
热门标签
热门文章
- 1Python(四):Pycharm的安装配置_python charm配置
- 2websocket 使用方法和步骤详解_websocket使用
- 3数据库安全:MySQL安全配置,MySQL安全基线检查加固_数据库安全基线
- 4CentOS7中一键安装openstack_packstack --allinone一直testing
- 5CorelDRAW Graphics Suite2024中文免费永久版专业的图形设计软件_coreldraw的免费版本
- 6智慧城市的新宠儿:会“思考”的井盖
- 7windows下kafka的环境配置及rdkafka库的应用_windows下安装的librdkafkacpp rdkafka -v
- 8查看当前分支是从那个分支拉来的_怎么查看本地分支是从哪个分支拉出来的?
- 9张大哥笔记:2024年公众号赚钱的8个方法_公众号赞赏
- 10cuda、torch、torchvision对应版本以及安装_torchvision版本
当前位置: article > 正文
GQA分组注意力机制_grouped query attention
作者:代码探险家 | 2024-08-06 05:44:56
赞
踩
grouped query attention
一、目录
- 定义
- demo
- GQA attention 注意力需要多大的kv cache缓存空间。
二、实现
- 定义
grouped query attention(GQA)
1 GQA 原理与优点:将query 进行分组,每组query 参数共享一份key,value, 从而使key, value 矩阵变小。
2. 优点: 降低内存读取模型权重的时间开销:由于Key矩阵和Value矩阵数量变少了,因此权重参数量也减少了,需要读取到内存的数量量少了,因此减少了读取权重的等待时间。
3. 效果(并未降低模型性能):GQA通过设置合适的分组大小,可以和MQA的推理性能几乎相等,同时逼近MHA的模型性能。 - llama3 分组数为4, chatglm2 分组数为2 .

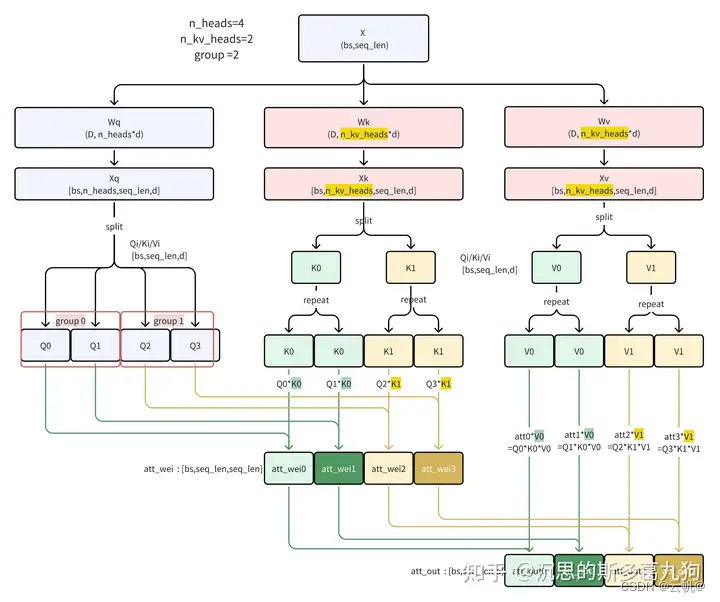
参考:https://zhuanlan.zhihu.com/p/693928854
demo
import torch import torch.nn as nn import math #GQA bs=3 seq_len =5 hidden_size= 32 n_heads=4 n_kv_heads = 2 head_dim = hidden_size//n_heads # groups = n_heads//n_kv_heads # 4/2 print("groups=",groups) x=torch.randn((bs,seq_len,hidden_size)) print("x:", x.shape) wq = nn.Linear(hidden_size,n_heads*head_dim,bias=False) wk = nn.Linear(hidden_size, n_kv_heads * head_dim, bias=False) wv = nn.Linear(hidden_size, n_kv_heads * head_dim, bias=False) xq,xk,xv=wq(x),wk(x),wv(x) xq = xq.view(bs,seq_len, n_heads, head_dim).transpose(1, 2) xk = xk.view(bs,seq_len, n_kv_heads, head_dim).transpose(1, 2) xv = xv.view(bs,seq_len, n_kv_heads, head_dim).transpose(1, 2) print("xq:",xq.shape) #[bs,n_heads,seq_len, head_dim] print("xk:", xk.shape)#[bs,n_kv_heads,seq_len, head_dim] print("xv:", xv.shape)#[bs,n_kv_heads,seq_len, head_dim] def repeat_kv(keys: torch.Tensor, values: torch.Tensor, repeats: int, dim: int): keys = torch.repeat_interleave(keys, repeats=repeats, dim=dim) values = torch.repeat_interleave(values, repeats=repeats, dim=dim) return keys, values #复制kv head key,val = repeat_kv(xk,xv, groups,dim=1) print("key:", key.shape) print("val:", val.shape) attn_weights = torch.matmul(xq, key.transpose(2, 3)) / math.sqrt(head_dim) print("attn_weights:", attn_weights.shape) #[bs,n_heads,seq_len,seq_len] attn_output = torch.matmul(attn_weights, val) print("attn_output:", attn_output.shape) # [bs,n_heads,seq_len,head_dim]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- GQA attention 注意力需要多大的kv cache缓存空间。
对于使用Group-Query Attention的模型,假设hidden size=D,Q的注意力头数量为h,每个头维度为d(假设有D=d×h),kv组数为n,输入上下文长度为s,batch size=b,模型层数为L,计算推理时kv cache所需的空间。
解:对于query、key 每一层分为n组,每一组维度为D/h; 因此每次计算量为sD/h, 同时Key,query 为一组,层数为L,所以模型参数为2bLnsD/h,当使用半精度训练时,每个浮点数需要2个字节,因此需要4bLnsD/h个字节的空间。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/代码探险家/article/detail/936023
推荐阅读
相关标签

