
- 1如何看待2020校招数据分析岗位招聘情况?
- 2pytorch安装超详细教程(Win10考虑CUDA&python版本,含各种报错情况)_win10安装pytorch
- 3ZYNQ学习笔记——13_AXI接口简介_手机接口axi
- 4Github 上 Star 数最多的大模型应用基础服务 Dify 深度解读(一)_dify源码解析
- 5使用MaxKB添加本地部署的Ollama大语言模型搭建智能聊天系统_maxkb ollama
- 6华为耗时五年研发的国产编程语言,到底是不是套壳?
- 7IPsec中IKE与ISAKMP过程分析(快速模式-消息3)_国密isakmp协议 分片
- 8图鸟UI vue3:基于Vue3和UniApp的酷炫简洁UI框架_tuniaoui
- 9Sonar代码规则之TOP30详解_string literals should not be duplicated
- 10基于Python的图书借阅推荐系统源码毕业设计_基于python的图书推荐系统毕业设计
简单介绍ES中的索引存储类型_es的存储类型
赞
踩
老铁们好,我是V,今天我们简单聊聊ES中的索引存储类型
支持的存储类型
目前ES中主要支持以下几种存储类型
fs
默认文件系统实现。这将根据操作环境选择最佳实施,目前会默认启用hybridfs
simplefs
Simple FS 类型是SimpleFsDirectory使用随机访问文件的文件系统存储(映射到 Lucene)的直接实现。这种实现的并发性能很差(多个线程会成为瓶颈),并且禁用了堆内存使用的一些优化。基本上使用的较少
niofs
NIO FS 类型使用 NIO 将分片索引存储在文件系统上(映射到 Lucene NIOFSDirectory)。它允许多个线程同时读取同一个文件。但是不建议在 Windows 上使用,因为在window环境下Java 实现中存在一些错误,并且禁用了堆内存使用的某些优化。
mmapfs
MMap FS 类型通过将文件映射到内存 ( MMapDirectorymmap) 将分片索引存储在文件系统上(映射到 Lucene)。内存映射占用进程中虚拟内存地址空间的一部分,其大小等于被映射文件的大小。在使用此类之前,请确保您已允许了足够的 虚拟地址空间。
hybridfs
该类型是niofs和mmaps的混合体,它根据读取访问模式为每种类型的文件选择最佳的文件系统类型。目前只有 Lucene 术语词典、规范和文档值文件是内存映射的。所有其他文件均使用 NIOFSDirectory 打开。和mmapfs类似,要确保你已允许了足够的 虚拟地址空间。
如何修改存储类型
修改存储类型首先需要关闭索引,然后修改存储类型后再打开索引
POST /xxx/_close
PUT /xxx/_settings
{
"index.store.type": "niofs"
}
POST /xxx/_open
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
存储类型源码解析
决定索引使用哪种存储类型的代码如下:
org.elasticsearch.index.store.FsDirectoryFactory#newFSDirectory
protected Directory newFSDirectory(Path location, LockFactory lockFactory, IndexSettings indexSettings) throws IOException { final String storeType = indexSettings.getSettings().get(IndexModule.INDEX_STORE_TYPE_SETTING.getKey(), IndexModule.Type.FS.getSettingsKey()); IndexModule.Type type; if (IndexModule.Type.FS.match(storeType)) { type = IndexModule.defaultStoreType(IndexModule.NODE_STORE_ALLOW_MMAP.get(indexSettings.getNodeSettings())); } else { type = IndexModule.Type.fromSettingsKey(storeType); } Set<String> preLoadExtensions = new HashSet<>( indexSettings.getValue(IndexModule.INDEX_STORE_PRE_LOAD_SETTING)); switch (type) { case HYBRIDFS: // Use Lucene defaults final FSDirectory primaryDirectory = FSDirectory.open(location, lockFactory); if (primaryDirectory instanceof MMapDirectory) { MMapDirectory mMapDirectory = (MMapDirectory) primaryDirectory; return new HybridDirectory(lockFactory, setPreload(mMapDirectory, lockFactory, preLoadExtensions)); } else { return primaryDirectory; } case MMAPFS: return setPreload(new MMapDirectory(location, lockFactory), lockFactory, preLoadExtensions); case SIMPLEFS: return new SimpleFSDirectory(location, lockFactory); case NIOFS: return new NIOFSDirectory(location, lockFactory); default: throw new AssertionError("unexpected built-in store type [" + type + "]"); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
当index.store.type为空、或者fs或者hybridfs在linux环境下都会选择hybridfs,即混合使用
niofs和mmapfs
所以上面看似有很多种类型,其实fs和hybridfs都是基于niofs和mmapfs来实现的,而simplefs基本上因为性能问题没有人使用,所以我们着重介绍下niofs和mmapfs实现。
niofs
niofs的实现是org.apache.lucene.store.NIOFSDirectory
niofs如何获取ByteBuffer
niofs对外提供的ByteBuffer是HeapByteBuffer
流程图
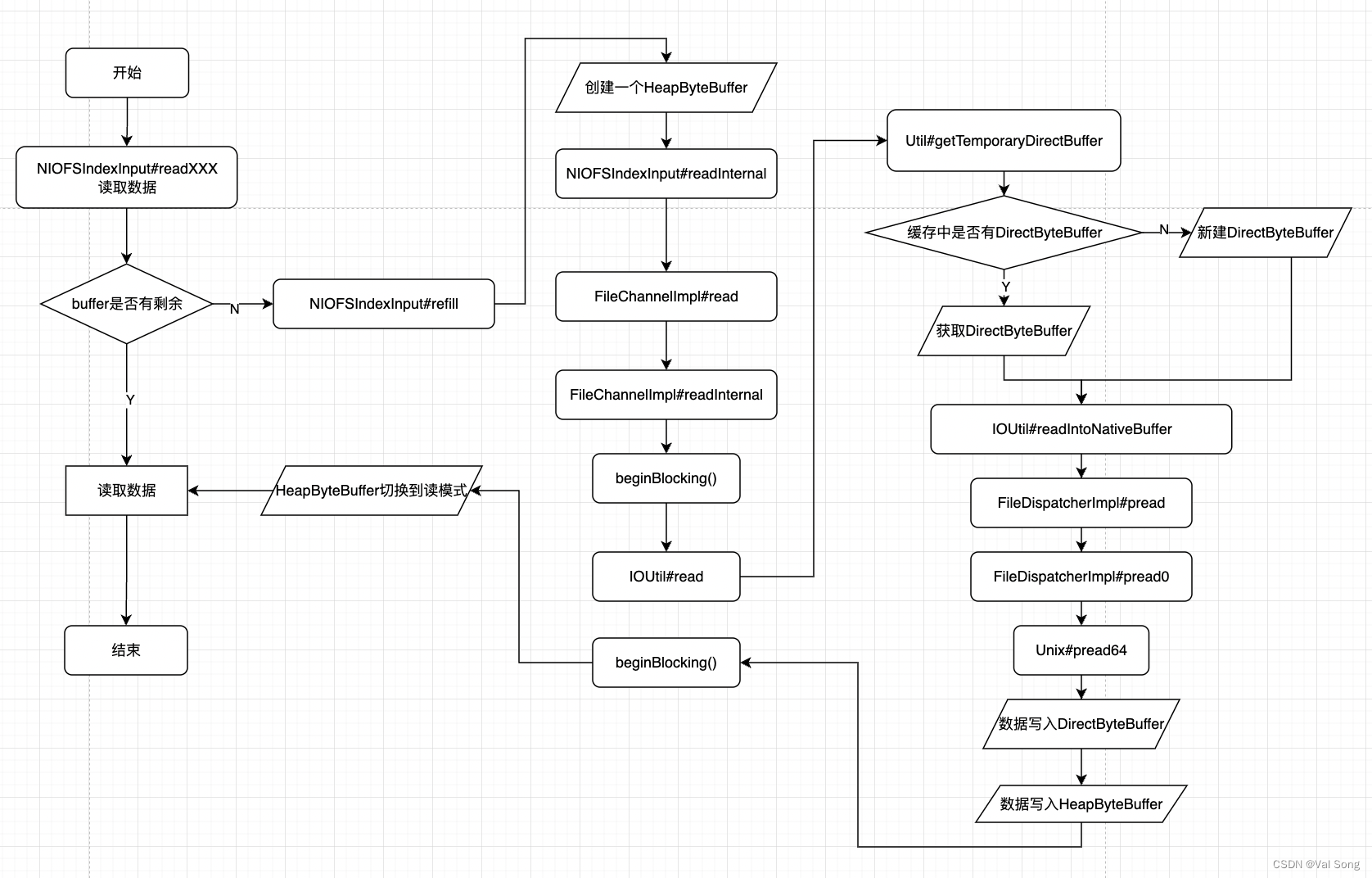
存储类型打开后返回一个IndexInput供其他模块读取数据
# org.apache.lucene.store.NIOFSDirectory#openInput @Override public IndexInput openInput(String name, IOContext context) throws IOException { ensureOpen(); ensureCanRead(name); Path path = getDirectory().resolve(name); FileChannel fc = FileChannel.open(path, StandardOpenOption.READ); boolean success = false; try { final NIOFSIndexInput indexInput = new NIOFSIndexInput("NIOFSIndexInput(path=\"" + path + "\")", fc, context); success = true; return indexInput; } finally { if (success == false) { IOUtils.closeWhileHandlingException(fc); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
IndexInput的实现是NIOFSIndexInput
其中主要包含一个FileChannel、是否克隆、开始坐标和结束坐标
static final class NIOFSIndexInput extends BufferedIndexInput {
/**
* The maximum chunk size for reads of 16384 bytes.
*/
private static final int CHUNK_SIZE = 16384;
/** the file channel we will read from */
protected final FileChannel channel;
/** is this instance a clone and hence does not own the file to close it */
boolean isClone = false;
/** start offset: non-zero in the slice case */
protected final long off;
/** end offset (start+length) */
protected final long end;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
父类BufferedIndexInput中的buffer才是真正对外提供数据的对象
public abstract class BufferedIndexInput extends IndexInput implements RandomAccessInput { private static final ByteBuffer EMPTY_BYTEBUFFER = ByteBuffer.allocate(0); /** Default buffer size set to {@value #BUFFER_SIZE}. */ public static final int BUFFER_SIZE = 1024; /** Minimum buffer size allowed */ public static final int MIN_BUFFER_SIZE = 8; // The normal read buffer size defaults to 1024, but // increasing this during merging seems to yield // performance gains. However we don't want to increase // it too much because there are quite a few // BufferedIndexInputs created during merging. See // LUCENE-888 for details. /** * A buffer size for merges set to {@value #MERGE_BUFFER_SIZE}. */ public static final int MERGE_BUFFER_SIZE = 4096; private int bufferSize = BUFFER_SIZE; private ByteBuffer buffer = EMPTY_BYTEBUFFER; private long bufferStart = 0; // position in file of buffer ... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
其他模块会调用NIOFSIndexInput的父类BufferedIndexInput的readByte readLong readInt等方法获取数据,而这些方法又是调用内部的buffer来获取数据
@Override public final short readShort() throws IOException { if (Short.BYTES <= buffer.remaining()) { return buffer.getShort(); } else { return super.readShort(); } } @Override public final int readInt() throws IOException { if (Integer.BYTES <= buffer.remaining()) { return buffer.getInt(); } else { return super.readInt(); } } @Override public final long readLong() throws IOException { if (Long.BYTES <= buffer.remaining()) { return buffer.getLong(); } else { return super.readLong(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
这些方法都会尝试先从buffer中获取数据,如果buffer中没有则调用父类的的方法
例如readInt会尝试先从buffer中获取数据,如果buffer中没有则调用父类的readInt方法
public int readInt() throws IOException {
return ((readByte() & 0xFF) << 24) | ((readByte() & 0xFF) << 16)
| ((readByte() & 0xFF) << 8) | (readByte() & 0xFF);
}
- 1
- 2
- 3
- 4
而父类的readInt又会调用readByte,最终buffer中如果没有数据则会出发refill逻辑
@Override
public final byte readByte() throws IOException {
if (buffer.hasRemaining() == false) {
refill();
}
return buffer.get();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
BufferedIndexInput#refill
buffer中的数据是调用refill方法首先创建一个HeapByteBuffer,然后调用readInternal来填充buffer
# org.apache.lucene.store.BufferedIndexInput#refill private void refill() throws IOException { long start = bufferStart + buffer.position(); long end = start + bufferSize; // bufferSize是1024 if (end > length()) // don't read past EOF end = length(); int newLength = (int)(end - start); if (newLength <= 0) throw new EOFException("read past EOF: " + this); if (buffer == EMPTY_BYTEBUFFER) { // 创建一个HeapByteBuffer buffer = ByteBuffer.allocate(bufferSize); // allocate buffer lazily // 检查当前坐标是否越界 seekInternal(bufferStart); } buffer.position(0); buffer.limit(newLength); bufferStart = start; // 填充当前的buffer readInternal(buffer); // Make sure sub classes don't mess up with the buffer. assert buffer.order() == ByteOrder.BIG_ENDIAN : buffer.order(); assert buffer.remaining() == 0 : "should have thrown EOFException"; assert buffer.position() == newLength; // 切换到读模式 buffer.flip(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
NIOFSIndexInput#readInternal
接下来我们来看看readInternal,里面是调用FileChannel的read方法来填充ByteBuffer
@Override protected void readInternal(ByteBuffer b) throws IOException { long pos = getFilePointer() + off; if (pos + b.remaining() > end) { throw new EOFException("read past EOF: " + this); } try { int readLength = b.remaining(); while (readLength > 0) { final int toRead = Math.min(CHUNK_SIZE, readLength); b.limit(b.position() + toRead); assert b.remaining() == toRead; final int i = channel.read(b, pos); if (i < 0) { // be defensive here, even though we checked before hand, something could have changed throw new EOFException("read past EOF: " + this + " buffer: " + b + " chunkLen: " + toRead + " end: " + end); } assert i > 0 : "FileChannel.read with non zero-length bb.remaining() must always read at least one byte (FileChannel is in blocking mode, see spec of ReadableByteChannel)"; pos += i; readLength -= i; } assert readLength == 0; } catch (IOException ioe) { throw new IOException(ioe.getMessage() + ": " + this, ioe); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
FileChannelImpl#read
# sun.nio.ch.FileChannelImpl#read(java.nio.ByteBuffer, long) public int read(ByteBuffer dst, long position) throws IOException { if (dst == null) throw new NullPointerException(); if (position < 0) throw new IllegalArgumentException("Negative position"); if (!readable) throw new NonReadableChannelException(); if (direct) Util.checkChannelPositionAligned(position, alignment); ensureOpen(); if (nd.needsPositionLock()) { synchronized (positionLock) { return readInternal(dst, position); } } else { return readInternal(dst, position); // 走这里 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
FileChannelImpl#readInternal
# sun.nio.ch.FileChannelImpl#readInternal private int readInternal(ByteBuffer dst, long position) throws IOException { assert !nd.needsPositionLock() || Thread.holdsLock(positionLock); int n = 0; int ti = -1; try { // 标记可能会长时间block beginBlocking(); ti = threads.add(); if (!isOpen()) return -1; do { n = IOUtil.read(fd, dst, position, direct, alignment, nd); } while ((n == IOStatus.INTERRUPTED) && isOpen()); return IOStatus.normalize(n); } finally { threads.remove(ti); // 解除block endBlocking(n > 0); assert IOStatus.check(n); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
IOUtil#read
从缓存中获取DirectByteBuffer,如果没有则新建一个DirectByteBuffer
将文件内容读取到DirectByteBuffer
将DirectByteBuffer所有字节写入HeapByteBuffer
# sun.nio.ch.IOUtil#read(java.io.FileDescriptor, java.nio.ByteBuffer, long, boolean, int, sun.nio.ch.NativeDispatcher) static int read(FileDescriptor fd, ByteBuffer dst, long position, boolean directIO, int alignment, NativeDispatcher nd) throws IOException { if (dst.isReadOnly()) throw new IllegalArgumentException("Read-only buffer"); if (dst instanceof DirectBuffer) return readIntoNativeBuffer(fd, dst, position, directIO, alignment, nd); // Substitute a native buffer ByteBuffer bb; int rem = dst.remaining(); if (directIO) { // directIO 是 flase Util.checkRemainingBufferSizeAligned(rem, alignment); bb = Util.getTemporaryAlignedDirectBuffer(rem, alignment); } else { bb = Util.getTemporaryDirectBuffer(rem); // 从缓存中返回java.nio.DirectByteBuffer } try { // 从fd中根据坐标获取数据,directIO为false int n = readIntoNativeBuffer(fd, bb, position, directIO, alignment,nd); bb.flip(); if (n > 0) // 非常朴实无华,循环获取byte放到目标ByteBuffer中 dst.put(bb); // dts是HeapByteBuffer return n; } finally { // 释放ByteBuffer,如果可以尝试缓存ByteBuffer Util.offerFirstTemporaryDirectBuffer(bb); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
Util#getTemporaryDirectBuffer
从缓存中获取DirectByteBuffer,如果没有则新建一个DirectByteBuffer
# sun.nio.ch.Util#getTemporaryDirectBuffer public static ByteBuffer getTemporaryDirectBuffer(int size) { // If a buffer of this size is too large for the cache, there // should not be a buffer in the cache that is at least as // large. So we'll just create a new one. Also, we don't have // to remove the buffer from the cache (as this method does // below) given that we won't put the new buffer in the cache. if (isBufferTooLarge(size)) { return ByteBuffer.allocateDirect(size); } BufferCache cache = bufferCache.get(); ByteBuffer buf = cache.get(size); if (buf != null) { return buf; // 可能走这里 } else { // No suitable buffer in the cache so we need to allocate a new // one. To avoid the cache growing then we remove the first // buffer from the cache and free it. if (!cache.isEmpty()) { buf = cache.removeFirst(); free(buf); } return ByteBuffer.allocateDirect(size); // 返回 java.nio.DirectByteBuffer } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
IOUtil#readIntoNativeBuffer
将文件内容读取到DirectByteBuffer
# sun.nio.ch.IOUtil#readIntoNativeBuffer private static int readIntoNativeBuffer(FileDescriptor fd, ByteBuffer bb, long position, boolean directIO, int alignment, NativeDispatcher nd) throws IOException { int pos = bb.position(); int lim = bb.limit(); assert (pos <= lim); int rem = (pos <= lim ? lim - pos : 0); if (directIO) { // directIO是false Util.checkBufferPositionAligned(bb, pos, alignment); Util.checkRemainingBufferSizeAligned(rem, alignment); } if (rem == 0) return 0; int n = 0; if (position != -1) { // 走的这里 最终调用linux的pread64 n = nd.pread(fd, ((DirectBuffer)bb).address() + pos, rem, position); } else { n = nd.read(fd, ((DirectBuffer)bb).address() + pos, rem); } if (n > 0) // 更新bb的position bb.position(pos + n); return n; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
FileDispatcherImpl#pread
调用native方法pread0
# sun.nio.ch.FileDispatcherImpl#pread
int pread(FileDescriptor fd, long address, int len, long position)
throws IOException
{
return pread0(fd, address, len, position);
}
static native int pread0(FileDescriptor fd, long address, int len,
long position) throws IOException;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
FileDispatcherImpl.c.read0
https://github.com/AdoptOpenJDK/openjdk-jdk11/blob/19fb8f93c59dfd791f62d41f332db9e306bc1422/src/java.base/unix/native/libnio/ch/FileDispatcherImpl.c#L89
JNIEXPORT jint JNICALL
Java_sun_nio_ch_FileDispatcherImpl_pread0(JNIEnv *env, jclass clazz, jobject fdo,
jlong address, jint len, jlong offset)
{
jint fd = fdval(env, fdo);
void *buf = (void *)jlong_to_ptr(address);
return convertReturnVal(env, pread64(fd, buf, len, offset), JNI_TRUE);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
ByteBuffer#put
非常朴实无华,循环获取byte放到目标ByteBuffer中
# java.nio.ByteBuffer#put(java.nio.ByteBuffer)
public ByteBuffer put(ByteBuffer src) {
if (src == this)
throw createSameBufferException();
if (isReadOnly())
throw new ReadOnlyBufferException();
int n = src.remaining();
if (n > remaining())
throw new BufferOverflowException();
for (int i = 0; i < n; i++)
put(src.get());
return this;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Util#offerFirstTemporaryDirectBuffer
清空DirectByteBuffer,并尝试将清空后的DirectByteBuffer缓存起来
# sun.nio.ch.Util#offerFirstTemporaryDirectBuffer
static void offerFirstTemporaryDirectBuffer(ByteBuffer buf) {
// If the buffer is too large for the cache we don't have to
// check the cache. We'll just free it.
if (isBufferTooLarge(buf)) {
free(buf);
return;
}
assert buf != null;
BufferCache cache = bufferCache.get();
if (!cache.offerFirst(buf)) { // 缓存buf
// cache is full
free(buf); // 清空buf
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
mmapfs
mmapfs的实现类是org.apache.lucene.store.MMapDirectory
mmapfs如何获取ByteBuffer
流程图
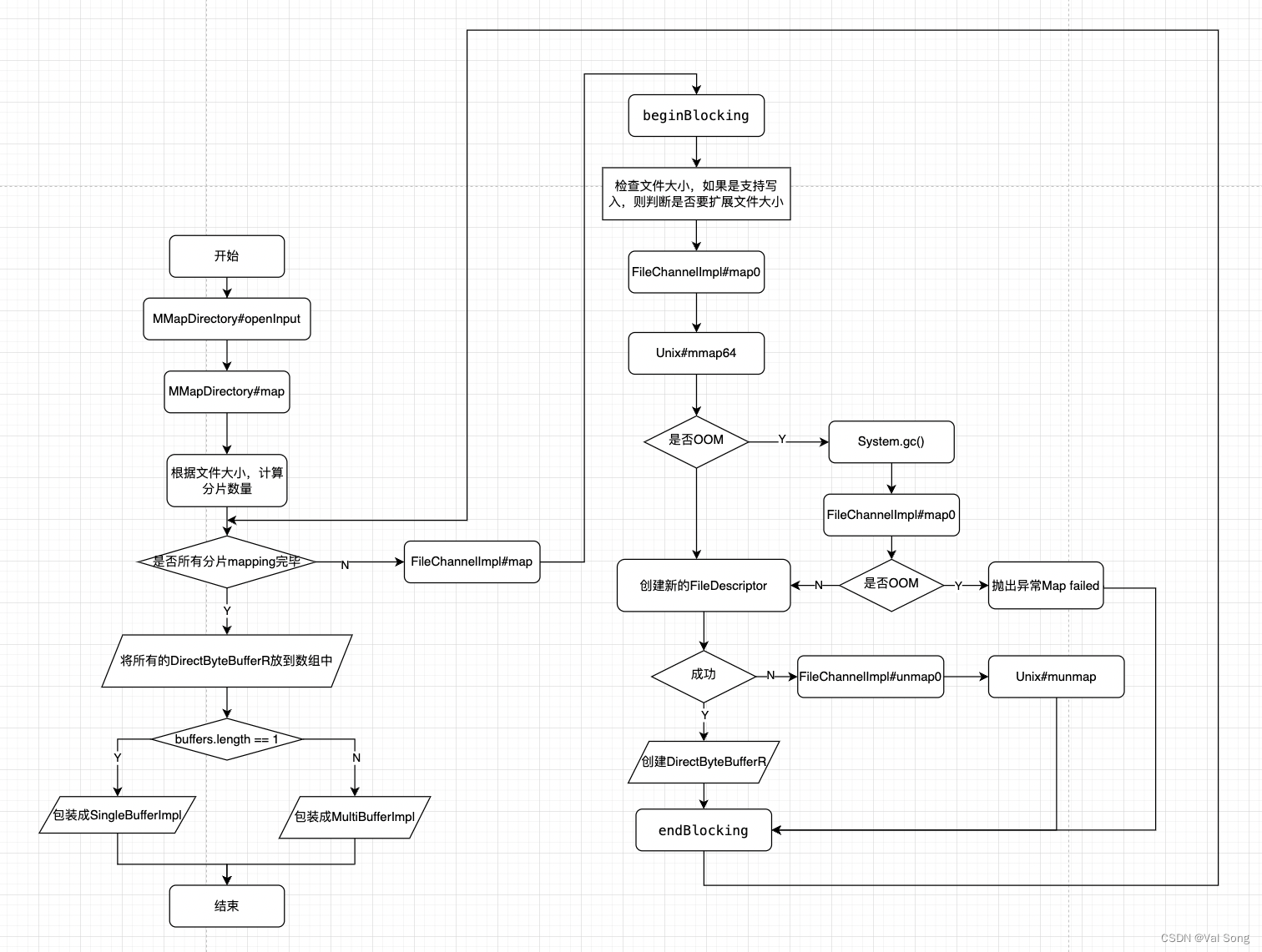
MMapDirectory#openInput
mmapfs使用MMapDirectory提供openInput返回一个IndexInput给其他的模块使用
# org.apache.lucene.store.MMapDirectory#openInput
@Override
public IndexInput openInput(String name, IOContext context) throws IOException {
ensureOpen();
ensureCanRead(name);
Path path = directory.resolve(name);
try (FileChannel c = FileChannel.open(path, StandardOpenOption.READ)) {
final String resourceDescription = "MMapIndexInput(path=\"" + path.toString() + "\")";
final boolean useUnmap = getUseUnmap(); // useUnmap=true
// 根据ByteBuffer数量选择使用SingleBufferImpl或者MultiBufferImpl包装
return ByteBufferIndexInput.newInstance(resourceDescription,
map(resourceDescription, c, 0, c.size()),
c.size(), chunkSizePower, new ByteBufferGuard(resourceDescription, useUnmap ? CLEANER : null)); // useUnmap为true
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
ByteBufferIndexInput.newInstance 就是个空壳
public static ByteBufferIndexInput newInstance(String resourceDescription, ByteBuffer[] buffers, long length, int chunkSizePower, ByteBufferGuard guard) {
if (buffers.length == 1) {
return new SingleBufferImpl(resourceDescription, buffers[0], length, chunkSizePower, guard);
} else {
return new MultiBufferImpl(resourceDescription, buffers, 0, length, chunkSizePower, guard);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
其中SingleBufferImpl和MultiBufferImpl本质都是代理了ByteBuffer对象,所以这些我们直接跳过,重点是这个map方法
MMapDirectory#map
方法返回的ByteBuffer数组是MappedByteBuffer,具体的实现类是java.nio.DirectByteBufferR
maxChunkSize的获取规则是 Constants.JRE_IS_64BIT ? (1 << 30) : (1 << 28); 在64位系统下是1073741824即1024MB
this.chunkSizePower = 31 Integer.numberOfLeadingZeros(maxChunkSize); = 30
这里面的preload一直是false,所以buffer.load()不会触发
# org.apache.lucene.store.MMapDirectory#map final ByteBuffer[] map(String resourceDescription, FileChannel fc, long offset, long length) throws IOException { if ((length >>> chunkSizePower) >= Integer.MAX_VALUE) throw new IllegalArgumentException("RandomAccessFile too big for chunk size: " + resourceDescription); final long chunkSize = 1L << chunkSizePower; // chunkSizePower是30, chunkSize是1G // we always allocate one more buffer, the last one may be a 0 byte one // 根据文件大小和块大小来计算分片数量 final int nrBuffers = (int) (length >>> chunkSizePower) + 1; ByteBuffer buffers[] = new ByteBuffer[nrBuffers]; long bufferStart = 0L; for (int bufNr = 0; bufNr < nrBuffers; bufNr++) { int bufSize = (int) ( (length > (bufferStart + chunkSize)) ? chunkSize : (length - bufferStart) ); MappedByteBuffer buffer; // buffer 是 java.nio.DirectByteBufferR try { buffer = fc.map(MapMode.READ_ONLY, offset + bufferStart, bufSize); } catch (IOException ioe) { throw convertMapFailedIOException(ioe, resourceDescription, bufSize); } if (preload) { // preload=false buffer.load(); } buffers[bufNr] = buffer; bufferStart += bufSize; } return buffers; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
重点看下fileChannel.map方法
FileChannelImpl#map
beginBlocking() 方法 标记可能会无限期阻塞,需要和endBlocking配合使用
nd.size(fd) 获取文件大小,然后校验文件大小是不是小于位点+块大小,如果是则扩张文件,但是我们是只读模式所以这个逻辑不会走
map0(imode, mapPosition, mapSize) 这段逻辑开启虚拟内存地址和文件之间的映射
nd.duplicateForMapping(fd); 创建了一个新的FileDescriptor
创建新的DirectByteBufferR Util.newMappedByteBufferR(isize, addr + pagePosition, mfd, um);
endBlocking()结束标记阻塞
# sun.nio.ch.FileChannelImpl#map // mode是MapMode.READ_ONLY // position是开始坐标 // size是小文件则是文件大小,大文件则是块大小 public MappedByteBuffer map(MapMode mode, long position, long size) throws IOException { ensureOpen(); if (mode == null) throw new NullPointerException("Mode is null"); if (position < 0L) throw new IllegalArgumentException("Negative position"); if (size < 0L) throw new IllegalArgumentException("Negative size"); if (position + size < 0) throw new IllegalArgumentException("Position + size overflow"); if (size > Integer.MAX_VALUE) throw new IllegalArgumentException("Size exceeds Integer.MAX_VALUE"); int imode = -1; if (mode == MapMode.READ_ONLY) imode = MAP_RO; else if (mode == MapMode.READ_WRITE) imode = MAP_RW; else if (mode == MapMode.PRIVATE) imode = MAP_PV; assert (imode >= 0); if ((mode != MapMode.READ_ONLY) && !writable) throw new NonWritableChannelException(); if (!readable) throw new NonReadableChannelException(); long addr = -1; int ti = -1; try { // 标记可能会一直阻塞,需要和endBlocking配合使用 beginBlocking(); ti = threads.add(); if (!isOpen()) return null; long mapSize; int pagePosition; synchronized (positionLock) { long filesize; do { filesize = nd.size(fd); // 获取文件大小 } while ((filesize == IOStatus.INTERRUPTED) && isOpen()); if (!isOpen()) return null; // 这段逻辑是写入时需要扩张文件,我们是只读模式不会走这段逻辑 if (filesize < position + size) { // Extend file size if (!writable) { throw new IOException("Channel not open for writing " + "- cannot extend file to required size"); } int rv; do { rv = nd.truncate(fd, position + size); } while ((rv == IOStatus.INTERRUPTED) && isOpen()); if (!isOpen()) return null; } // 正常情况size 大于0 if (size == 0) { addr = 0; // a valid file descriptor is not required FileDescriptor dummy = new FileDescriptor(); if ((!writable) || (imode == MAP_RO)) return Util.newMappedByteBufferR(0, 0, dummy, null); else return Util.newMappedByteBuffer(0, 0, dummy, null); } // allocationGranularity 16384 即16K pagePosition = (int)(position % allocationGranularity); long mapPosition = position - pagePosition; mapSize = size + pagePosition; try { // If map0 did not throw an exception, the address is valid // 开启虚拟内存地址 // imode MAP_RO addr = map0(imode, mapPosition, mapSize); } catch (OutOfMemoryError x) { // An OutOfMemoryError may indicate that we've exhausted // memory so force gc and re-attempt map System.gc(); try { Thread.sleep(100); } catch (InterruptedException y) { Thread.currentThread().interrupt(); } try { addr = map0(imode, mapPosition, mapSize); } catch (OutOfMemoryError y) { // After a second OOME, fail throw new IOException("Map failed", y); } } } // synchronized // On Windows, and potentially other platforms, we need an open // file descriptor for some mapping operations. FileDescriptor mfd; try { mfd = nd.duplicateForMapping(fd); } catch (IOException ioe) { unmap0(addr, mapSize); throw ioe; } assert (IOStatus.checkAll(addr)); assert (addr % allocationGranularity == 0); int isize = (int)size; Unmapper um = new Unmapper(addr, mapSize, isize, mfd); if ((!writable) || (imode == MAP_RO)) { return Util.newMappedByteBufferR(isize, addr + pagePosition, mfd, um); } else { return Util.newMappedByteBuffer(isize, addr + pagePosition, mfd, um); } } finally { threads.remove(ti); endBlocking(IOStatus.checkAll(addr)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
FileChannelImpl#map0
这段代码的是将文件的一部分和虚拟内存空间映射起来
# sun.nio.ch.FileChannelImpl#map0
// Creates a new mapping
private native long map0(int prot, long position, long length)
throws IOException;
- 1
- 2
- 3
- 4
https://github.com/AdoptOpenJDK/openjdk-jdk11/blob/19fb8f93c59dfd791f62d41f332db9e306bc1422/src/java.base/unix/native/libnio/ch/FileChannelImpl.c#L74
map0源码
JNIEXPORT jlong JNICALL Java_sun_nio_ch_FileChannelImpl_map0(JNIEnv *env, jobject this, jint prot, jlong off, jlong len) { void *mapAddress = 0; jobject fdo = (*env)->GetObjectField(env, this, chan_fd); jint fd = fdval(env, fdo); int protections = 0; int flags = 0; if (prot == sun_nio_ch_FileChannelImpl_MAP_RO) { protections = PROT_READ; flags = MAP_SHARED; } else if (prot == sun_nio_ch_FileChannelImpl_MAP_RW) { protections = PROT_WRITE | PROT_READ; flags = MAP_SHARED; } else if (prot == sun_nio_ch_FileChannelImpl_MAP_PV) { protections = PROT_WRITE | PROT_READ; flags = MAP_PRIVATE; } mapAddress = mmap64( 0, /* Let OS decide location */ len, /* Number of bytes to map */ protections, /* File permissions */ flags, /* Changes are shared */ fd, /* File descriptor of mapped file */ off); /* Offset into file */ if (mapAddress == MAP_FAILED) { if (errno == ENOMEM) { JNU_ThrowOutOfMemoryError(env, "Map failed"); return IOS_THROWN; } return handle(env, -1, "Map failed"); } return ((jlong) (unsigned long) mapAddress); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
Util#newMappedByteBufferR
# sun.nio.ch.Util#newMappedByteBufferR static MappedByteBuffer newMappedByteBufferR(int size, long addr, FileDescriptor fd, Runnable unmapper) { MappedByteBuffer dbb; if (directByteBufferRConstructor == null) initDBBRConstructor(); // 如果构造器为空则初始化构造器 try { // 反射创建新的DirectByteBufferR对象 dbb = (MappedByteBuffer)directByteBufferRConstructor.newInstance( new Object[] { size, addr, fd, unmapper }); } catch (InstantiationException | IllegalAccessException | InvocationTargetException e) { throw new InternalError(e); } return dbb; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
DirectByteBufferR 构造器
protected DirectByteBufferR(int cap, long addr,
FileDescriptor fd,
Runnable unmapper)
{
super(cap, addr, fd, unmapper);
this.isReadOnly = true;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
DirectByteBufferR父类构造器
protected DirectByteBuffer(int cap, long addr,
FileDescriptor fd,
Runnable unmapper)
{
super(-1, 0, cap, cap, fd);
address = addr;
cleaner = Cleaner.create(this, unmapper);
att = null;
}
MappedByteBuffer(int mark, int pos, int lim, int cap, // package-private
FileDescriptor fd)
{
super(mark, pos, lim, cap);
this.fd = fd;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
mmapfs如何读数据
@Override public final byte readByte() throws IOException { try { // curBuf是 java.nio.DirectByteBufferR return guard.getByte(curBuf); // guard 是 org.apache.lucene.store.ByteBufferGuard } catch (BufferUnderflowException e) { do { curBufIndex++; if (curBufIndex >= buffers.length) { throw new EOFException("read past EOF: " + this); } setCurBuf(buffers[curBufIndex]); curBuf.position(0); } while (!curBuf.hasRemaining()); return guard.getByte(curBuf); } catch (NullPointerException npe) { throw new AlreadyClosedException("Already closed: " + this); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
guard.getByte(curBuf)只是套了一层壳
# org.apache.lucene.store.ByteBufferGuard#getByte(java.nio.ByteBuffer)
public byte getByte(ByteBuffer receiver) {
ensureValid();
return receiver.get();
}
- 1
- 2
- 3
- 4
- 5
最终调用java.nio.DirectByteBuffer#get()
# java.nio.DirectByteBuffer#get()
public byte get() {
try {
return ((UNSAFE.getByte(ix(nextGetIndex()))));
} finally {
Reference.reachabilityFence(this);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

