
- 1java比较字符串大小写_java 字符串中判断字母大小写方法
- 2创建一个简单鸿蒙app项目_鸿蒙简单开发app实例代码
- 3深入理解计算机系统 CSAPP 家庭作业6.40
- 4【STM32HAL库学习】SysTick延时_hal库systick
- 5「五度易链」企业大数据API接口开放平台上线啦!
- 6【UE】AI行为树入门——以小白人跟踪玩家并攻击为例_ue ai行为树
- 7海云安荣登《嘶吼2023中国网络安全产业势能榜》 获评金融行业专精型安全厂商
- 8table() function
- 9105、基于STM32单片机倒车雷达超声波测距报警系统LCD1602设计(程序+原理图+PCB源文件+任务书+参考论文+开题报告+流程图+硬件设计资料+元器件清单等)_基于stm32单片机的停车雷达监测系统设计
- 10如何强制umount
code embedding研究系列二-基于AST的embedding_如何对控制流块进行embedding
赞
踩
Code Embedding系列 - AST embedding
在Embedding技术提出后,NLP得到了极大的提升,在上一篇中我们讨论了如何将embedding技术应用到SE(Software Engineering)领域。这对于源代码分析任务(克隆检测,bug检测等)有极大的意义,在上一篇中同样讨论了基于token的embedding方法,该方法将源代码词法分析后得到的token序列转化成向量表示,将源代码分析任务转化成token序列分析任务。而显然,这种token表示并没有考虑到程序包含丰富、明确和复杂的结构信息这一要点。因此,本文就讨论以下基于AST(抽象语法树)的embedding。
相关论文
1.Convolutional Neural Networks over Tree Structuresfor Programming Language Processing
这篇文章主要2个问题:
1.源代码分类
2.检测代码是否包含指定模式
为了解决这些问题,作者提出了一个叫TBCNN(基于树形结构的CNN)的网络架构。
关于TBCNN,论文中作者并没有给出github地址,不过我在github上搜到了一个可能的源码。
数据集
1.源代码分类:
数据主要采自于OJ系统,上面有很多道题目。每道题目都有许多学生的答案,把其中有效解答下载下来。下载了104道题目的答案,每一个答案相当于一个样本,标签是题目的ID(同一道题目的答案为同一个类别)。其中每个类别500个样本,总共52000个样本。
2.检测代码是否包含指定模式:
二分类任务,这里检测的模式是冒泡排序(作者认为冒泡排序是一个低效的算法),这里的任务就是检测一个源代码文本是否包含冒泡排序代码。这里作者随机从OJ上选择4000个作为非冒泡排序类别,而对于这4000个反类,作者随机从每个反类样本中用预写的冒泡排序片段替换掉原文本中的一个小片段来获得正样本,这样正例反例各4000。
用到的工具
pycparser:用来解析源代码
整体架构
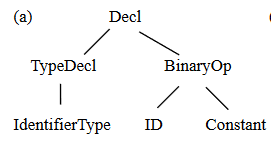
对于int a=b+3;,它生成的AST如下:
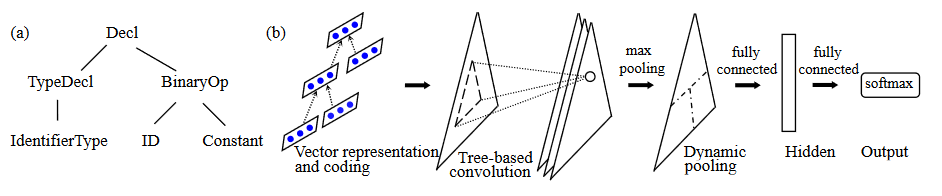
整个处理过程可以用下图表示:
AST结点的向量化表示
AST结点层次聚类如下图所示:

相似的结点应该有相似的向量化表示,While For与控制流相关。
在训练过程前,首先会为结点的token生成预训练向量(具操作我也不太明白)。
若n为叶子结点,则n的向量为预训练的token向量。
若n为非叶子结点,则n的向量由2部分构成,表示如下:
v e c ( n ) = W c o m b 1 ⋅ v e c ( t o k e n n ) + W c o m b 2 ⋅ t a n h ( ∑ i l i ⋅ W c o d e , i ⋅ v e c ( c i ) + b c o d e ) vec(n) = W_{comb1} \cdot vec(token_n) + W_{comb2} \cdot tanh( \sum_i l_i \cdot W_{code,i} \cdot vec(c_i) + b_{code}) vec(n)=Wcomb1⋅vec(tokenn)+Wcomb2⋅tanh(i∑li⋅Wcode,i⋅vec(ci)+bcode)
其中 v e c ( t o k e n n ) vec(token_n) vec(tokenn) 表示结点n的预训练token向量, v e c ( c i ) vec(c_i) vec(ci) 表示第i个叶子结点的向量。
其中对于每个结点p的向量 v e c ( p ) vec(p) vec(p) ,其维度为 N f N_f Nf
W c o d e , i W_{code,i} Wcode,i 为 N f × N f N_f \times N_f Nf×Nf 矩阵,对应着第i个子节点的权重矩阵。
l i = c i 的 叶 子 结 点 个 数 n 的 叶 子 结 点 个 数 l_i = \frac{c_i的叶子结点个数}{n的叶子结点个数} li=n的叶子结点个数ci的叶子结点个数 ,为第i个子节点的权重系数。
W c o m b 1 , W c o m b 2 W_{comb1}, W_{comb2} Wcomb1,Wcomb2 均为 N f × N f N_f \times N_f Nf×Nf 矩阵。用于结合n的token向量和子节点向量。
树形卷积
假设一个AST有n个结点,分别表示为
x
1
,
x
2
,
x
3
,
.
.
.
,
x
n
x_1, x_2, x_3,..., x_n
x1,x2,x3,...,xn ,那么树形卷积的输出y为:
y
=
t
a
n
h
(
∑
i
=
1
n
W
c
o
n
v
,
i
⋅
v
e
c
(
x
i
)
+
b
c
o
n
v
)
y = tanh(\sum_{i = 1}^{n} W_{conv,i} \cdot vec(x_i) + b_{conv})
y=tanh(i=1∑nWconv,i⋅vec(xi)+bconv)
y
,
b
c
o
n
v
y,b_{conv}
y,bconv 均为
N
c
N_c
Nc 维度的向量。
W
c
o
n
v
,
i
W_{conv,i}
Wconv,i 为
N
c
×
N
f
N_c \times N_f
Nc×Nf 的向量。
二叉树化
之前的计算过程有一个最大的问题就是由于树的子树长度不确定导致模型参数可能很大,这里作者把AST当作成一颗“二叉树”处理(过程可能和二叉树和树的转化类似)。i的取值只能为1,2。
则卷积层参数
W
c
o
n
v
,
i
W_{conv,i}
Wconv,i 可以转化为
W
c
o
n
v
t
,
W
c
o
n
v
l
,
W
c
o
n
v
r
W_{conv}^t, W_{conv}^l, W_{conv}^r
Wconvt,Wconvl,Wconvr(整个网络共用这三个参数
t
,
l
,
s
t,l,s
t,l,s 分别表示top, left, right)。
而编码层的参数
W
c
o
n
v
,
i
W_{conv,i}
Wconv,i 则是
W
c
o
d
e
l
,
W
c
o
d
e
r
W_{code}^l, W_{code}^r
Wcodel,Wcoder
关于二叉树化后的计算过程论文中没提到,根据自己的推测转化过程可能如下所示(可能有误,欢迎指正)
非叶子结点的编码操作可以转化为:
v
e
c
(
n
)
=
W
c
o
m
b
1
⋅
v
e
c
(
t
o
k
e
n
n
)
+
W
c
o
m
b
2
⋅
t
a
n
h
(
(
l
l
e
f
t
⋅
W
c
o
d
e
l
+
l
r
i
g
h
t
⋅
W
c
o
d
e
r
)
⋅
v
e
c
(
c
i
)
+
b
c
o
d
e
)
vec(n) = W_{comb1} \cdot vec(token_n) + W_{comb2} \cdot tanh(( l_{left} \cdot W_{code}^l + l_{right} \cdot W_{code}^r) \cdot vec(c_i) + b_{code})
vec(n)=Wcomb1⋅vec(tokenn)+Wcomb2⋅tanh((lleft⋅Wcodel+lright⋅Wcoder)⋅vec(ci)+bcode)
卷积操作如下图表示:
 可以修正为:
可以修正为:
y
=
t
a
n
h
(
∑
i
=
1
n
(
η
i
t
⋅
W
c
o
n
v
t
+
η
i
l
⋅
W
c
o
n
v
l
+
η
i
r
⋅
W
c
o
n
v
r
)
⋅
v
e
c
(
x
i
)
+
b
c
o
n
v
)
y = tanh(\sum_{i = 1}^{n} (\eta_i^t \cdot W_{conv}^t + \eta_i^l \cdot W_{conv}^l +\eta_i^r \cdot W_{conv}^r ) \cdot vec(x_i) +b_{conv})
y=tanh(i=1∑n(ηit⋅Wconvt+ηil⋅Wconvl+ηir⋅Wconvr)⋅vec(xi)+bconv)
其中参数
η
i
t
,
η
i
l
,
η
i
r
\eta_i^t, \eta_i^l,\eta_i^r
ηit,ηil,ηir 权重参数,具体计算过程参考论文。
池化和全连接
这里的计算和普通的CNN相同,但论文中并没有提到公式。
模型参数
编码层: W c o d e l , W c o d e r , b c o d e W_{code}^l, W_{code}^r, b_{code} Wcodel,Wcoder,bcode
卷积层: W c o n v t , W c o n v l , W c o n v r , b c o n v W_{conv}^t, W_{conv}^l, W_{conv}^r, b_{conv} Wconvt,Wconvl,Wconvr,bconv
全连接层: W h i d , W o u t , b h i d , b o u t W_{hid}, W_{out}, b_{hid}, b_{out} Whid,Wout,bhid,bout
关于权重初始化参考论文
实验结果
功能分类(检测完成哪个题目的作业):
| Method | Test Accuracy(%) |
|---|---|
| linear SVM+BoW | 52.0 |
| RBF SVM+BoW | 83.9 |
| linear SVM+BoT | 72.5 |
| RBF SVM+BoT | 88.2 |
| DNN+BoW | 76.0 |
| DNN+BoT | 89.7 |
| Vector avg. | 53.2 |
| RNN | 84.8 |
| TBCNN | 94.0 |
检测是否包含指定模式(这里的模式是冒泡排序):
| Classifier | Features | Accuracy |
|---|---|---|
| Rand/majority | - | 50.0 |
| RBF SVM | Bag-of-words | 62.3 |
| TBCNN | Learned | 89.1 |
2.Deep Learning Code Fragments for Code Clone Detection
这篇文章也是讨论的是克隆检测,而这篇论文中讨论了4种不同类型的检测,4种类型可以参考这篇博客:代码克隆的类别总结
整体架构
 架构整个了词法分析生成的token序列和句法分析生成的AST。
架构整个了词法分析生成的token序列和句法分析生成的AST。
1.关于token序列部分,作者采用了普通的RNN来分类:

2.关于AST部分:
(a).首先把AST转化为满二叉树(full binary tree是满二叉树,complete binary tree是完全二叉树)
转换步骤:
(1)删除matadata(JavaDoc等注释),空的类定义,空的block等等(删除掉度为1的结点,具体参考论文)
(2)编写一个文法(这个牛逼了)(把度多于2的结点的度变为2,具体参考论文)
比如:
〈
I
f
S
t
a
t
e
m
e
n
t
〉
:
:
=
〈
E
x
p
r
e
s
s
i
o
n
〉
∣
〈
B
r
a
n
c
h
e
s
〉
〈IfStatement〉::=〈Expression〉 |〈Branches〉
〈IfStatement〉::=〈Expression〉∣〈Branches〉
〈 B r a n c h e s 〉 : : = 〈 S t a t e m e n t 〉 ∣ 〈 S t a t e m e n t 〉 〈Branches〉::=〈Statement〉|〈Statement〉 〈Branches〉::=〈Statement〉∣〈Statement〉
〈 S t a t e m e n t L i s t 〉 : : = 〈 S t a t e m e n t 〉 ∣ 〈 S t a t e m e n t L i s t 〉 〈StatementList〉::=〈Statement〉|〈StatementList〉 〈StatementList〉::=〈Statement〉∣〈StatementList〉
(3)步骤(2)处理的AST会遗留一些度为1的结点,之后还会有一次自顶向下遍历AST的过程,如果遇到度为1的结点,则将它和它的子节点合并,非叶子结点的Type可能会有如下取值,在合并时,新结点取值是父节点和子结点按照下表的优先级来定。

转化后的满二叉树假如有k个那么叶子结点,那么就会有k-1个非叶子结点,给这颗满二叉树编码需要k-1个矩阵-向量乘法。
关于剩下的部分,比如如何编码结点,论文里提到了一种贪心策略(表示看不懂)。不过作者也没有给出如何用RvNN(不是RNN)来编码满二叉树化后的AST。
数据集和工具
作者用ANTLR来把源代码解析为token,然后用RNNLM来训练RNN模型。
其次,用Eclipse Java development tools来处理AST,这部分作者也开源了。
关于向量化表示,作者并没有提到别的信息。
用到的数据来自一些开源项目,统计信息如下:
| 项目 | Files | LOC | Tokens | 词表大小 |
|---|---|---|---|---|
| ANTLR 4 | 514 | 104,225 | 701,807 | 5,826 |
| Apache Ant 1.9.6 | 1,218 | 136,352 | 888,424 | 16,029 |
| ArgoUML 0.34 | 1,908 | 177,493 | 1,172,058 | 17,205 |
| CAROL 2.0.5 | 184 | 12,022 | 80,947 | 2,210 |
| dnsjava 2.0.0 | 196 | 24,660 | 169,219 | 3,012 |
| Hibernate 2 | 555 | 51,499 | 365,256 | 5,850 |
| JDK 1.4.2 | 4,129 | 562,120 | 3,512,807 | 45,107 |
| JHotDraw 6 | 984 | 58,130 | 377,652 | 4,803 |
3.A Novel Neural Source Code Representationasedon Abstract Syntax Tree
关于这篇文章的详细解读,这位大佬写的比较详细(A Novel Neural Source Code Representation based on Abstract Syntax Tree–ICSE2019)。我就简单说说。
这篇文章主要的任务是:
1.程序分类(和TBCNN一样)
2.克隆检测
数据集和工具
源代码解析工具:
pycparser(C语言)
javalang(Java)
数据集:
OJ数据集(TBCNN中用到的,104个类,C语言,代码分类)
BigCloneBench(简称BCB,Java,克隆检测)
数据集统计信息如下:
1.代码分类:
| 数据集 | OJ |
|---|---|
| 总数 | 52,000 |
| 类别 | 104 |
| 最大token数 | 8737 |
| 平均token数 | 245 |
| AST最大深度 | 76 |
| AST平均深度 | 13.3 |
| 最大AST结点数 | 7027 |
| 平均AST结点数 | 7027 |
2.代码克隆
| 数据集 | OJ | BCB |
|---|---|---|
| 代码片段总数 | 7,500 | 59,688 |
| True Clone Pairs | 6.6% | 95.7% |
| 最大token数 | 2,271 | 16,253 |
| 平均token数 | 244 | 227 |
| AST最大深度 | 60 | 192 |
| AST平均深度 | 13.2 | 9.9 |
| 最大AST结点数 | 1,624 | 15,217 |
| 平均AST结点数 | 192 | 206 |
AST的转化
作者将研究成果命名为ASTNN(作者已开源)
传统的基于AST的方法有如下缺点:
1.梯度消失问题。可能会丢失长期上下文信息。
2.直接AST转化为满二叉树,破坏了源代码原有的语法结构,而且转换的过程会增加AST的高度,进一步削弱了神经模型捕捉更真实和复杂语义的能力。
1.AST的
对于如下Java代码
static public String readText(final String path) throw Exception {
final InputStream stream = FileLocator.getAsStream(path);
final StringBuilder sb = new StringBuilder();
try(BufferedReader reader = new BufferedReader(new InputStreamReader(stream))){
String line;
while((line = reader.readLine()) != null){
sb.append(line).append("\n");
}
}
return sb.toString();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
作者将它的AST转化成一个ST-Tree列表(列表中的每个元素是ST-Tree)
ST-Tree(Statement Tree)的概念可以参考原论文(写的有点绕,看下图可能会更明白)
总体过程如下:

ST-Tree的向量化
作者提出了一个基于RvNN(不是RNN)的encoder来将ST-Tree向量化,单个ST-Tree的向量化可分为3步,这里第 t t t 个ST-Tree的向量用 e t e_t et 表示, 假设第 t t t 个ST-Tree下包含 N N N 个AST节点。
首先AST中包含很多syntactic symbol。
1.作者首先用前序遍历的方式遍历AST,将前序遍历获得的token列表用word2vec训练出一个初始的token embedding,用来做ST-Tree embedding的初始参数。
2.用RvNN向量化,下面说下详细过程

用
n
n
n 表示一个非叶子结点,
C
C
C 表示其子节点数量
1.首先得到
n
n
n 的lexical vector
v
n
v_n
vn (word2vec训练得到,相当于embedding)
v
n
=
W
e
T
⋅
x
n
v_n = W_e^T \cdot x_n
vn=WeT⋅xn
其中 x n x_n xn 是一个one-hot向量, W e W_e We 是一个 ∣ V ∣ × d |V| \times d ∣V∣×d 的矩阵, V V V 是token的词表, d d d 是embedding的维度。
2.之后用如下公式计算
n
n
n 的隐层向量表示
h
h
h:
h
n
=
σ
(
W
n
T
⋅
v
n
+
∑
i
∈
[
1
,
C
]
h
i
+
b
n
)
h_n = \sigma(W_n^T \cdot v_n + \sum_{i \in [1,C]} h_i + b_n)
hn=σ(WnT⋅vn+i∈[1,C]∑hi+bn)
其中 W n W_n Wn 是一个 d × k d \times k d×k 的矩阵, h i h_i hi 是结点 n n n 的第i个子节点的隐层向量表示, 维度为 k k k, 而 σ \sigma σ 是激活函数(可以为 t a n h tanh tanh 或者其它的函数)
3.之后,自底向上计算该ST-Tree每个结点的隐层向量 h h h 。将 N N N 个结点的向量 h h h push到一个栈 S S S 中,用max pooling。计算过程如下:
e t = [ m a x ( h i 1 ) , . . . , m a x ( h i k ) ] , i = 1 , . . . , N e_t = [ max(h_{i1}), ... , max(h_{ik}) ], i = 1, ... , N et=[max(hi1),...,max(hik)],i=1,...,N
相当于把一个 N × k N \times k N×k 维的向量 压缩成一个 k k k 维向量。
至此,ST-Tree结点的编码过程完成。
不过这个算法并不适用于批处理(Batch)的情况,每个结点的子结点数量可能有所不同,作者这里提出了一个批处理算法,这里不太明白。
ST-Tree列表的向量化
一个code片段会被转化成一个ST-Tree列表,所以code的最终向量表示就是ST-Tree列表的向量表示,前面已经得到了单个ST-Tree的向量表示
[
e
1
,
e
2
,
e
3
,
.
.
.
,
e
t
,
.
.
.
,
e
T
]
,
t
∈
[
1
,
T
]
[e_1,e_2,e_3,...,e_t,...,e_T], t \in [1,T]
[e1,e2,e3,...,et,...,eT],t∈[1,T] ,之后通过一个双向GRU对该序列进行处理。
 公式如下:
公式如下:
r
t
=
σ
(
W
r
T
⋅
e
t
+
U
r
T
⋅
h
t
−
1
+
b
r
)
r_t = \sigma(W_r^T \cdot e_t + U_r^T \cdot h_{t-1} + b_r)
rt=σ(WrT⋅et+UrT⋅ht−1+br)
z t = σ ( W z T ⋅ e t + U z T ⋅ h t − 1 + b z ) z_t = \sigma(W_z^T \cdot e_t + U_z^T \cdot h_{t-1} + b_z) zt=σ(WzT⋅et+UzT⋅ht−1+bz)
h ~ t = t a n h ( W h T ⋅ e t + r t ⊙ ( U h T ⋅ h t − 1 ) + b h ) \widetilde h_t = tanh(W_h^T \cdot e_t + r_t \odot (U_h^T \cdot h_{t-1}) + b_h) h t=tanh(WhT⋅et+rt⊙(UhT⋅ht−1)+bh)
h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ~ t h_t = (1 - z_t) \odot h_{t - 1} + z_t \odot \widetilde h_t ht=(1−zt)⊙ht−1+zt⊙h t
e
t
,
h
t
e_t, h_t
et,ht 是
k
k
k 维向量
W
r
,
W
z
,
W
h
,
U
r
,
U
z
,
U
h
W_r , W_z, W_h , U_r , U_z , U_h
Wr,Wz,Wh,Ur,Uz,Uh 是
k
×
m
k \times m
k×m 维向量。
r
t
,
z
t
r_t, z_t
rt,zt 是
m
m
m 维向量。
h t h_t ht 包括2部分, [ h t → , h t ← ] [h_t^\rightarrow, h_t^\leftarrow] [ht→,ht←], 每部分是一个 m m m 维向量,所以最终是一个 2 m 2m 2m 维的向量。
最终 [ h 1 , . . , h t , . . . , h T ] [h_1,..,h_t,...,h_T] [h1,..,ht,...,hT] 构成了一个 2 m × T 2m \times T 2m×T 维的向量,对其进行最大池化,得到code最终的向量表示 r r r,一个 2 m 2m 2m 维的向量。
在不同任务上的应用
1.代码分类任务:
最终假如类别数量为M,增加一个全连接层
W
o
W_o
Wo,一个
2
m
×
M
2m \times M
2m×M的矩阵。
输出
x
x
x 为:
x = W o ⋅ r + b o x = W_o \cdot r + b_o x=Wo⋅r+bo
x是1个 M M M 维向量
p r e d i c t i o n = a r g m a x ( x i ) , i = 1 , ⋅ ⋅ ⋅ , M prediction = argmax(x_i),i=1,···,M prediction=argmax(xi),i=1,⋅⋅⋅,M
损失函数用的是交叉熵损失
2.代码克隆检测:
计算过程如下:
假设有2个code vector
r
1
,
r
2
r_1, r_2
r1,r2
r = ∣ r 1 − r 2 ∣ r = | r1 - r2 | r=∣r1−r2∣
x = W o ⋅ r + b o x = W_o \cdot r + b_o x=Wo⋅r+bo
y = s i g m o i d ( x ) y =sigmoid(x) y=sigmoid(x)
p
r
e
d
i
c
t
i
o
n
=
{
T
r
u
e
p > δ
F
a
l
s
e
p <= δ
prediction =
δ是设置的阈值
实验结果(baseline参考论文,不列举了)
代码分类:

代码克隆(T1,T2,T3,T4是克隆的类别):
BCB数据集:
 OJ数据集:
OJ数据集:

参考文献
参考博客
A Novel Neural Source Code Representation based on Abstract Syntax Tree–ICSE2019

