
- 1内网渗透初探(三) | 查缺补漏_secretsdump.py
- 2vue从url中获取token并加入到 请求头里_django开发-django中实现用户登录认证的几种方式...
- 3自己搭建gitlab token没有写权限_gitlab迁移
- 4JavaScript的OO特性:静态方法
- 5Mac查看本机IP_mac ifconfig
- 6分享几个可以免费使用GPT的网站_免费gpt
- 7一文理解 Redis 持久化:RDB和AOF_rdb与aof结合一起做恢复
- 8[开源]基于 Flowable 的工作流管理平台,易集成、高度可定制、扩展性强_flowable开源
- 9计算机网络——IP协议基础原理_ip协议原理
- 10FPGA设计的指导性原则 (一)_fpga板卡design rule
MovieLens个性化电影推荐系统实战(二):用户群体划分(聚类)_movielens 聚类
赞
踩
一、前言
本系列文章使用MovieLens数据集进行机器学习综合实战。本文主要记录的是用户群体划分。由于平台有点鸡肋,不能显示运行代码块的结果,大家可以在评论区留言或私信我获取有结果显示的源码。文章和代码均是小编原创,为小编的期末实训项目。仅供大家参考,请勿全篇抄袭本文!!
数据集链接:https://files.grouplens.org/datasets/movielens/ml-1m.zip
系列文章目录:
MovieLens个性化电影推荐系统实战(一):数据探索(数据预处理、数据可视化)_movielens数据集下载-CSDN博客
MovieLens个性化电影推荐系统实战(三):个性化电影推荐(推荐算法)-CSDN博客
文章资源,百度网盘永久有效:
链接: https://pan.baidu.com/s/1P45bvnp6ezE-0J06Wjx2sQ?pwd=csdn 提取码: csdn 复制这段内容后打开百度网盘手机App,操作更方便哦
资料:MovieLens个性化电影推荐系统实战——系列文章资料-CSDN博客
二、聚类
聚类是按照某个特定标准把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
聚类算法的目的是将数据集划分为不同的组,使得组内的数据点相似度高,组间的相似度低。聚类算法可以分为层次聚类和非层次聚类两种。层次聚类可以分为聚合聚类和分裂聚类两种。常用的聚类算法包括k均值聚类(K-means)、层次聚类、谱聚类等。其中,K-means是最常见的聚类算法之一,它将数据集分为K个簇,每个簇的中心点被称为质心。层次聚类通过 计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树,其好处是不需要指定具体类别数目的,其得到的是一颗树,聚类完成之后,可在任意层次横切一刀,得到指定数目的簇。K-means算法和层次聚类的算法基本步骤如下:
1、K-means算法基本步骤
1)初始化:选择要创建的簇的数量k,并随机选择k个数据点作为初始的簇中心点。
2)分配数据点:对于每个数据点,计算其与所有簇中心点的距离,并将其分配给最近的簇。
3)更新簇中心点:对于每个簇,计算其内部所有数据点的均值,并将该均值作为新的簇中心点。
4)重复步骤2)和步骤3),直到满足某个停止条件,比如簇中心点不再发生变化或达到最大迭代次数。
5)输出结果:最终的簇中心点即为聚类结果,每个数据点都属于距离其最近的簇。
2、层次聚类算法步骤
1)初始化:将每个数据点视为一个单独的簇。
2)计算距离或相似度:根据所选的距离或相似度度量方法,计算每对数据点之间的距离或相似度。
3)合并最近的簇:找到距离或相似度最近的两个簇,并将它们合并成一个新的簇。
4)更新距离或相似度矩阵:根据合并后的簇,更新距离或相似度矩阵。
5)重复步骤3)和步骤4),直到所有数据点都被合并成一个大的簇或达到预设的聚类数目。
6)构建聚类树或聚类图:根据合并的顺序和距离或相似度矩阵,构建聚类树或聚类图。
7)切割树或图:根据预设的聚类数目或一定的相似度阈值,选择合适的切割位置,将聚类树或聚类图切割成所需的聚类结果。
聚类算法的评价指标包括轮廓系数、Calinski-Harabasz指数(CH指数)、Davies-Bouldin指数(DB指数)等。
聚类算法的优化方法包括选择合适的聚类算法、确定合适的聚类簇数、选择合适的相似度度量等。聚类算法的局限性包括需要事先确定聚类簇数、对初始质心的选择敏感、对异常值敏感等。
三、用户群体划分
1、基于影评的用户群体划分
本设计尝试了两种方案,一是构建用户-电影类型平均评分矩阵做聚类,二是构建用户-电影评分矩阵做聚类。在实验结束后,根据实验结果形成对比。
两种构建矩阵的方案均使用了K-means算法、层次聚类、谱聚类和高斯混合模型进行训练。并使用PCA算法对矩阵降到二维,虽然会丢失一部分原数据的信息,但可以降低计算复杂度,也方便聚类结果的可视化[9-10]。
K-means算法网格搜索的超参数:n_clusters为簇的数量;init为初始质心选择方法;algorithm为均值算法的实现方式。
层次聚类网格搜索的超参数为:n_clusters;affinity为两个对象之间的相似性度量;linkage为计算簇之间的距离的方式。
谱聚类网格搜索的超参数为:n_clusters;gamma为控制相似度矩阵中数据点间的相似度;affinity。
高斯混合模型网格搜索超参数为:n_components为保留的特征的数量,max_iter为最大迭代次数。
进行实验的结果如下表所示:
电影类型平均评分实验结果
| 模型 | 最佳簇数 | 轮廓系数 | DB指数 | CH指数 |
| K-means算法 | 6 | 0.322 | 0.912 | 334.063 |
| 层次聚类 | 6 | 0.269 | 0.939 | 277.418 |
| 谱聚类 | 3 | 0.325 | 0.999 | 348.022 |
| 高斯混合模型 | 5 | 0.310 | 0.915 | 297.248 |
电影评分实验结果
| 模型 | 最佳簇数 | 轮廓系数 | DB指数 | CH指数 |
| K-means算法 | 6 | 0.521 | 0.786 | 531.139 |
| 层次聚类 | 6 | 0.460 | 0.856 | 487.256 |
| 谱聚类 | 4 | 0.222 | 0.897 | 200.699 |
| 高斯混合模型 | 4 | 0.344 | 1.099 | 351.200 |
总结以上全部结果,在构建用户-电影评分矩阵的方案中,K-means算法得到的结果最好,在后续实验中使用该模型。其轮廓系数、DB指数为结果中最低的,CH指数为结果中最高的,其最优的初始质心选择方法是K-means++算法,最优的均值算法的实现方式为lloyd算法。
可视化在构建用户-电影评分矩阵的方案中,K-means算法得到的聚类结果如下图所示:
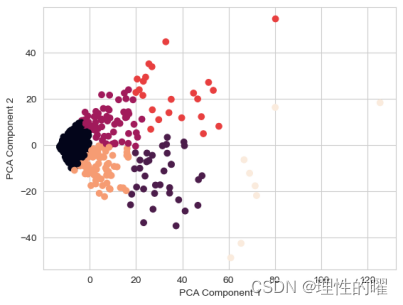
2、基于个人信息的用户群体分类
本设计还进行了对用户个人信息的群体划分,需要对用户个人信息数据集进行PCA算法降到二维,然后使用K-means算法、层次聚类和谱聚类进行聚类,并使用网格搜索找到最佳模型。
进行实验的结果如下表所示:
表3.3 用户个人信息实验结果
| 模型 | 最佳簇数 | 轮廓系数 | DB指数 | CH指数 |
| K-means算法 | 6 | 0.402 | 0.757 | 543.526 |
| 层次聚类 | 3 | 0.375 | 0.953 | 423.141 |
| 谱聚类 | 3 | 0.390 | 0.897 | 454.268 |
实验结果中,K-means算法的评估指标要由于其他模型,其最优的初始质心选择方法是random算法,最优的均值算法的实现方式为elkan算法。其聚类可视化结果如下图所示: 
四、关键代码
1、基于影评的用户群体分类
需要在上一篇文章的代码续写以下代码。
- genres_split = movies_df['genres'].str.get_dummies('|')
- movies = pd.concat([movies_df, genres_split], axis=1)
-
- # 合并ratings和movies表格,根据movieId连接
- merged_data = pd.merge(ratings_df, movies, on='movie_id')
- # 构建用户-电影类型平均评分矩阵做聚类
- avg_ratings_by_genre = merged_data.groupby(['user_id'])[genres_split.columns].mean()
- # avg_ratings_by_genre
- # 构建用户-电影评分矩阵做聚类
- user_movie_matrix = ratings_df.pivot_table(index='user_id', columns='movie_id', values='rating')
- user_movie_matrix = user_movie_matrix.fillna(0)
- user_movie_matrix
做PCA降维:
- from sklearn.model_selection import GridSearchCV
- from sklearn.cluster import KMeans
-
- # 将用户的兴趣类型向量作为聚类算法的输入
- # user_type_vectors_array = user_type_vectors.drop('user_id', axis=1).values
-
- #PCA降维
- from sklearn.decomposition import PCA
-
- pca = PCA(n_components=2)
- pca_data = pca.fit_transform(user_movie_matrix)
使用k-means算法:
- #进行网格搜索最佳参数
- param_grid = {
- 'n_clusters': [3, 4, 5, 6], # 簇的数量
- 'init': ['random', 'k-means++'], # 初始质心选择方法
- 'algorithm': ['lloyd', 'elkan'], # K均值算法的实现方式
- }
-
- # 创建K均值算法模型
- kmeans = KMeans(n_init="auto")
-
- # 创建网格搜索对象
- grid_search = GridSearchCV(estimator=kmeans, param_grid=param_grid)
-
- # 在训练集上拟合网格搜索对象
- grid_search.fit(pca_data)
-
- # 输出最佳参数组合和最佳评分
- print("最佳参数组合:", grid_search.best_params_)
- print("最佳评分:", grid_search.best_score_)

训练最佳参数模型,并可视化聚类结果 。
- best_model = grid_search.best_estimator_
- best_model.fit(pca_data)
- labels = best_model.labels_
-
- # 绘制散点图
- plt.scatter(pca_data[:, 0], pca_data[:, 1], c=labels)
- plt.xlabel('PCA Component 1')
- plt.ylabel('PCA Component 2')
- # plt.title('K-Means Clustering Result with PCA')
- plt.show()
评估模型的性能:
- from sklearn.metrics import silhouette_score, davies_bouldin_score, calinski_harabasz_score
-
- # 计算轮廓系数
- silhouette_avg = silhouette_score(pca_data, labels)
- print("轮廓系数:", silhouette_avg)
-
- # 计算DB指数
- db_index = davies_bouldin_score(pca_data, labels)
- print("DB指数:", db_index)
-
- ch_score = calinski_harabasz_score(pca_data, labels)
- print("Calinski-Harabasz指数:", ch_score)
由于其他模型与K-means算法参数搜索的做法一致,这里小编就不展示了。
完整代码可以私信或评论区留言!!
2、基于个人信息的用户群体分类
首先需要做一些预处理
- user_df['zip_encoding'] = le.fit_transform(user_df['zip'])
- user_df.drop(['gender', 'zip'], axis=1, inplace=True)
- user_df.set_index('user_id', inplace=True)
- user_df
在对数据进行归一化,不然聚类的结果的可视化会部太好。再进行PCA降维。
- from sklearn.preprocessing import StandardScaler
- from sklearn.model_selection import GridSearchCV
- scaler = StandardScaler()
- scaled_user_df = scaler.fit_transform(user_df)
-
- pca_data = pca.fit_transform(scaled_user_df)
接下来就是模型的参数搜索和结果的可视化,和上面的K-means一样。
实际上两种用户群体的划分方法都是K-means算法较好。这里使用多个模型形成对比的原因是实验的原则。大家训练好K-means模型即可,没有训练其他模型不会影响接下来的任务。
五、总结
本文主要介绍了聚类的常用的两种方法,以及在本任务中,我们如何去使用聚类。找到了划分群体最好的聚类方法。
根据用户个人信息划分的结果比根据影评的划分结果要更加合理。根据用户个人信息划分的结果的簇内间距较小,簇的轮廓比较清晰。但是根据业务的需要,两种划分方法均保留。
导致根据影评的划分结果不太合理的原因主要是某些用户评分的电影较少,降维后的数据会成为异常值,从而导致在聚类结果中比较分散或离群。这属于数据统计的不合理,可以筛选出评论数大致一样的用户评分数据,再进行数据补充。
本文章就到此结束啦,感谢大家的关注,希望大家能给出宝贵的点赞和收藏!!!

