
热门标签
热门文章
- 1微信答题小程序产品研发-需求分析与原型设计
- 2【Python】Tkinter 实现计算器_thinter计算器
- 3(Node*)malloc(sizeof(Node))的理解
- 4SDXL版本的基础模型和LoRA还有存在感么?(模型介绍系列DreamShaper XL1.0-综合型)_sdxl基础模型
- 5华为OD手撕代码题库,更新到9月23日,来自考友的真实反馈_华为手撕代码 csdn
- 6【Oracle SQL语句 某字段重复数据只取一条】_oracle重复数据只取一条
- 7发布Android Lib库(Jar、AAR、SO)到Maven Central_mavencentral
- 8pytorch安装_搭建nlp环境
- 9太扎心了,我学了半年 Python,还是找不到工作......_python程序员找不到工作
- 10chat gpt论文怎么降重_chatgpt降重
当前位置: article > 正文
Transformer加速算法【KV-cache、GQA(Grouped-query attention)、投机采样、RWKV、Inifni-Transformer、FlashAttention】_transformer gqa
作者:我家自动化 | 2024-08-06 05:43:06
赞
踩
transformer gqa
一、KV-cache
在LLM的推理过程中,KVCache已经属于必备的技术了。然而,网上现有的解读文章并不够清晰。看了一些文章之后,我决定还是自己写一篇新的,以飨读者。
二、GQA(Grouped-query attention)
在LLaMa2一文中,其主要区别于LLaMa的改动为:使用GQA和4k文本长度,那什么是GQA?
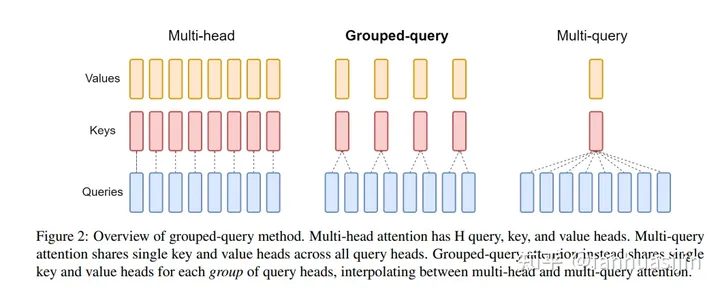
GQA(Grouped-query attention) - 知乎
三、投机采样(Speculative Decoding)
用小模型推理,用大模型做验证
投机采样(Speculative Decoding)是Google[1]和DeepMind[2]在2022年同时发现的大模型推理加速方法。它可以在不损失生成效果前提下,获得3x以上的加速比。GPT-4泄密报告也提到OpenAI线上模型推理使用了它。
对如此妙到毫巅的方法,介绍它中文资料却很少
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/936015
推荐阅读
相关标签

