
热门标签
热门文章
- 1git与github区别与简介_git和github的区别
- 2cmd命令行怎样运行python,在CMD命令行中运行python脚本的方法
- 3基于Python电商用户行为的数据分析、机器学习、可视化研究_利用机器学习算法分析用户行为数据
- 4【leetcode】n皇后问题--回溯法_n皇后问题回溯法
- 5基于SpringBoot+Vue+uniapp的明水县苹果网吧计费管理系统的详细设计和实现(源码+lw+部署文档+讲解等)_网吧计费系统 开源
- 6git访问失败,无法从git服务器下载代码或上传代码的解决办法_git 访问失败
- 7数据结构之二叉树(Binary-Tree)_数据结构中的树有哪些?介绍二叉树。
- 8JAVA华为面试题_在编译程序时所能指定的环境变量不包括
- 9手把手教你Anaconda安装虚拟环境配置yolov5_anaconda安装yolov5
- 102024金三银四Android面试心得,已拿到多个offer(1),大厂面试流程慢
当前位置: article > 正文
大数据计算分析技术:批处理、流计算、OLAP引擎_大数据流处理与批处理
作者:从前慢现在也慢 | 2024-06-15 07:55:25
赞
踩
大数据流处理与批处理
目录
二、流计算的代表:storm、spark streaming和flink
4.storm、spark streaming和flink 对比
- 大数据计算:指的是 面向业务需求 对海量数据的并行处理、分析和挖掘
- 大数据计算的手段:通过对海量数据分片、多个计算节点并行执行、实现高性能、高可靠的数据处理
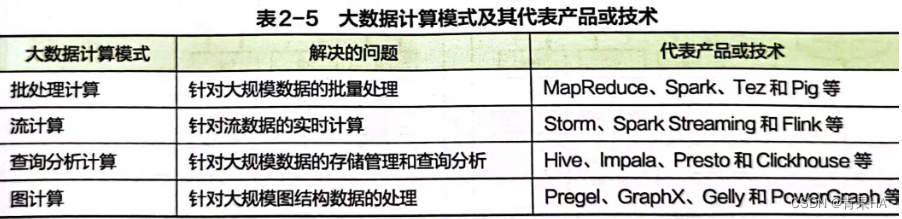
一、批处理的基石:MapReduce
1.工作流程
思想是:分而治之,将一个大的数据集,拆分成多个小数据集,然后再多台机器上并行map和reduce
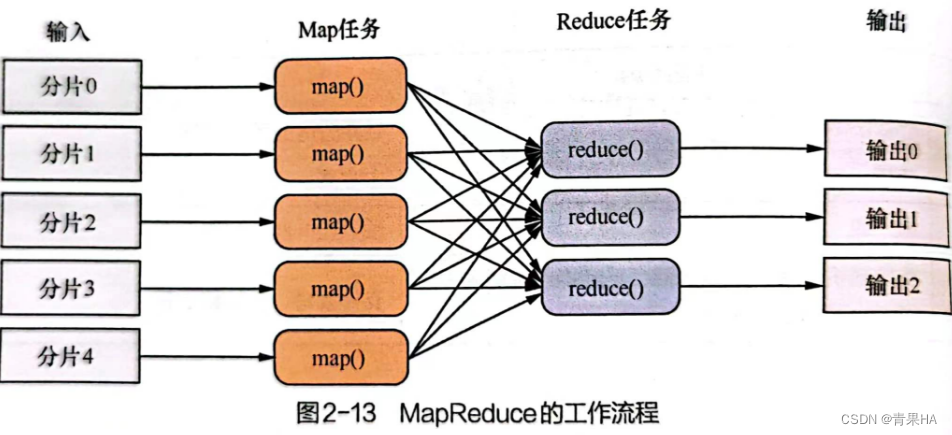
2.实例分析
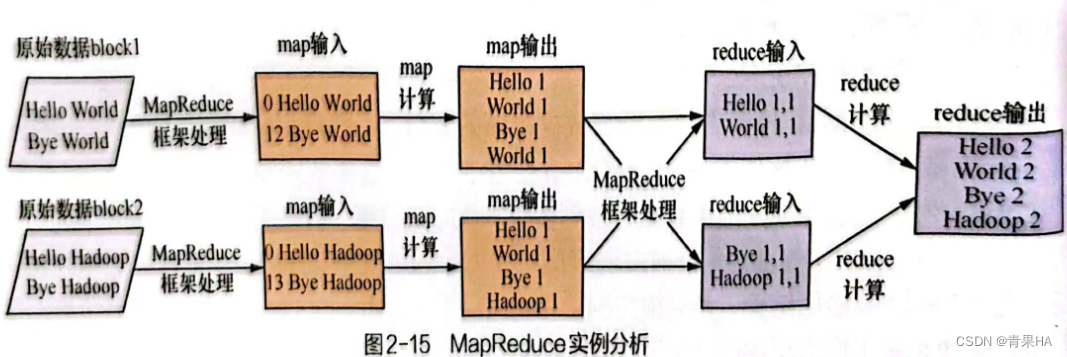
- 两个数据块block1和block2,MapReduce启动两个map进行处理,分别读入数据
- map函数对数据进行分词处理,输出<每个单词,1>
- MapReduce框架进行shuffle操作,相同的key发送到同一个reduce进程,将相同的key和value 合并成一个列表,作为reduce的输入
- reduce对1进行求和操作,得到每个单词的频次
二、流计算的代表:storm、spark streaming和flink
流计算:实时处理不同数据源、连续到达的流数据、分析处理输出有价值的分析结果
流计算特性:高性能、海量式、分布式、易用性、可靠性
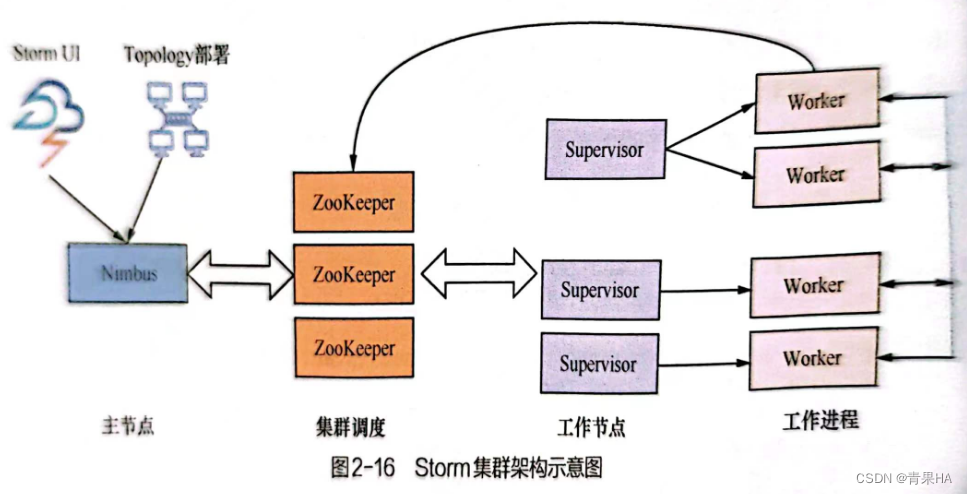
1.storm
- 遵循主从结构,由1个主节点、协调集群zookeeper和1个或多个工作节点组成
- 主节点:负责资源分配(向工作节点分配计算任务)、任务调度和监控工作节点的状态
- zookeeper:负责主节点和工作节点之间的 所有协调工作
- 工作节点:接受主节点的任务,启动和暂停工作进程
2.spark streaming
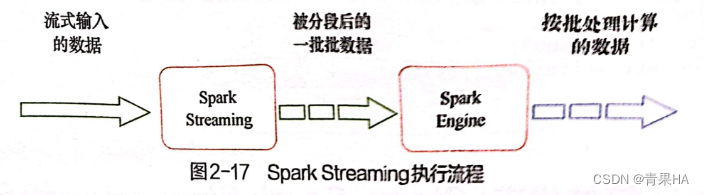
- 将实时输入的数据按照时间进行分段,一个时间段的数据合并在一起,当作一批数据,交给spark处理
- 分段时间足够段,每段的数据量就比较小,这样的话 spark engine 对数据的处理速度足够快
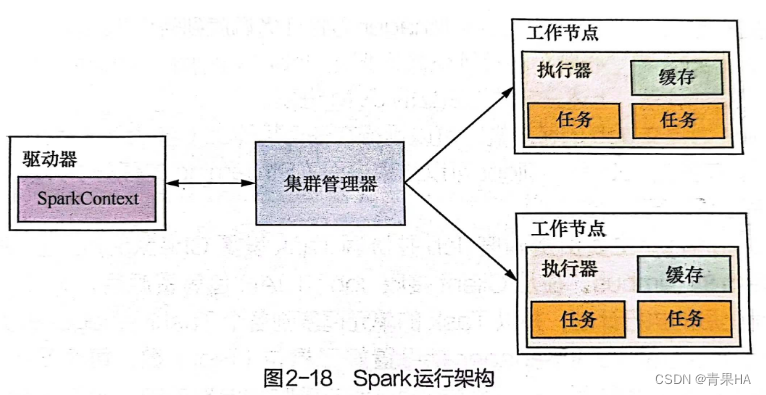
- 驱动器:运行应用的main()函数
- 集群管理器:资源管理器,是主节点控制整个集群,监控工作节点
- 工作节点:计算节点,启动执行
- 执行器:某个应用运行在工作节点上的一个进程
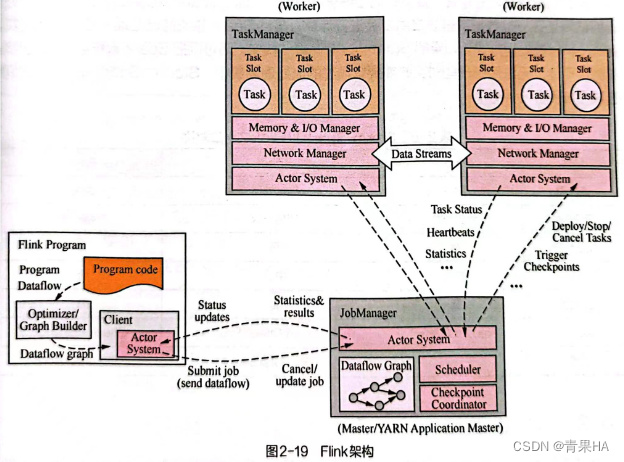
3.flink
- flink同时支持批处理和流计算
- client提交任务给jobManger,jobManger再将各个任务调度到taskManger去执行,taskManger将心跳和统计信息汇总给jobManger,taskManger之间以流的形式进行数据传输
- client:提交job的客户端,可以运行在任何机器上,只需要和jobManger环境打通即可,提交job后,可以结束进行并返回,也可以不结束进程直接结果返回
- jobManger:负责调度job,协调task设置checkpoint
- taskManger:启动的时候,设置好槽位(slot)数,每个slot只能启动一个线程task,从jobManger接受需要启动的task,并完成数据处理
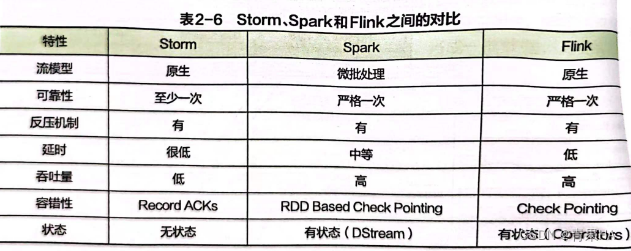
4.storm、spark streaming和flink 对比
三、OLAP引擎:Hive、Impala、Presto
准实时或实时的大规模数管理和查询分析技术
1.Hive
建立在Hadoop之上的数据仓库,本身不存储和处理数据,当将MapReduce作为执行引擎时,Hive通过自身组件把HiveQL语句转化成MapReduce任务,快速实现数据仓库的分析统计
1)Hive系统架构
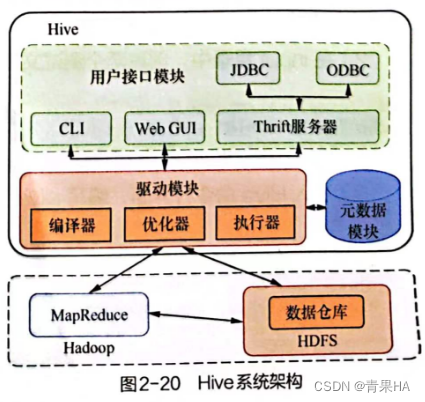
A. 用户接口模块:
a.用户可以直接使用Hive提供的CTL工具执行交互式的SQL语句
b.Hive提供了纯Java的JDBC驱动,使Java应用程序可以指定端口连接运行中的Hive服务器
c.用户可以通过web GUI即浏览器的方式输入SQL进行执行
B. 驱动模块:
包含编译器、优化器和执行器;对用户的输入内容进行解析、编译、计算优化,然后按照指定的步骤运行(启动MapReduce任务来执行)
C. 元数据模块:
存储在一个独立的关系型数据库中,通常使用Mysql或Derby数据库;元数据主要保存表模式和其他系统元数据,如表名称,表的列和属性,表的分区和属性及表属性和表中数据所在位置信息;
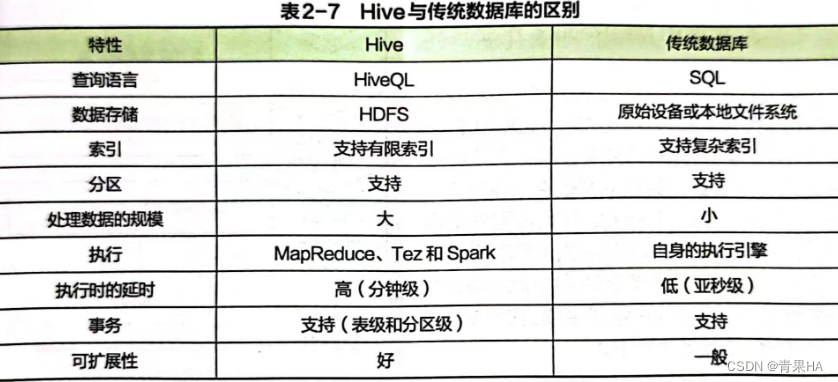
2)Hive和传统数据库的区别
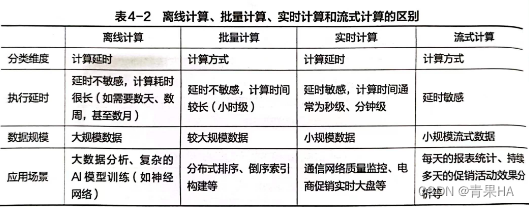
四 离线数据、批量计算、实时计算和流失计算的区别
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/721490
推荐阅读
相关标签

