- 1Oracle物化视图(Materialized View)_oracle 物化视图
- 2基于FPGA的并行DDS设计
- 3python渗透工具编写学习笔记:9、web漏洞检测与利用脚本_python语言写网络渗透测试脚本
- 42024.5月更新大麦autojs代码,实现app端自动抢票_autojs 大麦
- 5AI辅写疑似度高风险?七招助你化险为夷!_论文ai风险高怎么解决
- 6Android Studio入门:Android应用界面详解(上)(View、布局管理器)_android studio的view
- 7腾讯后台开发一面(凉)_腾讯后端一面
- 8最新版IDEA(或Android Studio)Lombok的使用方法_android lombok
- 9Centos7防火墙与IPTABLES详解_centos7 iptables 和防火墙
- 10《动手学ROS2进阶篇》8.2RVIZ2可视化移动机器人模型_如何重装rviz2
预训练语言模型fine-tuning近期进展概述
赞
踩
近年来,迁移学习改变了自然语言处理领域的范式,对预训练语言模型(PLM)进行微调(fine-tuning)已经成为了新的范式。本文主要梳理了近期的预训练语言模型做fine-tuning的进展。



 另外,我们还建立了自然语言处理、推荐搜索、智能对话、知识图谱等方向的讨论组,欢迎大家加入讨论(人数达到上限,添加下方好友手动邀请),注意一定备注喔!
另外,我们还建立了自然语言处理、推荐搜索、智能对话、知识图谱等方向的讨论组,欢迎大家加入讨论(人数达到上限,添加下方好友手动邀请),注意一定备注喔!

本期内容主要参考下文:
https://ruder.io/recent-advances-lm-fine-tuning/index.html
在过去的三年里, fine-tuning的方法已经取代了从预训练embedding做特征提取的方法,而预训练语言模型由于其训练效率和出色的性能受到各种任务的青睐,如机器翻译,自然语言推理等,在这些方法上的成功经验也导致了后来像BERT,T5这样更大模型的出现。最近,如GPT-3这样的模型,数据规模实际上已经大到在不需要任何参数更新的情况下也可以取得非常优异的性能。然而,这种zero-shot场景毕竟存在着一定的限制。为了达到最佳性能或保持效率,在使用大型的预训练语言模型时,fine-tuning依然会作为主流方法而继续存在。
如下图,在标准的迁移学习场景中,首先在大规模无监督数据上使用建模语言特征的loss(如MLM)对一个模型做预训练,然后在下游任务的有标签数据上使用标准的cross-entropy loss对预训练模型做fine-tuning。
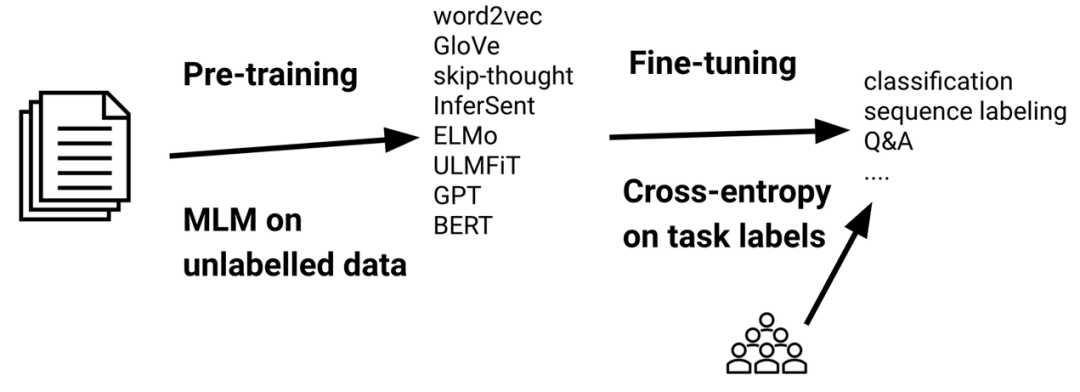
标准的pre-train —— fine-tuning 场景
虽然预训练依赖于大量的计算资源,但是fine-tuning只需要使用少量计算资源。因此,在对语言模型的实际使用中,fine-tuning就显得更为重要,例如,Hugging Face的模型库截至目前就已经被下载使用了数百万次之多。基于此,fine-tuning将是本文的讲述重点,尤其将重点介绍可能会影响我们fine-tune模型方式的一些近期进展。本文将分类介绍几种fine-tuning方法,如下图所示:

01
Adaptive fine-tuning 自适应微调
尽管预训练语言模型相比于之前的模型,有更为强大的泛化性能,但是它们仍然不能很好地适应与预训练数据分布差距较大的数据。Adaptive fine-tuning方法通过在更接近目标数据分布的数据上对模型做fine-tuning,来适应这种分布的变化。具体而言,adaptive fine-tuning在特定任务上fine-tuning之前,会基于增广数据对模型先做一次fine-tuning。这里需要注意的是,因为是基于预训练模型来做fine-tuning,所以adaptive fine-tuning只需要无监督数据。下图说明了adaptive fine-tuning的流程。
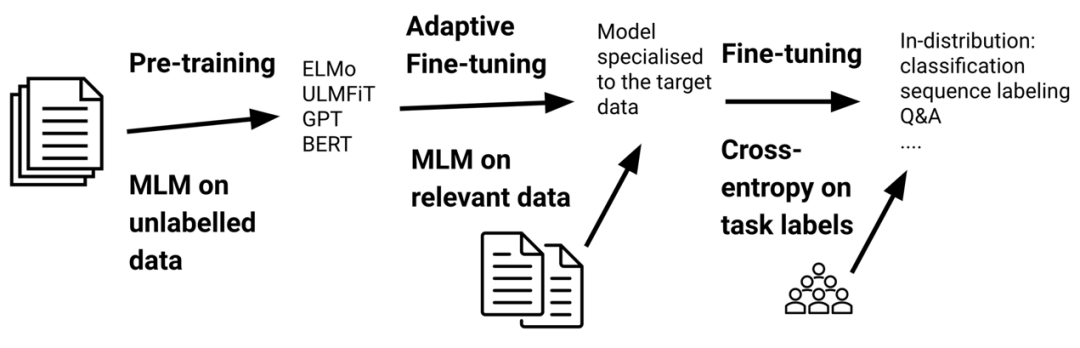
形式化来讲,给定由特征空间 一个特征空间上的边际概率分布 组成的目标域 ,其中 [1, 2],adaptive fine-tuning允许我们同时学习特征空间 目标数据分布 。
Adaptive fine-tuning的多种变体目前已经得到广泛应用,包括domain,task和language-adaptive fine-tuning,目标分别是让模型对目标域,目标任务或目标语言的数据进行拟合,并且最近已经应用在了最新的预训练模型中 [3, 4, 5]。
Adaptive fine-tuning模型为特定数据分布而设计,可以对其更好的建模。但是,它的特点决定了它很难成为通用的语言模型。所以adaptive fine-tuning在需要针对某单一领域(一个或多个任务)得到高性能时,是非常有效的。
02
Behavioural fine-tuning 行为微调
虽然adaptive fine-tuning让我们可以对模型做某些特殊分布 适应,但是它没有告诉我们任何直接相关于这个目标任务的信息。形式化来讲,一个目标任务 包括标签空间 ,一个先验分布 ,其中 ,还有一个条件概率分布 。所以,我们也许可以通过在相似的目标任务上fine-tuning来有效地训练一个模型,如下图所示。我们把这种设置叫做behavioural fine-tuning,因为与adaptive fine-tuning相比,它专注于学习有用的行为。
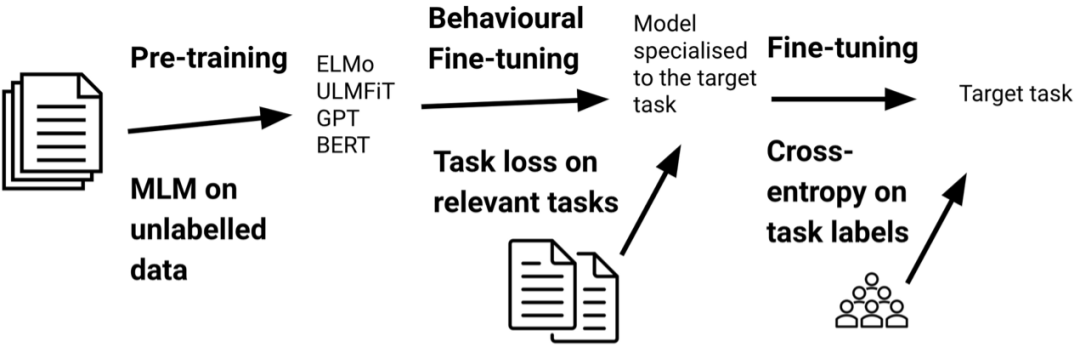
训练模型相关能力的一个途径是在特定任务fine-tuning之前,在相关的标注数据上做fine-tuning [6],这种方法也称为intermediate-task training。它在需要高级别推理能力的任务中表现最佳。使用有监督数据的Behavioural fine-tuning已经被用于训练模型的命名实体识别,语法分析,句法分析,问答等能力中 [7, 8, 9, 10, 11]。因为在这种高级别推理任务中,有监督数据通常难以获得。我们可以退而求其次,让模型以自监督训练的方式,学习到与下游任务相关的能力。比如对单词对齐的模型做fine-tuning,来学习到识别平行句子的能力 [12]。
另一种比较有效的方法是把目标任务套到masked language modelling(MLM)的框架中,基于此,[13] 使用基于中轴(pivot-based)的目标函数对情感域适应模型进行fine-tuning。其他一些工作提出类似用于fine-tuning的预训练任务:[14] 使用span selection任务做QA的预训练,[15] 通过few-shot learning,使用自动生成完形填空样式的多分类任务做预训练。
对adaptive和behavioural fine-tuning的区分主要在于考虑灌输到模型中的归纳偏置(inductive biases),以及它们是否与domain 或者task 的属性相关。区分domain和task的角色很重要,因为一个domain的信息经常通过有限的无标签数据来学习,而要获得更高的自然语言理解能力,通常需要超大规模的预训练数据。
然而,如果我们根据预训练目标来构造task,它和domain之间的区分会变得更模糊。一个MLM这样非常通用的预训练任务可能可以为学习 提供有用的信息,但是可能不包含对任务重要的所有训练信号。例如,使用MLM任务做预训练的模型难以建模否定命题,数字,或者命名实体 [16]。
数据增广也同样模糊了 和 的角色,它允许我们直接在数据中编码需要的能力。举例来说,通过对文本模型进行fine-tuning,把性别相关的单词替换为反性别的单词,会导致模型更倾向于性别偏见。
03
Parameter-efficient fine-tuning 参数有效的微调
如果一个模型需要在很多个场景下进行fine-tuning,如面对大量用户进行fine-tuning,为每个场景保存微调后的模型副本非常耗费算力等成本。因此,近期的工作主要关注点在保持模型大部分的参数固定,针对每个任务,对少量参数做fine-tuning。在实际应用中,这样可以只存储一个模型的大副本,存储多个根据具体任务进行修改的很小的模型副本。
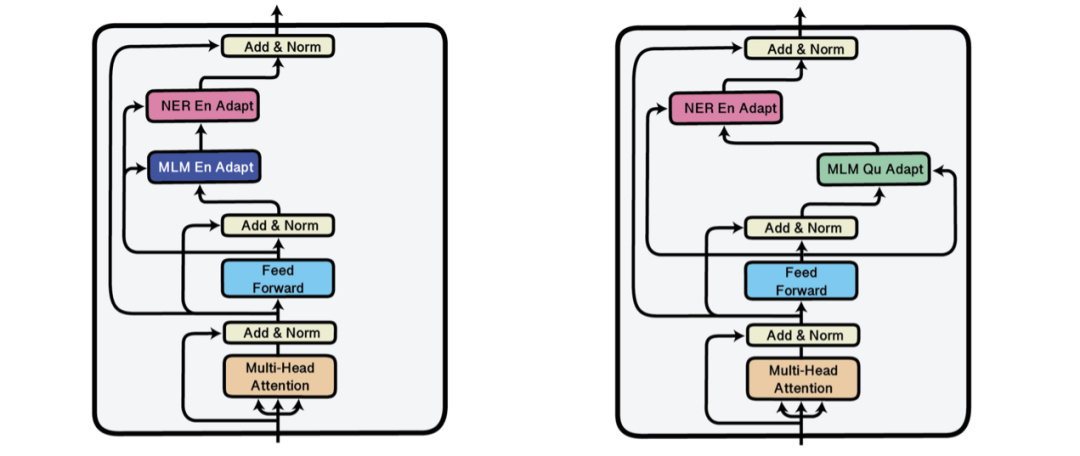
这类工作的第一种方法是基于adapter的方法 [17],它在预训练模型的各层之间加入了固定参数的bottleneck layers [18, 19]。Adapter构建了一个通用场景,例如在训练时存储多个checkpoint或像checkpoint averaging [20],snapshot ensembling [21]和temporal ensembling [22]这样空间效率更高的进阶技术。使用adapter,通用目标的模型可以高效地适应很多场景,例如跨语言的场景 [23]。通过把训练后的adapter进行堆叠,可以不在任何特定任务上fine-tuning的情况下,评估adaptive和behavioural fine-tuned adapter。这个场景如下图所示 [24],一个在NER任务上训练的task adapter叠在English(左)或者Quechua(右)语言的adapter上,adapter学习输出的表示,并且可以相互替换,实现zero-shot迁移。
Adapter在不改变底层参数的情况下修改模型的激活信息,另外一个方向的工作直接修改预训练的参数。为了对这类方法进行说明,我们可以把fine-tuning的过程看做学习如何对预训练模型的参数进行扰动。形式化来讲,为了获得一个fine-tuning之后模型的参数 ,其中 是模型的维度,我们学习一个任务特定的向量 ,用它来捕获如何改变预训练模型的参数 。Fine-tuning之后的参数就是把任务特定的排列应用到预训练参数的结果:
。
对于每个任务,我们可以存储一个预训练参数 的副本和一个任务参数 的副本,而不是存储每个任务的fine-tuning之后的全量参数 。如果我们可以更高效地参数化任务参数 ,这种做法成本会更低。基于此,[25] 把 作为稀疏向量来学习,[26] 用一个低维向量 乘上一个随机线性投影 代表 ,记为 。
另外,我们也可以只修改预训练参数的一个子集。一个经典的计算机视觉方法[27] 只对模型的最后一层做fine-tuning。 包含 层预训练的参数(即 ), 是第 层的参数, 和 也是类似的设置。所以只对模型的最后一层做fine-tuning就等价于:
。
虽然有工作证明了这种方法在NLP中效果不尽如人意 [28],但是还有其他的参数子集可以实现更有效的局部fine-tuning。[29] 在fine-tuning中,只调整模型的bias参数,也得到了很好的性能。
不同于前面的方向,还有一系列工作是在fine-tuning的时候对预训练模型的参数进行剪枝。这类方法依据不同的标准来修剪权重,如权重重要程度的零阶或者一阶信息[30] 。因为现在的机器对稀疏架构的支持有限,所以目前最好使用结构稀疏的方法,也就是对集中在一个有限集合中的层、矩阵或者向量进行更新。已经有工作证明预训练模型的最后几层在fine-tuning中的效果非常有限,可以随机重新初始化,甚至可以完全删除这些层 [31, 32, 33]。
修剪参数的方法重点在于减少task-specific模型的参数总量,而大多数其他方法关注减少可训练参数的数量,维护一个 的副本。最近使用这类方法的工作通常只训练大概0.5%的参数,就可以达到fine-tune全量参数一样的效果 [24, 25, 29]。
越来越多的证据表明,大规模预训练语言模型可以对NLP任务做很好的压缩 [34, 35, 26],这些工作的便利性,可用性以及成功经验,都让这些方法在实验中和实际场景的效果得到保证。
04
Text-to-text fine-tuning 文本到文本的微调
迁移学习的另一个发展方向是从MLM(如BERT,RoBERTa)向自回归模型(如T5,GPT-3)的转化。虽然这两种方法都可以给文本分配似然分数,但是自回归的语言模型更容易进行采样。相比之下,MLM模型通常只能在如完形填空任务的填空场景使用。
使用MLM模型做fine-tuning的标准方法是用随机初始化的task-specific head代替MLM模型使用的输出层来学习目标任务,也可以通过完形填空形式把任务重新定义为MLM,重用预训练模型的输出层。类似于这种方法,自回归的语言模型通常把目标任务定为text-to-text形式。在两种场景中,模型都可以从所有预训练知识中获得收益,不需要重新学习任何新参数,这样就提高了样本效率。
在不对参数fine-tune的极端情况下,构建一个关于预训练目标的目标任务框架,可以使用task-specific的提示(prompt)和少量任务样本来做zero-shot或者few-shot learning [36]。然而,即使可以做few-shot learning,它也不是最高效的使用这种模型方法 [37]。无更新的学习需要一个庞大的模型,因为需要完全依靠预训练模型的现有知识,而且它的可用信息量也受到上下文信息的限制,另外模型的提示信息也需要进行细致的设计。基于检索的强化方法可以减少外部知识的存储负担,而象征方法可以用于让模型学习task-specific的 [38]。即使预训练模型可以通过behavioural fine-tuning来做zero-shot learning,但是不经过fine-tuning的模型仍缺乏适应新任务的能力。
因此,在大多数情况下,最好的方法还是使用前面所描述的方法对模型参数的全集或者子集做fine-tuning。另外,预训练模型的生成能力也会越来越强。
05
Mitigating fine-tuning 缓解微调的不稳定性
对预训练模型做fine-tuning时存在一个问题,每次训练的性能可能会有比较大的差异,尤其是数据集的规模比较小的时候,这种差异可能会被放大。[39] 发现输出层的权重初始化和训练数据的顺序都会导致性能的变化,而且训练不稳定一般出现在训练的早期。也有一系列的工作试图缓解fine-tuning过程中的不稳定性[40, 41, 42, 43]。
根据前面的介绍,可以总结出一种降低fine-tuning不稳定性的方法:避免在数据规模比较小的目标任务上使用随机初始化的输出层,把目标任务规范为LM的形式或者在task-specific fine-tuning之前使用behavioural fine-tuning,对输出层做fine-tuning。因此,text-to-text模型在小规模数据上的fine-tuning性能更好,但是在few-shot场景会存在不稳定性,即对少量样本较为敏感。
随着现在的模型越来越多地应用于小样本学习这种具有挑战性的任务,对于变化样本仍然可以稳定fine-tune的研究也变得越来越重要,相信这样的工作还会不断涌现。
参考文献
[1] Pan, Sinno Jialin and Qiang Yang. “A Survey on Transfer Learning.” IEEE Transactions on Knowledge and Data Engineering 22 (2010): 1345-1359.
[2] Ruder, Sebastian. “Neural transfer learning for natural language processing.” (2019).
[3] Logeswaran, L. et al. “Zero-Shot Entity Linking by Reading Entity Descriptions.” ArXiv abs/1906.07348 (2019): n. pag.
[4] Han, Xiaochuang and Jacob Eisenstein. “Unsupervised Domain Adaptation of Contextualized Embeddings for Sequence Labeling.” EMNLP/IJCNLP (2019).
[5] Mehri, Shikib et al. “Pretraining Methods for Dialog Context Representation Learning.” ArXiv abs/1906.00414 (2019): n. pag.
[6] Phang, Jason et al. “Sentence Encoders on STILTs: Supplementary Training on Intermediate Labeled-data Tasks.” ArXiv abs/1811.01088 (2018): n. pag.
[7] Broscheit, Samuel. “Investigating Entity Knowledge in BERT with Simple Neural End-To-End Entity Linking.” ArXiv abs/2003.05473 (2019): n. pag.
[8] Arase, Yuki and Junichi Tsujii. “Transfer Fine-Tuning: A BERT Case Study.” EMNLP/IJCNLP (2019).
[9] Glavas, Goran and I. Vulić. “Is Supervised Syntactic Parsing Beneficial for Language Understanding? An Empirical Investigation.” ArXiv abs/2008.06788 (2020): n. pag.
[10] Garg, Siddhant et al. “TANDA: Transfer and Adapt Pre-Trained Transformer Models for Answer Sentence Selection.” ArXiv abs/1911.04118 (2020): n. pag.
[11] Khashabi, Daniel et al. “UnifiedQA: Crossing Format Boundaries With a Single QA System.” EMNLP (2020).
[12] Dou, Zi-Yi and Graham Neubig. “Word Alignment by Fine-tuning Embeddings on Parallel Corpora.” ArXiv abs/2101.08231 (2021): n. pag.
[13] Ben-David, Eyal et al. “PERL: Pivot-based Domain Adaptation for Pre-trained Deep Contextualized Embedding Models.” Transactions of the Association for Computational Linguistics 8 (2020): 504-521.
[14] Ram, Ori et al. “Few-Shot Question Answering by Pretraining Span Selection.” ArXiv abs/2101.00438 (2021): n. pag.
[15] Bansal, Trapit et al. “Self-Supervised Meta-Learning for Few-Shot Natural Language Classification Tasks.” EMNLP (2020).
[16] Rogers, Anna et al. “A Primer in BERTology: What We Know About How BERT Works.” Transactions of the Association for Computational Linguistics 8 (2020): 842-866.
[17] Rebuffi, Sylvestre-Alvise et al. “Learning multiple visual domains with residual adapters.” NIPS (2017).
[18] Houlsby, N. et al. “Parameter-Efficient Transfer Learning for NLP.” ICML (2019).
[19] Stickland, Asa Cooper and Iain Murray. “BERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning.” ICML (2019).
[20] Izmailov, Pavel et al. “Averaging Weights Leads to Wider Optima and Better Generalization.” ArXiv abs/1803.05407 (2018): n. pag.
[21] Huang, Gao et al. “Snapshot Ensembles: Train 1, get M for free.” ArXiv abs/1704.00109 (2017): n. pag.
[22] Laine, S. and Timo Aila. “Temporal Ensembling for Semi-Supervised Learning.” ArXiv abs/1610.02242 (2017): n. pag.
[23] Bapna, Ankur et al. “Simple, Scalable Adaptation for Neural Machine Translation.” EMNLP/IJCNLP (2019).
[24] Pfeiffer, Jonas et al. “MAD-X: An Adapter-based Framework for Multi-task Cross-lingual Transfer.” EMNLP (2020).
[25] Guo, Demi et al. “Parameter-Efficient Transfer Learning with Diff Pruning.” ArXiv abs/2012.07463 (2020): n. pag.
[26] Aghajanyan, Armen et al. “Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning.” ArXiv abs/2012.13255 (2020): n. pag.
[27] Donahue, J. et al. “DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition.” ICML (2014).
[28] Howard, J. and Sebastian Ruder. “Universal Language Model Fine-tuning for Text Classification.” ACL (2018).
[29] Ben-Zaken, Elad et al. “BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models.” (2020).
[30] Sanh, Victor et al. “Movement Pruning: Adaptive Sparsity by Fine-Tuning.” ArXiv abs/2005.07683 (2020): n. pag.
[31] Tamkin, A. et al. “Investigating Transferability in Pretrained Language Models.” EMNLP (2020).
[32] Zhang, Tianyi et al. “Revisiting Few-sample BERT Fine-tuning.” ArXiv abs/2006.05987 (2020): n. pag.
[33] Chung, Hyung Won et al. “Rethinking embedding coupling in pre-trained language models.” ArXiv abs/2010.12821 (2020): n. pag.
[34] Li, C. et al. “Measuring the Intrinsic Dimension of Objective Landscapes.” ArXiv abs/1804.08838 (2018): n. pag.
[35] Gordon, Mitchell A. et al. “Compressing BERT: Studying the Effects of Weight Pruning on Transfer Learning.” RepL4NLP@ACL (2020).
[36] Brown, T. et al. “Language Models are Few-Shot Learners.” ArXiv abs/2005.14165 (2020): n. pag.
[37] Schick, Timo and H. Schutze. “It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners.” ArXiv abs/2009.07118 (2020): n. pag.
[38] Awasthi, Abhijeet et al. “Learning from Rules Generalizing Labeled Exemplars.” ArXiv abs/2004.06025 (2020): n. pag.
[39] Dodge, Jesse et al. “Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping.” ArXiv abs/2002.06305 (2020): n. pag.
[40] Mosbach, Marius et al. “On the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselines.” ArXiv abs/2006.04884 (2020): n. pag.
[41] Zhu, C. et al. “FreeLB: Enhanced Adversarial Training for Natural Language Understanding.” arXiv: Computation and Language (2020): n. pag.
[42] Jiang, Haoming et al. “SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization.” ArXiv abs/1911.03437 (2020): n. pag.
[43] Aghajanyan, Armen et al. “Better Fine-Tuning by Reducing Representational Collapse.” ArXiv abs/2008.03156 (2020): n. pag.
- END -