
热门标签
当前位置: article > 正文
大模型训练之并行篇-------数据并行/模型并行(层间层内)/流水并行_模型并行的图片
作者:你好赵伟 | 2024-03-21 01:21:50
赞
踩
模型并行的图片
- 数据并行(data parallelism, DP):假设有 张卡,每张卡都保存一个模型,每一次迭代(iteration/step)都将batch数据分割成 个等大小的micro-batch,每张卡根据拿到的micro-batch数据独立计算梯度,然后调用AllReduce计算梯度均值,每张卡再独立进行参数更新。
- 模型并行(model parallelism/tensor parallelism, MP/TP):有的tensor/layer很大,一张卡放不下,将tensor分割成多块,一张卡存一块。
- 流水并行(pipeline parallelism, PP):将网络按层切分,划分成多组,一张卡存一组。
- 张量模型并行
模型并行
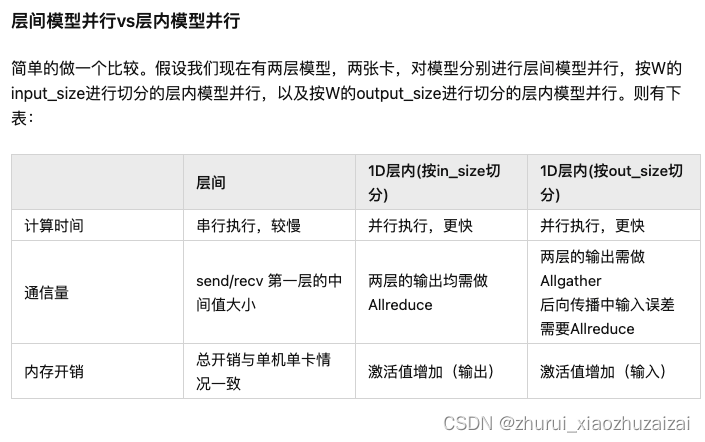
模型并行:层间模型并行(inter-layer)和层内模型并行(intra-layer)。
NUS的文章基本上都是针对intra-layer的model-paralleism,或者也可以叫tensor parallelism。
层内模型并行可以对输入矩阵,或者参数矩阵进行其中一个维度的切分,并将切片放到不同的设备上去。典型例子就是1D的Megatron。
层间模型并行则是对模型层进行切分,业界也有很多做框架的公司管它叫Pipeline并行,但是我的观点是层间模型并行只有真的流水起来了才能够叫Pipeline并行。
1D 2D 2.5D 3D模型并行详细介绍:
GPT 不同层的并行embedding self-att MLP
Tensor Parallelism
张量模型并行(Tensor Model Parallelism),Megatron就是使用了这种方式
XA = Y行并行(Row Parallelism)
就是把 A 按照行分割成两部分
列并行
Y=[Y1,Y2]MLP
对于第一个全连接层:使用列分割
对于第二个全连接层:使用行切分
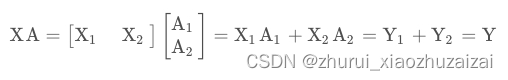
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】

