
- 1vivado 创建和运行链路清扫_vivado phase5 sweep
- 2学习STM32时遇到的关于sizeof()strlen()strcmp()strcpy()memset()函数的辨析_stm32 sizeof用法
- 3人工蜂群算法ABC(学习笔记_08)_人工蜂群算法流程图
- 4MinIO对象存储介绍和使用
- 5微服务架构以及服务治理_微服务治理平台技术资料
- 6手把手带你入坑树莓派(3B+)之第二篇,使用Putty与电脑VNC远程控制树莓派_手把手带你入坑树莓派(3b+)之第二篇
- 7nginx正反向代理概念和优点简介以及nginx反向代理配置_nginx代理和反向代理
- 8RocketMQ(五):功能特性——消费管理_rocketmq 并发消费
- 9不看后悔系列之一篇搞懂LinuxCentOS搭建MQTT服务器及客户端操作使用_linux mqtt
- 10SolidWorks Electrical无法加载数据库解决办法_solidworks electrical无法连接到数据库
FPGA设计的指导性原则 (一)_fpga板卡design rule
赞
踩
这一部分主要介绍FPGA/CPLD设计的指导性原则,如FPGA设计的基本原则、基本设 计思想、基本操作技巧、常用模块等。FPGA/CPLD设计的基本原则、思想、技巧和常用模 块是一个非常大的问题,在此不可能面面俱到,只能我们公司项目中常用的一些设计原则与 方法提纲携领地加以介绍,希望引起同事们的注意,如果大家能有意识的用这些原则方法指 导日后的工作,不断积累和充实自己,将取得事半功倍的效果!
本章主要内容如下:
基本原则之一:面积和速度的平衡与互换;
基本原则之二:硬件原则;
基本原则之三:系统原则;
基本原则之四:同步设计原则;
基本设计思想与技巧之一:乒乓操作;
基本设计思想与技巧之二:串并转换;
基本设计思想与技巧之三:流水线操作;
基本设计思想与技巧之四:数据接口的同步方法;
常用模块之一:RAM;
常用模块之二:全局时钟资源与时钟锁相环;
常用模块之三:全局复位/置位信号;
常用模块之四:高速串行收发器。
1.1基本原则之一:面积和速度的平衡与互换
这里“面积”指一个设计消耗FPGA/CPLD的逻辑资源的数量,对于FPGA可以用所消 耗的触发器(FF)和查找表(LUJT)来衡量,更一般的衡量方式可以用设计所占用的等价 逻辑门数。“速度”指设计在芯片上稳定运行,所能够达到的最高频率,这个频率由设计的 时序状况决定,和设计满足的时钟周期,PAD to PAD Time,Clock Setup Time,Clock Hold Time,Clock-to-Output Delay等众多时序特征量密切相关。面积(area)和速度(speed)这 两个指标贯穿着FPGA/CPLD设计的始终,是设计质量的评价的终极标准。这里我们就讨论 一下关于面积和速度的两个最基本的概念:面积与速度的平衡和面积与速度的互换。
面积和速度是一对对立统一的矛盾体。要求一个同时具备设计面积最小,运行频率最高 是不现实的。更科学的设计目标应该是在满足设计时序要求(包含对设计频率的要求)的前 提下,占用最小的芯片面积。或者在所规定的面积下,使设计的时序余量更大,频率跑得更 高。这两种目标充分体现了面积和速度的平衡的思想。关于面积和速度的要求,我们不应该简单的理解为工程师水平的提高和设计完美性的追求,而应该认识到它们是和我们产品的质 量和成本直接相关的。如果设计的时序余量比较大,跑的频率比较高,意味着设计的健壮性 更强,整个系统的质量更有保证:另一方面,设计所消耗的面积更小,则意味着在单位芯片 上实现的功能模块更多,需要的芯片数量更少,整个系统的成本也随之大幅度削减。
作为矛盾的两个组成部分,面积和速度的地位是不一样的。相比之下,满足时序、工作 频率的要求更重要一些,当两者冲突时,采用速度优先的准则。
面积和速度的互换是FPGA/CPLD设计的一个重要思想。从理论上讲,一个设计如果时 序余量较大,所能跑的频率远远高于设计要求,那么就能通过功能模块复用减少整个设计消 耗的芯片面积,这就是用速度的优势换面积的节约:反之,如果一个设计的时序要求很高, 普通方法达不到设计频率,那么一般可以通过将数据流串并转换,并行复制多个操作模块, 对整个设计采取“乒乓操作”和“串并转换”的思想进行运作,在芯片输出模块再在对数据 进行“并串转换”,是从宏观上看整个芯片满足了处理速度的要求,这相当于用面积复制换 速度提高。面积和速度的互换的具体操作有很多的技巧,比如模块复用,“乒乓操作”,“串 并转换”等,需要大家在日后工作中积累掌握。下面举例说明如何使用“速度换面积”和 “面积换速度”。
例1.如何使用“速度的优势换取面积的节约”?
在WCDMA预商用系统设计中,使用到了快速哈达码(FHT)运算,FHT由四步相同 的算法完成,如图l所示。FHT的单步算法如下:
Ou[2i] = In[2i]+ In[2i + 8];i = 0-7;
Ou[21+ 1]= In[2i+1]- In[2i+1+8];i =0-7
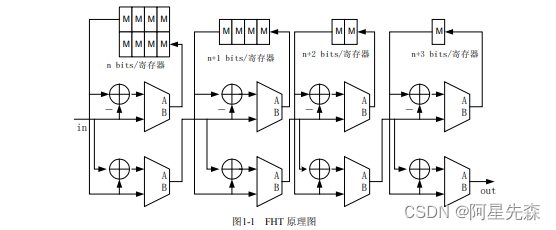
原设计由于考虑流水线式数据处理的要求,做了不同端口宽度的4个单步FHT,并用 将这4个单步模块串联起来,以完成数据流的流水线处理。该FHT实现方式的代码如下:
//该模块是FH?的顶层,调用4个不同端口宽度的单步FHT模块,完成整个FHT算法
module
fhtpart (Clk,Reset,FhtStarOne,FhtStarTvo,FhtStarThree,FhtStarFour,
I0,I1,I2,I3,I4,I5,I6,I7,I8,






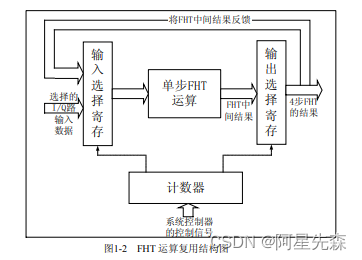
当评估完系统的流水线时间余量后,发现整个流水线有l6个时钟周期,而FHT模块的 频率很高,加法本身仅仅消耗l个时钟周期,加上数据的选择和分配所消耗时间,也能完全 满足频率要求,所以将单步FHT运算复用4次,就能大幅度节约所消耗的资源。这种复用 单步算法的FHT实现框图如图2所示,由输入选择寄存、单步FHT模块、输出选择寄存、 计数器构成。






为了便于对比两种实现方式的资源消耗,我在SynplifyPro对两种实现方法分别做了综 合。两次综合选用的参数都完全一致,器件类型为:Xilinx Virtex-EXCV100E-6BG352, 出于仅仅考察设计所消耗的寄存器和逻辑资源,Enable“Disable I/O lnsertion”选项,不插 入IO.取消Synplify Pro中诸如“FSM Compiler”、“FSM Explorer”、“Resource Sharing”、 “Retiming”、“Pipelining”等综合优化选项。两次综合的结果如图3.图4所示。
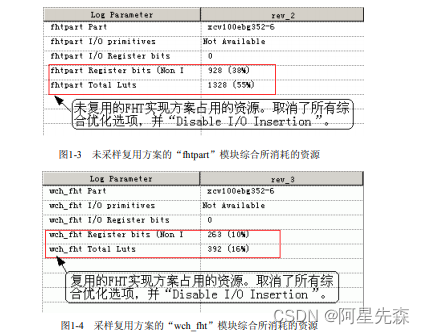
通过对比可以清晰的观察到,采样复用实现方案所占面积约为原方案的1/4,而得到这 个好处的代价是:完成整个FHT运算的周期为原来的4倍。这个例子通过运算周期的加长,换取了消耗芯片面积的减少,是前面所述的用频率换面积的一种体现。本例所述“频率 换面积”的前提是:FHT模块频率较高,运算周期的余量较大,采用4步复用后,仍然能 够满足系统流水线设计的要求。其实,如果流水线时序允许,FHT运算甚至可以采用lbit 全串行方案实现,该方案所消耗的芯片面积资源更少!
例2.如何使用“面积复制换速度提高”?
举一个路由器设计的一个例子。假设输入数据流的速率是450Mb/s,在而FPGA上设计 的数据处理模块的处理速度最大为l50Mb/s,由于处理模块的数据吞吐量满足不了要求,看 起来直接在FPGA 上实现是一个“impossible mission”。这种情况下,就应该利用“面积换 速度”的思想,至少复制3个处理模块,首先将输入数据进行串并转换,然后利用这三个模 块并行处理分配的数据,然后将处理结果“并串变换”,就完成数据速率的要求。我们在整 个处理模块的两端看,数据速率是450Mb/s,而在FPGA的内部看,每个子模块处理的数据 速率是l50Mb/s,其实整个数据的吞吐量的保障是依赖于3个子模块并行处理完成的,也就 是说利用了占用更多的芯片面积,实现了高速处理,通过“面积的复制换取处理速度的提 高”的思想实现了设计。设计的示意框图如图5所示。
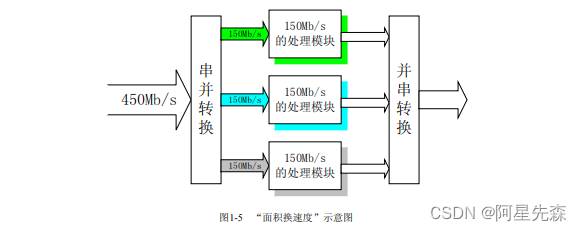
上面仅仅是对“面积换速度”思想的一个简单的举例,其实具体操作过程中还涉及很多 的方法和技巧,例如,对高速数据流进行串并转换,采用“乒乓操作”方法提高数据处理速 率等。希望读者通过平时的应用进一步积累。
1.2基本原则之二:硬件原则
硬件原则主要针对HDL代码编写而言的。
首先应该明确FPGA/CPLD、ASIC的逻辑设计所采用的硬件描述语言(HDL)与同软 件语言(如C,C++等)是有本质区别的!以VerilogHDL.语言为例(我们公司多数逻辑工 程师使用Verilog),虽然Verilog很多语法规则和C语言相似,但是Verilog作为硬件描述语 言,它的本质作用在于描述硬件!应该认识到Verilog是采用了C语言形式的硬件的抽象, 它的最终实现结果是芯片内部的实际电路。所以评判一段HDL.代码的优劣的最终标准是:
其描述并实现的硬件电路的性能(包括面积和速度两个方面)。评价一个设计的代码水平较 高,仅仅是说这个设计由硬件向HDL代码这种表现形式转换的更流畅、合理。而一个设计 的最终性能,在更大程度上取决于设计工程师所构想的硬件实现方案的效率以及合理性。 初学者,特别是由软件转行的初学者,片面追求代码的整洁、简短,这是错误的,是与 评价HDL的标准背道而驰的!正确的编码方法是,首先要做到对所需实现的硬件电路”心有 成竹”,对该部分硬件的结构与连接十分清晰,然后再用适当的HDL.语句表达出来即可。 另外,Verilog作为一种HDL.语言,是分层次的。比较重要的层次有:系统级 (System)、算法级(Algorithm)、寄存器传输级(RTL)、逻辑级(Logic)、门级(Gate)、电路开关 级(Switch)设计等。系统级和算法级与C语言更相似,可用的语法和表现形式也更丰富。自 RTL.级以后,HDL.语言的功能就越来越侧重于硬件电路的描述,可用的语法和表现形式的 局限性也越大。相比之下C语言与系统级和算法级Verilog描述更相近一些,而与RTL级, Gate级、Switch级描述从描述目标和表现形式上都有较大的差异。
例3.举例RTL级Verilog描述语法和C语言描述语法的一些区别。
简单的举例RTL级Verilog描述语法和C语言描述语法的一些区别。在C语言的描述 中,为了代码执行效率高,与表述简洁,经常用到如下所示的for循环语句:
for (i=0; i<16; i++)
DoSomething();
但是在我们工作中,除了描述仿真测试激励(testbench)时,使用for循环语句外,极 少在RTL.级编码中使用for循环。其原因是for循环会被综合器展开为所有变量情况的执行 语句,每个变量独立占用寄存器资源,每条执行语句并不能有效的复用硬件逻辑资源,造成 巨大的资源浪费。在RTL.硬件描述中,遇到类似算法,推荐的方式是先搞清楚设计的时序 要求,做一个reg型计数器,在每个时钟沿累加,并在每个时钟沿判断计数器情况,做相应 的处理,如果能复用的处理模块,尽量复用,即使所有操作都不能复用,也采用case语句 展开处理。如下所示:


两者之间的区别主要在于switch是多分支选择语句,而if语句只有两个分支可供选 择。虽然可以用嵌套的i语句来实现多分支选择,但那样的程序冗长难读。
对应 Verilog 也有if.….else语句和case语句,if语句的语法相似,case语句的语法如 下:
case (var)
var_valuel:
var_valuel:
... ...
default:
endcase
姑且不论casex和casez的作用(这两个语句的应用一定要小心,要注意是否可综合), case 语句和if.….else 嵌套描述结构就有很大的区别。在Verilog 语法中,if.….else if.….else 语句 是有优先级的,一般来说第一个if的优先级最高,最后一个else的优先级最低。如果描述 一个编码器,在Xilinx的XST综合参数就有一个关于优先级编码器硬件原语的选项Priority Encoder Extraction。而 case语句是“平行”的结构,所有的case的条件和执行都没有“优 先级”。而建立优先级结构(优先级树)会消耗大量的组合逻辑,所以如果能够使用case语 句的地方,尽量用case替换if.else结构。
关于这点简单的引申两点:第一,也可以用ifif...的结构描述出不带优先级的“平 行”条件判断语。第二,随着现在综合工具的优化能力越来越强,大多数情况下可以将不必 要的优先级树优化掉。关于if和case语句的更详细的阐释,见后面关于Coding Style的讨 论。
1.3基本原则之三:系统原则
系统原则包含两个层次的含义:更高层面上看,是一个硬件系统,一块单板如何进行模 块花费与任务分配,什么样的算法和功能适合放在FPGA里面实现,什么样的算法和功能 适合放在DSP、CPU里面实现,以及FPGA的规模估算数据接口设计等:具体到FPGA设 计就要求对设计的全局有个宏观上的合理安排,比如时钟域,模块复用,约束,面积,速度 等问题。要知道在系统上复用模块节省的面积远比在代码上小打小闹来的实惠得多。
一般来说实时性要求高、频率快的功能模块适合使用FPGA/CPLD实现。而FPGA和 CPLD相比,更适合实现规模较大、频率较高、寄存器资源使用较多的设计。使用 FPGA/CPLD 设计时,应该对芯片内部的各种底层硬件资源,和可用的设计资源有一个较深 刻的认识。比如FPGA一般触发器资源比较丰富,而CPLD组合逻辑资源更丰富一些,这 点直接影响着两者使用的编码风格。FPGA/CPLD一般是由底层可编程硬件单元、Block RAM资源、布线资源、可配置l0单元、时钟资源等构成。底层可编程硬件单元一般由触 发器(FF)和查找表(LUT)组成,Xilinx的底层可编程硬件资源叫SLICE,由2个FF和 2个LUT组成,Altera的底层可编程硬件资源叫LE,由1个FF和1个LUT组成,评估两 者芯片的可编程资源时需要注意这个区别。可配置IO单元,是FPGA/CPLD内部的一个重 要单元,通过在实现中配置相应选项,可用使10单元适配不同的10接口标准,不同的器 件可支持的IO标准不同,一些高端器件可以支持:LVTTL、LVCMOS、PCI、GTL、 GTLP HSTL、SSTL、LDT、LVDS、LVDSEXT、BLVDS、ULVDS、LVPECL、LVDCI等 多种I0标准,在通信领域应用是否便捷。布线资源用以连接不同硬件单元,根据用途不 同,布线资源的工艺、速度、驱动能力都不同。有全铜层的全局时钟布线资源,也有速度较 快,抖动时延很小的长线资源,普通的布线资源也分很多种。时钟资源主要指片内集成的一 些DLL.或者PLL,用于完成时钟的高精度、低抖动的倍频、分频、移相等操作。目前, Xilinx芯片主要集成的是 DLL,而 Altera芯片集成的是 PLL,他们各有优缺点,时钟控制 的功能复杂,而精度却非常高,一般在ps的数量级。Block RAM是FPGA的一个重要资 源,在片内集成RAM是FPGA的优势之一,高端FPGA的片内RAM规模越来越大,应用 也越来越广泛,是SOPC(可编程片上系统)的有力硬件支持。使用片内RAM可以实现单 口RAM、双口RAM、同步/异步FIFO、ROM、CAM等常用单元模块。目前FPGA的两个 重要发展与突破是,大多数厂商在其高端器件上都提供了片上的处理器(如CPU、DSP) 等硬核(Hard Core)或固化核(Fixed Core)。比如 Xilinx的 Virtex IⅡ Pro芯片可以提供 Power PC.而Altera 的Stratix、Excalibur等系列芯片可以提供Nios、DSP和Am等模块。 在FPGA上集成微处理器,使SOPC设计更加便利与强大。另一个发展是在不同器件商推 出的高端芯片上大都集成了高速串行收发器,一般能够达到3Gb/s以上的数据处理能力,在 Xilinx、Altera、Lattice都有相应的器件型号提供该功能。这些新功能是FPGA的数据吞吐 能力大幅度增强。 一般FPGA系统规划的简化流程如6所示。
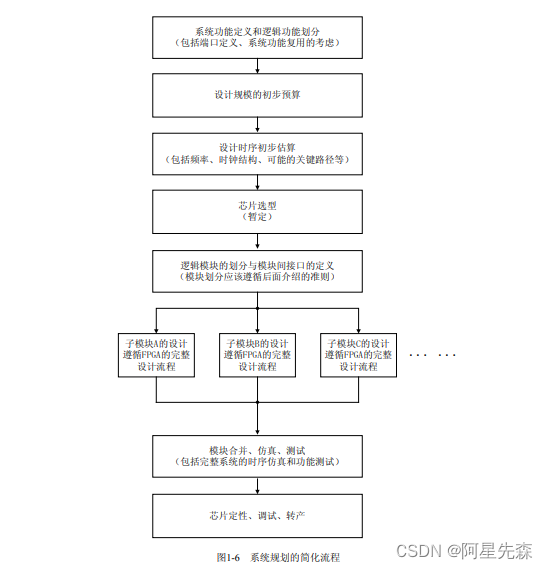
其中整设计的模块复用应该在系统功能定义后就初步考虑,并对模块的划分起指导性作 用。模块划分非常重要,除了关系到是否最大程度上发挥项目成员的协同设计能力,而且直 接决定着设计的综合、实现效果和相关的操作时间,模块划分的具体方法请参考第二章的 Coding Style中关于模块划分技巧的论述。 对于系统原则做一点引中,简单谈谈模块化设计方法。模块化设计是系统原则的一个很 好的体现,它不仅仅是一种设计工具,它更是一种设计思路、设计方法,它是是由项向下、 模块划分、分工协作设计思路的集中体现。是当代大型复杂系统的推荐设计方法。目前很多 的EDA厂商都提高了模块化设计工具,如Xilinx ISE 5.x系列中的“Modular Design”工具 包。在“Modular Design”设计流程中,实现步骤的第一步,也是整个设计流程的最重要的 一步就是Initial Budgeting,lnitial Budgeting就重复的体现了系统原则的设计理念,在该步 骤,设计管理者对设计的整体进行位置布局,并完成约束每个子模块的规模和区域,定位每个模块的输入/输出,对设计进行全局时序约束等任务。
例4.在系统层次复用模块。
某公司在一篇专利中提到可编程匹配滤波器实现WCDMA基站的方案,就重复利用了 系统原则,提高单元模块的复用率,从而大大的降低硬件消耗。其简单功能框图7所示。
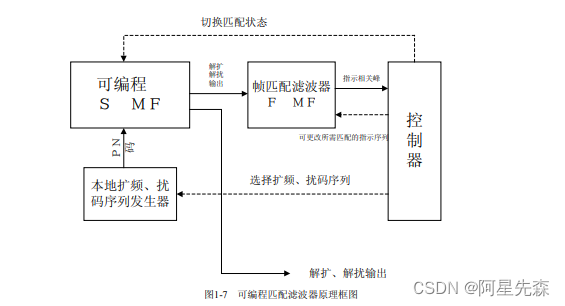
其设计思想是:利用信道固有特点(如信道pilot导频,信道结构等),应用现代可编程 数字信号处理的技术(如DSP、FPGA等),采取反馈与控制匹配滤波方式,实现对某信道 的已扩信息的自动解扩解扰。该可编程MF的主要组成部分为以下四部分:本地码发生器、 可编程信号MF(SMF)、帧匹配滤波器(FRAME MF)和控制器。本地码发生器可生成各 种所需的扩频、加扰序列。可接收控制器的指示脉冲,产生规定的本地解扩、解扰序列,作 为SMF的参考序列:SMF是完成匹配滤波的主体,可接收控制器的指示脉冲,将自己的 匹配状态切换倒下一匹配状态:FMF完成对导频信号等特殊信号(信息比特待选集有限) 的检测,生成指示相关峰,通知控制器将SMF切换倒下一匹配状态:控制器统一协调各部 分工作。这种可编程滤波器可以在如越区切换、同步方面、CPCH收发信机等多方面应用, 如果适当安排时序流程,可以在较大的程度上节约硬件资源。
1.4基本原则之四:同步设计原则
采用同步时序设计是FPGA/CPLD设计的一个重要原则。简单比较一下异步电路和同步 电路的特点。
异步电路
电路的核心逻辑用组合逻辑电路实现。比如异步的FIFO/RAM读写信号,地 址译码等电路。
电路的主要信号,输出信号等并不依赖于任何一个时钟性信号,不是由时钟信 号驱动FF产生的。
异步时序电路的最大缺点是容易产生毛刺。在布局布线后仿真和用逻辑分析仪 观测实际信号时,这种毛刺尤其明显。
同步时序电路
电路的核心逻辑用各种各样的触发器实现。
电路的主要信号,输出信号等都是由某个时钟沿驱动触发器产生出来的。
同步时序电路可以很好的避免毛刺。布局布线后仿真,和用逻辑分析仪采样实 际工作信号都没有毛刺。
由于大家对同步时序设计的原则都有一定的了解,在此不累述同步时序设计的重要性, 仅仅对同步时序设计中一些常见疑问做以分析和解答。
是否同步时序电路一定比异步电路使用更多的资源呢?
如果单纯的从ASIC设计来看,大约需要7个门来实现一个D触发器,而一个 门即可实现一个2输入与非门,所以一般来说ASIC设计中,同步时序电路比 异步电路占用更大的面积。但是由于FPGA/CPLD是定制好的底层单元,对于 Xilinx器件一个底层可编程单元Slice包含2个触发器(FF)和2个查找表 (LUT),对于Altera器件,一个底层可编程单元LE包含1个触发器(FF) 和1个查找表(LUT).其中FF用以实现同步实现电路,LUT用以实现组合 电路。FPGA/CPLD的最终使用率用Slice或者LE的利用率来街量。所以对于 某个选定器件,其可实现为同步实现电路和异步电路的资源的数量和比例是固 定的。这点造成了过度使用LUT,会浪费FF资源;过度使用FF,会浪费 LUT资源的情况,因而对于FPGA/CPLD 同步时序设计不一定比异步设计多 消耗资源,单纯的从节约资源的角度考虑,应该按照芯片配置的资源比例实现 设计,但是设计者还要时刻权衡到同步时序设计带来的没有毛刺,信号稳定的 优点,所以从资源使用的角度上看,FPGA/CPLD设计,也是推荐采用同步时 序设计的。
如何实现同步时序电路的延时?
异步电路产生延时的一般方法是插入一个Buffer、两级非门等,这种延时调整 手段是不适用于同步时序设计思想的。首先要明确一点HDL.语言中的延时控 制语法,例如:
#5a<=4'b0101:
其中的延时5个时间单位,是行为级代码描述,常用于仿真测试激励,但是在 电路综合是会被忽略,并不能启动延时作用。
同步时序电路的延时一般是通过时序控制完成的,换句话说,同步时序电路的 延时被当做一个电路逻辑来设计。对于比较大的和特殊定时要求的延时,一般 用高速时钟产生一个计数器,根据计数器的计数,控制延时;对于比较小的延 时,可以用D触发器打一下,这种做法不仅仅使信号延时了一个时钟周期, 而且完成了信号与时钟的初次间步,在输入信号采样和增加时序约束余量中使用。
同步时序电路的时钟如何产生?
同步时序电路的核心就是时钟,时钟沿驱动FF控制数据的产生,是同步时序 电路的主要表现形式,所以时钟的质量和稳定性直接决定着同步时序电路的性 能。
为了获得高驱动能、低抖动时延、稳定的占空比的时钟信号,一般使用 FPGA/CPLD内部的专用时钟资源产生同步时序电路的主工作时钟,专用时钟 资源主要指两部分,一部分是布线资源,包括全局时钟布线资源,和长线资源 等。另一部分是FPGA内部的PLL或者DLL,关于专用时钟资源和PLL/DLL 模块的使用方法,详见“常用模块之三:全局时钟资源与时钟锁相环”。
输入信号的同步
同步时序电路要求对输入信号进行同步化,同步化的主要作用是使本级时钟的 处理沿获得相对于数据的最长有效处理时间,从而获得了更长的时间余量。如 果输入数据的节拍和本级芯片的处理时钟同频,并且建立、保持时间匹配,可 以直接用本级芯片的主时钟对输入数据寄存器采样,完成输入数据的同步化。 如果输入数据和本级芯片的处理时钟是异步的,特别是频率不匹配的时候,则 只是要用处理时钟对输入数据做两次寄存器采样,才能完成输入数据的同步 化。需要说明的是,两次寄存器采样的作用在于有效地防止了亚稳态(数据状 态不定)的传播,是后级电路获得的电平为有效电平,但是这种处理并不能防 止错误采样电平的产生,关于输入数据的同步化的详细论述,参见“基本设计 思想与技巧之四:数据接口的同步方法”。
是不是定义为reg型,就一定综合成寄存器,并且是同步时序电路呢?
答案是否定的,在Verilog代码中最常用的两种数据类型是wire和reg,一般 来说,wire型指定的数据和网线通过组合逻辑实现,而reg型指定的数据不一 定就是用寄存器实现。下面的例子就是一个纯组合逻辑的译码器。请大家注 意,代码中将输出信号Dout定义为reg型,但是综合与实现结果却没有使用 FF,这个电路是一个纯组合逻辑设计。


1.5基本设计思想与技巧之一:乒乓操作
后面3个小节,简单介绍一些FPGA的设计思想与操作技巧。FPGA的设计思想和技巧 多种多样,篇幅所限,我们不可能将日常工作中涉及的所有设计思想和技巧都一一讨论,在 此仅仅挑选了3个有代表性的方法加以简要介绍,希望读者能够通过日常工作实践,总结出 更多的设计思想与技巧。
“乒乓操作”是一个常常应用于数据流控制的处理技巧。典型的乒乓操作方法如图8所 示。
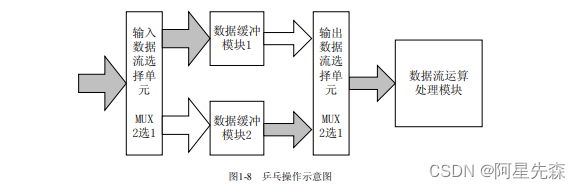
乒乓操作的处理流程描述如下:输入数据流通过“输入数据选择单元”,等时的将数据 流等时分配到两个数据缓冲区。数据缓冲模块可以为任何存储模块,比较常用的存储单元为 双口 RAM(DPRAM)、单口 RAM(SPRAM)、FIFO等。在第一个缓冲周期,将输入的数据 流缓存到“数据缓冲模块l”。在第2个缓冲周期,通过“输入数据选择单元”的切换,将输入的数据流缓存到“数据缓冲模块2”,与此同时,将“数据缓冲模块l”缓存的第l个周 期的数据通过“输入数据选择单元”的选择,送到“数据流运算处理模块”被运算处理。在 第3个缓冲周期,通过“输入数据选择单元”的再次切换,将输入的数据流缓存到“数据缓 冲模块l”,与此同时,将“数据缓冲模块2”缓存的第2个周期的数据通过“输入数据选择 单元”的切换,送到“数据流运算处理模块”被运算处理。如此循环,周而复始。
乒乓操作的最大特点是,通过“输入数据选择单元”和“输出数据选择单元”按节拍、 相互配合的切换,将经过缓冲的数据流没有时间停顿的送到“数据流运算处理模块”,被运 算与处理。把乒乓操作模块当做一个整体,站在这个模块的两端看数据,输入数据流和输出 数据流都是连续不断的,没有任何停顿,因此非常适合对数据流进行流水线式处理。所以乒 乓操作常常并应用于流水线式算法,完成数据的无缝缓冲与处理。
乒乓操作的第二个优点是可以节约缓冲区空间。比如在WCDMA基带应用中,1帧 (Frame)是由l5个时隙(Slot)组成的,有时需要将1整帧的数据延时一个时隙后处理, 比较直接的办法是将这帧数据缓存起来,然后延时l个时隙,进行处理。这时缓冲区的长度 是1整帧数据长,假设数据速率是3.84Mb/s,1帧长10ms,则此时需要缓冲区长度是 38400bit。如果采用乒乓操作,只需定义两个能缓冲1个slot数据的RAM(单口RAM即 可),当向一块RAM写数据的时候,从另一块RAM读数据,然后送到处理单元处理,此 时,每块RAM的容量仅需2560bit即可。2块RAM加起来也只有5120bit的容量。
I另外巧妙的运用乒乓操作,还可以达到用低速模块处理高速数据流的效果。如图9所 示,数据缓冲模块采用了双口RAM,并在DPRAM后引入了一级数据预处理模块,这个数 据预处理可以根据需要是各种数据运算,比如在WCDMA设计中,对输入数据流的解扩、 解扰、去旋转等。假设端口A的输入数据流的速率为100Mb/s,乒乓操作的缓冲周期是 10ms。我们下面一起分析一下各个节点端口的数据速率。
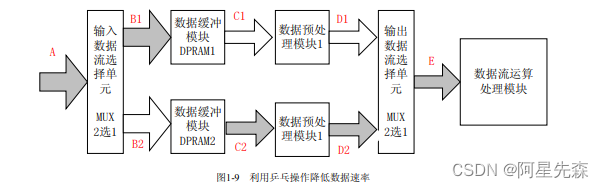
输入数据流A端口处数据速率为100Mb/s,在第1个缓冲周期10ms内,通过“输入数 据选择单元”,从B1到达DPRAM1。B1的数据速率也是100Mb/s,在10ms内,DPRAM1 要写入1Mb数据。同理在第2个10ms,数据流被切换到DPRAM2,端口B2的数据速率也 是100Mb/s,DPRAM2在第2个10ms被写入1Mb数据。周而复始,在第3个10ms,数据 流又切换到DPRAM1,DPRAM1被写入1Mb数据。 仔细分析一下,就会发现到第3个缓冲周期时,留给DPRAM1读取数据并送到“数据 预处理模块1”的时间一共是20Ms。有的同事比较困惑于DPRAM1的读数时间为什么是20ms,其实这一点完全可以实现。首先在在第2个缓冲周期,向DPRAM2写数据的10ms 内,DPRAM1可以进行读操作:另外在第1个缓冲周期的第5ms起(绝对时间为5ms时 刻),DPRAM1就可以边向500K以后的地址写数,边从地址0读数,到达10ms时, DPRAM1刚好写完了1Mb数据,并且读了500K数据,这个缓冲时间内DPRAM1读了5ms 的时间:另外在第3个缓冲周期的第5ms起(绝对时间为35ms时刻),同理可以边向500K 以后的地址写数,边从地址0读数,又读取了5个ms,所以截止DPRAM1第一个周期存入 的数据被完全覆盖以前,DPRAM1最多可以读取了20ms时间,而所需读取的数据为 1Mb,所以端口C1的数据速率为:1Mb/20ms=50Mb/s。因此“数据预处理模块1”的最低 数据吞吐能力也仅仅要求为50Mb/s。同理“数据预处理模块2”的最低数据吞吐能力也仅 仅要求为50Mb/s。换言之,通过乒乓操作,“数据预处理模块”的时序压力减轻了,所要求 的数据处理速率仅仅为输入数据速率的1/2。
通过乒乓操作实现低速模块处理高速数据的实质是:通过DPRAM这种缓存单元,实 现了数据流的串并转换,并行用“数据预处理模块l”和“数据预处理模块2”处理分流的 数据,是面积与速度互换原则的有一个体现!

