
热门标签
热门文章
- 1CSDN博客——“我的2014”年度征文活动火爆开启_配置管理学习的感悟和展望总结
- 2AndroidStudio期末大作业校园快递领取系统(Android课设,新手小白必看)_android studio大作业物流源代码
- 3【Python入门系列】第六篇:Python常用内置库总结_python内置库
- 4git clone error: RPC failed; HTTP 504 curl 22 The requested URL returned error: 504 Gateway Time-out
- 5键盘盲打练习打字软件 v6.30绿色版_键盘盲打练习入门程序
- 6Python之socket-UDP协议通信_sendaddr
- 7华为OD机试C++ - 悄悄话_华为od 悄悄话
- 8SQL SERVER之数据查询_sql server 无结算记录查询
- 9SSM+微信小程序网易云音乐设计与实现 毕业设计-附源码261620_音乐小程序论文
- 10go interface
当前位置: article > 正文
使用 ORPO 微调 Llama 3 更便宜、更快的统一微调技术(教程含源码)
作者:代码探险家 | 2024-07-02 16:45:51
赞
踩
使用 ORPO 微调 Llama 3 更便宜、更快的统一微调技术(教程含源码)
ORPO 是一种令人兴奋的新型微调技术,它将传统的监督微调和偏好调整阶段结合到一个过程中。这减少了训练所需的计算资源和时间。此外,实证结果表明,ORPO 在各种模型大小和基准上优于其他对齐方法。
在本文中,我们将使用 ORPO 和 TRL 库对新的 Llama 3 8B 模型进行微调。该代码
https://colab.research.google.com/drive/1eHNWg9gnaXErdAa8_mcvjMupbSS6rDvi?usp=sharing
- 1
ORPO
指令调整和偏好对齐是使大型语言模型 (LLM) 适应特定任务的基本技术。传统上,这涉及一个多阶段过程: 1/根据指令进行监督微调(SFT),以使模型适应目标域,然后是 2/偏好对齐方法,例如人类反馈强化学习 (RLHF) 或直接偏好优化(DPO) 以增加生成首选响应而非拒绝响应的可能性。
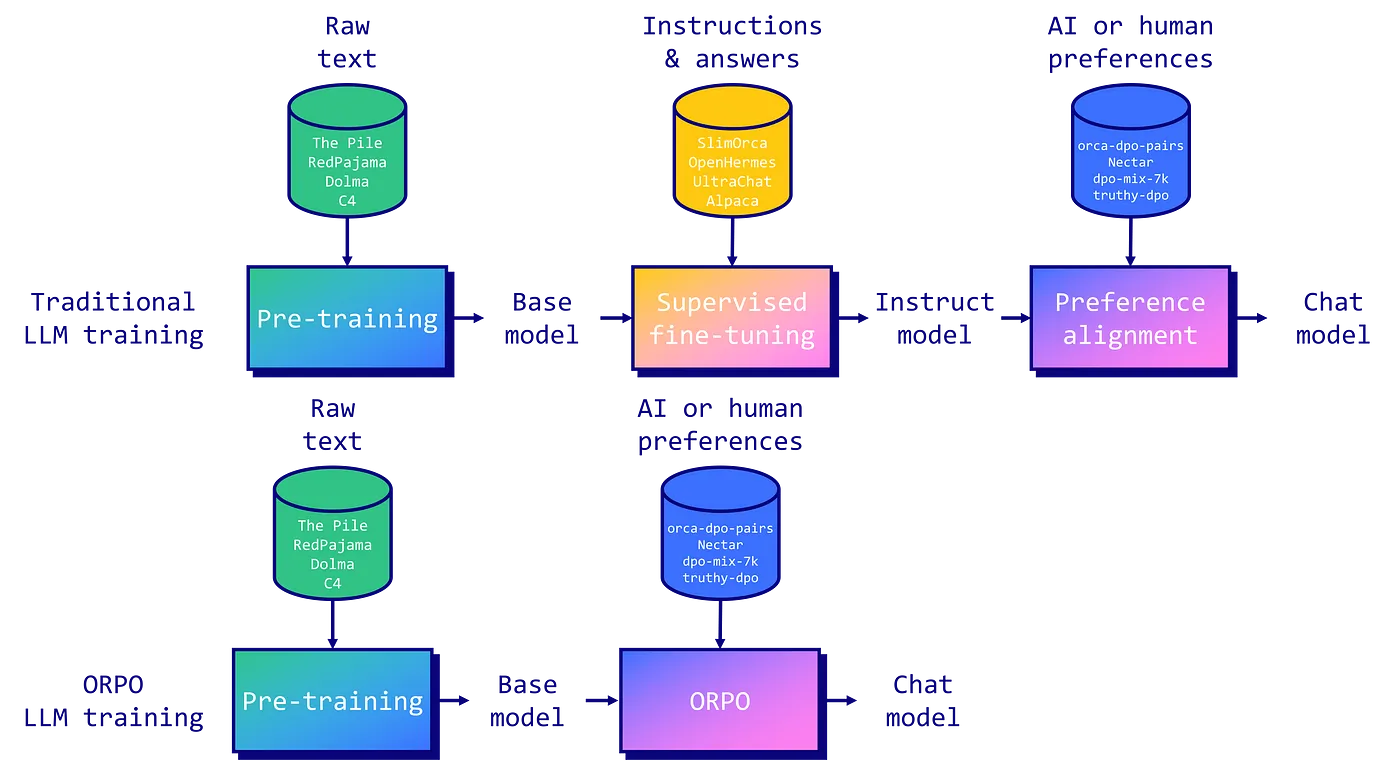
然而,研究人员发现了这种方法的局限性。虽然 SFT 有效地使模型适应所需的领域,但它无意中增加了在首选答案的同时生成不需要的答案的可能性。这就是为什么偏好调整阶段对于扩大首选输出和拒绝输出的可能性之间的差距是必要的。
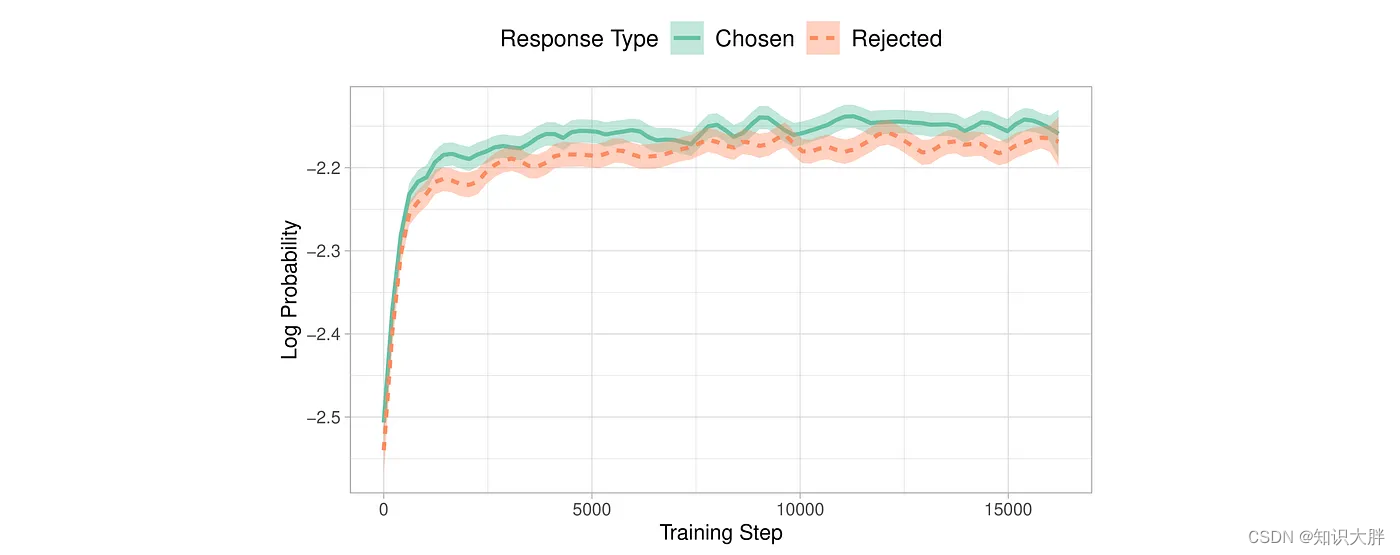
由Hong 和 Lee (2024)提出的ORPO 通过将指令调整和偏好对齐结合到一个单一的整体训练过程中,为这个问题提供了一个优雅的解决方案。 ORPO 修改了标准语言建模目标,将负对
推荐阅读
相关标签

