
- 1开始着手用Python写一个游戏脚本(一)_python写游戏脚本
- 2Unity场景内模型出现粉色的处理方法_unity2d图片粉色
- 3支付宝生活号对接-----(三)芝麻认证_biz no
- 4canvas详解01-绘制基本图形_canvas绘制
- 5rosweb开源项目运行
- 6WPF项目创建HTTP WEB服务,不使用IIS业务 WPF桌面程序WebApi WPF 集成WebApi C# 创建HTTP Web API服务_c# wpf应用http
- 7长短期记忆网络LSTM识别验证码、车牌识别
- 8nextjs系列教程(三):pages和路由_nextjs新建路由
- 9如何避免引擎项目里面的美术资源的“脏”_增加材质球影响引擎性能
- 10Unity 基于Netcode for gameObjects实现局域网同步_unity netcode
如何入门 Python 爬虫?详细教程在这里_python爬虫教程
赞
踩
根据本人的习惯与理解,用最简洁的表述,介绍爬虫的定义、组成部分、爬取流程,并讲解示例代码。
基础
爬虫的定义:定向抓取互联网内容(大部分为网页)、并进行自动化数据处理的程序。主要用于对松散的海量信息进行收集和结构化处理,为数据分析和挖掘提供原材料。
今日t条就是一只巨大的“爬虫”。
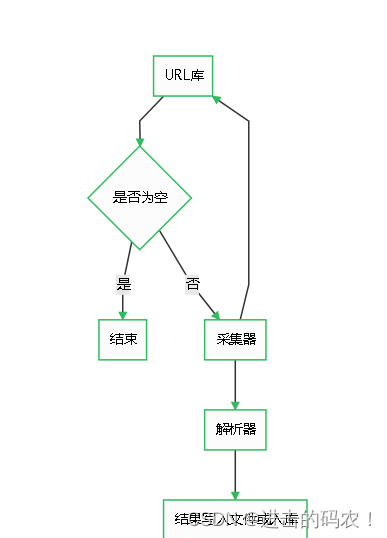
爬虫由URL库、采集器、解析器组成。
流程
如果待爬取的url库不为空,采集器会自动爬取相关内容,并将结果给到解析器,解析器提取目标内容后进行写入文件或入库等操作。
代码
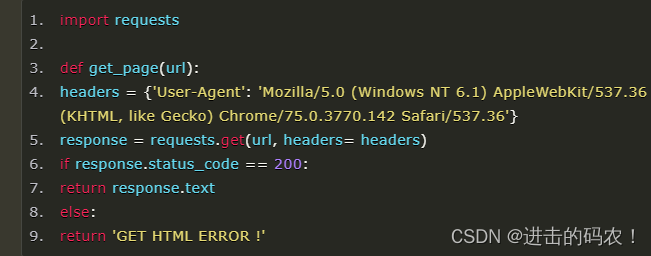
第一步:写一个采集器
如下是一个比较简单的采集器函数。需要用到requests库。
首先,构造一个http的header,里面有浏览器和操作系统等信息。如果没有这个伪造的header,可能会被目标网站的WAF等防护设备识别为机器代码并干掉。
然后,用requests库的get方法获取url内容。如果http响应代码是200 ok,说明页面访问正常,将该函数返回值设置为文本形式的html代码内容。
如果响应代码不是200 ok,说明页面不能正常访问,将函数返回值设置为特殊字符串或代码。
第二步:解析器
解析器的作用是对采集器返回的html代码进行过滤筛选,提取需要的内容。
作为一个14年忠实用户,当然要用豆瓣举个栗子 _
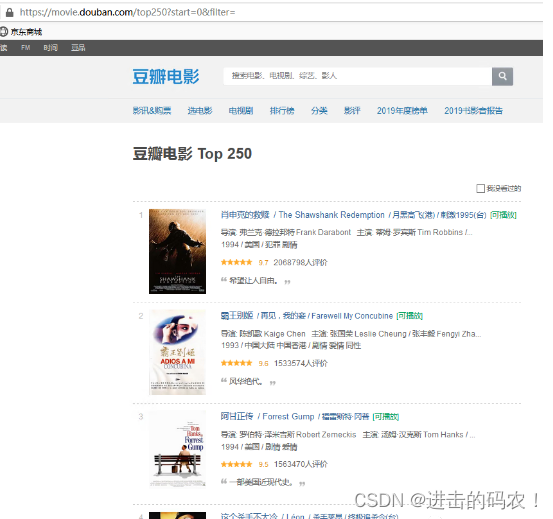
我们计划爬取豆瓣排名TOP250电影的8个参数:排名、电影url链接、电影名称、导演、上映年份、国家、影片类型、评分。整理成字典并写入文本文件。
待爬取的页面如下,每个页面包括25部电影,共计10个页面。
在这里,必须要表扬豆瓣的前端工程师们,html标签排版非常工整具有层次,非常便于信息提取。
下面是“肖申克的救赎”所对应的html代码:(需要提取的8个参数用红线标注)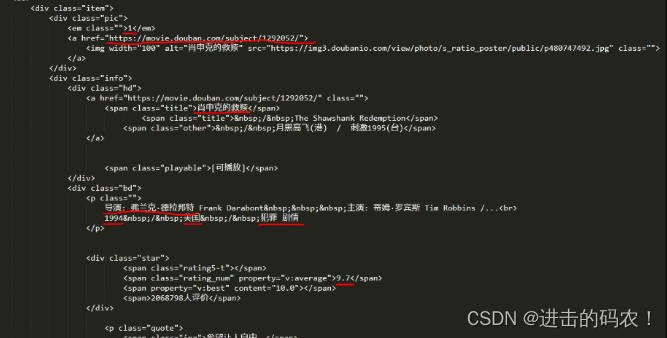
根据上面的html编写解析器函数,提取8个字段。该函数返回值是一个可迭代的序列。
我个人喜欢用re(正则表达式)提取内容。8个(.*?)分别对应需要提取的字段。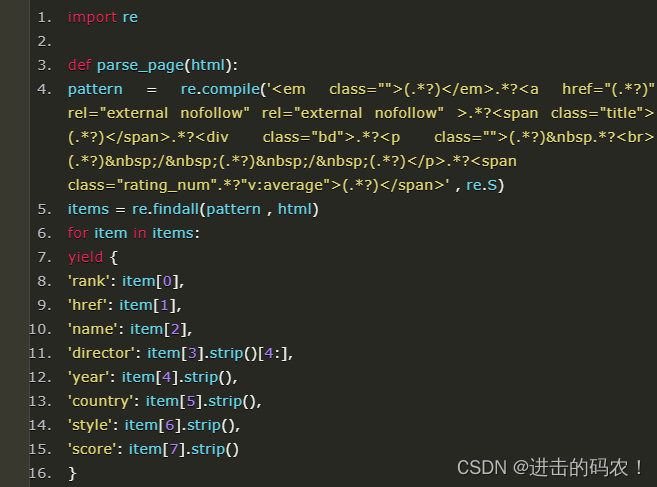
提取后的内容如下:

整理成完整的代码:(暂不考虑容错)
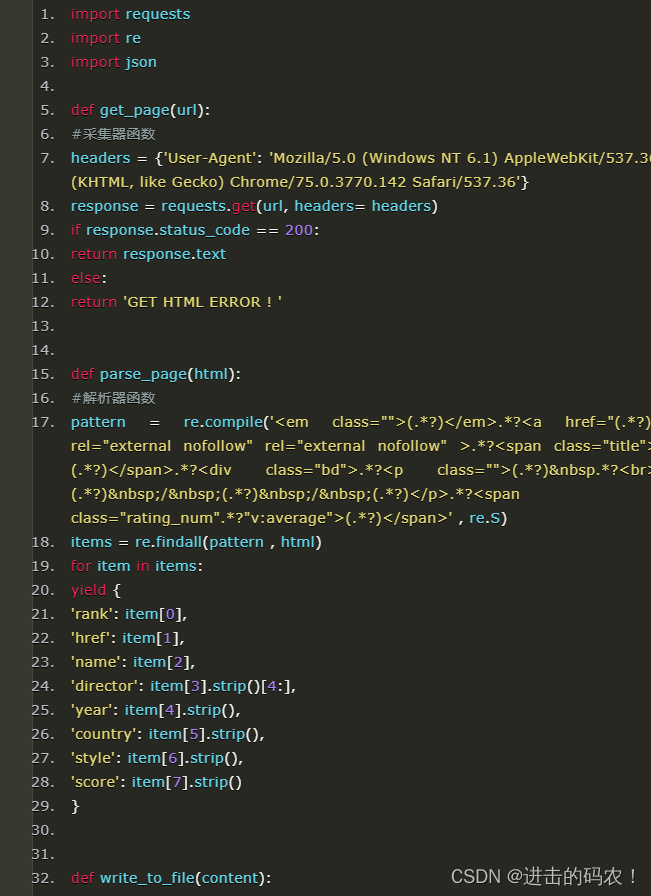
非常简洁,非常符合python简单、高效的特点。
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、精品Python学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、Python练习题
检查学习结果。

七、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/124152
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

