸全球竞赛
此次比赛所用数据集RACE,全称:Large-scale ReAding Comprehension Dataset From Examination,是一个从初中和高中试题中收集的大型英文阅读理解数据集。
2017年正式对外推出,主要考察AI模型在英文阅读理解方面的学习能力。
从推出至今,总共有13支全球豪强来试过身手。除了前面提到的微信AI、云从、腾讯AI Lab和康奈尔之外,OpenAI、微软研究院、IBM研究院也都参与其中。
但2年以来,还没有哪支团队的AI模型真正实现超越人类水平。
但就在今年1月,中国公司云从科技和上海交大联队,首次在高中生数据集部分实现了AI模型水平对人类超越,该排名也一度占据榜首50多天。
如此成绩,云从自然应该庆祝一番。
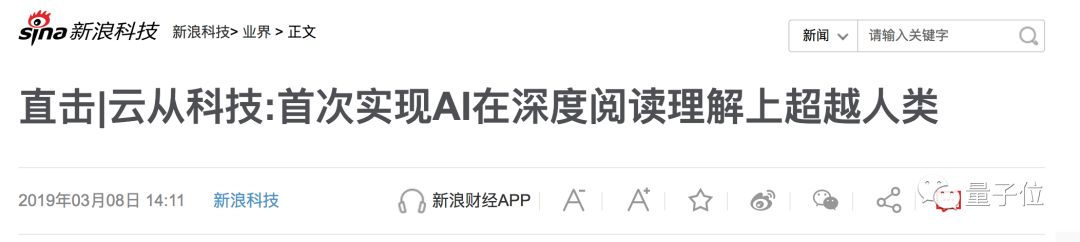
不过熟料战况异常激烈,万万没想到,在云从刷榜通告发出后不久,中国另一代表队——微信AI提交最新成绩,并成功实现超越,且还是对人类水平的全面超越。
这年头,庆功都不允许雍容款款了。
微信第一,BERT称王
那么微信AI模型,究竟有何独到之处?
在RACE中,微信AI模型整体正确率73.5%,超过了普通人类的73.3%。
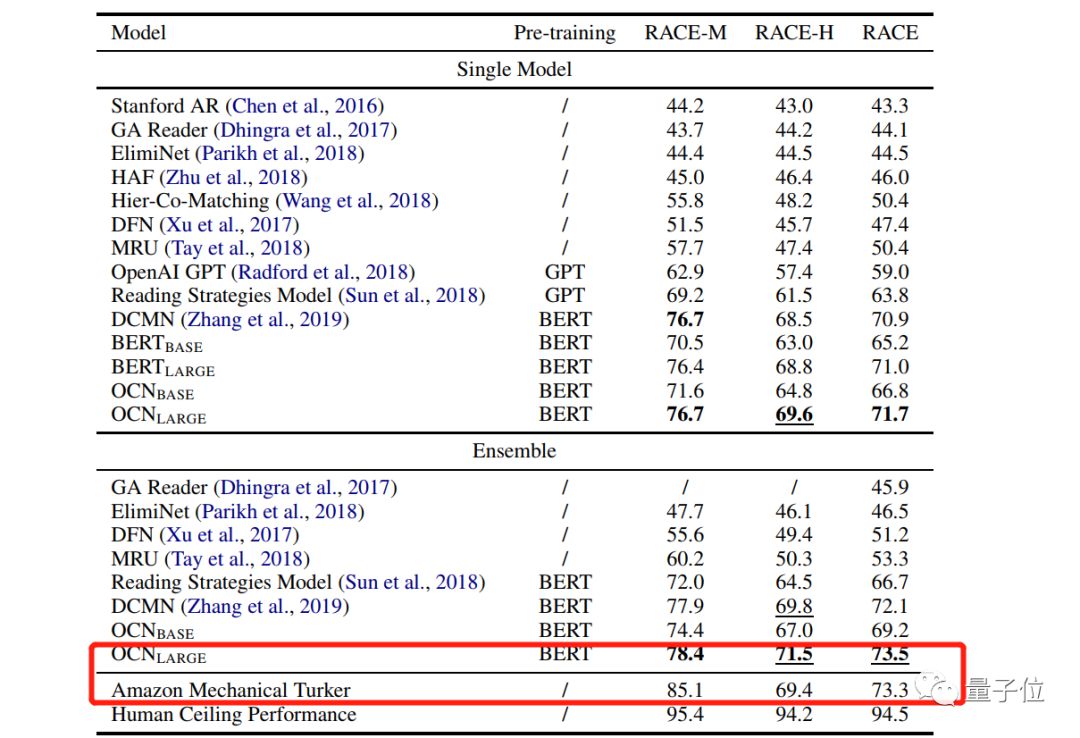
其使用的是选项比较网络(OCN),模仿人类完成阅读理解任务的做法,在单词级别上对各个选项进行比较,以识别其中的相关性,来帮助推理答案。
不过,在这个竞赛中,更大的赢家却是BERT。
微信AI使用的模型,正是基于BERT。
不仅仅是微信AI,榜单二三名,也都是基于BERT。
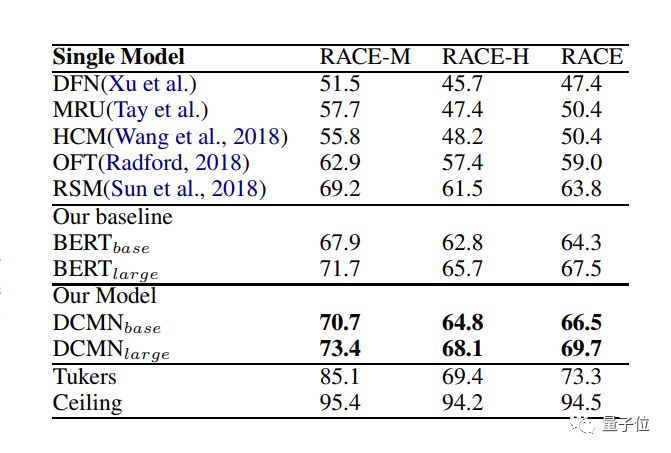
目前排名第二的选手,上海交大与云从提出的双协同匹配网络(DCMN),可以模拟段落、问题和答案之间的双向关系,来进行更好的推理。在RACE数据集高中题目上拿下了69.8%准确率,超过普通人类表现。
BERT的成绩,并不会让人太过意外。
这个于2018年10月由谷歌推出模型,刚一问世便交出了一份惊人的成绩单。
在机器阅读理解顶级水平测试SQuAD1.1中,全面超越人类表现,并在11种不同NLP测试中创出最佳成绩。
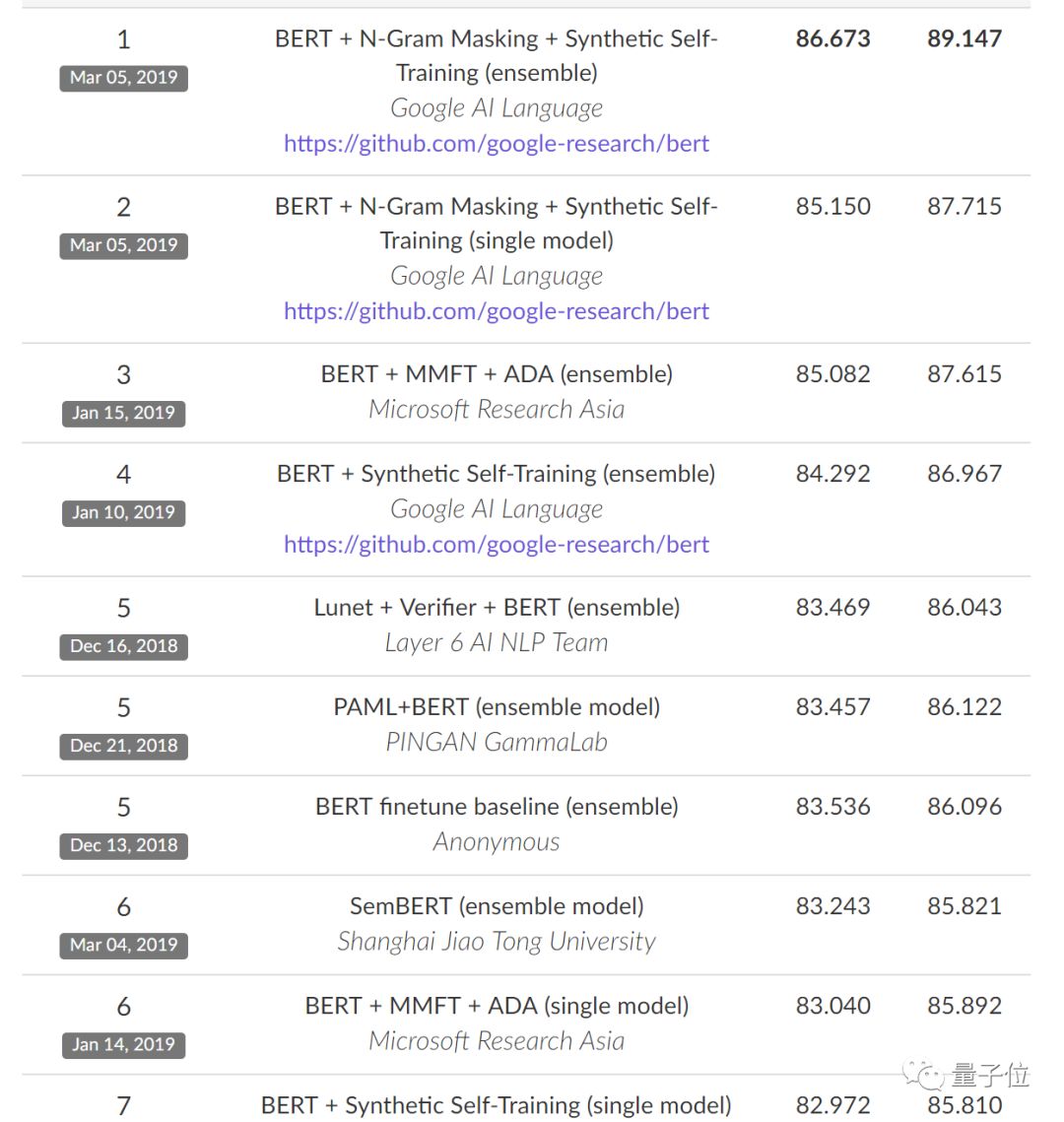
现在,SQuAD 2.0榜单已经被BERT垄断,前30名之中都很难见到不用BERT的选手。
在我们今天要讲的RACE竞赛中,借BERT上榜的还有一名高中生。他来自新加坡立化中学,也是中国人。
他的模型,比腾讯AI Lab和康奈尔大学提出模型成绩还要好。
高中生力压腾讯AI Lab+康奈尔
这位高中生名叫司程磊,初中就读于合肥市第五十中学,2015年被新加坡立化中学录取。
他的这项研究并不复杂,只是基于RACE数据集对预训练好的BERT模型进行调参。
司程磊在GitHub页上声明自己的成果是基于BERT的PyTorch实现。但作为一名高中生,已经开始上手调参炼丹,的确比不少同龄人要超前了不少。
还在高中就读的司程磊展现出了对计算机科学的浓厚兴趣,他的GitHub页上显示他正在自学斯坦福大学的NLP课程CS224N,还在Coursera上自学加州大学圣迭戈的算法课程。
另一方面,他也在关注NOI(全国信息学奥林匹克竞赛)、ACM竞赛。
司程磊可不仅仅把这些停留在简单的关注上,每门学过的课程,他都认认真真地在GitHub上编写习题的代码。
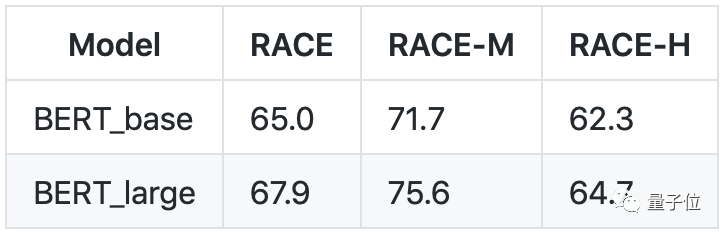
言归正传,司程磊根据模型的精细程度,将结果分成基本BERT(BERT_base)和大型BERT(BERT_large)两部分。BERT_large的batch size更小、学习率更低,因此在测试结果上优于BERT_base。
不过,腾讯AI Lab被超越,也是情理之中。
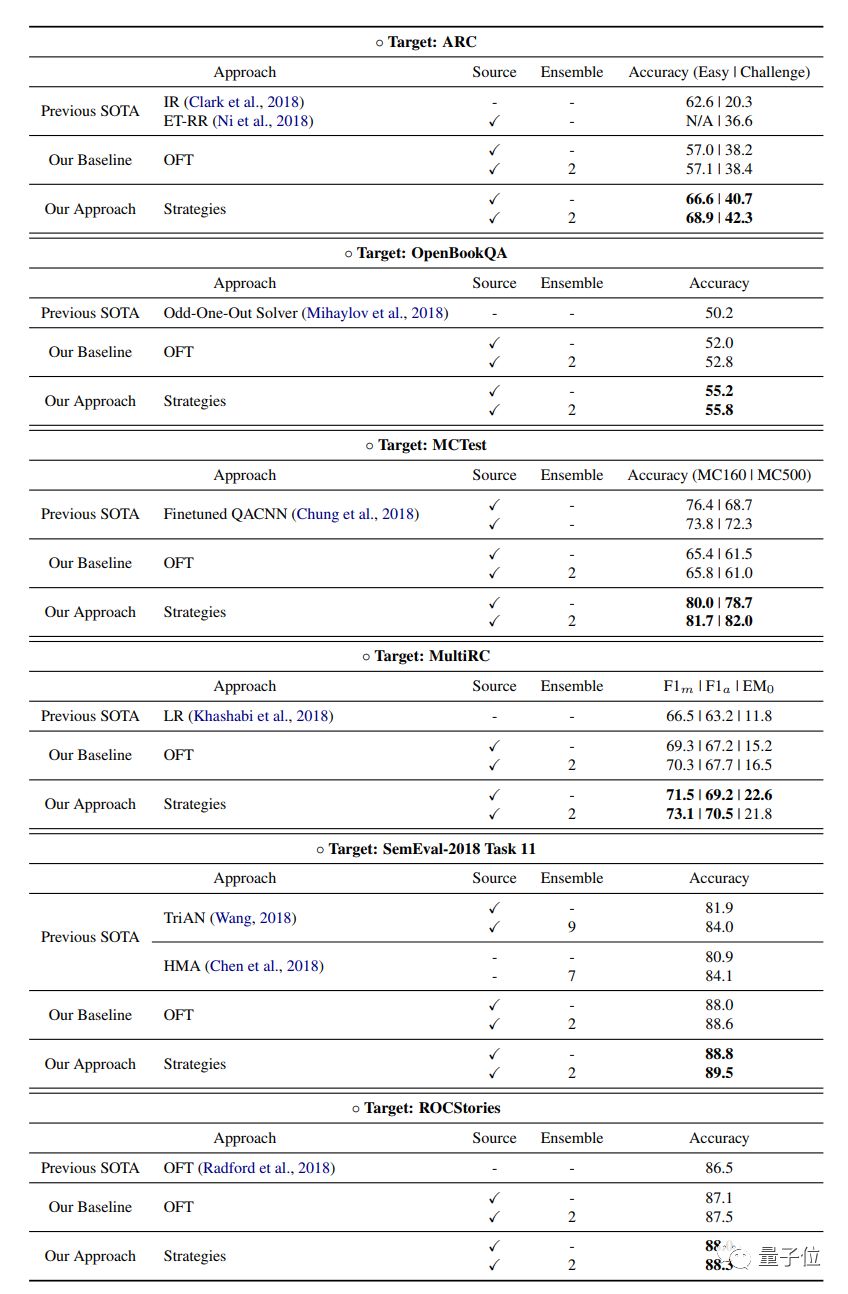
他们上次提交成绩,还是在2018年10月。
当时,他们基于Transformer的模型,在多个阅读理解数据集上都实现了最优结果。
但现在已经是2019年了,BERT已经开源,成了各个NLP模型中的核心。
而2017年推出的RACE,也因此迎来革命性时刻。
RACE:让AI做高考题的数据集
RACE(Large-scale ReAding Comprehension Dataset From Examination),由两位来自中国的博士生提出,是一个从初中和高中试题中收集的大型英文阅读理解数据集。
RACE一共收集了28,130篇文章,包含了98,432个问题。 数据集又分为RACE-M(初中)和RACE-H(高中)两个部分。
RACE由中学教师设计,用于测试学生的阅读理解技能。要想选出正确答案,不能直接从原句子中寻找,而是需要找到相关的上下文,还需要逻辑推理并运用社会、数学、文化等方面的常识进行分析。这对AI是个很大的考验。
关于RACE数据集的文章曾被EMNLP 2017收录,当时最先进的机器阅读理解模型也只能获得42.3%的正确率,而在亚马逊的众包平台Turkers上,人类的平均正确率达到了73.3%,上限成绩是94.5%。
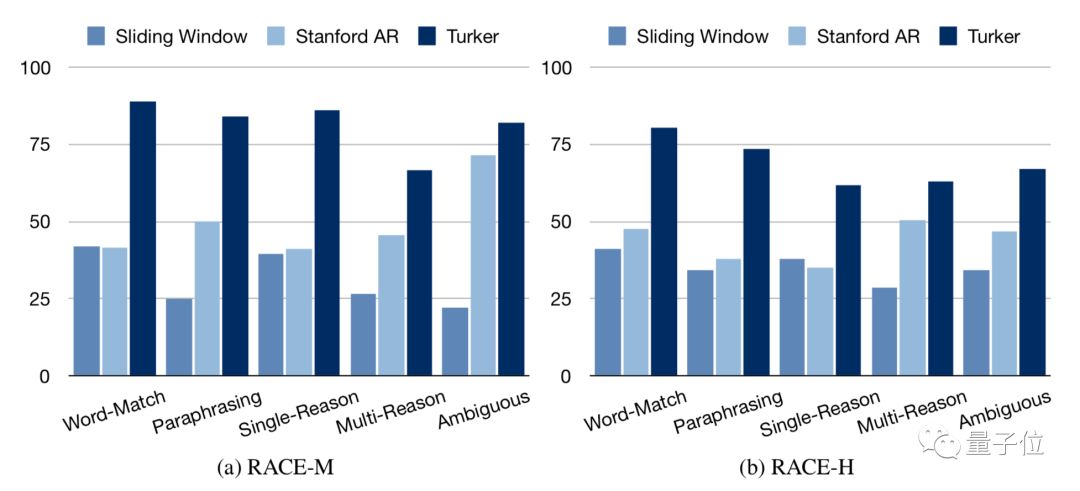
数据集作者用Sliding Window和Stanford AR两个模型的测试结果与人类对比
显然最先进模型与人类表现之间存在显着差距,RACE很适合作为机器阅读的测试标准。
开发这个数据集的,是卡内基·梅隆大学的两位在读博士赖国堃和谢其哲,他们都曾都在微软亚洲研究院实习过。
除了阅读理解外,这两位还提出过英文完型填空的数据集CLOTH。他们去年12月用BERT模型超越了人类得分。
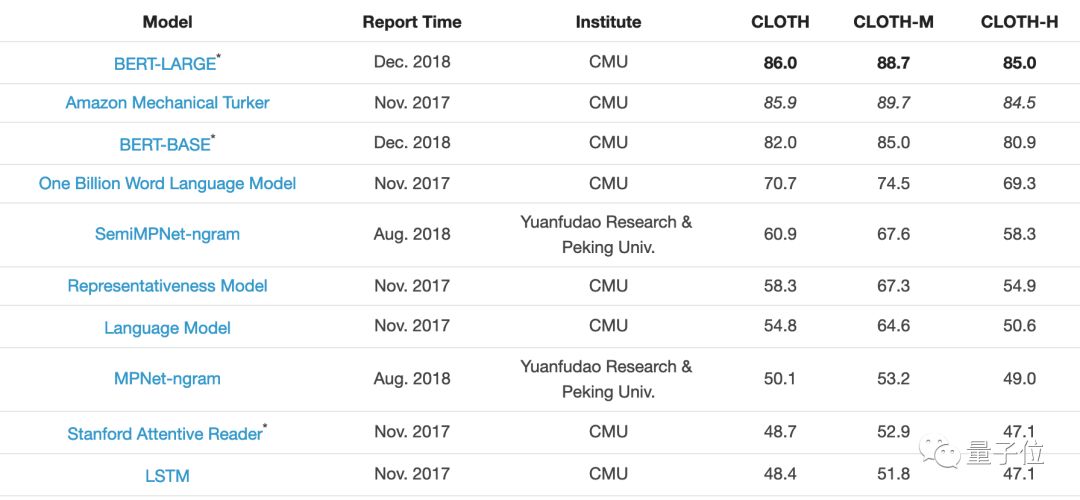
谢其哲毕业于上海交大ACM班,目前正在攻读CMU博士学位,已有多篇论文被ACL、EMNLP、NIPS等顶会收录。

他的本科导师俞凯,是苏州思必驰信息科技有限公司首席科学家,同时也是上海交通大学苏州人工智能研究院执行院长。
也是名师出高徒的又一例证。
后生可畏
当然,现在各大全球AI竞赛被中国军团霸榜,早已见怪不怪了。
远的不说,2018年的国际顶级口语机器翻译评测大赛IWSLT上,搜狗第一,讯飞第二,阿里巴巴第三,承包了Baseline Model赛道前三。
还有COCO+Mapillary 2018物体识别联合挑战赛上,中国团队包揽全部六项赛事的第一名,其中旷视团队获得4项冠军,商汤、北邮和滴滴团队分别获得1项冠军。
然而与之前种种霸榜事件相比,这次大有不同,毕竟此次中国军团中,还有崭露头角的高中生——此外测试标准本身,也由两名中国留学生提出。
真是一个后生可畏的年代啊!
如果你也关注近期AI顶会的论文,还会发现各路本科生、实习生大展神威。
中国AI的年轻一代,正在源源不断走到前台。
看来未来AI工程师退休,都不用拖到35岁高龄了。(手动狗头)
传送门
RACE榜单地址:
http://www.qizhexie.com/data/RACE_leaderboard
RACE论文地址:
https://arxiv.org/pdf/1704.04683.pdf
RACE数据集地址:
http://www.cs.cmu.edu/~glai1/data/race/
微信AI论文地址:
https://arxiv.org/pdf/1903.03033.pdf
编辑:王菁
校对:陈瑞清



