
热门标签
热门文章
- 1支付宝二面:生成订单30分钟未支付,则自动取消,该怎么实现?
- 2Android集成Unity(二)_android studio集成游戏引擎
- 3Jetty学习2.Eclipse中安装Jetty插件_org.eclipse.jetty在哪个jar
- 4Linux 命令大全(看这一篇就足够)_linux命令
- 5纯干货全面解读AI框架RAG_rag ai
- 6什么是好的FPGA编码风格?(3)--尽量不要使用锁存器Latch_vivado ldce
- 7【Devops】【docker】【CI/CD】Jenkins源码管理,设置gitlab上项目的clone地址 + jenkins构建报错:Please make sure you have the ...
- 8点击按钮弹出模态框实现_怎么函数通过点击图片显示模态框
- 9Uniapp+vue3 APP上传图片到oss_uni.uploadfile put上传图片到oss
- 10Kafka消费组rebalance原理_kafka rebalance
当前位置: article > 正文
BERT直观理解_使用bert模型进行时序数据分类
作者:你好赵伟 | 2024-02-29 11:45:18
赞
踩
使用bert模型进行时序数据分类
BERT架构图

简单解释一下BERT的架构图。位置向量解决了时序问题(RNN不能并行的执行,只能一个一个的来,但是不一个一个的来,时序即word的先后顺序,怎么处理呢,位置向量就解决了);Self-Attention解决RNN不能并行的问题,multi-head可以提取到多种语义的层次表达,这一部分是核心;接着将向量层的数据(向量表示)和Mutil-Head-Attention的数据进行合并,这个操作叫残差连接,为了使下一层不比上一层差,其中归一化(标准化)的操作是为了更好的求导,防止梯度消失,还能让模型快速收敛;然后通过全连接层对数据特征进行再一次提取,针对上一层使用激活函数进行激活,提取特征,针对上一层数据进行维度变换成可以和上一层LayerNorm一样的维度,以利于再进行残差连接;接着合并第三层数据与全连接层并归一化;至此,一个Transformer Encoder就完了,重复多个这样的block,然后将得到的词向量用于下游任务。
那么BERT是怎么去训练的呢?它没有使用label,而是使用两种预训练模式,让其理解上下文,得到训练结果。
第一个预训练叫做Masked LM,简单来说, 就是随机遮盖或替换一句话里面任意字或词, 然后让模型通过上下文的理解预测那一个被遮盖或替换的部分。
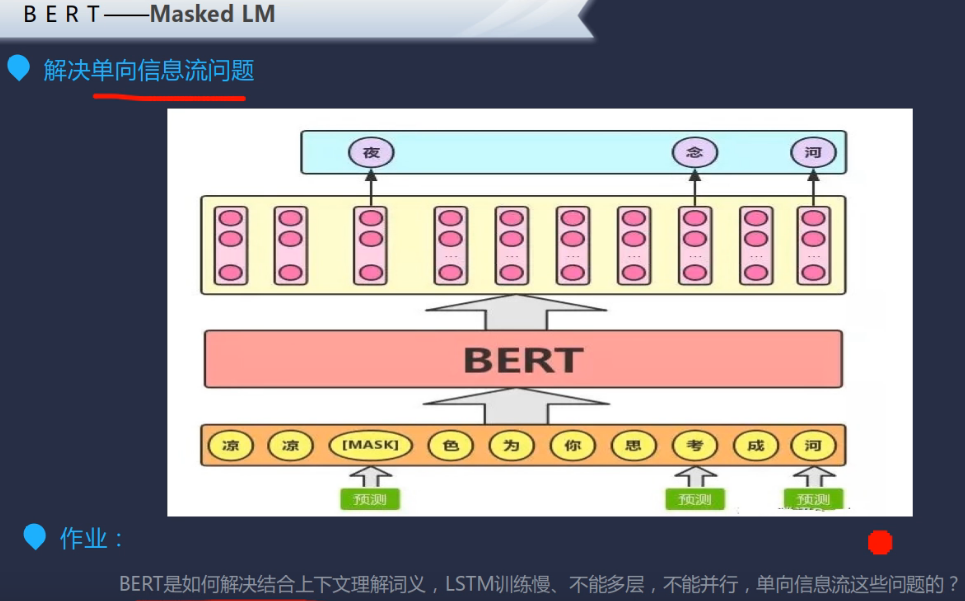
第二个预训练是Next Sentence Prediction,简言之,随机替换一些句子,然后利用上一句进行IsNext/NotNext的预测。
向量层
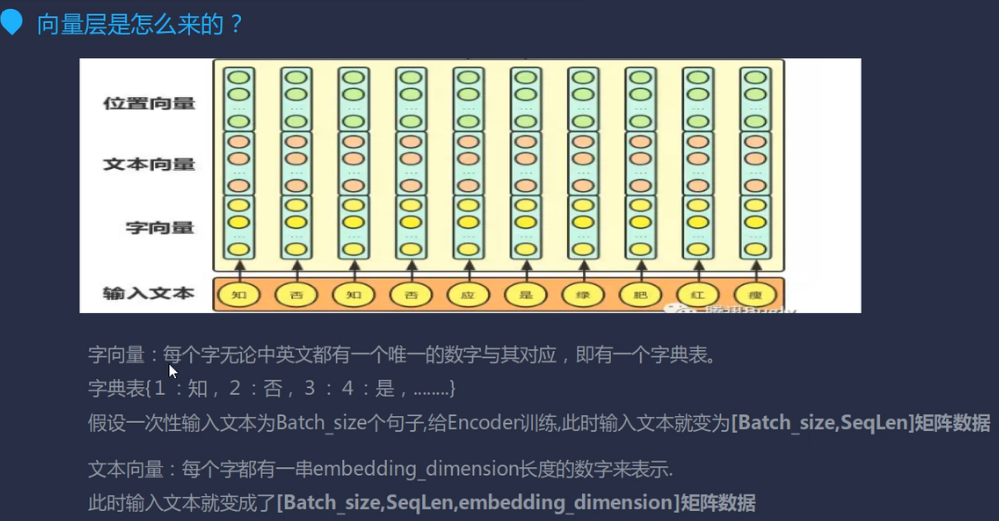
其中,SeqLen是最大的那个句子的长度,文本向量中,每个字用一个长度为embedding_dimension的数字表示,这是TF提供的转换方法。
位置向量

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/165411
推荐阅读
相关标签

