
- 1别再分库分表了,来试试 TiDB 吧!
- 2基于深度学习算法的垃圾分类图像识别研究_垃圾分类算法摄像头
- 3记一次实战中巧用Nday拿下shell
- 4React中 将UI 视为树
- 5visionpro图片读取、写入_康耐视智能相机 visionpro 写入excel
- 6计算机设计文献参考,优秀计算机设计论文参考文献 计算机设计论文参考文献数量是多少...
- 7mybatis数据库交互框架_mybatis的markerinterface
- 8MATLAB下载+安装教程_matlab下载csdn
- 9微软发布Copilot+ PC:集成GPT-4o,史上最强、最快Windows!_copilot+pc 文生图
- 10为Atmega328P定制bootloader 添加自己的板卡到Arduino IDE
【计算机视觉】 opencv双目视觉 立体视觉 三维重建_stereo vision : algorithms and applications ppt
赞
踩
双目 MATLAB标定 ,查阅博主的【计算机视觉】摄像机标定 matlab toolbox_calib工具箱(单目标定和双目标定)
1 基本原理

得到了立体标定参数之后,就可以把参数放入xml文件,然后用cvLoad读入OpenCV了。具体的方法可以参照Learning OpenCV第11章的例子,上面就是用cvSave保存标定结果,然后再用cvLoad把之前的标定结果读入矩阵的
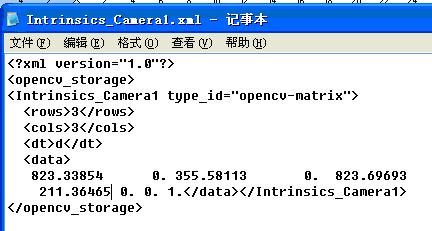
2.14. xml文件示例
这里需要注意的是Matlab标定结果中的om向量,这个向量是旋转矩阵通过Rodrigues变换之后得出的结果,如果要在cvStereoRectify中使用的话,需要首先将这个向量用cvRodrigues转换成旋转矩阵。关于Rodrigues变换,Learning OpenCV的第11章也有说明。

2.15. 旋转矩阵的Rodrigues形式表示
3. 立体校准和匹配
有了标定参数,校准的过程就很简单了。
我使用的是OpenCV中的cvStereoRectify,得出校准参数之后用cvRemap来校准输入的左右图像。这部分的代码参考的是Learning OpenCV 十二章的例子。
校准之后,就可以立体匹配了。立体匹配OpenCV里面有两种方法,一种是Block Matching,一种是Graph Cut。Block Matching用的是SAD方法,速度比较快,但效果一般。Graph Cut可以参考Kolmogrov03的那篇博士论文,效果不错,但是运行速度实在是慢到不能忍。所以还是选择BM。
以下是我用BM进行立体匹配的参数设置
[cpp] view plain copy
- BMState = cvCreateStereoBMState(CV_STEREO_BM_BASIC,0);
- assert(BMState != 0);
- BMState->preFilterSize=13;
- BMState->preFilterCap=13;
- BMState->SADWindowSize=19;
- BMState->minDisparity=0;
- BMState->numberOfDisparities=unitDisparity*16;
- BMState->textureThreshold=10;
- BMState->uniquenessRatio=20;
- BMState->speckleWindowSize=13;
其中minDisparity这个参数我设置为0是由于我的两个摄像头是前向平行放置,相同的物体在左图中一定比在右图中偏右,如下图3.1所示。所以没有必要设置回搜的参数。
如果为了追求更大的双目重合区域而将两个摄像头向内偏转的话,这个参数是需要考虑的。

3.1. 校正后的左右视图
另外需要提的参数是uniquenessRatio,实验下来,我感觉这个参数对于最后的匹配结果是有很大的影响。uniquenessRatio主要可以防止误匹配,其主要作用从下面三幅图的disparity效果比对就可以看出。在立体匹配中,我们宁愿区域无法匹配,也不要误匹配。如果有误匹配的话,碰到障碍检测这种应用,就会很麻烦。
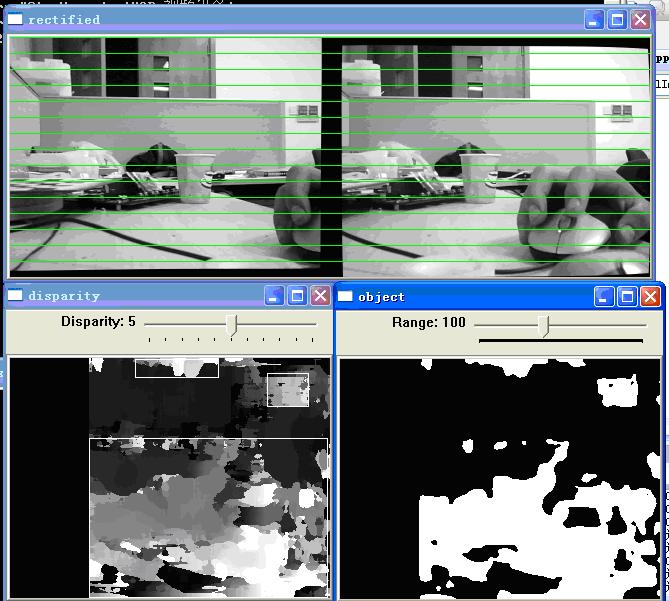
3.2. UniquenessRatio为0时的匹配图,可以看到大片的误匹配区域
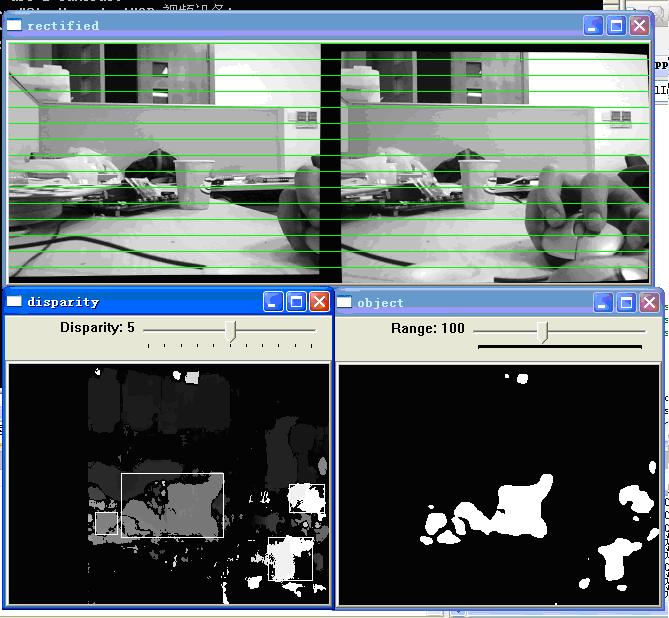
3.3. UniquenessRatio为10时的disparity map, 可以看到误匹配被大量减少了, 但还是有噪点
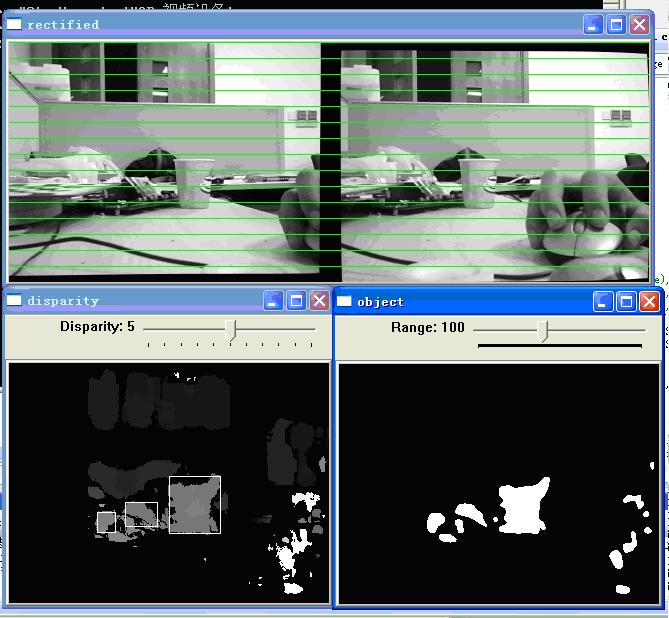
3.4. UniquenessRatio为20时的disparity map, 可以看到误匹配基本被去除了, 点云干净了很多
关于cvFindStereoCorrespondenceBM这个函数的源代码,曾经做过比较详细的研究,过一段时间也会把之前写的代码注释整理一下,发篇博文。
4. 实际距离的测量
在用cvFindStereoCorrespondenceBM得出disparity map之后,还需要通过cvReprojectImageTo3D这个函数将单通道Disparity Map转换成三通道的实际坐标矩阵。
具体的数学原理可以参考下面这个公式(from chenyusiyuan http://blog.csdn.net/chenyusiyuan/archive/2009/12/25/5072597.aspx,实际深度的一些问题这篇博文中也有提到)

4.1 距离转换公式
但是在实际操作过程中,用cvReprojectImageTo3D得到的数据并未如实际所想,生成深度矩阵所定义的世界坐标系我就一直没弄清楚。这在下面的例子中会详细说明,希望这方面的专家能帮忙解答一下:
图4.2是测量时的实际场景图,场景中主要测量的三个物体就是最前面的利乐包装盒、中间的纸杯、和最远的塑料瓶。

4.2. 实际场景中三个待测物体的位置
图4.3是校准后的左右图和匹配出来的disparity map,disparity窗口中是实际的点云,object窗口是给disparity map加了个阈值之后得到的二值图,主要是为了分割前景和背景。可以看到要测的三个物体基本被正确地分割出来了
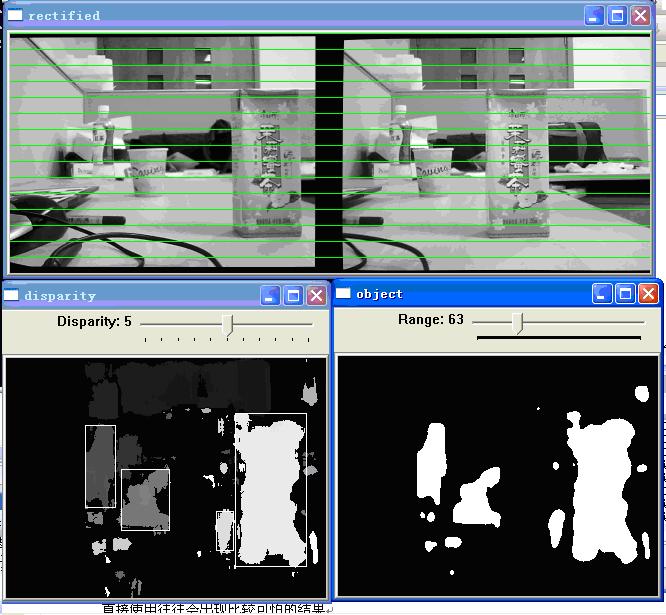
4.3. 双目摄像头得到的disparity map
图4.4是在disparity窗口中选取一个点后然后在实际坐标矩阵中得到的对应三维信息,在这里,我在三个物体的点云上各选一个点来代表一个物体实际的坐标信息。(这里通过鼠标获取一点坐标信息的方法参考的是opencv sample里的watershed.cpp)
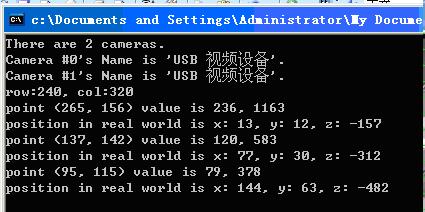
4.4. 对应点的三维坐标
在这里可以看到,(265, 156)也就是利乐包装盒的坐标是(13, 12, -157),(137, 142)纸杯的坐标是(77, 30, -312),(95, 115)塑料瓶的坐标是(144, 63, -482)。
补充一下:为了方便显示,所以视差图出来之后进行了一个0-255的normalize,所以value值的前一个是normalize之后点的灰度值,后一个是normalize之前点的实际视差图。
由cvFindStereoCorrespondenceBM算法的源代码:
dptr[y*dstep] = (short)(((ndisp - mind - 1 + mindisp)*256 + (d != 0 ? (p-n)*128/d : 0) + 15) >> 4);
其中
ndisp是ndisp = state->numberOfDisparities;
mindisp是mindisp = state->minDisparity;
mind就是sad得出的视差
实际视差大约是(64-mind-1)*256=1163, 基本是对的, 后面一项修正值在通常情况下可以忽略
目前我还是不是很清楚立体坐标系原点(左相机坐标原点)和尺度,但是从这三个点的z坐标可以大致看出这三个物体的距离差大概是1:2:3,基本与实际场景中物体的位置一致。因此,可以通过这种方法确定出物体的大致距离信息。
但是,如果就从摄像头参数本身来测量距离的话,就不是很明白了,还求这方面的大牛解答。
5. 一些问题
5.1 关于StereoCalibrate
OpenCV自带的cvStereoCalibrate感觉不怎么好用,用这个函数求出的内参外参和旋转平移矩阵进行校准,往往无法达到行对准,有时甚至会出现比较可怕的畸变。在看了piao的http://www.opencv.org.cn/forum/viewtopic.php?f=1&t=4603帖子之后,也曾经尝试过现用cvCalibrateCamera2单独标定(左右各20幅图),得出的结果基本和Matlab单独标定的相同,然后再在cvStereoCalibrate中将参数设成CV_CALIB_USE_INTRINSIC_GUESS,用来细化内参数和畸变参数,结果得出的标定结果就又走样了。
不知道有谁在这方面有过成功经验的,可以出来分享一下。毕竟用Matlab工具箱还是麻烦了些。
5.2 Translation向量以及立体匹配得出的世界坐标系
Learning OpenCV中对于Translation和Rotation的图示是这样的
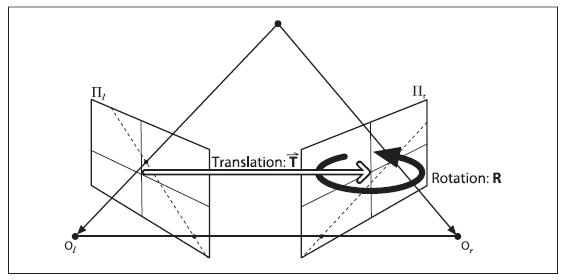
5.1. Learning OpenCV中的图示
可是在实验过程中发现,如果将Translation向量按尺度缩放,对于StereoRectify之后的左右视图不会有变化,比如将T = [ -226.73817 -0.62302 8.93984 ] ,变成T = [ -22.673817 -0.062302 0.893984 ],在OpenCV中显示的结果不会有任何变化。而且我如果修改其中的一个参量的话,左右视图发生的变化也不是图5.1中所示的那种变化(比如把x缩小,那么视图发生的变化不是往x轴方向的平移)。
因此又回到了老问题,这里这些坐标的尺度究竟是什么?通过ReprojectTo3D那个函数得到的三维坐标又是以哪个点为原点,那三个方向为x,y,z轴的?
补充: 对这个问题的解答来自于和maxwellsdemon的讨论
他的解释如下:rotation是两者的旋转角度的关系,但是你要把它矫正平行,也是需要translation matrix的。你可以设想,两个看似已经平行了的摄像头,但是深度上放置的有差距,那么在矫正的时候会议translation matrix所对应的角度或者直线为基准,二者旋转一个小角度,使得完全平行。
目前立体匹配算法是计算机视觉中的一个难点和热点,算法很多,但是一般的步骤是:
A、匹配代价计算
匹配代价计算是整个立体匹配算法的基础,实际是对不同视差下进行灰度相似性测量。常见的方法有灰度差的平方SD(squared intensity differences),灰度差的绝对值AD(absolute intensity differences)等。另外,在求原始匹配代价时可以设定一个上限值,来减弱叠加过程中的误匹配的影响。以AD法求匹配代价为例,可用下式进行计算,其中T为设定的阈值。

图18
B、 匹配代价叠加
一般来说,全局算法基于原始匹配代价进行后续算法计算。而区域算法则需要通过窗口叠加来增强匹配代价的可靠性,根据原始匹配代价不同,可分为:
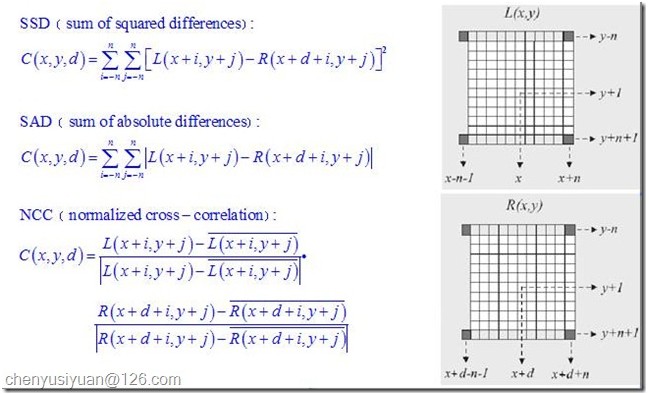
图19
C、 视差获取
对于区域算法来说,在完成匹配代价的叠加以后,视差的获取就很容易了,只需在一定范围内选取叠加匹配代价最优的点(SAD和SSD取最小值,NCC取最大值)作为对应匹配点,如胜者为王算法WTA(Winner-take-all)。而全局算法则直接对原始匹配代价进行处理,一般会先给出一个能量评价函数,然后通过不同的优化算法来求得能量的最小值,同时每个点的视差值也就计算出来了。
D、视差细化(亚像素级)
大多数立体匹配算法计算出来的视差都是一些离散的特定整数值,可满足一般应用的精度要求。但在一些精度要求比较高的场合,如精确的三维重构中,就需要在初始视差获取后采用一些措施对视差进行细化,如匹配代价的曲线拟合、图像滤波、图像分割等。
有关立体匹配的介绍和常见匹配算法的比较,推荐大家看看Stefano Mattoccia 的讲义 Stereo Vision: algorithms and applications,190页的ppt,讲解得非常形象详尽。
1. opencv2.1和opencv2.0在做stereo vision方面有什么区别了?
2.1版增强了Stereo Vision方面的功能:
(1) 新增了 SGBM 立体匹配算法(源自Heiko Hirschmuller的《Stereo Processing by Semi-global Matching and Mutual Information》),可以获得比 BM 算法物体轮廓更清晰的视差图(但低纹理区域容易出现横/斜纹路,在 GCstate->fullDP 选项使能时可消减这种异常纹路,但对应区域视差变为0,且运行速度会有所下降),速度比 BM 稍慢, 352*288的帧处理速度大约是 5 帧/秒;
(2) 视差效果:BM < SGBM < GC;处理速度:BM > SGBM > GC ;
(3) BM 算法比2.0版性能有所提升,其状态参数新增了对左右视图感兴趣区域 ROI 的支持(roi1 和 roi2,由stereoRectify函数产生);
(4) BM 算法和 GC 算法的核心代码改动不大,主要是面向多线程运算方面的(由 OpenMP 转向 Intel TBB);
(5) cvFindStereoCorrespondenceBM 函数的disparity参数的数据格式新增了 CV_32F 的支持,这种格式的数据给出实际视差,而 2.0 版只支持 CV_16S,需要除以 16.0 才能得到实际的视差数值。
2. 用于立体匹配的图像可以是彩色的吗?
在OpenCV2.1中,BM和GC算法只能对8位灰度图像计算视差,SGBM算法则可以处理24位(8bits*3)彩色图像。所以在读入图像时,应该根据采用的算法来处理图像:
int color_mode = alg == STEREO_SGBM ? 1 : 0;
//
// 载入图像
cvGrabFrame( lfCam );
cvGrabFrame( riCam );
frame1 = cvRetrieveFrame( lfCam );
frame2 = cvRetrieveFrame( riCam );
if(frame1.empty()) break;
resize(frame1, img1, img_size, 0, 0);
resize(frame2, img2, img_size, 0, 0);
// 选择彩色或灰度格式作为双目匹配的处理图像
if (!color_mode && cn>1)
{
cvtColor(img1, img1gray, CV_BGR2GRAY);
cvtColor(img2, img2gray, CV_BGR2GRAY);
img1p = img1gray;
img2p = img2gray;
}
else
{
img1p = img1;
img2p = img2;
}
3. 怎样获取与原图像有效像素区域相同的视差图?
在OpenCV2.0及以前的版本中,所获取的视差图总是在左侧和右侧有明显的黑色区域,这些区域没有有效的视差数据。视差图有效像素区域与视差窗口(ndisp,一般取正值且能被16整除)和最小视差值(mindisp,一般取0或负值)相关,视差窗口越大,视差图左侧的黑色区域越大,最小视差值越小,视差图右侧的黑色区域越大。其原因是为了保证参考图像(一般是左视图)的像素点能在目标图像(右视图)中按照设定的视差匹配窗口匹配对应点,OpenCV 只从参考图像的第 (ndisp - 1 + mindisp) 列开始向右计算视差,第 0 列到第 (ndisp - 1 + mindisp) 列的区域视差统一设置为 (mindisp - 1) *16;视差计算到第 width + mindisp 列时停止,余下的右侧区域视差值也统一设置为 (mindisp - 1) *16。
- 00177 static const int DISPARITY_SHIFT = 4;
- …
- 00411 int ndisp = state->numberOfDisparities;
- 00412 int mindisp = state->minDisparity;
- 00413 int lofs = MAX(ndisp - 1 + mindisp, 0);
- 00414 int rofs = -MIN(ndisp - 1 + mindisp, 0);
- 00415 int width = left->cols, height = left->rows;
- 00416 int width1 = width - rofs - ndisp + 1;
- …
- 00420 short FILTERED = (short)((mindisp - 1) << DISPARITY_SHIFT);
- …
- 00466 // initialize the left and right borders of the disparity map
- 00467 for( y = 0; y < height; y++ )
- 00468 {
- 00469 for( x = 0; x < lofs; x++ )
- 00470 dptr[y*dstep + x] = FILTERED;
- 00471 for( x = lofs + width1; x < width; x++ )
- 00472 dptr[y*dstep + x] = FILTERED;
- 00473 }
- 00474 dptr += lofs;
- 00475
- 00476 for( x = 0; x < width1; x++, dptr++ )
-
- …

这样的设置很明显是不符合实际应用的需求的,它相当于把摄像头的视场范围缩窄了。因此,OpenCV2.1 做了明显的改进,不再要求左右视图和视差图的大小(size)一致,允许对视差图进行左右边界延拓,这样,虽然计算视差时还是按上面的代码思路来处理左右边界,但是视差图的边界得到延拓后,有效视差的范围就能够与对应视图完全对应。具体的实现代码范例如下:
- //
- // 对左右视图的左边进行边界延拓,以获取与原始视图相同大小的有效视差区域
- copyMakeBorder(img1r, img1b, 0, 0, m_nMaxDisp, 0, IPL_BORDER_REPLICATE);
- copyMakeBorder(img2r, img2b, 0, 0, m_nMaxDisp, 0, IPL_BORDER_REPLICATE);
-
- //
- // 计算视差
- if( alg == STEREO_BM )
- {
- bm(img1b, img2b, dispb);
- // 截取与原始画面对应的视差区域(舍去加宽的部分)
- displf = dispb.colRange(m_nMaxDisp, img1b.cols);
- }
- else if(alg == STEREO_SGBM)
- {
- sgbm(img1b, img2b, dispb);
- displf = dispb.colRange(m_nMaxDisp, img1b.cols);
- }
4. cvFindStereoCorrespondenceBM的输出结果好像不是以像素点为单位的视差?
“@scyscyao:在OpenCV2.0中,BM函数得出的结果是以16位符号数的形式的存储的,出于精度需要,所有的视差在输出时都扩大了16倍(2^4)。其具体代码表示如下:
dptr[y*dstep] = (short)(((ndisp - mind - 1 + mindisp)*256 + (d != 0 ? (p-n)*128/d : 0) + 15) >> 4);
可以看到,原始视差在左移8位(256)并且加上一个修正值之后又右移了4位,最终的结果就是左移4位。
因此,在实际求距离时,cvReprojectTo3D出来的X/W,Y/W,Z/W都要乘以16 (也就是W除以16),才能得到正确的三维坐标信息。”
在OpenCV2.1中,BM算法可以用 CV_16S 或者 CV_32F 的方式输出视差数据,使用32位float格式可以得到真实的视差值,而CV_16S 格式得到的视差矩阵则需要 除以16 才能得到正确的视差。另外,OpenCV2.1另外两种立体匹配算法 SGBM 和 GC 只支持 CV_16S 格式的 disparity 矩阵。
5. 如何设置BM、SGBM和GC算法的状态参数?
(1)StereoBMState
// 预处理滤波参数
- preFilterType:预处理滤波器的类型,主要是用于降低亮度失真(photometric distortions)、消除噪声和增强纹理等, 有两种可选类型:CV_STEREO_BM_NORMALIZED_RESPONSE(归一化响应) 或者 CV_STEREO_BM_XSOBEL(水平方向Sobel算子,默认类型), 该参数为 int 型;
- preFilterSize:预处理滤波器窗口大小,容许范围是[5,255],一般应该在 5x5..21x21 之间,参数必须为奇数值, int 型
- preFilterCap:预处理滤波器的截断值,预处理的输出值仅保留[-preFilterCap, preFilterCap]范围内的值,参数范围:1 - 31(文档中是31,但代码中是 63), int
// SAD 参数
- SADWindowSize:SAD窗口大小,容许范围是[5,255],一般应该在 5x5 至 21x21 之间,参数必须是奇数,int 型
- minDisparity:最小视差,默认值为 0, 可以是负值,int 型
- numberOfDisparities:视差窗口,即最大视差值与最小视差值之差, 窗口大小必须是 16 的整数倍,int 型
// 后处理参数
- textureThreshold:低纹理区域的判断阈值。如果当前SAD窗口内所有邻居像素点的x导数绝对值之和小于指定阈值,则该窗口对应的像素点的视差值为 0(That is, if the sum of absolute values of x-derivatives computed over SADWindowSize by SADWindowSize pixel neighborhood is smaller than the parameter, no disparity is computed at the pixel),该参数不能为负值,int 型
- uniquenessRatio:视差唯一性百分比, 视差窗口范围内最低代价是次低代价的(1 + uniquenessRatio/100)倍时,最低代价对应的视差值才是该像素点的视差,否则该像素点的视差为 0 (the minimum margin in percents between the best (minimum) cost function value and the second best value to accept the computed disparity, that is, accept the computed disparity d^ only if SAD(d) >= SAD(d^) x (1 + uniquenessRatio/100.) for any d != d*+/-1 within the search range ),该参数不能为负值,一般5-15左右的值比较合适,int 型
- speckleWindowSize:检查视差连通区域变化度的窗口大小, 值为 0 时取消 speckle 检查,int 型
- speckleRange:视差变化阈值,当窗口内视差变化大于阈值时,该窗口内的视差清零,int 型
// OpenCV2.1 新增的状态参数
- roi1, roi2:左右视图的有效像素区域,一般由双目校正阶段的 cvStereoRectify 函数传递,也可以自行设定。一旦在状态参数中设定了 roi1 和 roi2,OpenCV 会通过cvGetValidDisparityROI 函数计算出视差图的有效区域,在有效区域外的视差值将被清零。
- disp12MaxDiff:左视差图(直接计算得出)和右视差图(通过cvValidateDisparity计算得出)之间的最大容许差异。超过该阈值的视差值将被清零。该参数默认为 -1,即不执行左右视差检查。int 型。注意在程序调试阶段最好保持该值为 -1,以便查看不同视差窗口生成的视差效果。具体请参见《使用OpenGL动态显示双目视觉三维重构效果示例》一文中的讨论。
在上述参数中,对视差生成效果影响较大的主要参数是 SADWindowSize、numberOfDisparities 和 uniquenessRatio 三个,一般只需对这三个参数进行调整,其余参数按默认设置即可。
在OpenCV2.1中,BM算法有C和C++ 两种实现模块。
(2)StereoSGBMState
SGBM算法的状态参数大部分与BM算法的一致,下面只解释不同的部分:
- SADWindowSize:SAD窗口大小,容许范围是[1,11],一般应该在 3x3 至 11x11 之间,参数必须是奇数,int 型
- P1, P2:控制视差变化平滑性的参数。P1、P2的值越大,视差越平滑。P1是相邻像素点视差增/减 1 时的惩罚系数;P2是相邻像素点视差变化值大于1时的惩罚系数。P2必须大于P1。OpenCV2.1提供的例程 stereo_match.cpp 给出了 P1 和 P2 比较合适的数值。
- fullDP:布尔值,当设置为 TRUE 时,运行双通道动态编程算法(full-scale 2-pass dynamic programming algorithm),会占用O(W*H*numDisparities)个字节,对于高分辨率图像将占用较大的内存空间。一般设置为 FALSE。
注意OpenCV2.1的SGBM算法是用C++ 语言编写的,没有C实现模块。与H. Hirschmuller提出的原算法相比,主要有如下变化:
- 算法默认运行单通道DP算法,只用了5个方向,而fullDP使能时则使用8个方向(可能需要占用大量内存)。
- 算法在计算匹配代价函数时,采用块匹配方法而非像素匹配(不过SADWindowSize=1时就等于像素匹配了)。
- 匹配代价的计算采用BT算法("Depth Discontinuities by Pixel-to-Pixel Stereo" by S. Birchfield and C. Tomasi),并没有实现基于互熵信息的匹配代价计算。
- 增加了一些BM算法中的预处理和后处理程序。
(3)StereoGCState
GC算法的状态参数只有两个:numberOfDisparities 和 maxIters ,并且只能通过 cvCreateStereoGCState 在创建算法状态结构体时一次性确定,不能在循环中更新状态信息。GC算法并不是一种实时算法,但可以得到物体轮廓清晰准确的视差图,适用于静态环境物体的深度重构。
注意GC算法只能在C语言模式下运行,并且不能对视差图进行预先的边界延拓,左右视图和左右视差矩阵的大小必须一致。
6. 如何实现视差图的伪彩色显示?
首先要将16位符号整形的视差矩阵转换为8位无符号整形矩阵,然后按照一定的变换关系进行伪彩色处理。我的实现代码如下:
- // 转换为 CV_8U 格式,彩色显示
- dispLfcv = displf, dispRicv = dispri, disp8cv = disp8;
- if (alg == STEREO_GC)
- {
- cvNormalize( &dispLfcv, &disp8cv, 0, 256, CV_MINMAX );
- }
- else
- {
- displf.convertTo(disp8, CV_8U, 255/(m_nMaxDisp*16.));
- }
- F_Gray2Color(&disp8cv, vdispRGB);
灰度图转伪彩色图的代码,主要功能是使灰度图中 亮度越高的像素点,在伪彩色图中对应的点越趋向于 红色;亮度越低,则对应的伪彩色越趋向于 蓝色;总体上按照灰度值高低,由红渐变至蓝,中间色为绿色。其对应关系如下图所示:
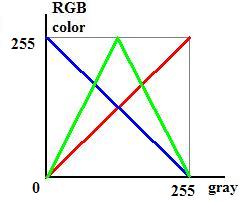
图20
- void F_Gray2Color(CvMat* gray_mat, CvMat* color_mat)
- {
- if(color_mat)
- cvZero(color_mat);
-
- int stype = CV_MAT_TYPE(gray_mat->type), dtype = CV_MAT_TYPE(color_mat->type);
- int rows = gray_mat->rows, cols = gray_mat->cols;
-
- // 判断输入的灰度图和输出的伪彩色图是否大小相同、格式是否符合要求
- if (CV_ARE_SIZES_EQ(gray_mat, color_mat) && stype == CV_8UC1 && dtype == CV_8UC3)
- {
- CvMat* red = cvCreateMat(gray_mat->rows, gray_mat->cols, CV_8U);
- CvMat* green = cvCreateMat(gray_mat->rows, gray_mat->cols, CV_8U);
- CvMat* blue = cvCreateMat(gray_mat->rows, gray_mat->cols, CV_8U);
- CvMat* mask = cvCreateMat(gray_mat->rows, gray_mat->cols, CV_8U);
-
- // 计算各彩色通道的像素值
- cvSubRS(gray_mat, cvScalar(255), blue); // blue(I) = 255 - gray(I)
- cvCopy(gray_mat, red); // red(I) = gray(I)
- cvCopy(gray_mat, green); // green(I) = gray(I),if gray(I) < 128
- cvCmpS(green, 128, mask, CV_CMP_GE ); // green(I) = 255 - gray(I), if gray(I) >= 128
- cvSubRS(green, cvScalar(255), green, mask);
- cvConvertScale(green, green, 2.0, 0.0);
-
- // 合成伪彩色图
- cvMerge(blue, green, red, NULL, color_mat);
-
- cvReleaseMat( &red );
- cvReleaseMat( &green );
- cvReleaseMat( &blue );
- cvReleaseMat( &mask );
- }
- }
7. 如何将视差数据保存为 txt 数据文件以便在 Matlab 中读取分析?
由于OpenCV本身只支持 xml、yml 的数据文件读写功能,并且其xml文件与构建网页数据所用的xml文件格式不一致,在Matlab中无法读取。我们可以通过以下方式将视差数据保存为txt文件,再导入到Matlab中。
- void saveDisp(const char* filename, const Mat& mat)
- {
- FILE* fp = fopen(filename, "wt");
- fprintf(fp, "%02d/n", mat.rows);
- fprintf(fp, "%02d/n", mat.cols);
- for(int y = 0; y < mat.rows; y++)
- {
- for(int x = 0; x < mat.cols; x++)
- {
- short disp = mat.at<short>(y, x); // 这里视差矩阵是CV_16S 格式的,故用 short 类型读取
- fprintf(fp, "%d/n", disp); // 若视差矩阵是 CV_32F 格式,则用 float 类型读取
- }
- }
- fclose(fp);
- }
相应的Matlab代码为:
- function img = txt2img(filename)
- data = importdata(filename);
- r = data(1); % 行数
- c = data(2); % 列数
- disp = data(3:end); % 视差
- vmin = min(disp);
- vmax = max(disp);
- disp = reshape(disp, [c,r])'; % 将列向量形式的 disp 重构为 矩阵形式
- % OpenCV 是行扫描存储图像,Matlab 是列扫描存储图像
- % 故对 disp 的重新排列是首先变成 c 行 r 列的矩阵,然后再转置回 r 行 c 列
- img = uint8( 255 * ( disp - vmin ) / ( vmax - vmin ) );
- mesh(disp);
- set(gca,'YDir','reverse'); % 通过 mesh 方式绘图时,需倒置 Y 轴方向
- axis tight; % 使坐标轴显示范围与数据范围相贴合,去除空白显示区
显示效果如下:
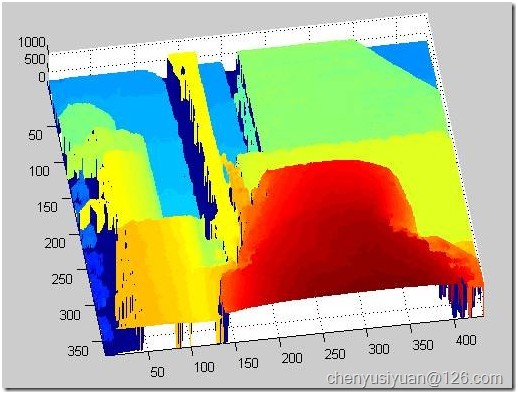
图21

