
热门标签
热门文章
- 1[转]CS的顶级会议和期刊_cagd影响因子
- 2LibreELEC 10.0.2发布_reboot to libreelec.apk下载
- 3Redis核心数据结构及底层原理详解_redis底层数据结构实现原理
- 4Python 多线程:伪多线程?详细代码总结_多线程伪代码
- 5pytest.mark.parametrize参数化引用另一个模块py文件里的函数数据_pytest 引用另一个文件方法
- 6使用 ONLYOFFICE 宏借助 ChatGPT 生成文章_onlyoffice chatgpt
- 7stl中unique函数,erase函数(个人笔记向)
- 8ACL访问控制_acl策略
- 9C/C++学习规划与发展指引_c++ 个人发展计划
- 10pd.DataFrame的几种构造方式_pd.dataframe() 构造
当前位置: article > 正文
基于tensorflow、CNN网络识别花卉的种类(图像识别)_tensoeflow花卉识别数据集
作者:你好赵伟 | 2024-02-25 10:12:11
赞
踩
tensoeflow花卉识别数据集
基于tensorflow、CNN网络识别花卉的种类
这是一个图像识别项目,基于 tensorflow,现有的 CNN 网络可以识别四种花的种类。适合新手对使用 tensorflow进行一个完整的图像识别过程有一个大致轮廓。项目包括对数据集的处理,从硬盘读取数据,CNN 网络的定义,训练过程,还实现了一个 GUI界面用于使用训练好的网络。
Notice:本项目完全开源,需要源码关注我,再私信我哦
1、环境工具支持
- 安装 Anaconda
- 导入环境 environment.yaml
conda env update -f=environment.yaml
2、运行方法
- git clone 这个项目;
- 解压 input_data.rar 到你喜欢的目录;
- 修改 train.py 中;(如下修改)
train_dir = 'D:/ML/flower/input_data' # 训练样本的读入路径
logs_train_dir = 'D:/ML/flower/save' # logs存储路径
- 1
- 2
为你本机的目录。
- 运行 train.py 开始训练。
- 训练完成后,修改 test.py 中的
logs_train_dir = 'D:/ML/flower/save/'为你的目录。 - 运行 test.py 或者 gui.py 查看结果。
3、运行UI界面结果
gui.py运行界面:
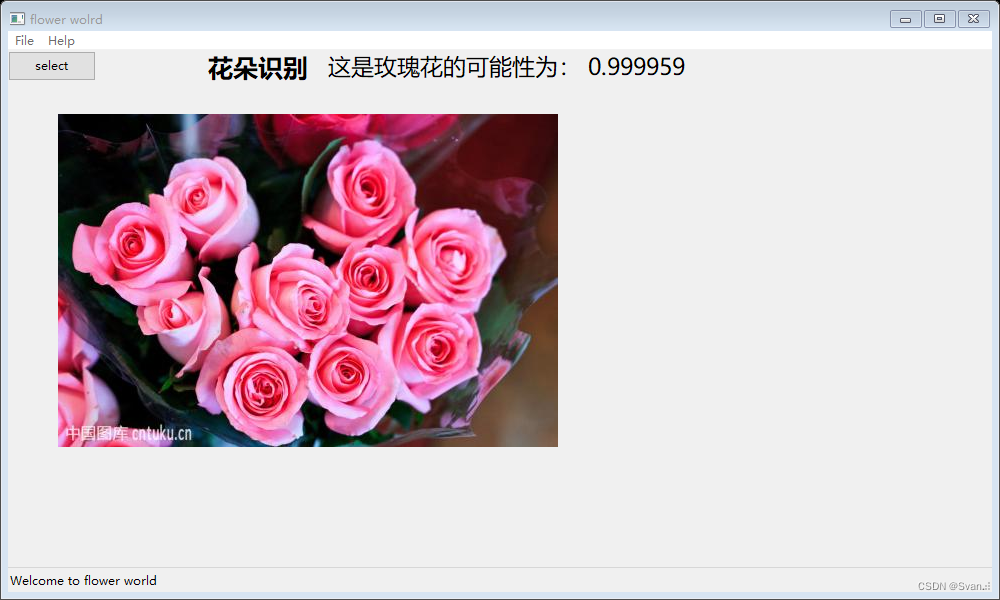
4、项目源码模块化介绍(需要源码关注我,并私信我)
主界面文件(gui.py):
主要包含控件的设计,很简单,没有用到其他库
class HelloFrame(wx.Frame): def __init__(self,*args,**kw): super(HelloFrame,self).__init__(*args,**kw) pnl = wx.Panel(self) self.pnl = pnl st = wx.StaticText(pnl, label="花朵识别", pos=(200, 0)) font = st.GetFont() font.PointSize += 10 font = font.Bold() st.SetFont(font) # 选择图像文件按钮 btn = wx.Button(pnl, -1, "select") btn.Bind(wx.EVT_BUTTON, self.OnSelect) self.makeMenuBar() self.CreateStatusBar() self.SetStatusText("Welcome to flower world") def makeMenuBar(self): fileMenu = wx.Menu() helloItem = fileMenu.Append(-1, "&Hello...\tCtrl-H", "Help string shown in status bar for this menu item") fileMenu.AppendSeparator() exitItem = fileMenu.Append(wx.ID_EXIT) helpMenu = wx.Menu() aboutItem = helpMenu.Append(wx.ID_ABOUT) menuBar = wx.MenuBar() menuBar.Append(fileMenu, "&File") menuBar.Append(helpMenu, "Help") self.SetMenuBar(menuBar) self.Bind(wx.EVT_MENU, self.OnHello, helloItem) self.Bind(wx.EVT_MENU, self.OnExit, exitItem) self.Bind(wx.EVT_MENU, self.OnAbout, aboutItem) def OnExit(self, event): self.Close(True) def OnHello(self, event): wx.MessageBox("Hello again from wxPython") def OnAbout(self, event): """Display an About Dialog""" wx.MessageBox("This is a wxPython Hello World sample", "About Hello World 2", wx.OK | wx.ICON_INFORMATION) def OnSelect(self, event): wildcard = "image source(*.jpg)|*.jpg|" \ "Compile Python(*.pyc)|*.pyc|" \ "All file(*.*)|*.*" dialog = wx.FileDialog(None, "Choose a file", os.getcwd(), "", wildcard, wx.ID_OPEN) if dialog.ShowModal() == wx.ID_OK: print(dialog.GetPath()) img = Image.open(dialog.GetPath()) imag = img.resize([64, 64]) image = np.array(imag) result = evaluate_one_image(image) result_text = wx.StaticText(self.pnl, label=result, pos=(320, 0)) font = result_text.GetFont() font.PointSize += 8 result_text.SetFont(font) self.initimage(name= dialog.GetPath()) # 生成图片控件 def initimage(self, name): imageShow = wx.Image(name, wx.BITMAP_TYPE_ANY) sb = wx.StaticBitmap(self.pnl, -1, imageShow.ConvertToBitmap(), pos=(0,30), size=(600,400)) return sb if __name__ == '__main__': app = wx.App() frm = HelloFrame(None, title='flower wolrd', size=(1000,600)) frm.Show() app.MainLoop()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
将原始图片转换成需要的大小,并将其保存(creat record.py):
这里就不做详细介绍了,具体解释看源码注释,注释里面写的很详细
# 原始图片的存储位置 orig_picture = 'D:/ML/flower/flower_photos/' # 生成图片的存储位置 gen_picture = 'D:/ML/flower/input_data/' # 需要的识别类型 classes = {'dandelion', 'roses', 'sunflowers','tulips'} # 样本总数 num_samples = 4000 # 制作TFRecords数据 def create_record(): writer = tf.python_io.TFRecordWriter("flower_train.tfrecords") for index, name in enumerate(classes): class_path = orig_picture + "/" + name + "/" for img_name in os.listdir(class_path): img_path = class_path + img_name img = Image.open(img_path) img = img.resize((64, 64)) # 设置需要转换的图片大小 img_raw = img.tobytes() # 将图片转化为原生bytes print(index, img_raw) example = tf.train.Example( features=tf.train.Features(feature={ "label": tf.train.Feature(int64_list=tf.train.Int64List(value=[index])), 'img_raw': tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_raw])) })) writer.write(example.SerializeToString()) writer.close() # ======================================================================================= def read_and_decode(filename): # 创建文件队列,不限读取的数量 filename_queue = tf.train.string_input_producer([filename]) # create a reader from file queue reader = tf.TFRecordReader() # reader从文件队列中读入一个序列化的样本 _, serialized_example = reader.read(filename_queue) # get feature from serialized example # 解析符号化的样本 features = tf.parse_single_example( serialized_example, features={ 'label': tf.FixedLenFeature([], tf.int64), 'img_raw': tf.FixedLenFeature([], tf.string) }) label = features['label'] img = features['img_raw'] img = tf.decode_raw(img, tf.uint8) img = tf.reshape(img, [64, 64, 3]) # img = tf.cast(img, tf.float32) * (1. / 255) - 0.5 label = tf.cast(label, tf.int32) return img, label # ======================================================================================= if __name__ == '__main__': create_record() batch = read_and_decode('flower_train.tfrecords') init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) with tf.Session() as sess: # 开始一个会话 sess.run(init_op) coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(coord=coord) for i in range(num_samples): example, lab = sess.run(batch) # 在会话中取出image和label img = Image.fromarray(example, 'RGB') # 这里Image是之前提到的 img.save(gen_picture + '/' + str(i) + 'samples' + str(lab) + '.jpg') # 存下图片;注意cwd后边加上‘/’ print(example, lab) coord.request_stop() coord.join(threads) sess.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
生成图片路径和标签的List,Batch:
这里用源码结构图来呈现:
- 生成图片路径和标签的List
- 获取所有的图片路径名,存放到对应的列表中,同时贴上标签,存放到label列表中
- 对生成的图片路径和标签List做打乱处理
- 利用shuffle打乱顺序
- 将所有的img和lab转换成list
- 将所得List分为两部分,一部分用来训练tra,一部分用来测试valratio是测试集的比例
- 生成Batch
- 将上面生成的List传入
get_batch(),转换类型,产生一个输入队列queue,因为img和lab是分开的,所以使用tf.train.slice_input_producer(),然后用tf.read_file()从队列中读取图像 image_W, image_H:设置好固定的图像高度和宽度设置batch_size:每个batch要放多少张图片capacity:一个队列最大多少- 将图像解码,不同类型的图像不能混在一起,要么只用jpeg,要么只用png等
- 数据预处理,对图像进行旋转、缩放、裁剪、归一化等操作,让计算出的模型更健壮
- 重新排列label,行数为[batch_size]
- 将上面生成的List传入
# ============================================================================ # -----------------生成图片路径和标签的List------------------------------------ train_dir = 'D:/ML/flower/input_data' roses = [] label_roses = [] tulips = [] label_tulips = [] dandelion = [] label_dandelion = [] sunflowers = [] label_sunflowers = [] # step1:获取所有的图片路径名,存放到 # 对应的列表中,同时贴上标签,存放到label列表中。 def get_files(file_dir, ratio): for file in os.listdir(file_dir + '/roses'): roses.append(file_dir + '/roses' + '/' + file) label_roses.append(0) for file in os.listdir(file_dir + '/tulips'): tulips.append(file_dir + '/tulips' + '/' + file) label_tulips.append(1) for file in os.listdir(file_dir + '/dandelion'): dandelion.append(file_dir + '/dandelion' + '/' + file) label_dandelion.append(2) for file in os.listdir(file_dir + '/sunflowers'): sunflowers.append(file_dir + '/sunflowers' + '/' + file) label_sunflowers.append(3) # step2:对生成的图片路径和标签List做打乱处理 image_list = np.hstack((roses, tulips, dandelion, sunflowers)) label_list = np.hstack((label_roses, label_tulips, label_dandelion, label_sunflowers)) # 利用shuffle打乱顺序 temp = np.array([image_list, label_list]) temp = temp.transpose() np.random.shuffle(temp) # 从打乱的temp中再取出list(img和lab) # image_list = list(temp[:, 0]) # label_list = list(temp[:, 1]) # label_list = [int(i) for i in label_list] # return image_list, label_list # 将所有的img和lab转换成list all_image_list = list(temp[:, 0]) all_label_list = list(temp[:, 1]) # 将所得List分为两部分,一部分用来训练tra,一部分用来测试val # ratio是测试集的比例 n_sample = len(all_label_list) n_val = int(math.ceil(n_sample * ratio)) # 测试样本数 n_train = n_sample - n_val # 训练样本数 tra_images = all_image_list[0:n_train] tra_labels = all_label_list[0:n_train] tra_labels = [int(float(i)) for i in tra_labels] val_images = all_image_list[n_train:-1] val_labels = all_label_list[n_train:-1] val_labels = [int(float(i)) for i in val_labels] return tra_images, tra_labels, val_images, val_labels # --------------------------------------------------------------------------- # --------------------生成Batch---------------------------------------------- # step1:将上面生成的List传入get_batch() ,转换类型,产生一个输入队列queue,因为img和lab # 是分开的,所以使用tf.train.slice_input_producer(),然后用tf.read_file()从队列中读取图像 # image_W, image_H, :设置好固定的图像高度和宽度 # 设置batch_size:每个batch要放多少张图片 # capacity:一个队列最大多少 def get_batch(image, label, image_W, image_H, batch_size, capacity): # 转换类型 image = tf.cast(image, tf.string) label = tf.cast(label, tf.int32) # make an input queue input_queue = tf.train.slice_input_producer([image, label]) label = input_queue[1] image_contents = tf.read_file(input_queue[0]) # read img from a queue # step2:将图像解码,不同类型的图像不能混在一起,要么只用jpeg,要么只用png等。 image = tf.image.decode_jpeg(image_contents, channels=3) # step3:数据预处理,对图像进行旋转、缩放、裁剪、归一化等操作,让计算出的模型更健壮。 image = tf.image.resize_image_with_crop_or_pad(image, image_W, image_H) image = tf.image.per_image_standardization(image) # step4:生成batch # image_batch: 4D tensor [batch_size, width, height, 3],dtype=tf.float32 # label_batch: 1D tensor [batch_size], dtype=tf.int32 image_batch, label_batch = tf.train.batch([image, label], batch_size=batch_size, num_threads=32, capacity=capacity) # 重新排列label,行数为[batch_size] label_batch = tf.reshape(label_batch, [batch_size]) image_batch = tf.cast(image_batch, tf.float32) return image_batch, label_batch
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
CNN网络结构的定义(model.py):
这里主要运用tensorflow库进行定义,不懂源码的可以看一下我的注释
# 网络结构定义 # 输入参数:images,image batch、4D tensor、tf.float32、[batch_size, width, height, channels] # 返回参数:logits, float、 [batch_size, n_classes] def inference(images, batch_size, n_classes): # 一个简单的卷积神经网络,卷积+池化层x2,全连接层x2,最后一个softmax层做分类。 # 卷积层1 # 64个3x3的卷积核(3通道),padding=’SAME’,表示padding后卷积的图与原图尺寸一致,激活函数relu() with tf.variable_scope('conv1') as scope: weights = tf.Variable(tf.truncated_normal(shape=[3, 3, 3, 64], stddev=1.0, dtype=tf.float32), name='weights', dtype=tf.float32) biases = tf.Variable(tf.constant(value=0.1, dtype=tf.float32, shape=[64]), name='biases', dtype=tf.float32) conv = tf.nn.conv2d(images, weights, strides=[1, 1, 1, 1], padding='SAME') pre_activation = tf.nn.bias_add(conv, biases) conv1 = tf.nn.relu(pre_activation, name=scope.name) # 池化层1 # 3x3最大池化,步长strides为2,池化后执行lrn()操作,局部响应归一化,对训练有利。 with tf.variable_scope('pooling1_lrn') as scope: pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME', name='pooling1') norm1 = tf.nn.lrn(pool1, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='norm1') # 卷积层2 # 16个3x3的卷积核(16通道),padding=’SAME’,表示padding后卷积的图与原图尺寸一致,激活函数relu() with tf.variable_scope('conv2') as scope: weights = tf.Variable(tf.truncated_normal(shape=[3, 3, 64, 16], stddev=0.1, dtype=tf.float32), name='weights', dtype=tf.float32) biases = tf.Variable(tf.constant(value=0.1, dtype=tf.float32, shape=[16]), name='biases', dtype=tf.float32) conv = tf.nn.conv2d(norm1, weights, strides=[1, 1, 1, 1], padding='SAME') pre_activation = tf.nn.bias_add(conv, biases) conv2 = tf.nn.relu(pre_activation, name='conv2') # 池化层2 # 3x3最大池化,步长strides为2,池化后执行lrn()操作, # pool2 and norm2 with tf.variable_scope('pooling2_lrn') as scope: norm2 = tf.nn.lrn(conv2, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='norm2') pool2 = tf.nn.max_pool(norm2, ksize=[1, 3, 3, 1], strides=[1, 1, 1, 1], padding='SAME', name='pooling2') # 全连接层3 # 128个神经元,将之前pool层的输出reshape成一行,激活函数relu() with tf.variable_scope('local3') as scope: reshape = tf.reshape(pool2, shape=[batch_size, -1]) dim = reshape.get_shape()[1].value weights = tf.Variable(tf.truncated_normal(shape=[dim, 128], stddev=0.005, dtype=tf.float32), name='weights', dtype=tf.float32) biases = tf.Variable(tf.constant(value=0.1, dtype=tf.float32, shape=[128]), name='biases', dtype=tf.float32) local3 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name=scope.name) # 全连接层4 # 128个神经元,激活函数relu() with tf.variable_scope('local4') as scope: weights = tf.Variable(tf.truncated_normal(shape=[128, 128], stddev=0.005, dtype=tf.float32), name='weights', dtype=tf.float32) biases = tf.Variable(tf.constant(value=0.1, dtype=tf.float32, shape=[128]), name='biases', dtype=tf.float32) local4 = tf.nn.relu(tf.matmul(local3, weights) + biases, name='local4') # dropout层 # with tf.variable_scope('dropout') as scope: # drop_out = tf.nn.dropout(local4, 0.8) # Softmax回归层 # 将前面的FC层输出,做一个线性回归,计算出每一类的得分 with tf.variable_scope('softmax_linear') as scope: weights = tf.Variable(tf.truncated_normal(shape=[128, n_classes], stddev=0.005, dtype=tf.float32), name='softmax_linear', dtype=tf.float32) biases = tf.Variable(tf.constant(value=0.1, dtype=tf.float32, shape=[n_classes]), name='biases', dtype=tf.float32) softmax_linear = tf.add(tf.matmul(local4, weights), biases, name='softmax_linear') return softmax_linear # ----------------------------------------------------------------------------- # loss计算 # 传入参数:logits,网络计算输出值。labels,真实值,在这里是0或者1 # 返回参数:loss,损失值 def losses(logits, labels): with tf.variable_scope('loss') as scope: cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels, name='xentropy_per_example') loss = tf.reduce_mean(cross_entropy, name='loss') tf.summary.scalar(scope.name + '/loss', loss) return loss # -------------------------------------------------------------------------- # loss损失值优化 # 输入参数:loss。learning_rate,学习速率。 # 返回参数:train_op,训练op,这个参数要输入sess.run中让模型去训练。 def trainning(loss, learning_rate): with tf.name_scope('optimizer'): optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate) global_step = tf.Variable(0, name='global_step', trainable=False) train_op = optimizer.minimize(loss, global_step=global_step) return train_op # ----------------------------------------------------------------------- # 评价/准确率计算 # 输入参数:logits,网络计算值。labels,标签,也就是真实值,在这里是0或者1。 # 返回参数:accuracy,当前step的平均准确率,也就是在这些batch中多少张图片被正确分类了。 def evaluation(logits, labels): with tf.variable_scope('accuracy') as scope: correct = tf.nn.in_top_k(logits, labels, 1) correct = tf.cast(correct, tf.float16) accuracy = tf.reduce_mean(correct) tf.summary.scalar(scope.name + '/accuracy', accuracy) return accuracy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
训练模块(train.py):
这里只针对四种花进行分类(时间有限,只准备了四种花的数据)
# 变量声明 N_CLASSES = 4 # 四种花类型 IMG_W = 64 # resize图像,太大的话训练时间久 IMG_H = 64 BATCH_SIZE = 20 CAPACITY = 200 MAX_STEP = 10000 # 一般大于10K learning_rate = 0.0001 # 一般小于0.0001 # 获取批次batch train_dir = 'D:/ML/flower/input_data' # 训练样本的读入路径 logs_train_dir = 'D:/ML/flower/save' # logs存储路径 # train, train_label = input_data.get_files(train_dir) train, train_label, val, val_label = input_data.get_files(train_dir, 0.3) # 训练数据及标签 train_batch, train_label_batch = input_data.get_batch(train, train_label, IMG_W, IMG_H, BATCH_SIZE, CAPACITY) # 测试数据及标签 val_batch, val_label_batch = input_data.get_batch(val, val_label, IMG_W, IMG_H, BATCH_SIZE, CAPACITY) # 训练操作定义 train_logits = model.inference(train_batch, BATCH_SIZE, N_CLASSES) train_loss = model.losses(train_logits, train_label_batch) train_op = model.trainning(train_loss, learning_rate) train_acc = model.evaluation(train_logits, train_label_batch) # 测试操作定义 test_logits = model.inference(val_batch, BATCH_SIZE, N_CLASSES) test_loss = model.losses(test_logits, val_label_batch) test_acc = model.evaluation(test_logits, val_label_batch) # 这个是log汇总记录 summary_op = tf.summary.merge_all() # 产生一个会话 sess = tf.Session() # 产生一个writer来写log文件 train_writer = tf.summary.FileWriter(logs_train_dir, sess.graph) # val_writer = tf.summary.FileWriter(logs_test_dir, sess.graph) # 产生一个saver来存储训练好的模型 saver = tf.train.Saver() # 所有节点初始化 sess.run(tf.global_variables_initializer()) # 队列监控 coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 进行batch的训练 try: # 执行MAX_STEP步的训练,一步一个batch for step in np.arange(MAX_STEP): if coord.should_stop(): break _, tra_loss, tra_acc = sess.run([train_op, train_loss, train_acc]) # 每隔50步打印一次当前的loss以及acc,同时记录log,写入writer if step % 10 == 0: print('Step %d, train loss = %.2f, train accuracy = %.2f%%' % (step, tra_loss, tra_acc * 100.0)) summary_str = sess.run(summary_op) train_writer.add_summary(summary_str, step) # 每隔100步,保存一次训练好的模型 if (step + 1) == MAX_STEP: checkpoint_path = os.path.join(logs_train_dir, 'model.ckpt') saver.save(sess, checkpoint_path, global_step=step) except tf.errors.OutOfRangeError: print('Done training -- epoch limit reached') finally: coord.request_stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
测试模块(test.py):
通过输入指定的图像数据到模型中,进行简单测试(源码中含有注释)
# 获取一张图片 def get_one_image(train): # 输入参数:train,训练图片的路径 # 返回参数:image,从训练图片中随机抽取一张图片 n = len(train) ind = np.random.randint(0, n) img_dir = train[ind] # 随机选择测试的图片 img = Image.open(img_dir) plt.imshow(img) plt.show() image = np.array(img) return image # 测试图片 def evaluate_one_image(image_array): with tf.Graph().as_default(): BATCH_SIZE = 1 N_CLASSES = 4 image = tf.cast(image_array, tf.float32) image = tf.image.per_image_standardization(image) image = tf.reshape(image, [1, 64, 64, 3]) logit = model.inference(image, BATCH_SIZE, N_CLASSES) logit = tf.nn.softmax(logit) x = tf.placeholder(tf.float32, shape=[64, 64, 3]) # you need to change the directories to yours. logs_train_dir = 'D:/ML/flower/save/' saver = tf.train.Saver() with tf.Session() as sess: print("Reading checkpoints...") ckpt = tf.train.get_checkpoint_state(logs_train_dir) if ckpt and ckpt.model_checkpoint_path: global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1] saver.restore(sess, ckpt.model_checkpoint_path) print('Loading success, global_step is %s' % global_step) else: print('No checkpoint file found') prediction = sess.run(logit, feed_dict={x: image_array}) max_index = np.argmax(prediction) if max_index == 0: result = ('这是玫瑰花的可能性为: %.6f' % prediction[:, 0]) elif max_index == 1: result = ('这是郁金香的可能性为: %.6f' % prediction[:, 1]) elif max_index == 2: result = ('这是蒲公英的可能性为: %.6f' % prediction[:, 2]) else: result = ('这是这是向日葵的可能性为: %.6f' % prediction[:, 3]) return result # ------------------------------------------------------------------------ if __name__ == '__main__': img = Image.open('D:/ML/flower/flower_photos/roses/12240303_80d87f77a3_n.jpg') plt.imshow(img) plt.show() imag = img.resize([64, 64]) image = np.array(imag) evaluate_one_image(image)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
至此主要源码部分就讲解完毕了,还包括其他的训练数据集,就不讲解了。
需要源码的同志们请关注,再私信我(本人看到私信一定及时回复)
创作不易,大家且行且珍惜!!!!!!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/140267
推荐阅读
相关标签

