Caffe、TensorFlow、MXnet三个开源库对比+主流分类模型对比_基于tensorflow引擎创建的预测算法 预测未来 半年 数据
赞
踩
Caffe、TensorFlow、MXnet三个开源库对比+主流分类模型对比
| 库名称 | 开发语言 | 支持接口 | 安装难度(ubuntu) | 文档风格 | 示例 | 支持模型 | 上手难易 |
|---|---|---|---|---|---|---|---|
| Caffe | c++/cuda | c++/python/matlab | *** | * | *** | CNN | ** |
| MXNet | c++/cuda | python/R/Julia | ** | *** | ** | CNN/RNN | * |
| TensorFlow | c++/cuda/python | c++/python | * | ** | * | CNN/RNN/… | *** |
- 安装难度: (简单) –> **(复杂)
- 文档风格: (一般) –> **(好看、全面)
- 示例: (给的少) –> **(给的多、全)
- 上手难易: (易) –> **(难)
1.基本数据结构
| 库名称 | 数据结构名称 | 设计方式 |
|---|---|---|
| Caffe | Blob | 存储的数据可以看成N维的c数组,有(n,k,h,w)四个维数,一个blob里面有两块数据空间保存前向和后向求导数据 |
| MXNet | NDArray | 提供cpu/gpu的矩阵和矢量计算,能够自动并行 |
| TensorFlow | tensor | 相当于N维的array或者list,维数可变,数据类型一旦定义不能改变 |
caffe的数据存储类blob,当把数据可以看成是一个N维的c数组,它们的存储空间连续。例如存储图片是4维(num, channel, height, width),变量(n,k,h,w)在数组中存储位置为((n*K+k)*H+h)*W+w。blob有以下三个特征[4]:
- 两块数据,一个是原始data,一个是求导值diff
- 两种内存分配方式,一种是分配在cpu上,一种是分配在gpu上,通过前缀cpu、gpu来区分
- 两种访问方式,一种是不能改变数据,一种能改变数据
Caffe最让我觉得精妙的地方在于一个blob保存前向和后向的数据。虽然就代码本身而言,前向数据是因为输入数据不同而改变,后向求导是因为求导不同而改变,根据SRP原则,在一个类里面因为两个原因而改变了数据这种是不合适的设计。但是从逻辑层面,前向数据的改变引起了反向求导的不同,它们实际上是一起在改变,本身应该是一个整体。所以我很喜欢这个设计,虽然基本上其他框架中都是将两个数据给分离出来,caffe2也不知是否保留。
MXNet的NDArray类似numpy.ndarray,也支持把数据分配在gpu或者cpu上进行运算。但是与numpy和caffe不同的是,当在操作NDArray,它能自动的将需要执行的数据分配到多台gpu和cpu上进行计算,从而完成高速并行。在调用者的眼中代码可能只是一个单线程的,数据只是分配到了一块内存中,但是背后执行的过程实际上是并行的。将指令(加减等)放入中间引擎,然后引擎来评估哪些数据有依赖关系,哪些能并行处理。定义好数据之后将它绑定到网络中就能处理它了。
TensorFlow的tensor,它相当于N维的array或者list,与MXNet类似,都是采用了以python调用的形式展现出来。某个定义好的tensor的数据类型是不变的,但是维数可以动态改变。用tensor rank和TensorShape来表示它的维数(例如rank为2可以看成矩阵,rank为1可以看成向量)。tensor是个比较中规中矩的类型。唯一特别的地方在于在TensorFlow构成的网络中,tensor是唯一能够传递的类型,而类似于array、list这种不能当成输入。
值得一提的是cuda-convnet采用的数据结构是NVMatrix,NV表示数据分配在gpu上,即将所有变量都当成矩阵来处理,它只有两维,它算是最早用cuda实现的深度学习框架,而上面三种框架都采用了多维可变维的思想,这种可变维在用矩阵做卷积运算的时候是很有效的。
2.网络实现方式
Caffe是典型的功能(过程)计算方式,它首先按照每一个大功能(可视化、损失函数、非线性激励、数据层)将功能分类并针对部分功能实现相应的父类,再将具体的功能实现成子类,或者直接继承Layer类,从而形成了XXXLayer的形式。然后将不同的layer组合起来就成了net。

图1 caffe的网络结构(来源[7])
MXNet是符号计算和过程计算混合[5],它设计了Symbol大类,提供了很多符号运算的接口,每个symbol定义了对数据进行怎样的处理,symbol只是定义处理的方式,这步还并未真正的执行运算。其中一个需要注意的是symbol里面有Variable,它作为承载数据的符号,定义了需要传递什么样的数据给某个Variable,并在后续的操作中将数据绑定到Variable上。下面的代码是一个使用示例,它实现了将激励函数连接到前面定义好的net后面,并给出了这一个symbol的名字和激励函数类型,从而构造出net。下图左边部分是定义symbol的合集,中间将数据绑定到Variable上之后变成了右边真正的执行流程图。
net = mx.symbol.Activation(data=net, name='relu1', act_type="relu")

图2 MXNet的网络结构(图来源[2])
TensorFlow选择的是符号计算方式,它的程序分为计算构造阶段和执行阶段,构造阶段是构造出computation graph,computation graph就是包含一系列符号操作Operation和Tensor数据对象的流程图,跟mxnet的symbol类似,它定义好了如何进行计算(加减乘除等)、数据通过不同计算的顺序(也就是flow,数据在符号操作之间流动的感觉)。但是暂时并不读取输入来计算获得输出,而是由后面的执行阶段启动session的run来执行已经定义好的graph。这样的方式跟mxnet很相似,应该都是借鉴了theano的想法。其中TensorFlow还引入了Variable类型,它不像mxnet的Variable属于symbol(tf的operation类似mxnet的symbol),而是一个单独的类型,主要作用是存储网络权重参数,从而能够在运行过程中动态改变。tf将每一个操作抽象成了一个符号Operation,它能够读取0个或者多个Tensor对象作为输入(输出),操作内容包括基本的数学运算、支持reduce、segment(对tensor中部分进行运算。例如tensor长度为10,可以同时计算前5个,中间2个,后面三个的和)、对image的resize、pad、crop、filpping、transposing等。tf没有像mxnet那样给出很好的图形解释或者实例(可能因为我没找到。。),按照自己的理解画了一部分流程图。有点疑惑的是,为什么要设计Variable,tf给出的一个alexnet的example源码中,输入数据和权重都设置成了Variable,每一层的输出并未直接定义,按照tf的说法,只有tensor类型能够在网络中传递,输出的类型应该是tensor,但是由于输入和权重改变了,输出应该也在随着改变,既然如此,为何不只设计一个tensor,让tensor也能动态改变。

图3 TensorFlow的computation graph
就设计而言,TensorFlow相对于其他两个更像是一种通用的机器学习框架,而不是只针对cnn或rnn,但就现在的性能而言,tf的速度比很多开源框架都要差一点[6]。
3.分布式训练
Caffe和TensorFlow没有给出分布式的版本,MXNet提供了多机分布式,因而前两者只有如何控制使用多gpu。Caffe通过直接在执行指令后面加上-gpu 0,1来表示调用两个gpu0和1,只实现了数据并行,也就是在不同的gpu上执行相同网络和不同数据,caffe会实例化多个solver和net让每次处理的batch_size加倍。TensorFlow则能够自己定义某个操作执行在哪个gpu上,通过调用with tf.device(‘/gpu:2’)表示接下来的操作要在gpu2上处理,它也是数据并行。MXNet通过执行脚本时指定多机节点个数来确定在几台主机上运行,也是数据并行。MXNet的多gpu分配和它们之间数据同步是通过MXNet的数据同步控制KVStore来完成的。
KVStore的使用首先要创建一个kv空间,这个空间用来在不同gpu不同主机间分享数据,最基本的操作是push和pull,push是把数据放入这个空间,pull是从这个空间取数据。这个空间内保存的是key-value([int, NDArray]),在push/pull的时候来指定到哪个key。下面的代码将不同的设备上分配的b[i]通过key3在kv空间累加再输出到a,从而完成了对多gpu的处理。这个是个非常棒的设计,提供了很大的自由度,并且为开发者减少了控制底层数据传输的麻烦。
- gpus = [mx.gpu(i) for i in range(4)]
- b = [mx.nd.ones(shape, gpu) for gpu in gpus]
- kv.push(3, b)
- kv.pull(3, out = a)
之前有看过一篇论文,如何将卷积网络放在多gpu上训练,论文中有两种方法,一种是常用的数据并行,另一种是模型并行。模型并行指的是将一个完整的网络切分成不同块放在不同gpu上执行,每个gpu可能只处理某一张图的四分之一。采用模型并行很大程度上是因为显存不够放不下整个网络的数据,而现在gpu的功能性能提高,一个gpu已经能够很好的解决显存不够的问题,再加上模型并行会有额外的通信开销,因此开源框架采用了数据并行,用来提高并行度。
4.小结
上面针对三个框架的不同方面进行了一些分析与比较,可以看出TensorFlow和MXNet有一些相似的地方,都是想做成更加通用的深度学习框架,貌似caffe2也会采用符号计算[5],说明以后的框架会更加的偏向通用性和高效,个人最喜欢的是caffe,也仿造它和cuda-convnet的结构写过卷积网络,如果是想提高编程能力可以多看看这两个框架的源码。而MXNet给人的感觉是非常用心,更加注重高效,文档也非常的详细,不仅上手很容易,运用也非常的灵活。TensorFlow则是功能很齐全,能够搭建的网络更丰富而不是像caffe仅仅局限在CNN。总之框架都是各有千秋,如何选择也仅凭个人的喜好,然而google这个大杀器一出现引起的关注度还是最大的,虽然现在单机性能还不够好,但是看着长长的开发人员名单,也只能说大牛多就是任性。
参考:
[2] http://mxnet.readthedocs.org/en/latest/index.html
[3] http://caffe.berkeleyvision.org/
[6] Imagenet Winners Benchmarking
[7] Blobs, Layers, and Nets: anatomy of a Caffe model
[8] Deep Learning in a Single File for Smart Devices
——————————————————————————————————————————————————
MXNet设计和实现简介
来源:https://github.com/dmlc/mxnet/issues/797?url_type=39&object_type=webpage&pos=1
神经网络本质上是一种语言,我们通过它来表达对应用问题的理解。例如我们用卷积层来表达空间相关性,RNN来表达时间连续性。根据问题的复杂性和信息如何从输入到输出一步步提取,我们将不同大小的层按一定原则连接起来。近年来随着数据的激增和计算能力的大幅提升,神经网络也变得越来越深和大。例如最近几次imagnet竞赛的冠军都使用有数十至百层的网络。对于这一类神经网络我们通常称之为深度学习。从应用的角度而言,对深度学习最重要的是如何方便的表述神经网络,以及如何快速训练得到模型。
对于一个优秀的深度学习系统,或者更广来说优秀的科学计算系统,最重要的编程接口的设计。他们都采用将一个领域特定语言(domain specific language)嵌入到一个主语言中。例如numpy将矩阵运算嵌入到python中。这类嵌入一般分为两种,其中一种嵌入的较浅,其中每个语句都按原来的意思执行,且通常采用命令式编程(imperative programming),其中numpy和Torch就是属于这种。而另一种则用一种深的嵌入方式,提供一整套针对具体应用的迷你语言。这一种通常使用声明式语言(declarative programing),既用户只需要声明要做什么,而具体执行则由系统完成。这类系统包括Caffe,theano和刚公布的TensorFlow。
这两种方式各有利弊,总结如下
| 浅嵌入,命令式编程 | 深嵌入,声明式编程 | |
|---|---|---|
| 如何执行a=b+1 | 需要b已经被赋值。立即执行加法,将结果保存在a中。 | 返回对应的计算图(computation graph),我们可以之后对b进行赋值,然后再执行加法运算 |
| 优点 | 语义上容易理解,灵活,可以精确控制行为。通常可以无缝的和主语言交互,方便的利用主语言的各类算法,工具包,bug和性能调试器。 | 在真正开始计算的时候已经拿到了整个计算图,所以我们可以做一系列优化来提升性能。实现辅助函数也容易,例如对任何计算图都提供forward和backward函数,对计算图进行可视化,将图保存到硬盘和从硬盘读取。 |
| 缺点 | 实现统一的辅助函数困和提供整体优化都很困难。 | 很多主语言的特性都用不上。某些在主语言中实现简单,但在这里却经常麻烦,例如if-else语句 。debug也不容易,例如监视一个复杂的计算图中的某个节点的中间结果并不简单。 |
目前现有的系统大部分都采用上两种编程模式的一种。与它们不同的是,MXNet尝试将两种模式无缝的结合起来。在命令式编程上MXNet提供张量运算,而声明式编程中MXNet支持符号表达式。用户可以自由的混合它们来快速实现自己的想法。例如我们可以用声明式编程来描述神经网络,并利用系统提供的自动求导来训练模型。另一方便,模型的迭代训练和更新模型法则中可能涉及大量的控制逻辑,因此我们可以用命令式编程来实现。同时我们用它来进行方便的调式和与主语言交互数据。
下表我们比较MXNet和其他流行的深度学习系统
| 主语言 | 从语言 | 硬件 | 分布式 | 命令式 | 声明式 | |
|---|---|---|---|---|---|---|
| Caffe | C++ | Python/Matlab | CPU/GPU | x | x | v |
| Torch | Lua | - | CPU/GPU/FPGA | x | v | x |
| Theano | Python | - | CPU/GPU | x | x | v |
| TensorFlow | C++ | Python | CPU/GPU/Mobile | v | x | v |
| MXNet | C++ | Python/R/Julia/Go | CPU/GPU/Mobile | v | v | v |
(注,TensforFlow暂时没有公开其分布式实现)
MXNet的系统架构如下图所示:
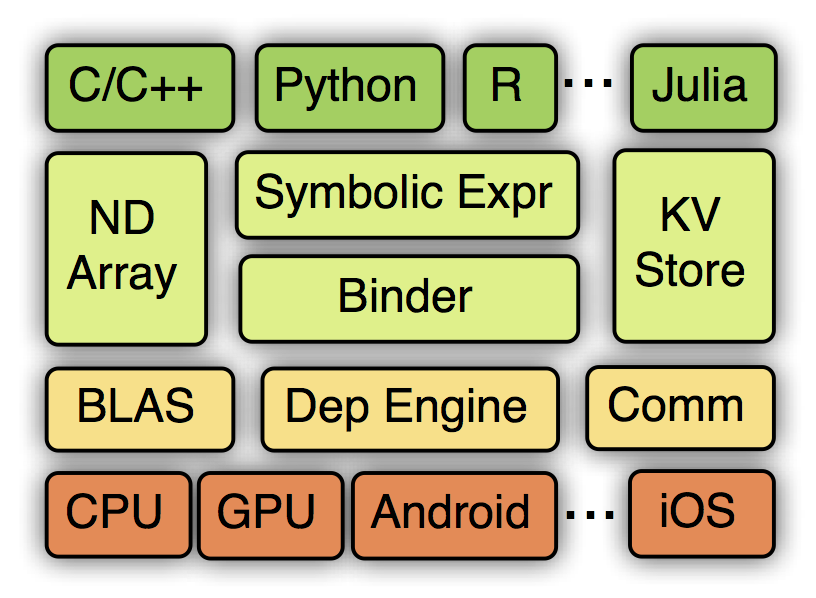
从上到下分别为各种主语言的嵌入,编程接口(矩阵运算,符号表达式,分布式通讯),两种编程模式的统一系统实现,以及各硬件的支持。接下一章我们将介绍编程接口,然后下一章介绍系统实现。之后我们给出一些实验对比结果,以及讨论MXNet的未来。
编程接口
Symbol: 声明式的符号表达式
MXNet使用多值输出的符号表达式来声明计算图。符号是由操作子构建而来。一个操作子可以是一个简单的矩阵运算“+”,也可以是一个复杂的神经网络里面的层,例如卷积层。一个操作子可以有多个输入变量和多个输出变量,还可以有内部状态变量。一个变量既可以是自由的,我们可以之后对其赋值;也可以是某个操作子的输出。例如下面的代码中我们使用Julia来定义一个多层感知机,它由一个代表输入数据的自由变量,和多个神经网络层串联而成。
using MXNet mlp = @mx.chain mx.Variable(:data) => mx.FullyConnected(num_hidden=64) => mx.Activation(act_type=:relu) => mx.FullyConnected(num_hidden=10) => mx.Softmax()
在执行一个符号表达式前,我们需要对所有的自由变量进行赋值。上例中,我们需要给定数据,和各个层里隐式定义的输入,例如全连接层的权重和偏值。我们同时要申明所需要的输出,例如softmax的输出。
除了执行获得softmax输出外(通常也叫forward),符号表达式也支持自动求导来获取各权重和偏值对应的梯度(也称之为backward)。此外,我们还可以提前估计计算时需要的内存,符号表达式的可视化,读入和输出等。
NDArray:命令式的张量计算
MXNet提供命令式的张量计算来桥接主语言的和符号表达式。下面代码中,我们在GPU上计算矩阵和常量的乘法,并使用numpy来打印结果
>>> import MXNet as mx >>> a = mx.nd.ones((2, 3), ... mx.gpu()) >>> print (a * 2).asnumpy() [[ 2. 2. 2.] [ 2. 2. 2.]]
另一方面,NDArray可以无缝和符号表达式进行对接。假设我们使用Symbol定义了一个神经网络,那么我们可以如下实现一个梯度下降算法
for (int i = 0; i < max_iter; ++i) {
network.forward();
network.backward();
network.weight -= eta * network.gradient
}
这里梯度由Symbol计算而得。Symbol的输出结果均表示成NDArray,我们可以通过NDArray提供的张量计算来更新权重。此外,我们还利用了主语言的for循环来进行迭代,学习率eta也是在主语言中进行修改。
上面的混合实现跟使用纯符号表达式实现的性能相差无二,然后后者在表达控制逻辑时会更加复杂。其原因是NDArray的执行会和Symbol类似的构建一个计算图,并与其他运算一同交由后台引擎执行。对于运算-=由于我们只是将其结果交给另一个Symbol的forward作为输入,因此我们不需要立即得到结果。当上面的for循环结束时,我们只是将数个Symbol和NDarray对应的计算图提交给了后台引擎。当我们最终需要结果的时候,例如将weight复制到主语言中或者保存到磁盘时,程序才会被阻塞直到所有计算完成。
KVStore:多设备间的数据交互
MXNet提供一个分布式的key-value存储来进行数据交换。它主要有两个函数,
1. push: 将key-value对从一个设备push进存储
2. pull:将某个key上的值从存储中pull出来此外,KVStore还接受自定义的更新函数来控制收到的值如何写入到存储中。最后KVStore提供数种包含最终一致性模型和顺序一致性模型在内的数据一致性模型。
在下面例子中,我们将前面的梯度下降算法改成分布式梯度下降。
KVStore kvstore("dist_async");
kvstore.set_updater([](NDArray weight, NDArray gradient) {
weight -= eta * gradient;
});
for (int i = 0; i < max_iter; ++i) {
kvstore.pull(network.weight);
network.forward();
network.backward();
kvstore.push(network.gradient);
}
在这里我们先使用最终一致性模型创建一个kvstore,然后将更新函数注册进去。在每轮迭代前,每个计算节点先将最新的权重pull回来,之后将计算的得到的梯度push出去。kvstore将会利用更新函数来使用收到的梯度更新其所存储的权重。
这里push和pull跟NDArray一样使用了延后计算的技术。它们只是将对应的操作提交给后台引擎,而引擎则调度实际的数据交互。所以上述的实现跟我们使用纯符号实现的性能相差无几。
读入数据模块
数据读取在整体系统性能上占重要地位。MXNet提供工具能将任意大小的样本压缩打包成单个或者数个文件来加速顺序和随机读取。
通常数据存在本地磁盘或者远端的分布式文件系统上(例如HDFS或者Amazon S3),每次我们只需要将当前需要的数据读进内存。MXNet提供迭代器可以按块读取不同格式的文件。迭代器使用多线程来解码数据,并使用多线程预读取来隐藏文件读取的开销。
训练模块
MXNet实现了常用的优化算法来训练模型。用户只需要提供数据数据迭代器和神经网络的Symbol便可。此外,用户可以提供额外的KVStore来进行分布式的训练。例如下面代码使用分布式异步SGD来训练一个模型,其中每个计算节点使用两快GPU。
import MXNet as mx
model = mx.model.FeedForward(
ctx = [mx.gpu(0), mx.gpu(1)],
symbol = network,
num_epoch = 100,
learning_rate = 0.01,
momentum = 0.9,
wd = 0.00001,
initializer = mx.init.Xavier(factor_type="in", magnitude=2.34))
model.fit(
X = train_iter,
eval_data = val_iter,
kvstore = mx.kvstore.create('dist_async'),
epoch_end_callback = mx.callback.do_checkpoint('model_'))
系统实现
计算图
一个已经赋值的符号表达式可以表示成一个计算图。下图是之前定义的多层感知机的部分计算图,包含forward和backward。
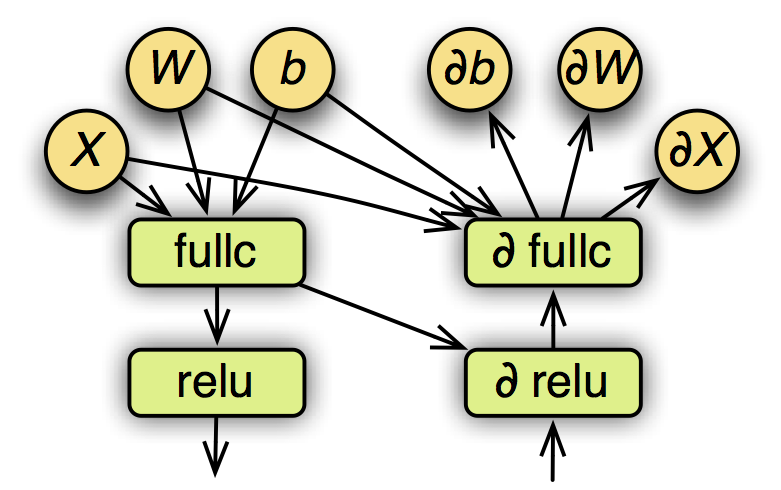
其中圆表示变量,方框表示操作子,箭头表示数据依赖关系。在执行之前,MXNet会对计算图进行优化,以及为所有变量提前申请空间。
计算图优化
计算图优化已经在数据库等领域被研究多年,我们目前只探索了数个简单的方法。
1. 注意到我们提前申明了哪些输出变量是需要的,这样我们只需要计算这些输出需要的操作。例如,在预测时我们不需要计算梯度,所以整个backforward图都可以忽略。而在特征抽取中,我们可能只需要某些中间层的输出,从而可以忽略掉后面的计算。
2. 我们可以合并某些操作。例如 ab+1*只需要一个blas或者cuda函数即可,而不需要将其表示成两个操作。
3. 我们实现了一些“大”操作,例如一个卷积层就只需要一个操作子。这样我们可以大大减小计算图的大小,并且方便手动的对这个操作进行优化。
内存申请
内存通常是一个重要的瓶颈,尤其是对GPU和智能设备而言。而神经网络计算时通常需要大量的临时空间,例如每个层的输入和输出变量。对每个变量都申请一段独立的空间会带来高额的内存开销。幸运的是,我们可以从计算图推断出所有变量的生存期,就是这个变量从创建到最后被使用的时间段,从而可以对两个不交叉的变量重复使用同一内存空间。这个问题在诸多领域,例如编译器的寄存器分配上,有过研究。然而最优的分配算法需要 O(n2) 时间复杂度,这里n是图中变量的个数。
MXNet提供了两个启发式的策略,每个策略都是线性的复杂度。
1. inplace。在这个策略里,我们模拟图的遍历过程,并为每个变量维护一个还有多少其他变量需要它的计数。当我们发现某个变量的计数变成0时,我们便回收其内存空间。
2. co-share。我们允许两个变量使用同一段内存空间。这么做当然会使得这两个变量不能同时在写这段空间。所以我们只考虑对不能并行的变量进行co-share。每一次我们考虑图中的一条路(path),路上所有变量都有依赖关系所以不能被并行,然后我们对其进行内存分配并将它们从图中删掉。
引擎
在MXNet中,所有的任务,包括张量计算,symbol执行,数据通讯,都会交由引擎来执行。首先,所有的资源单元,例如NDArray,随机数生成器,和临时空间,都会在引擎处注册一个唯一的标签。然后每个提交给引擎的任务都会标明它所需要的资源标签。引擎则会跟踪每个资源,如果某个任务所需要的资源到到位了,例如产生这个资源的上一个任务已经完成了,那么引擎会则调度和执行这个任务。
通常一个MXNet运行实例会使用多个硬件资源,包括CPU,GPU,PCIe通道,网络,和磁盘,所以引擎会使用多线程来调度,既任何两个没有资源依赖冲突的任务都可能会被并行执行,以求最大化资源利用。
与通常的数据流引擎不同的是,MXNet的引擎允许一个任务修改现有的资源。为了保证调度正确性,提交任务时需要分开标明哪些资源是只读,哪些资源会被修改。这个附加的写依赖可以带来很多便利。例如我们可以方便实现在numpy以及其他张量库中常见的数组修改操作,同时也使得内存分配时更加容易,比如操作子可以修改其内部状态变量而不需要每次都重来内存。再次,假如我们要用同一个种子生成两个随机数,那么我们可以标注这两个操作会同时修改种子来使得引擎不会并行执行,从而使得代码的结果可以很好的被重复。
数据通讯
KVStore的实现是基于参数服务器。但它跟前面的工作有两个显著的区别。
1. 我们通过引擎来管理数据一致性,这使得参数服务器的实现变得相当简单,同时使得KVStore的运算可以无缝的与其他结合在一起。
2. 我们使用一个两层的通讯结构,原理如下图所示。第一层的服务器管理单机内部的多个设备之间的通讯。第二层服务器则管理机器之间通过网络的通讯。第一层的服务器在与第二层通讯前可能合并设备之间的数据来降低网络带宽消费。同时考虑到机器内和外通讯带宽和延时的不同性,我们可以对其使用不同的一致性模型。例如第一层我们用强的一致性模型,而第二层我们则使用弱的一致性模型来减少同步开销。
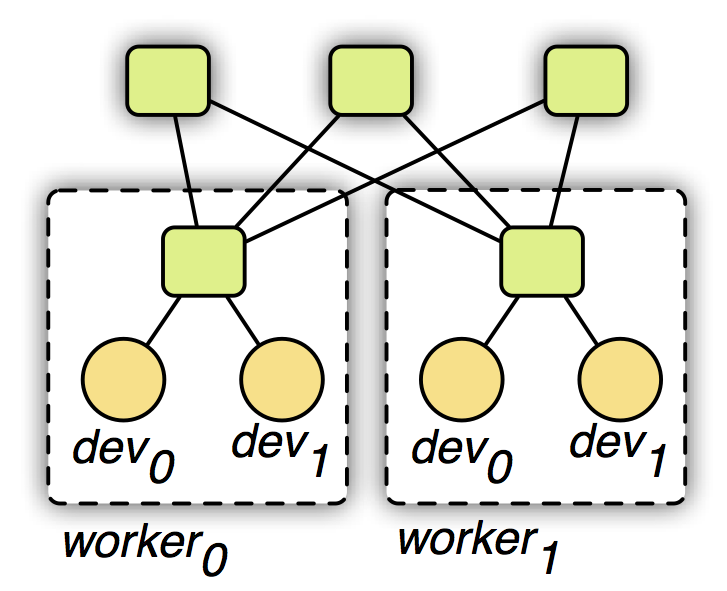
可移植性
轻量和可移植性是MXNet的一个重要目标。MXNet核心使用C++实现,并提供C风格的头文件。因此方便系统移植,也使得其很容易被其他支持C FFI (forigen language interface )的语言调用。此外,我们也提供一个脚本将MXNet核心功能的代码连同所有依赖打包成一个单一的只有数万行的C++源文件,使得其在一些受限的平台,例如智能设备,方便编译和使用。
实验结果
这里我们提供一些早期的实验结果。
与其他系统相比
我们首先使用一个流行卷积网络测试方案来对比MXNet与Torch,Caffe和TensorFlow在过去几届imagenet竞赛冠军网络上的性能。每个系统使用同样的CUDA 7.0和CUDNN 3,但TensorFlow使用其只支持的CUDA 6.5 和CUDNN 2。我们使用单块GTX 980并报告单个forward和backward的耗时。
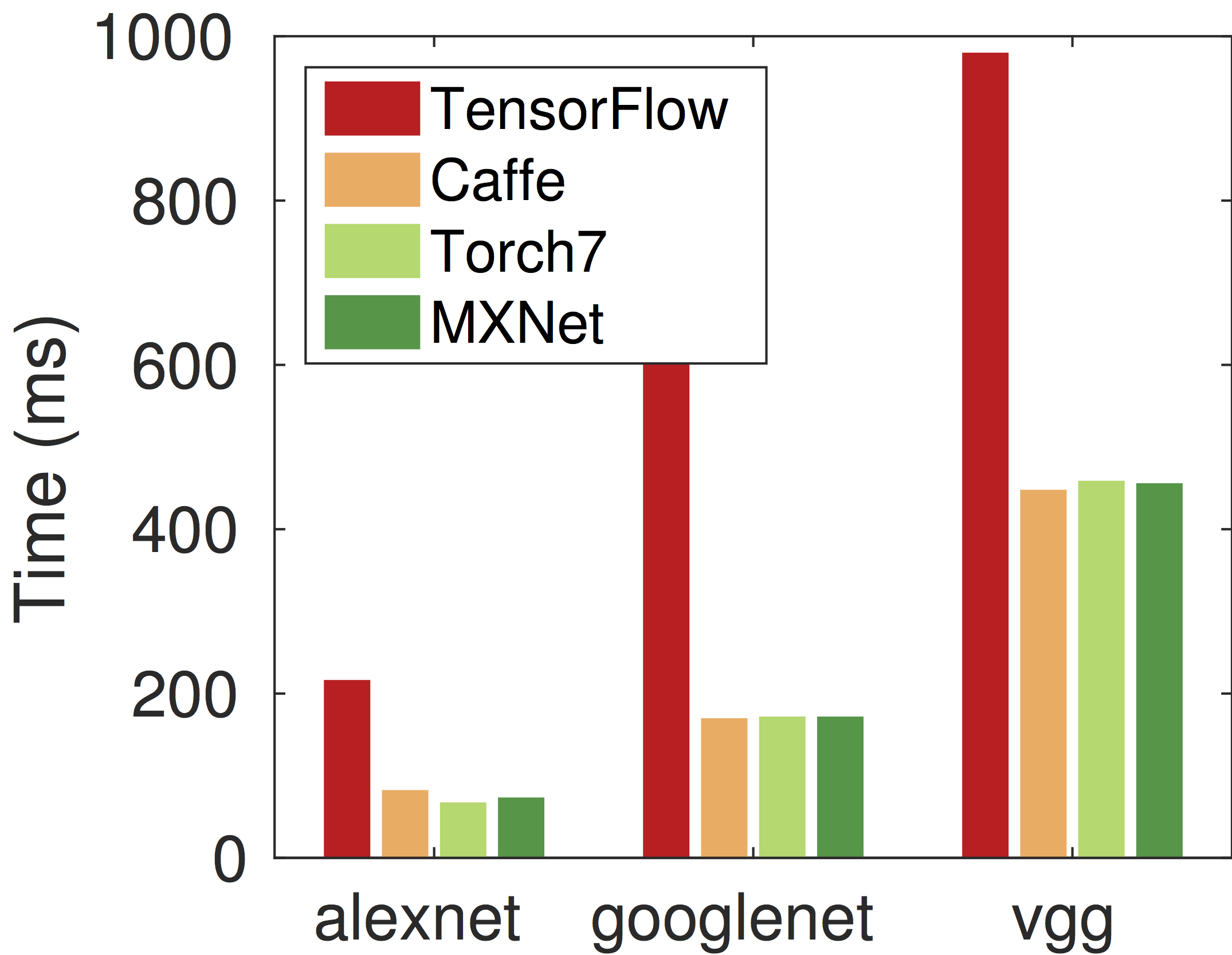
可以看出MXNet,Torch和Caffe三者在性能上不相上下。这个符合预期,因为在单卡上我们评测的几个网络的绝大部分运算都由CUDA和CUDNN完成。TensorFlow比其他三者都慢2倍以上,这可能由于是低版本的CUDNN和项目刚开源的缘故。
内存的使用
接下来我们考察不同的内存分配算法对内存占用的影响。下图分别表示使用batch=128时,在做预测时和做训练时的不同算法在内部变量(除去模型,最初输入和最终输出)上的内存开销。
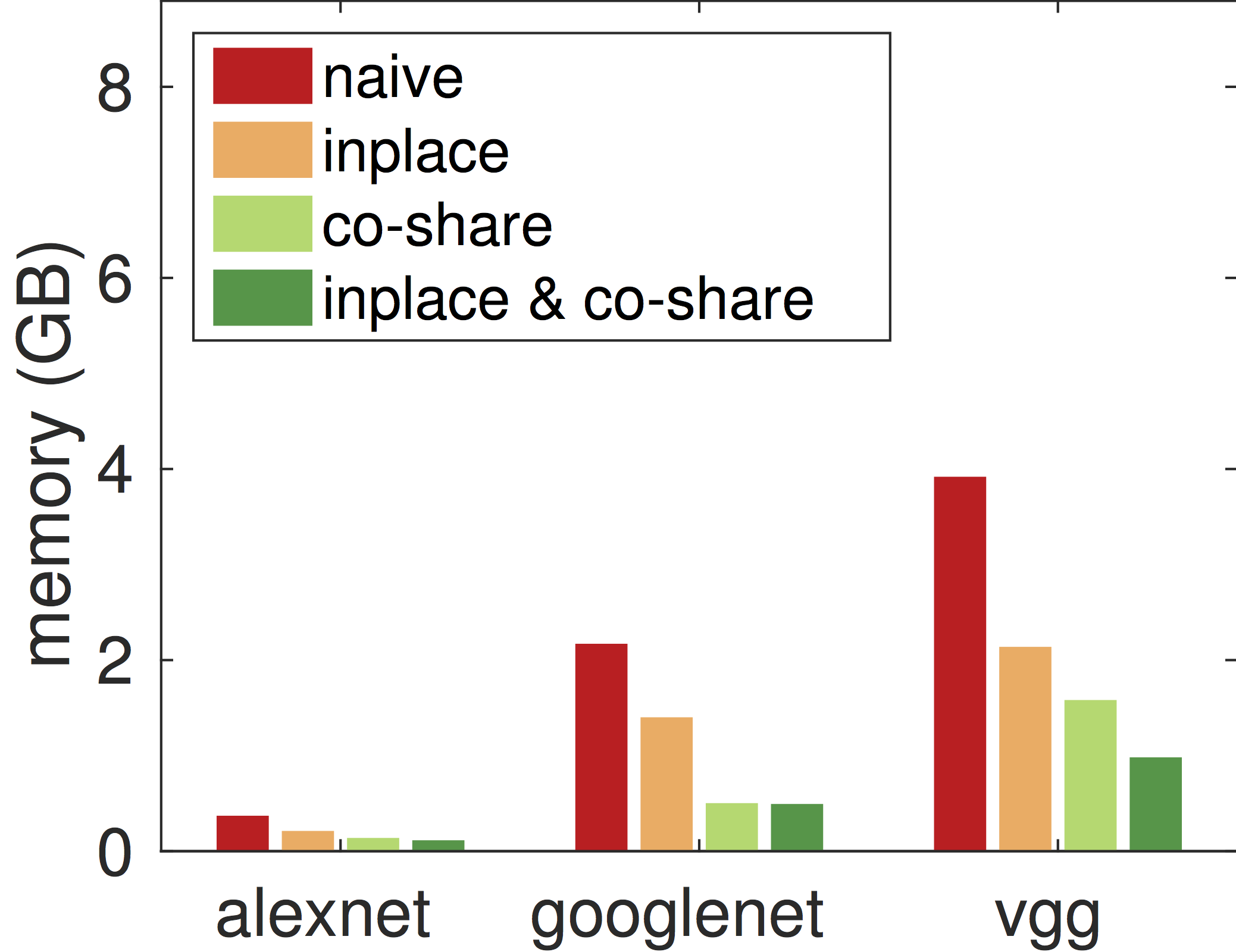
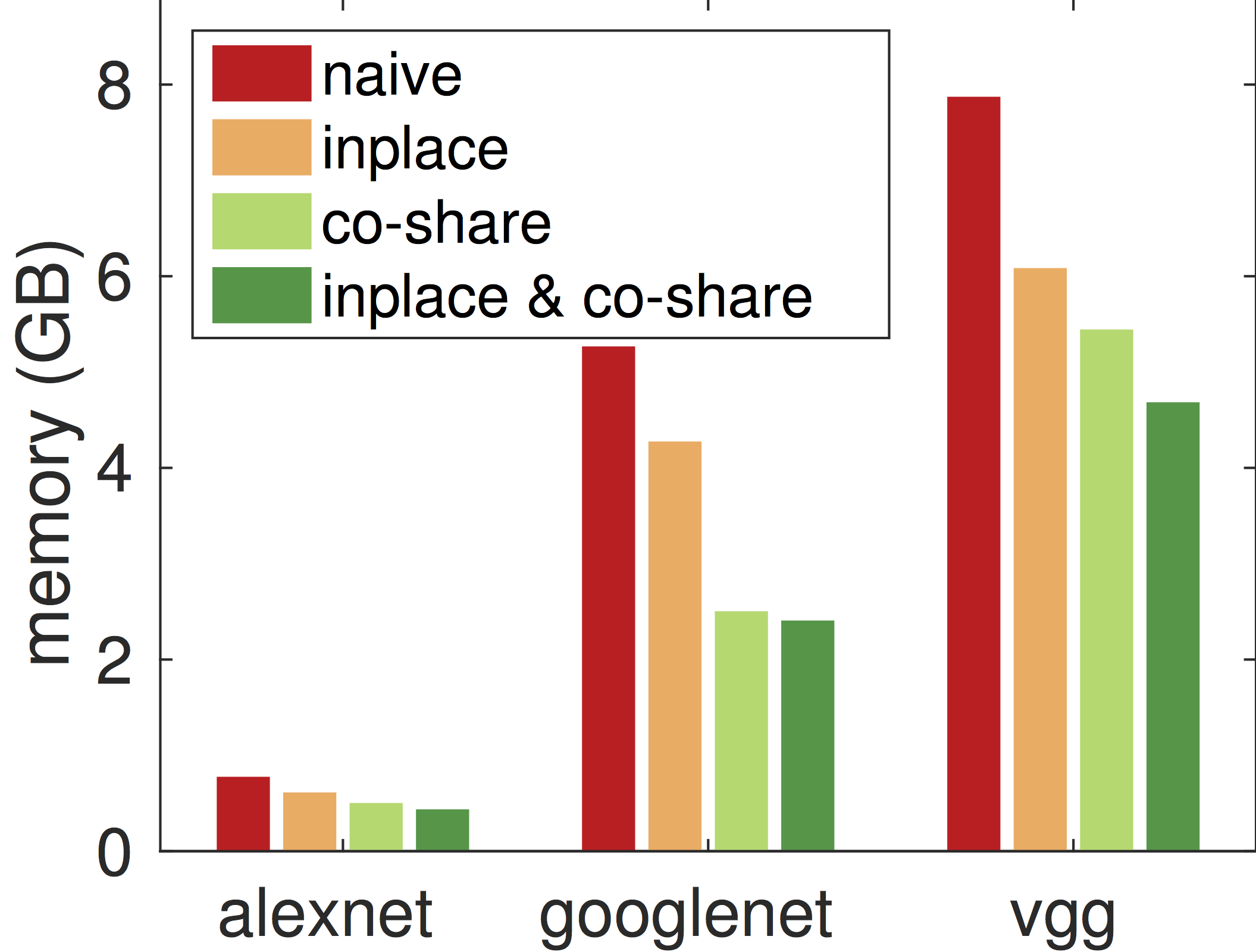
可以看出,inplace和co-share两者都可以极大的降低内存使用。将两者合起来可以在训练时减少2倍内存使用,在预测时则可以减小4倍内存使用。特别的,即使是最复杂的vggnet,对单张图片进行预测时,MXNet只需要16MB额外内存。
Scalability
最后我们报告在分布式训练下的性能。我们使用imagenet 1k数据(120万224x224x3图片,1000类),并用googlenet加上batch normalization来训练。我们使用Amazon EC2 g2.8x,单机和多机均使用同样的参数,下图表示了使用单机和10台g2.8x时的收敛情况。
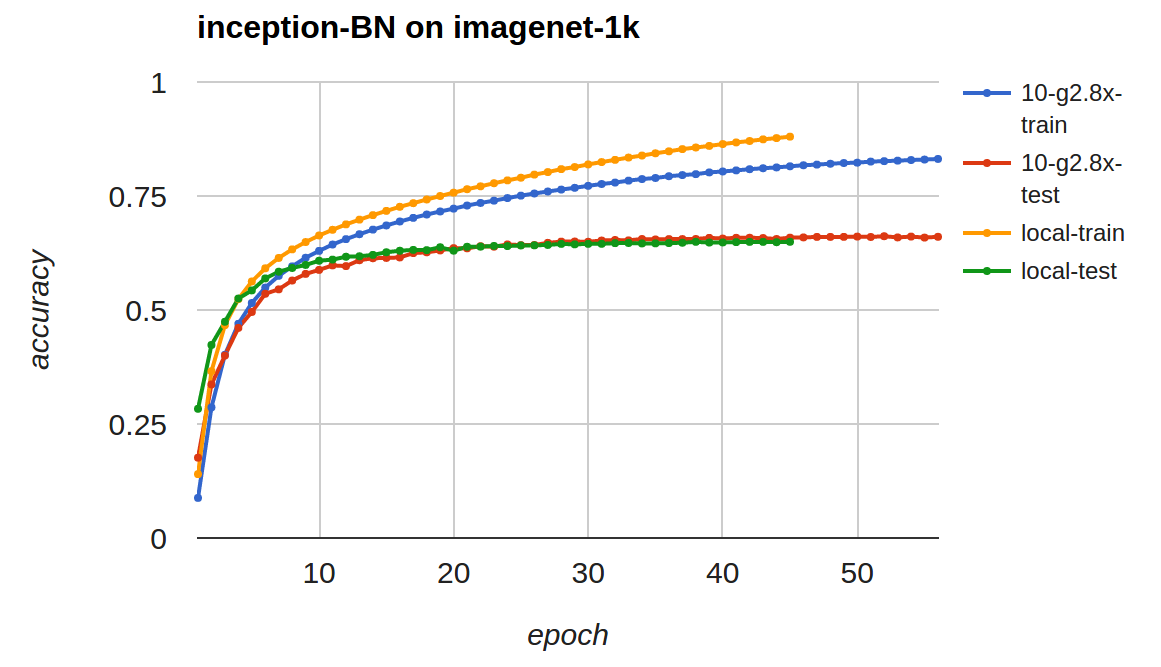
从训练精度来看,单机的收敛比多机快,这个符合预期,因为多机时有效的batch大小比单机要大,在处理同样多的数据上收敛通常会慢。但有意思的是两者在测试精度上非常相似。
单机下每遍历一次数据需要1万4千秒,而在十台机器上,每次只需要1千4百秒。如果考虑运行时间对比测试精度,10台机器带来了10倍的提升。
过去,现状,和未来
大半年前我们拉来数个优秀的C++机器学习系统的开发人员成立了DMLC,本意是更方便共享各自项目的代码,并给用户提供一致的体验。当时我们有两个深度学习的项目,一个是CXXNet,其通过配置来定义和训练神经网络。另一个是Minerva,提供类似numpy一样的张量计算接口。前者在图片分类等使用卷积网络上很方便,而后者更灵活。那时候我们想要能不能一个两者功能都具备的系统,于是这样就有了MXNet。其名字来自Minerva的M和CXXNet的XNet。其中Symbol的想法来自CXXNet,而NDArray的想法来自Minerva。我们也常把MXNet叫“mix net”。
MXNet是DMLC第一个结合了所有的成员努力的项目,也同时吸引了很多核心成员的加入。MXNet目的是做一个有意思的系统,能够让大家用着方便的系统,一个轻量的和可以快速测试系统和算法想法的系统。对于未来,我们主要关注下面四个方向:
- 支持更多的硬件,我们目前在积极考虑支持AMD GPU,高通GPU,Intel Phi,FPGA,和更多智能设备。相信MXNet的轻量和内存节省可以在这些上大有作为。
- 更加完善的操作子。目前不论是Symbol还是NDArray支持的操作还是有限,我们希望能够尽快的扩充他们。
- 更多编程语言。除了C++,目前MXNet对Python,R和Julia的支持比较完善。但我们希望还能有很多的语言,例如javascript。
-
更的应用。我们之前花了很多精力在图片分类上,下面我们会考虑很多的应用。例如上周我们试了下如何利用一张图片的风格和一张图片的内容合成一张新图片。下图是利用我办公室窗景和梵高的starry night来合成图片



接下来我们希望能够在更多应用,例如语音,翻译,问答,上有所产出。
我们忠心希望MXNet能为大家做深度学习相关研究和应用带来便利。也希望能与更多的开发者一起学习和进步。
——————————————————————————————————————————
延伸一:主流分类模型对比
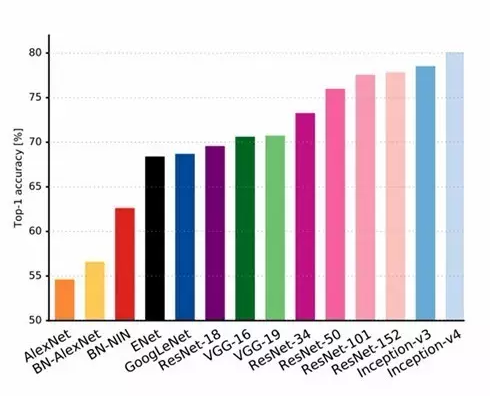
来源【干货】ImageNet 历届冠军最新评析:哪个深度学习模型最适合你?
来看看主流分类框架的精确度,