
- 1LeetCode:经典题之206、92 题解及延伸
- 2使用Flink CDC实时监控MySQL数据库变更_mysqlsource.
builder 参数 - 3IEEE SLT 2022论文丨如何利用x-vectors提升语音鉴伪系统性能?
- 4Python人工智能学习路线_python ai学习_python ai 学习路线
- 5Django——3.模板进阶(自定义过滤器、标签及模板继承)_django 过滤器
- 6一款比 Ollama 更好用的本地大语言模型 (LLM) 应用平台
- 7TCP/IP协议工作原理和工作流程_tcp工作原理
- 8pytorchOCR之DBnet(多类别文本检测1)_pytorch文本检测
- 9【OpenHarmony】Windows 平台搭建 DevEco Studio 开发环境 ① ( 安装 Node.js / ohpm | 安装配置 SDK | 环境变量配置 | 新建项目示例 )_deveco studio 开发windows
- 10买电脑_决策树买电脑
情感倾向性分析_情感倾向分析
赞
踩
概念















快来选一顿好吃的年夜饭:看看如何自定义数据集,实现文本分类中的情感分析任务
情感分析是自然语言处理领域一个老生常谈的任务。句子情感分析目的是为了判别说者的情感倾向,比如在某些话题上给出的的态度明确的观点,或者反映的情绪状态等。情感分析有着广泛应用,比如电商评论分析、舆情分析等。

环境介绍
-
PaddlePaddle框架,AI Studio平台已经默认安装最新版2.0。
-
PaddleNLP,深度兼容框架2.0,是飞桨框架2.0在NLP领域的最佳实践。
这里使用的是beta版本,马上也会发布rc版哦。AI Studio平台后续会默认安装PaddleNLP,在此之前可使用如下命令安装。
In [1]
- # 下载paddlenlp
- !pip install --upgrade paddlenlp==2.0.0b4 -i https://pypi.org/simple
Requirement already up-to-date: paddlenlp==2.0.0b4 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (2.0.0b4) Requirement already satisfied, skipping upgrade: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.0.0b4) (0.42.1) Requirement already satisfied, skipping upgrade: h5py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.0.0b4) (2.9.0) Requirement already satisfied, skipping upgrade: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.0.0b4) (4.1.0) Requirement already satisfied, skipping upgrade: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.0.0b4) (0.4.4) Requirement already satisfied, skipping upgrade: visualdl in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.0.0b4) (2.1.1) Requirement already satisfied, skipping upgrade: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.0.0b4) (1.2.2) Requirement already satisfied, skipping upgrade: numpy>=1.7 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp==2.0.0b4) (1.16.4) Requirement already satisfied, skipping upgrade: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp==2.0.0b4) (1.15.0) Requirement already satisfied, skipping upgrade: Flask-Babel>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp==2.0.0b4) (1.0.0) Requirement already satisfied, skipping upgrade: shellcheck-py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp==2.0.0b4) (0.7.1.1) Requirement already satisfied, skipping upgrade: Pillow>=7.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp==2.0.0b4) (7.1.2) Requirement already satisfied, skipping upgrade: flake8>=3.7.9 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp==2.0.0b4) (3.8.2) Requirement already satisfied, skipping upgrade: requests in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp==2.0.0b4) (2.22.0) Requirement already satisfied, skipping upgrade: flask>=1.1.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp==2.0.0b4) (1.1.1) Requirement already satisfied, skipping upgrade: bce-python-sdk in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp==2.0.0b4) (0.8.53) Requirement already satisfied, skipping upgrade: protobuf>=3.11.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp==2.0.0b4) (3.14.0) Requirement already satisfied, skipping upgrade: pre-commit in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp==2.0.0b4) (1.21.0) Requirement already satisfied, skipping upgrade: scikit-learn>=0.21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp==2.0.0b4) (0.22.1) Requirement already satisfied, skipping upgrade: Jinja2>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp==2.0.0b4) (2.10.1) Requirement already satisfied, skipping upgrade: Babel>=2.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp==2.0.0b4) (2.8.0) Requirement already satisfied, skipping upgrade: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp==2.0.0b4) (2019.3) Requirement already satisfied, skipping upgrade: pyflakes<2.3.0,>=2.2.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp==2.0.0b4) (2.2.0) Requirement already satisfied, skipping upgrade: pycodestyle<2.7.0,>=2.6.0a1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp==2.0.0b4) (2.6.0) Requirement already satisfied, skipping upgrade: importlib-metadata; python_version < "3.8" in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp==2.0.0b4) (0.23) Requirement already satisfied, skipping upgrade: mccabe<0.7.0,>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp==2.0.0b4) (0.6.1) Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp==2.0.0b4) (2.8) Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp==2.0.0b4) (2019.9.11) Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp==2.0.0b4) (3.0.4) Requirement already satisfied, skipping upgrade: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp==2.0.0b4) (1.25.6) Requirement already satisfied, skipping upgrade: itsdangerous>=0.24 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp==2.0.0b4) (1.1.0) Requirement already satisfied, skipping upgrade: Werkzeug>=0.15 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp==2.0.0b4) (0.16.0) Requirement already satisfied, skipping upgrade: click>=5.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp==2.0.0b4) (7.0) Requirement already satisfied, skipping upgrade: future>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl->paddlenlp==2.0.0b4) (0.18.0) Requirement already satisfied, skipping upgrade: pycryptodome>=3.8.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl->paddlenlp==2.0.0b4) (3.9.9) Requirement already satisfied, skipping upgrade: toml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp==2.0.0b4) (0.10.0) Requirement already satisfied, skipping upgrade: identify>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp==2.0.0b4) (1.4.10) Requirement already satisfied, skipping upgrade: nodeenv>=0.11.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp==2.0.0b4) (1.3.4) Requirement already satisfied, skipping upgrade: aspy.yaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp==2.0.0b4) (1.3.0) Requirement already satisfied, skipping upgrade: virtualenv>=15.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp==2.0.0b4) (16.7.9) Requirement already satisfied, skipping upgrade: cfgv>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp==2.0.0b4) (2.0.1) Requirement already satisfied, skipping upgrade: pyyaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp==2.0.0b4) (5.1.2) Requirement already satisfied, skipping upgrade: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp==2.0.0b4) (0.14.1) Requirement already satisfied, skipping upgrade: scipy>=0.17.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp==2.0.0b4) (1.3.0) Requirement already satisfied, skipping upgrade: MarkupSafe>=0.23 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Jinja2>=2.5->Flask-Babel>=1.0.0->visualdl->paddlenlp==2.0.0b4) (1.1.1) Requirement already satisfied, skipping upgrade: zipp>=0.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from importlib-metadata; python_version < "3.8"->flake8>=3.7.9->visualdl->paddlenlp==2.0.0b4) (0.6.0) Requirement already satisfied, skipping upgrade: more-itertools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from zipp>=0.5->importlib-metadata; python_version < "3.8"->flake8>=3.7.9->visualdl->paddlenlp==2.0.0b4) (7.2.0)
查看安装的版本
In [2]
- import paddle
- import paddlenlp
-
- print(paddle.__version__, paddlenlp.__version__)
2.0.0 2.0.0b4
PaddleNLP和Paddle框架是什么关系?

- Paddle框架是基础底座,提供深度学习任务全流程API。PaddleNLP基于Paddle框架开发,适用于NLP任务。
PaddleNLP中数据处理、数据集、组网单元等API未来会沉淀到框架paddle.text中。
- 代码中继承
class TSVDataset(paddle.io.Dataset)
使用飞桨完成深度学习任务的通用流程
-
数据集和数据处理
paddle.io.Dataset
paddle.io.DataLoader
paddlenlp.data -
组网和网络配置
paddle.nn.Embedding
paddlenlp.seq2vec paddle.nn.Linear
paddle.tanh
paddle.nn.CrossEntropyLoss
paddle.metric.Accuracy
paddle.optimizer
model.prepare
-
网络训练和评估
model.fit
model.evaluate -
预测 model.predict
In [3]
- import numpy as np
- from functools import partial
-
- import paddle.nn as nn
- import paddle.nn.functional as F
- import paddlenlp as ppnlp
- from paddlenlp.data import Pad, Stack, Tuple
- from paddlenlp.datasets import MapDatasetWrapper
-
- from utils import load_vocab, convert_example
数据集和数据处理
自定义数据集
映射式(map-style)数据集需要继承paddle.io.Dataset
-
__getitem__: 根据给定索引获取数据集中指定样本,在 paddle.io.DataLoader 中需要使用此函数通过下标获取样本。 -
__len__: 返回数据集样本个数, paddle.io.BatchSampler 中需要样本个数生成下标序列。
In [4]
- class SelfDefinedDataset(paddle.io.Dataset):
- def __init__(self, data):
- super(SelfDefinedDataset, self).__init__()
- self.data = data
-
- def __getitem__(self, idx):
- return self.data[idx]
-
- def __len__(self):
- return len(self.data)
-
- def get_labels(self):
- return ["0", "1"]
-
- def txt_to_list(file_name):
- res_list = []
- for line in open(file_name):
- res_list.append(line.strip().split('\t'))
- return res_list
-
- trainlst = txt_to_list('train.txt')
- devlst = txt_to_list('dev.txt')
- testlst = txt_to_list('test.txt')
-
- # 通过get_datasets()函数,将list数据转换为dataset。
- # get_datasets()可接收[list]参数,或[str]参数,根据自定义数据集的写法自由选择。
- # train_ds, dev_ds, test_ds = ppnlp.datasets.ChnSentiCorp.get_datasets(['train', 'dev', 'test'])
- train_ds, dev_ds, test_ds = SelfDefinedDataset.get_datasets([trainlst, devlst, testlst])
-

看看数据长什么样
In [5]
- label_list = train_ds.get_labels()
- print(label_list)
-
- for i in range(10):
- print (train_ds[i])
['0', '1'] ['赢在心理,输在出品!杨枝太酸,三文鱼熟了,酥皮焗杏汁杂果可以换个名(九唔搭八)', '0'] ['服务一般,客人多,服务员少,但食品很不错', '1'] ['東坡肉竟然有好多毛,問佢地點解,佢地仲話係咁架\ue107\ue107\ue107\ue107\ue107\ue107\ue107冇天理,第一次食東坡肉有毛,波羅包就幾好食', '0'] ['父亲节去的,人很多,口味还可以上菜快!但是结账的时候,算错了没有打折,我也忘记拿清单了。说好打8折的,收银员没有打,人太多一时自己也没有想起。不知道收银员忘记,还是故意那钱露入自己钱包。。', '0'] ['吃野味,吃个新鲜,你当然一定要来广州吃鹿肉啦*价格便宜,量好足,', '1'] ['味道几好服务都五错推荐鹅肝乳鸽飞鱼', '1'] ['作为老字号,水准保持算是不错,龟岗分店可能是位置问题,人不算多,基本不用等位,自从抢了券,去过好几次了,每次都可以打85以上的评分,算是可以了~粉丝煲每次必点,哈哈,鱼也不错,还会来帮衬的,楼下还可以免费停车!', '1'] ['边到正宗啊?味味都咸死人啦,粤菜讲求鲜甜,五知点解感多人话好吃。', '0'] ['环境卫生差,出品垃圾,冇下次,不知所为', '0'] ['和苑真是精致粤菜第一家,服务菜品都一流', '1']
数据处理
为了将原始数据处理成模型可以读入的格式,本项目将对数据作以下处理:
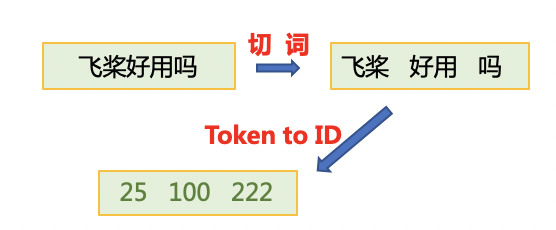
- 首先使用jieba切词,之后将jieba切完后的单词映射词表中单词id。
- 使用
paddle.io.DataLoader接口多线程异步加载数据。
其中用到了PaddleNLP中关于数据处理的API。PaddleNLP提供了许多关于NLP任务中构建有效的数据pipeline的常用API
| API | 简介 |
|---|---|
paddlenlp.data.Stack | 堆叠N个具有相同shape的输入数据来构建一个batch,它的输入必须具有相同的shape,输出便是这些输入的堆叠组成的batch数据。 |
paddlenlp.data.Pad | 堆叠N个输入数据来构建一个batch,每个输入数据将会被padding到N个输入数据中最大的长度 |
paddlenlp.data.Tuple | 将多个组batch的函数包装在一起 |
更多数据处理操作详见: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/data.md
In [6]
- # 下载词汇表文件word_dict.txt,用于构造词-id映射关系。
- !wget https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txt
-
- # 加载词表
- vocab = load_vocab('./senta_word_dict.txt')
-
- for k, v in vocab.items():
- print(k, v)
- break
--2021-02-06 16:47:39-- https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txt Resolving paddlenlp.bj.bcebos.com (paddlenlp.bj.bcebos.com)... 182.61.200.195, 182.61.200.229, 2409:8c00:6c21:10ad:0:ff:b00e:67d Connecting to paddlenlp.bj.bcebos.com (paddlenlp.bj.bcebos.com)|182.61.200.195|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 14600150 (14M) [text/plain] Saving to: ‘senta_word_dict.txt.2’ senta_word_dict.txt 100%[===================>] 13.92M 25.8MB/s in 0.5s 2021-02-06 16:47:39 (25.8 MB/s) - ‘senta_word_dict.txt.2’ saved [14600150/14600150] [PAD] 0
构造dataloder
下面的create_data_loader函数用于创建运行和预测时所需要的DataLoader对象。
-
paddle.io.DataLoader返回一个迭代器,该迭代器根据batch_sampler指定的顺序迭代返回dataset数据。异步加载数据。 -
batch_sampler:DataLoader通过 batch_sampler 产生的mini-batch索引列表来 dataset 中索引样本并组成mini-batch -
collate_fn:指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是prepare_input函数,对产生的数据进行pad操作,并返回实际长度等。
In [7]
- # Reads data and generates mini-batches.
- def create_dataloader(dataset,
- trans_function=None,
- mode='train',
- batch_size=1,
- pad_token_id=0,
- batchify_fn=None):
- if trans_function:
- dataset = dataset.apply(trans_function, lazy=True)
-
- # return_list 数据是否以list形式返回
- # collate_fn 指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是`prepare_input`函数,对产生的数据进行pad操作,并返回实际长度等。
- dataloader = paddle.io.DataLoader(
- dataset,
- return_list=True,
- batch_size=batch_size,
- collate_fn=batchify_fn)
-
- return dataloader
-
- # python中的偏函数partial,把一个函数的某些参数固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
- trans_function = partial(
- convert_example,
- vocab=vocab,
- unk_token_id=vocab.get('[UNK]', 1),
- is_test=False)
-
- # 将读入的数据batch化处理,便于模型batch化运算。
- # batch中的每个句子将会padding到这个batch中的文本最大长度batch_max_seq_len。
- # 当文本长度大于batch_max_seq时,将会截断到batch_max_seq_len;当文本长度小于batch_max_seq时,将会padding补齐到batch_max_seq_len.
- batchify_fn = lambda samples, fn=Tuple(
- Pad(axis=0, pad_val=vocab['[PAD]']), # input_ids
- Stack(dtype="int64"), # seq len
- Stack(dtype="int64") # label
- ): [data for data in fn(samples)]
-
-
- train_loader = create_dataloader(
- train_ds,
- trans_function=trans_function,
- batch_size=128,
- mode='train',
- batchify_fn=batchify_fn)
- dev_loader = create_dataloader(
- dev_ds,
- trans_function=trans_function,
- batch_size=128,
- mode='validation',
- batchify_fn=batchify_fn)
- test_loader = create_dataloader(
- test_ds,
- trans_function=trans_function,
- batch_size=128,
- mode='test',
- batchify_fn=batchify_fn)
模型搭建
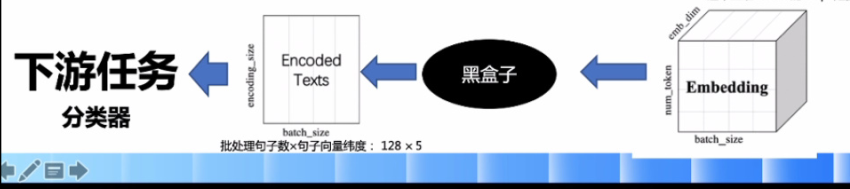
使用LSTMencoder搭建一个BiLSTM模型用于进行句子建模,得到句子的向量表示。
然后接一个线性变换层,完成二分类任务。
paddle.nn.Embedding组建word-embedding层ppnlp.seq2vec.LSTMEncoder组建句子建模层paddle.nn.Linear构造二分类器
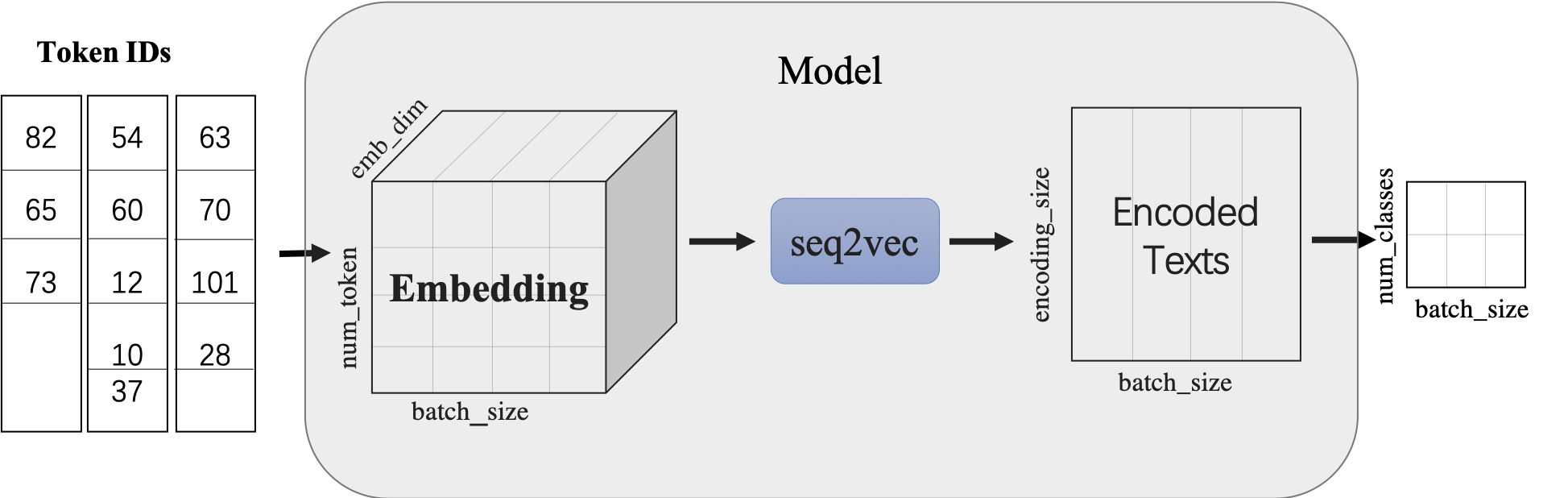
图1:seq2vec示意图
- 除LSTM外,
seq2vec还提供了许多语义表征方法,详细可参考:seq2vec介绍
In [8]
- class LSTMModel(nn.Layer):
- def __init__(self,
- vocab_size,
- num_classes,
- emb_dim=128,
- padding_idx=0,
- lstm_hidden_size=198,
- direction='forward',
- lstm_layers=1,
- dropout_rate=0,
- pooling_type=None,
- fc_hidden_size=96):
- super().__init__()
-
- # 首先将输入word id 查表后映射成 word embedding
- self.embedder = nn.Embedding(
- num_embeddings=vocab_size,
- embedding_dim=emb_dim,
- padding_idx=padding_idx)
-
- # 将word embedding经过LSTMEncoder变换到文本语义表征空间中
- self.lstm_encoder = ppnlp.seq2vec.LSTMEncoder(
- emb_dim,
- lstm_hidden_size,
- num_layers=lstm_layers,
- direction=direction,
- dropout=dropout_rate,
- pooling_type=pooling_type)
-
- # LSTMEncoder.get_output_dim()方法可以获取经过encoder之后的文本表示hidden_size
- self.fc = nn.Linear(self.lstm_encoder.get_output_dim(), fc_hidden_size)
-
- # 最后的分类器
- self.output_layer = nn.Linear(fc_hidden_size, num_classes)
-
- def forward(self, text, seq_len):
- # text shape: (batch_size, num_tokens)
- # print('input :', text.shape)
-
- # Shape: (batch_size, num_tokens, embedding_dim)
- embedded_text = self.embedder(text)
- # print('after word-embeding:', embedded_text.shape)
-
- # Shape: (batch_size, num_tokens, num_directions*lstm_hidden_size)
- # num_directions = 2 if direction is 'bidirectional' else 1
- text_repr = self.lstm_encoder(embedded_text, sequence_length=seq_len)
- # print('after lstm:', text_repr.shape)
-
-
- # Shape: (batch_size, fc_hidden_size)
- fc_out = paddle.tanh(self.fc(text_repr))
- # print('after Linear classifier:', fc_out.shape)
-
- # Shape: (batch_size, num_classes)
- logits = self.output_layer(fc_out)
- # print('output:', logits.shape)
-
- # probs 分类概率值
- probs = F.softmax(logits, axis=-1)
- # print('output probability:', probs.shape)
- return probs
-
- model= LSTMModel(
- len(vocab),
- len(label_list),
- direction='bidirectional',
- padding_idx=vocab['[PAD]'])
- model = paddle.Model(model)
模型配置和训练
模型配置
In [9]
- optimizer = paddle.optimizer.Adam(
- parameters=model.parameters(), learning_rate=5e-5)
-
- loss = paddle.nn.CrossEntropyLoss()
- metric = paddle.metric.Accuracy()
-
- model.prepare(optimizer, loss, metric)
In [10]
- # 设置visualdl路径
- log_dir = './visualdl'
- callback = paddle.callbacks.VisualDL(log_dir=log_dir)
模型训练
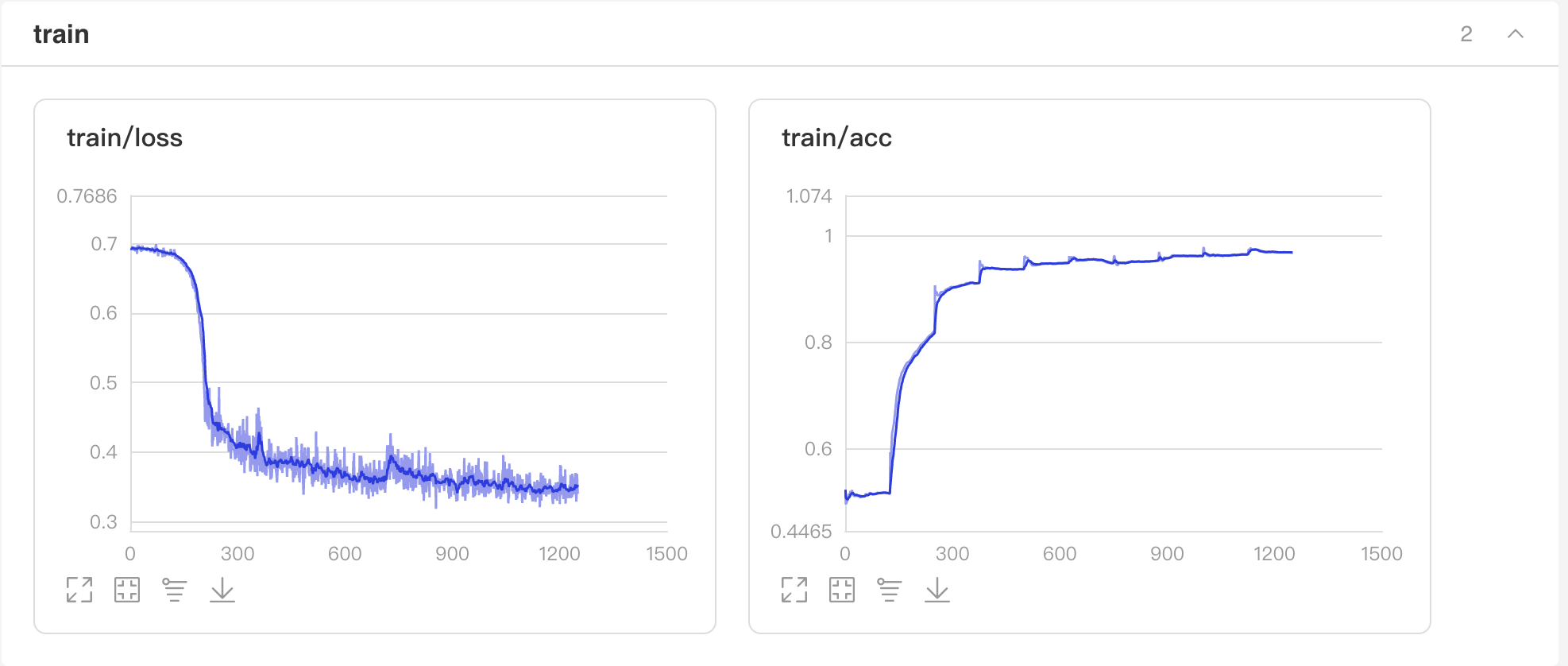
训练过程中会输出loss、acc等信息。这里设置了10个epoch,在训练集上准确率约97%。

In [11]
model.fit(train_loader, dev_loader, epochs=10, save_dir='./checkpoints', save_freq=5, callbacks=callback)The loss value printed in the log is the current step, and the metric is the average value of previous step. Epoch 1/10
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache Loading model cost 0.708 seconds. Prefix dict has been built successfully. /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and
step 10/125 - loss: 0.6971 - acc: 0.4813 - 192ms/step step 20/125 - loss: 0.6926 - acc: 0.4957 - 138ms/step step 30/125 - loss: 0.6924 - acc: 0.5102 - 120ms/step step 40/125 - loss: 0.6910 - acc: 0.5135 - 110ms/step step 50/125 - loss: 0.6887 - acc: 0.5166 - 105ms/step step 60/125 - loss: 0.6951 - acc: 0.5154 - 101ms/step step 70/125 - loss: 0.6930 - acc: 0.5157 - 98ms/step step 80/125 - loss: 0.6889 - acc: 0.5138 - 96ms/step step 90/125 - loss: 0.6917 - acc: 0.5134 - 95ms/step step 100/125 - loss: 0.6866 - acc: 0.5143 - 95ms/step step 110/125 - loss: 0.6824 - acc: 0.5141 - 95ms/step step 120/125 - loss: 0.6831 - acc: 0.5202 - 94ms/step step 125/125 - loss: 0.6840 - acc: 0.5291 - 92ms/step save checkpoint at /home/aistudio/checkpoints/0 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 10/84 - loss: 0.6813 - acc: 0.8094 - 86ms/step step 20/84 - loss: 0.6814 - acc: 0.8141 - 70ms/step step 30/84 - loss: 0.6817 - acc: 0.8128 - 66ms/step step 40/84 - loss: 0.6807 - acc: 0.8113 - 63ms/step step 50/84 - loss: 0.6829 - acc: 0.8105 - 62ms/step step 60/84 - loss: 0.6790 - acc: 0.8102 - 60ms/step step 70/84 - loss: 0.6821 - acc: 0.8122 - 59ms/step step 80/84 - loss: 0.6818 - acc: 0.8117 - 58ms/step step 84/84 - loss: 0.6809 - acc: 0.8123 - 56ms/step Eval samples: 10646 Epoch 2/10 step 10/125 - loss: 0.6840 - acc: 0.7734 - 105ms/step step 20/125 - loss: 0.6732 - acc: 0.7992 - 94ms/step step 30/125 - loss: 0.6667 - acc: 0.8057 - 93ms/step step 40/125 - loss: 0.6572 - acc: 0.7963 - 91ms/step step 50/125 - loss: 0.6399 - acc: 0.7873 - 91ms/step step 60/125 - loss: 0.6104 - acc: 0.7980 - 89ms/step step 70/125 - loss: 0.5418 - acc: 0.8084 - 89ms/step step 80/125 - loss: 0.4695 - acc: 0.8139 - 88ms/step step 90/125 - loss: 0.4383 - acc: 0.8186 - 88ms/step step 100/125 - loss: 0.4254 - acc: 0.8241 - 88ms/step step 110/125 - loss: 0.4109 - acc: 0.8310 - 88ms/step step 120/125 - loss: 0.4272 - acc: 0.8370 - 87ms/step step 125/125 - loss: 0.3959 - acc: 0.8385 - 86ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 10/84 - loss: 0.4385 - acc: 0.8984 - 82ms/step step 20/84 - loss: 0.4225 - acc: 0.9000 - 67ms/step step 30/84 - loss: 0.4100 - acc: 0.8990 - 64ms/step step 40/84 - loss: 0.3847 - acc: 0.9025 - 62ms/step step 50/84 - loss: 0.4368 - acc: 0.9009 - 61ms/step step 60/84 - loss: 0.4361 - acc: 0.8992 - 60ms/step step 70/84 - loss: 0.4122 - acc: 0.8987 - 60ms/step step 80/84 - loss: 0.4274 - acc: 0.8991 - 58ms/step step 84/84 - loss: 0.4525 - acc: 0.8996 - 56ms/step Eval samples: 10646 Epoch 3/10 step 10/125 - loss: 0.4590 - acc: 0.8961 - 108ms/step step 20/125 - loss: 0.4129 - acc: 0.9062 - 96ms/step step 30/125 - loss: 0.4015 - acc: 0.9091 - 92ms/step step 40/125 - loss: 0.4158 - acc: 0.9127 - 89ms/step step 50/125 - loss: 0.4060 - acc: 0.9145 - 89ms/step step 60/125 - loss: 0.3665 - acc: 0.9195 - 87ms/step step 70/125 - loss: 0.3572 - acc: 0.9233 - 87ms/step step 80/125 - loss: 0.3764 - acc: 0.9243 - 86ms/step step 90/125 - loss: 0.3540 - acc: 0.9253 - 86ms/step step 100/125 - loss: 0.3687 - acc: 0.9254 - 87ms/step step 110/125 - loss: 0.3746 - acc: 0.9268 - 87ms/step step 120/125 - loss: 0.3848 - acc: 0.9283 - 86ms/step step 125/125 - loss: 0.3699 - acc: 0.9282 - 85ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 10/84 - loss: 0.3962 - acc: 0.9391 - 83ms/step step 20/84 - loss: 0.3826 - acc: 0.9395 - 68ms/step step 30/84 - loss: 0.3804 - acc: 0.9380 - 64ms/step step 40/84 - loss: 0.3629 - acc: 0.9395 - 61ms/step step 50/84 - loss: 0.3888 - acc: 0.9381 - 60ms/step step 60/84 - loss: 0.3601 - acc: 0.9400 - 59ms/step step 70/84 - loss: 0.3860 - acc: 0.9385 - 58ms/step step 80/84 - loss: 0.3741 - acc: 0.9391 - 57ms/step step 84/84 - loss: 0.3629 - acc: 0.9400 - 55ms/step Eval samples: 10646 Epoch 4/10 step 10/125 - loss: 0.4101 - acc: 0.9273 - 104ms/step step 20/125 - loss: 0.3851 - acc: 0.9348 - 94ms/step step 30/125 - loss: 0.3655 - acc: 0.9375 - 91ms/step step 40/125 - loss: 0.3867 - acc: 0.9398 - 89ms/step step 50/125 - loss: 0.3850 - acc: 0.9411 - 89ms/step step 60/125 - loss: 0.3467 - acc: 0.9452 - 89ms/step step 70/125 - loss: 0.3454 - acc: 0.9475 - 88ms/step step 80/125 - loss: 0.3606 - acc: 0.9467 - 88ms/step step 90/125 - loss: 0.3544 - acc: 0.9469 - 89ms/step step 100/125 - loss: 0.3511 - acc: 0.9463 - 89ms/step step 110/125 - loss: 0.3551 - acc: 0.9465 - 89ms/step step 120/125 - loss: 0.3743 - acc: 0.9475 - 88ms/step step 125/125 - loss: 0.3614 - acc: 0.9470 - 87ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 10/84 - loss: 0.3768 - acc: 0.9445 - 83ms/step step 20/84 - loss: 0.3730 - acc: 0.9477 - 67ms/step step 30/84 - loss: 0.3660 - acc: 0.9464 - 64ms/step step 40/84 - loss: 0.3615 - acc: 0.9479 - 62ms/step step 50/84 - loss: 0.3692 - acc: 0.9466 - 61ms/step step 60/84 - loss: 0.3472 - acc: 0.9475 - 60ms/step step 70/84 - loss: 0.3890 - acc: 0.9464 - 59ms/step step 80/84 - loss: 0.3742 - acc: 0.9464 - 58ms/step step 84/84 - loss: 0.3475 - acc: 0.9474 - 56ms/step Eval samples: 10646 Epoch 5/10 step 10/125 - loss: 0.3871 - acc: 0.9359 - 105ms/step step 20/125 - loss: 0.3757 - acc: 0.9426 - 94ms/step step 30/125 - loss: 0.3538 - acc: 0.9461 - 91ms/step step 40/125 - loss: 0.3755 - acc: 0.9484 - 88ms/step step 50/125 - loss: 0.3766 - acc: 0.9487 - 87ms/step step 60/125 - loss: 0.3514 - acc: 0.9491 - 86ms/step step 70/125 - loss: 0.3369 - acc: 0.9516 - 86ms/step step 80/125 - loss: 0.3452 - acc: 0.9518 - 86ms/step step 90/125 - loss: 0.3420 - acc: 0.9525 - 86ms/step step 100/125 - loss: 0.3471 - acc: 0.9525 - 86ms/step step 110/125 - loss: 0.3501 - acc: 0.9533 - 86ms/step step 120/125 - loss: 0.3681 - acc: 0.9543 - 86ms/step step 125/125 - loss: 0.3555 - acc: 0.9541 - 85ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 10/84 - loss: 0.3788 - acc: 0.9477 - 87ms/step step 20/84 - loss: 0.3725 - acc: 0.9492 - 70ms/step step 30/84 - loss: 0.3631 - acc: 0.9510 - 66ms/step step 40/84 - loss: 0.3571 - acc: 0.9531 - 63ms/step step 50/84 - loss: 0.3687 - acc: 0.9525 - 62ms/step step 60/84 - loss: 0.3433 - acc: 0.9535 - 61ms/step step 70/84 - loss: 0.3743 - acc: 0.9523 - 59ms/step step 80/84 - loss: 0.3591 - acc: 0.9529 - 58ms/step step 84/84 - loss: 0.3475 - acc: 0.9538 - 56ms/step Eval samples: 10646 Epoch 6/10 step 10/125 - loss: 0.3748 - acc: 0.9461 - 104ms/step step 20/125 - loss: 0.3684 - acc: 0.9535 - 94ms/step step 30/125 - loss: 0.3509 - acc: 0.9555 - 91ms/step step 40/125 - loss: 0.3707 - acc: 0.9563 - 90ms/step step 50/125 - loss: 0.3548 - acc: 0.9573 - 90ms/step step 60/125 - loss: 0.3348 - acc: 0.9600 - 89ms/step step 70/125 - loss: 0.3331 - acc: 0.9619 - 88ms/step step 80/125 - loss: 0.3374 - acc: 0.9614 - 88ms/step step 90/125 - loss: 0.3319 - acc: 0.9615 - 88ms/step step 100/125 - loss: 0.3395 - acc: 0.9612 - 88ms/step step 110/125 - loss: 0.3424 - acc: 0.9614 - 87ms/step step 120/125 - loss: 0.3697 - acc: 0.9620 - 87ms/step step 125/125 - loss: 0.3448 - acc: 0.9616 - 85ms/step save checkpoint at /home/aistudio/checkpoints/5 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 10/84 - loss: 0.3758 - acc: 0.9547 - 82ms/step step 20/84 - loss: 0.3649 - acc: 0.9555 - 68ms/step step 30/84 - loss: 0.3578 - acc: 0.9549 - 65ms/step step 40/84 - loss: 0.3503 - acc: 0.9572 - 63ms/step step 50/84 - loss: 0.3733 - acc: 0.9566 - 62ms/step step 60/84 - loss: 0.3445 - acc: 0.9570 - 61ms/step step 70/84 - loss: 0.3643 - acc: 0.9557 - 60ms/step step 80/84 - loss: 0.3518 - acc: 0.9559 - 59ms/step step 84/84 - loss: 0.3537 - acc: 0.9564 - 57ms/step Eval samples: 10646 Epoch 7/10 step 10/125 - loss: 0.3693 - acc: 0.9516 - 108ms/step step 20/125 - loss: 0.3702 - acc: 0.9520 - 98ms/step step 30/125 - loss: 0.3448 - acc: 0.9557 - 94ms/step step 40/125 - loss: 0.3677 - acc: 0.9572 - 91ms/step step 50/125 - loss: 0.3457 - acc: 0.9594 - 89ms/step step 60/125 - loss: 0.3301 - acc: 0.9618 - 88ms/step step 70/125 - loss: 0.3277 - acc: 0.9637 - 87ms/step step 80/125 - loss: 0.3331 - acc: 0.9637 - 87ms/step step 90/125 - loss: 0.3305 - acc: 0.9635 - 87ms/step step 100/125 - loss: 0.3339 - acc: 0.9633 - 87ms/step step 110/125 - loss: 0.3364 - acc: 0.9640 - 87ms/step step 120/125 - loss: 0.3675 - acc: 0.9648 - 87ms/step step 125/125 - loss: 0.3410 - acc: 0.9645 - 85ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 10/84 - loss: 0.3716 - acc: 0.9531 - 82ms/step step 20/84 - loss: 0.3634 - acc: 0.9535 - 68ms/step step 30/84 - loss: 0.3656 - acc: 0.9544 - 64ms/step step 40/84 - loss: 0.3552 - acc: 0.9559 - 62ms/step step 50/84 - loss: 0.3683 - acc: 0.9553 - 61ms/step step 60/84 - loss: 0.3359 - acc: 0.9552 - 59ms/step step 70/84 - loss: 0.3762 - acc: 0.9547 - 58ms/step step 80/84 - loss: 0.3609 - acc: 0.9552 - 57ms/step step 84/84 - loss: 0.3484 - acc: 0.9560 - 55ms/step Eval samples: 10646 Epoch 8/10 step 10/125 - loss: 0.3605 - acc: 0.9555 - 104ms/step step 20/125 - loss: 0.3592 - acc: 0.9625 - 95ms/step step 30/125 - loss: 0.3441 - acc: 0.9643 - 91ms/step step 40/125 - loss: 0.3638 - acc: 0.9639 - 89ms/step step 50/125 - loss: 0.3421 - acc: 0.9655 - 89ms/step step 60/125 - loss: 0.3277 - acc: 0.9673 - 87ms/step step 70/125 - loss: 0.3255 - acc: 0.9685 - 86ms/step step 80/125 - loss: 0.3280 - acc: 0.9681 - 86ms/step step 90/125 - loss: 0.3278 - acc: 0.9682 - 86ms/step step 100/125 - loss: 0.3317 - acc: 0.9677 - 86ms/step step 110/125 - loss: 0.3315 - acc: 0.9682 - 86ms/step step 120/125 - loss: 0.3636 - acc: 0.9689 - 86ms/step step 125/125 - loss: 0.3386 - acc: 0.9686 - 84ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 10/84 - loss: 0.3705 - acc: 0.9570 - 85ms/step step 20/84 - loss: 0.3633 - acc: 0.9598 - 70ms/step step 30/84 - loss: 0.3593 - acc: 0.9607 - 65ms/step step 40/84 - loss: 0.3519 - acc: 0.9604 - 63ms/step step 50/84 - loss: 0.3639 - acc: 0.9602 - 62ms/step step 60/84 - loss: 0.3323 - acc: 0.9599 - 62ms/step step 70/84 - loss: 0.3648 - acc: 0.9590 - 61ms/step step 80/84 - loss: 0.3474 - acc: 0.9594 - 60ms/step step 84/84 - loss: 0.3425 - acc: 0.9600 - 57ms/step Eval samples: 10646 Epoch 9/10 step 10/125 - loss: 0.3569 - acc: 0.9578 - 105ms/step step 20/125 - loss: 0.3518 - acc: 0.9668 - 96ms/step step 30/125 - loss: 0.3406 - acc: 0.9672 - 91ms/step step 40/125 - loss: 0.3612 - acc: 0.9664 - 89ms/step step 50/125 - loss: 0.3390 - acc: 0.9673 - 88ms/step step 60/125 - loss: 0.3244 - acc: 0.9694 - 87ms/step step 70/125 - loss: 0.3236 - acc: 0.9708 - 87ms/step step 80/125 - loss: 0.3252 - acc: 0.9706 - 87ms/step step 90/125 - loss: 0.3256 - acc: 0.9706 - 87ms/step step 100/125 - loss: 0.3314 - acc: 0.9704 - 87ms/step step 110/125 - loss: 0.3290 - acc: 0.9707 - 87ms/step step 120/125 - loss: 0.3601 - acc: 0.9714 - 87ms/step step 125/125 - loss: 0.3265 - acc: 0.9711 - 85ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 10/84 - loss: 0.3656 - acc: 0.9594 - 84ms/step step 20/84 - loss: 0.3503 - acc: 0.9621 - 68ms/step step 30/84 - loss: 0.3611 - acc: 0.9617 - 64ms/step step 40/84 - loss: 0.3493 - acc: 0.9619 - 62ms/step step 50/84 - loss: 0.3844 - acc: 0.9616 - 61ms/step step 60/84 - loss: 0.3401 - acc: 0.9607 - 59ms/step step 70/84 - loss: 0.3646 - acc: 0.9592 - 58ms/step step 80/84 - loss: 0.3482 - acc: 0.9594 - 57ms/step step 84/84 - loss: 0.3522 - acc: 0.9601 - 55ms/step Eval samples: 10646 Epoch 10/10 step 10/125 - loss: 0.3544 - acc: 0.9586 - 122ms/step step 20/125 - loss: 0.3471 - acc: 0.9672 - 105ms/step step 30/125 - loss: 0.3355 - acc: 0.9690 - 98ms/step step 40/125 - loss: 0.3596 - acc: 0.9689 - 95ms/step step 50/125 - loss: 0.3382 - acc: 0.9700 - 93ms/step step 60/125 - loss: 0.3217 - acc: 0.9717 - 91ms/step step 70/125 - loss: 0.3222 - acc: 0.9732 - 90ms/step step 80/125 - loss: 0.3215 - acc: 0.9732 - 89ms/step step 90/125 - loss: 0.3250 - acc: 0.9731 - 89ms/step step 100/125 - loss: 0.3307 - acc: 0.9729 - 88ms/step step 110/125 - loss: 0.3267 - acc: 0.9730 - 88ms/step step 120/125 - loss: 0.3576 - acc: 0.9738 - 88ms/step step 125/125 - loss: 0.3253 - acc: 0.9734 - 86ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 10/84 - loss: 0.3602 - acc: 0.9609 - 85ms/step step 20/84 - loss: 0.3520 - acc: 0.9625 - 70ms/step step 30/84 - loss: 0.3555 - acc: 0.9633 - 66ms/step step 40/84 - loss: 0.3464 - acc: 0.9635 - 64ms/step step 50/84 - loss: 0.3675 - acc: 0.9634 - 63ms/step step 60/84 - loss: 0.3309 - acc: 0.9632 - 62ms/step step 70/84 - loss: 0.3578 - acc: 0.9618 - 60ms/step step 80/84 - loss: 0.3434 - acc: 0.9620 - 59ms/step step 84/84 - loss: 0.3476 - acc: 0.9627 - 57ms/step Eval samples: 10646 save checkpoint at /home/aistudio/checkpoints/final
启动VisualDL查看训练过程可视化结果
启动步骤:
- 1、切换到本界面左侧「可视化」
- 2、日志文件路径选择 'visualdl'
- 3、点击「启动VisualDL」后点击「打开VisualDL」,即可查看可视化结果: Accuracy和Loss的实时变化趋势如下:
In [12]
- results = model.evaluate(dev_loader)
- print("Finally test acc: %.5f" % results['acc'])
Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 10/84 - loss: 0.3602 - acc: 0.9609 - 84ms/step step 20/84 - loss: 0.3520 - acc: 0.9625 - 69ms/step step 30/84 - loss: 0.3555 - acc: 0.9633 - 65ms/step step 40/84 - loss: 0.3464 - acc: 0.9635 - 63ms/step step 50/84 - loss: 0.3675 - acc: 0.9634 - 62ms/step step 60/84 - loss: 0.3309 - acc: 0.9632 - 60ms/step step 70/84 - loss: 0.3578 - acc: 0.9618 - 59ms/step step 80/84 - loss: 0.3434 - acc: 0.9620 - 58ms/step step 84/84 - loss: 0.3476 - acc: 0.9627 - 55ms/step Eval samples: 10646 Finally test acc: 0.96271
预测
In [13]
- label_map = {0: 'negative', 1: 'positive'}
- results = model.predict(test_loader, batch_size=128)[0]
- predictions = []
-
- for batch_probs in results:
- # 映射分类label
- idx = np.argmax(batch_probs, axis=-1)
- idx = idx.tolist()
- labels = [label_map[i] for i in idx]
- predictions.extend(labels)
-
- # 看看预测数据前5个样例分类结果
- for idx, data in enumerate(test_ds.data[:10]):
- print('Data: {} \t Label: {}'.format(data[0], predictions[idx]))
Predict begin... step 42/42 [==============================] - ETA: 3s - 88ms/ste - ETA: 3s - 97ms/ste - ETA: 3s - 94ms/ste - ETA: 3s - 94ms/ste - ETA: 2s - 86ms/ste - ETA: 2s - 82ms/ste - ETA: 2s - 79ms/ste - ETA: 1s - 76ms/ste - ETA: 1s - 74ms/ste - ETA: 1s - 72ms/ste - ETA: 1s - 71ms/ste - ETA: 1s - 69ms/ste - ETA: 1s - 68ms/ste - ETA: 0s - 68ms/ste - ETA: 0s - 67ms/ste - ETA: 0s - 66ms/ste - ETA: 0s - 66ms/ste - ETA: 0s - 65ms/ste - ETA: 0s - 64ms/ste - ETA: 0s - 61ms/ste - 59ms/step Predict samples: 5353 Data: 楼面经理服务态度极差,等位和埋单都差,楼面小妹还挺好 Label: negative Data: 欺负北方人没吃过鲍鱼是怎么着?简直敷衍到可笑的程度,团购连青菜都是两人份?!难吃到死,菜色还特别可笑,什么时候粤菜的小菜改成拍黄瓜了?!把团购客人当傻子,可这满大厅的傻子谁还会再来?! Label: negative Data: 如果大家有时间而且不怕麻烦的话可以去这里试试,点一个饭等左2个钟,没错!是两个钟!期间催了n遍都说马上到,结果?呵呵。乳鸽的味道,太咸,可能不新鲜吧……要用重口味盖住异味。上菜超级慢!中途还搞什么表演,麻烦有人手的话就上菜啊,表什么演?!?!要大家饿着看表演吗?最后结账还算错单,我真心服了……有一种店叫不会有下次,大概就是指它吧 Label: negative Data: 偌大的一个大厅就一个人点菜,点菜速度超级慢,菜牌上多个菜停售,连续点了两个没标停售的菜也告知没有,粥上来是凉的,榴莲酥火大了,格格肉超级油腻而且咸?????? Label: negative Data: 泥撕雞超級好吃!!!吃了一個再叫一個還想打包的節奏! Label: positive Data: 作为地道的广州人,从小就跟着家人在西关品尝各式美食,今日带着家中长辈来这个老字号泮溪酒家真实失望透顶,出品差、服务差、洗手间邋遢弥漫着浓郁尿骚味、丢广州人的脸、丢广州老字号的脸。 Label: negative Data: 辣味道很赞哦!猪肚鸡一直是我们的最爱,每次来都必点,服务很给力,环境很好,值得分享哦!西洋菜 Label: positive Data: 第一次吃到這麼脏的火鍋:吃着吃著吃出一條尾指粗的黑毛毛蟲——惡心!脏!!!第一次吃到這麼無誠信的火鍋服務:我們呼喚人員時,某女部長立即使服務員迅速取走蟲所在的碗,任我們多次叫「放下」論理,她們也置若罔聞轉身將蟲毁屍滅跡,還嘻皮笑臉辯稱只是把碗換走,態度行為惡劣——奸詐!毫無誠信!!爛!!!當然還有剛坐下時的情形:第一次吃到這樣的火鍋:所有肉食熟食都上桌了,鍋底遲遲沒上,足足等了半小時才姍姍來遲;---差!!第一次吃到這樣的火鍋:1元雞鍋、1碟6塊小牛肉、1碟小腐皮、1碟5塊裝的普通肥牛、1碟數片的細碎牛肚結帳便2百多元;---不值!!以下省略千字差評......白云路的稻香是最差、最失禮的稻香,天河城、華廈的都比它好上過萬倍!!白云路的稻香是史上最差的餐廳!!! Label: negative Data: 文昌鸡份量很少且很咸,其他菜味道很一般!服务态度差差差!还要10%的服务费、 Label: negative Data: 这个网站的评价真是越来越不可信了,搞不懂为什么这么多好评。真的是很一般,不要迷信什么哪里回来的大厨吧。环境和出品若是当作普通茶餐厅来看待就还说得过去,但是价格又不是茶餐厅的价格,这就很尴尬了。。服务也是有待提高。 Label: negative
这里只采用了一个基础的模型,就得到了较高的的准确率。
可以试试预训练模型,能得到更好的效果!参考如何通过预训练模型Fine-tune下游任务

