
- 1计算机视觉任务汇总(超全)_计算机视觉常见任务
- 2ChatGLM-6B部署和微调实例_调试chatglm-6b
- 3拉扎维模集英文原版阅读笔记1_拉扎维张鸿学习笔记
- 4 多图带你读懂 Transformers 的工作原理
- 5PaddleOCR #使用PaddleOCR进行光学字符识别 - OCR模型对比_check_and_read_gif
- 62023媒体邀约企业发布会现场采访报道需要注意这3点
- 7天池医疗AI大赛[第一季] Rank8解决方案[附TensorFlow/PyTorch/Caffe实现方案]
- 8算法工程师-笔(面)试题汇总_算法工程师笔试题
- 9USAD : UnSupervised Anomaly Detection on Multivariate Time Series_usad - unsupervised anomaly detection on multivari
- 10【AAAI 2021】全部接受论文列表(一)_rt3d: achieving real-time execution of 3d convolut
原创《基于深度特征学习的细粒度图像分类研究综述》_ma-cnn
赞
踩
原创,未经同意,请勿转载
后记:这篇综述文章虽然是19年放出来,但是我在18年初的时候写的,当时准备找个国内期刊投一下的,后面某些原因放弃了。所以文中引用的方法都是17年以前的,有点过时了,现在又出现了好多新方法,最高的在CUB上的精确度已经达到了91%左右
摘 要
深度学习技术已经在各种视觉分析任务中展现出了其强大的特征提取能力。特别是在细粒度图像分类领域,深度特征提取技术让其获得了巨大的性能提升。基于深度学习模型提取到的深度特征具有很强的表达能力。细粒度图像分类旨在对大的类别进行子类的划分,如区分不同种类的鸟。由于这些子类具有较大的类内差异和较小的类间差异,因此这种识别任务更加具有挑战性。本文综合介绍了基于深度特征学习的细粒度图像分类方法的四种类型,包括一般的卷积神经网络(CNN),基于局部特征的检测的方法,基于神经网络集成的方法,和基于视觉注意力的细粒度图像分类方法。本文还比较了这些分类算法在常用数据集上的性能表现,最后分析并总结了该领域未来可能的研究方向。
关键词 细粒度图像分类 深度学习 卷积神经网络 计算机视觉
0 引 言
随着近几年深度学习[1] 的兴起,神经网络技术作为深度学习的核心技术,已经取得了较大的突破。图像分类的准确率成为了新的神经网络模型的性能检验标准。作为图像分类技术研究的热点领域之一的细粒度图像分类(fine-grained image categorization),也被称为细粒度识别、子类别分类,是计算机视觉领域兴起的新的研究热点。细粒度图像分类旨在对大类别比如鸟类[2] ,进行更加细致的划分。此类任务非常具有挑战性,这是由于子类类别的微小的类间差异和较大的类内差异,相比于普通的图像分类任务,细粒度的图像分类显然难度要大得多。
早期的细粒度图像分类方法都是基于人工设计的特征的分类算法,人工设计特征的表达能力非常有限,因此分类效果并不理想。并且人工特征大多依赖于大量的人工标注信息,耗费资源的同时也限制了该类算法的应用场景。近年来由于深度学习技术的快速发展,特别是卷积神经网络技术的快速进步,使得深度学习特征在细粒度图像分类上应用广泛。基于深度学习得到的特征具有更强的表达能力,因此涌现大量的基于深度特征学习的算法,这极大的促进了该领域的研究进步。深度学习模型具有端到端训练的特点,并且基于深度特征学习的算法日趋不再依赖于人工标注信息,而仅仅使用图像的类别标签,这使得细粒度图像分类技术发展更为迅速,该领域也日趋发展成熟。
文章剩下的部分内容组织如下:在第1节,我们将从细粒度图像分类的概念开始,简要介绍该领域的发展现状以及技术难点。在接下来的第2节,我们给出几个目前最为常用的细粒度图像分类数据库,其中鸟类数据库将在之后的方法性能比较中用到。本文的主要内容,基于深度特征学习的细粒度图像分类方法,将在第3节介绍。性能比较和最后的总结分别在第4、5节给出。
1 细粒度图像分类概述
图像分类是计算机视觉领域的一个热门研究课题。随着深度学习的进步,细粒度图像分类受到了相当多的关注。近年来已经提出了许多基于深度学习的细粒度分类方法。细粒度图像分类旨在将对象与一般类别中的不同子类别区分开来,例如,不同种类的鸟类[2] ,狗[3] 或不同类型的汽车[4] 。然而,细粒度分类是一项非常具有挑战性的任务[5] ,因为来自相近子类别的对象可能具有微小的类别差异,而同一子类的对象,由于存在拍摄尺度或视角的不同,或是对象姿态的不同、复杂背景和遮挡的变化,导致同一子类别中的对象可能呈现较大的外观变化。因此造成了细粒度分类的难度较大。

(a) 加利福利亚海鸥

(b) 北极海鸥
图1 来自CUB 200数据集的两种海鸥:同种海鸥的姿势、背景和视角变化很大。区分性差异仅存在于一些微小的区域,例如喙或翅膀。
图1展示了两种不同种类的海鸥,它们具有较大的类内差异和较小的类间差异。以海鸥的分类为例,仅仅海鸥这一生物,就有加利福尼亚海鸥,北极海欧,加州鸥,银鸥,象牙海鸥等多个不同的种类,这些不同种的海鸥之间差异十分微小,因此想要挖掘出有用的信息也十分困难。有的仅仅是翅膀或者喙的差异,即使是对于鸟类专家而言,要想完全识别出这些海鸥也有一定难度。
细粒度图像分类具有很广阔的应用前景,这一技术日趋成熟后,将在濒危生物物种保护,商品识别,交通违章汽车管理等许多领域都发挥重要作用。例如,在生态保护中,准确有效地识别出不同种类的生物,才能采取进一步措施对其进行相关的管理和保护。以前这些任务都只能由生态保护领域的专家来完成,因此大大提高了保护成本。但如果借助于现在的计算机视觉技术,利用细粒度识别技术对鸟类进行有效识别,则可以节省大量的人力物力,也提高了效率。细粒度识别相关的研究目标还有花,狗,汽车,飞机[6] 等,这些目标对于人类相关细粒度识别技术研究具有重要意义,因此也诞生了相关的一些图像数据库。这些数据库将在下一节中进行介绍。
和普通的图像识别任务不同,细粒度图像识别的具有区分度的重要信息往往是包含在一些很小的局部区域,并且很多时候都也仅有局部微小区域不同。因此,如何准确有效地找到并充分利用这些有效信息,则成为细粒度识别准确与否的关键所在。目前,绝大多数的分类算法大致遵循以下的步骤:首先找到目标对象和局部区域,然后对这些区域提取深度特征并进行适当处理,之后用来完成分类器的训练,最后结合对象和局部区域的预测成为最终的预测。
因此,特征的提取是决定图像分类性能的关键因素。如何寻找最具有区分性的特征是这些分类算法的主要创新点或者说是主要差异所在。早期的基于人工特征的分类算法具有很大的局限性。这类算法一般是先从图像中提取SIFT[7] (Scale invariant feature transform)或者HOG[8] (Histogram of orienred gradient)这些局部特征,之后利用VLAD[9] (Vector of locally aggregated descriptors)或者Fisher vector[10] ,11] 等编码模型进行特征编码,得到最终需要的特征表示。然而由于人工特征的表达能力十分有限,分类效果并不是很好。近年来由于深度学习,尤其是卷积神经网络在计算机视觉领域取得的巨大成功,使得研究人员将深度卷积特征应用到细粒度图像分类中来,从深度卷积神经网络中提取到的特征比人工特征具有更强的表达能力,因此取得了更好的分类效果。
根据算法在训练时有无人工标注信息(Annotations),可以分为强监督的细粒度图像分类和弱监督的细粒度图像分类。强监督的细粒度分类在算法训练过程中需要提供标注信息,主要是指标注框(Bounding box)和局部区域定位(Part locations)等,借助于这些信息算法能准确地完成局部定位和获取前景对象,但由于人工标注信息代价昂贵,因此也限制了此类算法的实用性。弱监督的细粒度分类则仅要求给图片提供类别信息。因此应用场景更为广泛,近年来的算法大部分都是研究弱监督的细粒度图像分类,并取得了较大突破,某些算法甚至可以媲美最好的强监督学习算法的性能。
现有的基于深度特征学习的细粒度图像分类方法可以根据有无标注信息或人类推理的使用分为以下四类[5] :1)直接使用一般深度神经网络(主要是CNN)进行细粒度图像分类的方法;2)使用深度神经网络作为特征提取器,来更好地定位对象的不同部分并进行对齐,从而进行细粒度分类的方法;3)使用多个深度神经网络以更好地区分在视觉上高度相似的细粒度图像,以及4)根据人类视觉注意机制来找出细粒度图像的最具辨别力的区域从而进行分类的方法。
2 细粒度图像分类数据库介绍
与普通的图像分类数据库相比,细粒度的图像数据库要求更高,需要具备更多相关领域的专家知识,来完成图片的采集和标注。近年来由于细粒度图像分类成为研究热点,出现了越来越多的细粒度图像数据库。下面将对一些主要的细粒度图像数据库进行简单介绍。
1)CUB-200-2011[2] :细粒度图像分类领域最经典,也是最常用的一个数据库。共包含200种不同的鸟类,一共有11788张图片。该数据库的每张图片都提供了丰富的人工标注信息,包含标注框和局部区域位置信息。
2)Stanford Dogs[3] :提供120种不同类别的狗的图像数据,共20580张图像,每张图像除了提供类别标签外,仅提供标注框这一个人工标注信息。
3)Oxford Flowers[12] :有两种不同规模的数据库,分别含有17种类别和102种类别的花。常用的是102种类别的数据库,每类包含40到258张图像数据,共8189张图片。不含有细粒度图像标注信息。
4)Stanford Cars[4] :Stanford Cars 汽车图像数据包含196类共16185 张汽车图片。其中 8144张为训练数据,8041张为测试数据。每个类别按照“年份 制造商 型号”进行区分。只提供标注框信息。
5)FGVC-Aircraft[6] :FGVC-Aircraft包含102类不同的飞机的图片,每一种类别都含有100张不同的图片,一共10200张图像数据。除了提供类别标签外,只提供标注框这一个人工标注信息。

图2 分别从CUB200-2011、Stanford Dogs、Oxford Flowers、Stanford Cars以及FGVC-Aircraft中随机选取4张图片。可以看到,同一数据库中不同类别的图片,差异十分微小。
3 基于深度特征学习的细粒度图像分类技术
在本节中,我们将首先介绍几种卷积神经网络,这些网络将主要用于细粒度图像分类。 然后,我们分别详细阐述基于局部区域定位与对齐的方法和基于网络的集合的方法。本节的最后一部分将介绍基于视觉注意力的方法。
3.1 基于卷积神经网络的通用分类方法
CNN在计算机视觉方面有着悠久的历史。它由LeCun等人[13] 首先引入。最几年来随着大规模分类训练数据集比如ImageNet[14] 的出现,CNN在大规模视觉识别任务中表现出优越的性能。CNN令人印象深刻的表现也促使大量研究人员将在ImageNet上预训练的CNN模型用于其他领域和数据集,例如细粒度图像数据集。此外,CNN通常能够对输入图像产生更多的具有区分性的特征,这对于细粒度图像分类是必不可少的。大多数当前先进的CNN模型都可以用于细粒度图像分类。
AlexNet[15] 是一个深度卷积神经网络,它获得了ILSVRC-2012竞赛的top-5错误率的冠军,错误率仅为15.3%,远好于相比之下的第二名top-5错误率为26.2%。AlexNet是一个八层结构,前五层是卷积层,其余三个是全连接层。 图3是AlexNet模型的架构。
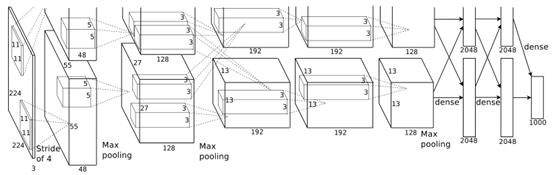
图3 AlexNet的架构
VGG网络[16] 增加了神经网络的深度,这不仅实现了在ILSVRC分类和定位任务上取得了当年最好的成绩,而且该模型对于其他图像识别数据集也具有相当不错的适应性,因此在近几年的计算机视觉研究中应用非常广泛。VGG-16具有13个卷积层和3个全连接层,VGG-19比VGG-16模型多3个卷积层。他们都使用了具有非常小的感受野的过滤器:3 × 3(这是捕获左/右,上/下,中心视野的最小尺寸)。并且所有隐藏层都使用修正非线性单元(ReLU)。
GoogLeNet[17] 在2014年刷新了ILSVRC的视觉分类和检测任务的最好成绩。该体系结构的主要亮点是提高网络内部计算资源的利用率。作者精心设计了称为“Inception”的模块,该设计模块允许增加网络的深度和宽度,同时保证了并不会增加计算量。当仅计算具有参数的层时,GoogLeNet是22层深(如果包含池化层的话,则为27层)。通过Inception模块的大量使用,GoogLeNet使用的参数不足AlexNet的1/12。Inception模块的结构如图4所示。在3×3和5×5的卷积核使用之前,先使用1×1的卷积核用于减少计算量。除了被用作减少计算量之外,也包含使用了修正线性激活单元,这使它们具有双重用途。
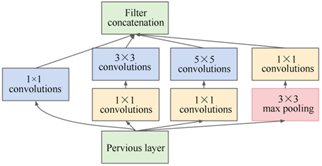
图4 GoogLetNet模型的Inception结构
用于图像分类的一些其他通用深度卷积特征提取器包括CNN feature off-the-shelf[18] ,ONE[19] 和InterActive [20] 。使用这些用于细粒度图像分类的CNN时,最后的全连接层的输出一般设置为细粒度图像分类的类别总数。例如,在用于CUB200-2011[2] 数据集分类时,全连接层输出设置为相应的属于200个类别的概率。这些分类结果表明从卷积神经网络中提取的通用描述符非常强大。
3.2 基于局部区域定位和对齐的方法
语义局部区域定位可以通过明确地分离与特定对象局部区域相关联的细微外观差异来促进细粒度分类。因此,在对象中对局部区域进行定位对于建立对象实例与同种因姿势变化和摄像机视图位置变化对象之间的对应关系非常重要。许多传统方法遵循图4所示的流水线。首先定位细粒度物体的局部区域,例如用于鸟类物种分类的头部和躯干,然后进行局部区域对齐,最后是使用在对齐的局部区域上提取的特征进行分类。POOF[21] 使用数据挖掘技术学习一组中间特征。其中的每个特征都擅长于基于特定部分的外观区分两个特定类别。为了找到准确的局部区域,例如狗的脸和眼睛,刘等人[22] 建立了基于样本的狗品种及其脸部的几何外观模型。Yang等人[23] 提出了一个模板模型用于发现对象局部区域的共同的几何图案和模式的共现统计。在对齐的共同图案中提取特征用于细粒度图像识别。类似地,Gavves等人[24] 和Chai等人[25] 采用一种无监督的方式对图像进行分割并对齐图像片段。然后使用对齐将局部区域的标注信息从训练图像迁移到测试图像并提取用于分类的特征。在本小节中,我们将介绍基于深度学习的局部区域检测方法。

图5 基于局部区域定位与对齐方法的一般框架
3.2.1 Part R-CNN算法
由于深度卷积特征的更强的表达性,许多方法中广泛使用了局部区域检测器来获取深度卷积特征,并获得了性能提升。因此,Zhang[26] 等提出Part R-CNN通过利用从自下而上产生的候选区域中学习深度卷积特征,从而学习得到局部区域检测器。 它扩展了R-CNN[27] 方法以检测对象并使用几何约束定位这些局部区域。整个过程如图6所示。首先使用自底向上的区域算法selective search[28] 产生许多的候选区域,然后目标对象和局部区域检测器都基于深度卷积特征进行训练。在测试期间,所有候选区域都由这些检测器来进行评分,根据评分分值挑选出区域检测结果。Zhang等认为R-CNN给出的评分并不能准确反映出每个区域的好坏。因此使用一些非参数几何约束来修正候选区域,选择最佳目标对象和局部区域。最后提取语义局部区域特征进行姿势归一化表示,然后训练最终细粒度分类的分类器。

图6 Part-bases R-CNN流程图
为了使CNN生成的深度特征对细粒度的鸟类分类任务更具区分性,首先使用在ImageNet上预训练的CNN模型对从原始CUB图像的真实边界框中裁剪出的图像进行输出为200路的鸟类分类任务。对象边界框标注信息和一组语义上的局部区域标注用于训练多个检测器。最初所有的对象及其每个局部区域被视为独立的对象类别:从候选区域中提取的卷积特征描述符用来训练一对多的线性SVM分类器。由于单个的局部区域检测器存在缺陷,尤其是在存在遮挡时缺陷更为明显。为了过滤掉不准确的检测器,Zhang等提出了一个基于对象的相对位置的几何约束,使得检测器的准确率大大提高。
在测试中,自下而上产生的候选区域由所有检测器进行评分,并且施加非参数的几何约束以重新调整窗口,并选择最佳的对象和局部区域检测器。最后一步是使用针对特定的对象或局部区域的微调模型来提取和连接预测的整个对象或局部区域的特征。然后,使用最终的特征表示来训练一对多的线性SVM分类器完成预测。
3.2.2 挑选深度过滤器响应(Picking deep filter responses)
为了实现细粒度的图像识别,大多数算法在训练和测试时都需要对象或者局部区域标注信息,这些标注等于是告诉了网络需要从哪里寻找识别的突破口。有一些工作在测试时不额外使用标注,但是在训练阶段还是需要大量的带标注的图像,并且在大尺度的图像识别时显得很吃力。近几年越来越多工作开始尝试构建完全不使用标注的识别网络,这样大大地提高了算法的实用性。
Zhang[29] 等提出的挑选深度过滤器响应(Picking deep filter responses,以下简称PDFS)方法构建了一种新颖的自动局部区域检测方法。图7是PDFR方法的框架结构图。首先,作者提出了一种新颖的检测学习初始化方法:先用原始的selective search方法提取一些候选区域,将它们送入VGG-M[16] 网络,查看第四个卷积层的输出。结果发现有些通道对一些特定图案相应,而有些响应十分混乱,对分类任务没有帮助。因此Zhang等提出精巧地选择响应显著且一致的深层过滤器作为初始的检测器:通过对所有通道上的响应进行排序并选择最高的10k个响应,然后它们被分到各自响应最多的通道上。Zhang等人发现大多数的响应集中在少数几个通道上,认为这些通道就是挑选出的具有区分性的过滤器,它们对特定的模式有响应。
接下来Zhang等人使用这些初始的正样本迭代地学习一个线性SVM分类器:通过迭代地进行新的正样本的挖掘和正则化局部区域模型,学习一系列的检测器,其中每步都使用交叉验证以防止过拟合。另外为了避免检测器过拟合于少数几个正样本,作者引入了正则化损失项。随着迭代过程的进行,正样本越来越趋向于持久化,反过来促进了局部区域模型的区分能力。
经过以上步骤得到的训练过的检测器,已经能很好地从每张图片生成的上千个候选区域中找出相应的具有区分性的局部区域了。之前的一些工作的方法是直接从这些局部区域中提取CNN的倒数第二个全连接层的特征并组合它们用于最终的预测结果。但这样做有两个限制,首先是由于CNN需要固定的输入图像大小,因此不可避免地会引入杂乱的背景;第二是会由于局部区域检测器的可能的不准确性而损失基于局部区域表示的关键信息。因此,zhang等采用了新的适用于细粒度图像识别的特征提取方法。传统的特征表达都使用CNN来实现不可避免地包含了大量背景信息,且一些姿势变化和局部区域的重叠都会影响到检测和识别效果。为了解决这个问题,zhang等将深层过滤器的响应视为用于定位的描述符,将其通过SWFV-CNN(Spatially Weighted Fisher Vector CNN)编码。通过SWFV-CNN,对识别很重要的部分会被强调,这样就可以实现让网络有条件地选择那些需要的描述符。

图7 Picking Deep Filter Responses(PDFR)方法的框架图
3.2.3 多注意力CNN(Multi-attention CNN)
目前的细粒度分类方法主要解决的是寻找具有区分的局部区域和精细的特征学习,但是它们都忽视了局部定位和特征学习之间的相互关系。因此Zheng[30] 等提出了一个新的局部区域学习方法,使用多注意力卷积神经网络学习来产生局部区域并进行特征学习,这样使二者都相互得到加强,作者称为Multi-attention CNN (简称MA-CNN)模型。
图8是MA-CNN的框架图。该模型将网络分为卷积层、通道分组和局部区域分类子网络三个部分。给定一张图片X,首先使用预训练过的卷积神经网络提取基于区域的深度特征。这些深度特征用W*X 表示,其中 * 表示一系列的操作,包括卷积、池化和激活函数,W表示所有的参数。则特征表示的维度为 w*h*c ,其中w,h,c 分别代表特征图的宽、高和特征通道数。尽管一个卷积特征通道能对一种特定的视觉模式产生响应,但仅仅通过一个通道来表达丰富的局部区域信息是不够的。因此,作者提出了一种通道分组和权重子网络,用来从通道组中聚类空间上相关的微小模式作为紧凑的和具有区分性的局部区域,这些通道组的峰值响应出现在相邻的位置。

图8 多注意力CNN模型(MA-CNN)框架
针对上述的局部区域的选择和通道分组,作者提出了两个约束,即两个损失函数:局部区域分类损失函数和通道分组损失函数。将目标函数看做一个多目标优化问题,输入图片X的损失函数定义为:
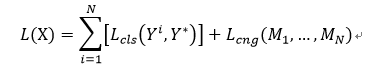
其中Lcls和Lcng分别表示每个局部区域分类损失和通道分组损失。Yi表示使用基于局部区域的特征得到的预测标签向量,Y*为真实的标签向量。通过softmax函数拟合类别标签来进行训练。
为了使局部区域定位和特征学习这两个过程在训练中能相互增强,作者采用了一种交替的训练方式,首先固定卷积层的参数来优化通道分组层使局部区域的寻找结果达到收敛,然后固定通道分组层,转而优化卷积层和softmax层以进行细粒度分类特征学习。这两个学习过程迭代进行,直到这两个损失函数不再变化。
3.3 基于多个网络的集合的方法
将细粒度数据库划分为多个视觉上相似的子集或直接使用多个神经网络来提高分类性能是在许多基于深度学习的细粒度图像分类系统中另一种广泛使用的方法。我们将在本小节中介绍这些方法。
3.3.1 子集特征学习网络(Subset feature learning networks)
如图9所示,子集特征学习网络[31] 由两个主要部分组成:域通用卷积神经网络和几个特定的卷积神经网络。域通用卷积神经网络首先在与目标数据集相同的域的大规模数据集上进行预训练,然后在目标数据集上进行微调。使用具有线性判别分析(LDA)的fc6特征来降低其维度,视觉上相似的物种被聚类成K个子集以在第二部分中训练多个特定的CNN。
针对K个预聚类子集中的每一个学习单独的CNN以学习每个子集的特征,这些特征可以更容易地区分视觉上相似的物种。每个单独CNN的fc6特征用作每个子集学习到的子集特征。每个特定的卷积神经网络适用于一个子图像集。因此,如何为一幅图像选择最佳的特定卷积神经网络是子集特征学习网络的核心问题。
子集选择器CNN(SCNN)用于选择相关度最高的CNN以对给定图像进行预测。使用来自预聚类的输出作为类标签,通过改变softmax层即fc8层使其具有K个输出来训练SCNN。softmax层预测测试图像属于特定子集的概率,然后将最大投票法应用于该预测过程以选择该图像最可能属于的子集。与之前的CNN的训练方法一样,采用AlexNet网络,SCNN的权重通过反向传播和随机梯度下降法(SGD)进行训练。

图9 子集特征学习网络框架
3.3.2 多粒度CNN(Multiple granularity CNN)
有一种观点是,子类别的标签带有隐含的标签层次结构[32] ,每个层次的标签对应于它本体中的级别。 例如,melanerpes formicivorus,也称为橡子啄木鸟,它的种级别的标签为melanerpes,科级别的标签为picidae。从这些标签中很容易提取相应的具有区分性的区域块和特征。这些标签可用于训练一系列基于CNN的分类器,每个分类器专门用于一个粒度级别的分类。 这些网络的内部表示具有不同的感兴趣区域,允许构建多粒度的描述符,其编码覆盖所有粒度级别的信息性和判别性的特征。
基于这种思想,Wang等人提出多粒度CNN[32] ,该方法包含一组并行的深度卷积神经网络,如图10所示,每个都被优化以按给定的粒度进行分类。换句话说,多粒度CNN由一组单粒度描述符组成。隐藏层中的显著性指导从自下而上产生的候选图像块的公共池中选择感兴趣区域(ROI)。因此,ROI的选择依赖于粒度,在某种意义上,所选择的图像块是给定粒度的相关联的分类器分类的结果。同时,ROI的选择也是交叉粒度依赖的:更细粒度的ROI通常从较粗粒度的ROI中采样得到。最后,将每个粒度的ROI传送到框架的第二阶段以提取每个粒度的描述符,然后将其合并以给出最终的分类结果。

图10 多粒度CNN模型的框架
3.3.3 双线性CNN(Bilinear CNN)
双线性模型[33] 是一种双流体系结构,其由两个特征提取器组成,输出在图像的每个位置使用外积相乘并合并以获得图像描述符。如图11所示,该体系结构可以以平移不变的方式对局部成对的特征相互作用进行建模,这对于细粒度分类特别有用。

图11 双线性CNN模型的网络结构图


(这段公式太多了,我就从word截图了,哈哈,手打字太累了)
特征函数 f 的一种自然的选择方案是使用由卷积和池化层组成的CNN。在论文中,作者使用在ImageNet数据集上预先训练的CNN,这些CNN在包含非线性的卷积层处截断,作为特征提取器。通过预训练,当特定领域的数据不足时,双线性网络模型将从另外的的训练数据中受益。这已经被证明对于从物体检测,纹理识别到细粒度分类等许多识别任务都是有益的。仅使用卷积层的另一个优点是所得到的CNN可以在单个前向传播步骤中处理任意大小的图像,并产生有图像和特征通道中的位置索引的输出。
3.4 基于视觉注意力的方法
人类视觉系统最奇特的一个方面就是注意力的存在。视觉注意力系统并不是将整个图像压缩成静态表示,而是允许突出的特征根据需要动态地出现在最前面。当图像中的内容比较杂乱时,这一点尤其重要。因此视觉注意机制也被用在许多细粒度图像分类系统中。
3.4.1 两级注意力(Two-level attention)模型
图12所示的两级注意模型[34] 融合了三种类型的注意力:产生候选区域块的自底向上的注意力,选择与对象相关的区域块的自顶向下的对象级注意力,以及用于定位具有区分性的部分的局部区域级别的自顶向下的注意力。这些注意力类型被组合以训练特定域的深度神经网络,然后用于查找前景对象或对象以及局部区域,以提取具有区分性的特征。

图12 两级注意力模型的框架
首先,使用在1000类的ILSVRC2012数据集上预训练过的CNN作为FilterNet,从自底向上产生的大量图片块中挑选出分类对象相关的图片,然后使用FilterNet选择的图像块来训练DomainNet,取测试图片的图像块在softmax输出的得分的平均值作为对象级的分类结果。在局部区域级别上,由于DomainNet的中间隐藏层呈现聚类的模式,因此,Xiao等在相似性矩阵S上执行谱聚类以将中间层中的滤波器划分为k个簇,相似矩阵由两个中间层滤波器的余弦相似度S(i , j)组成。每个簇充当局部区域检测器。然后通过局部区域检测器选择的图片块被缩放到DomainNet的输入大小以产生激活,不同局部区域和原始图像的激活整合到一起用于训练SVM,作为基于局部区域的分类器。最后,结合两级注意力的各自优点,合并对象级注意力和局部区域注意力的预测结果,作为最终的预测结果。该模型更易于使用,因为它不需要额外的对象边界框或局部区域标注信息。
3.4.2 全卷积网络注意力模型(FCN attention model)
FCN注意力[35] 是一种基于强化学习的全卷积注意力定位网络,用于自适应地选择多个任务驱动的视觉注意区域。与之前基于强化学习的模型[36, 37, 38] 相比,由于其全卷积的体系结构,所提出的方法在训练和测试期间的计算效率明显更高,并且能够同时聚焦多个视觉注意力区域。
图13是全卷积注意力定位网络的架构。它可以使用注意机制定位多个对象局部区域。不同的局部区域可以具有不同的预定义尺寸。该网络包含两个组件:局部区域定位组件和分类组件。
局部区域定位组件使用全卷积神经网络来定位局部区域的位置。对于给定的输入图像,使用在ImageNet数据集[14] 上预训练的VGG-16模型[16] 来提取基础卷积特征图,并在目标细粒度数据集上进行微调。注意力定位网络通过使用基础卷积特征图生成每个局部区域的得分图来定位多个局部区域。使用两个堆叠的卷积层和一个空间softmax层来生成每个得分图。第一个卷积层使用64个3×3卷积核,第二个卷积层使用一个3×3卷积核来输出单通道的置信度图。将空间softmax层应用于置信度图以将置信度得分转换为概率。选择概率最高的注意力区域作为局部区域位置。对具有固定时间步的多个局部区域位置使用相同的处理过程。每个时间步都生成特定部件的位置。
分类组件包含每个局部区域以及整张图像各自对应的一个深度卷积神经网络分类器。不同的局部区域可能大小不同,根据其尺寸在每个局部区域位置裁剪一个局部图像区域。分别训练每个局部图像区域的图像分类器以及整张图像的图像分类器。最终的分类结果是每个单独的分类器的分类结果的平均值。 为了区分细微的视觉差异,将每个局部图像区域调整为高分辨率。针对每个局部区域训练深度卷积神经网络以分别进行分类。

图13 FCN注意力模型框架
3.4.3 对象-局部区域注意力模型(Object-part attention models)
过去常用的生成对象和局部区域的算法为selective search[28] ,但它的召回率高,精准度低。细粒度图像识别中的寻找对象和局部区域可以视为一个两级注意力模型[34] 。大多数算法在训练寻找对象和局部区域的网络时都依赖于对象级注意力和局部区域标注等额外信息,此为第一个限制。虽然现在有很多人开始不用标注信息来训练这些网络,但这些方法破坏了对象和局部之间的关联性,这就导致了生成的局部区域包含大量背景,且局部区域之间互相重叠严重,此为第二个限制。针对上面两个限制,Peng等人[39] 提出了OPAM(Object-part attention models)模型。

图14 Object-part attention model(OPAM)模型框架图
图12是该OPAM模型的框架图。Peng等也使用了两级注意力,在对象级注意力使用在ImageNet 1k上预训练过的网络——称为FilterNet,来筛选从selective search[28] 中产生的噪声候选区域,留下对象相关的候选区域,然后将它们用来重新训练一个称为ClassNet 的CNN网络,可用于细粒度分类。采用使用CAM[40] 方法,对CNN的神经元提取显著性图来获取图片中的对象的定位。然后对定位了的图片训练一个ObjectNet网络,作为对象级预测结果。
在局部区域注意力上包含两个部分:对象-局部区域空间约束模型和局部区域对齐。对象-局部区域空间约束模型分为两个部分,一个是对象空间约束,用来使选择的局部区域位于对象区域中;另一个是局部区域空间约束,使选择的局部区域之间的重复性降低,减少冗余,增加局部区域之间的区分性。局部对齐的目的是让相同语义的局部区域在一起。由于在ClassNet的中间层存在聚类的模式[41] ,因此作者对ClassNet的卷积层倒数第二层的神经元使用谱聚类的方法,将局部区域都经过这些局部区域簇得到激活值,计算各个簇的得分,然后把局部区域归到得分高的那一类。并使用它们训练一个PartNet,也是一个细粒度分类器。
最终的结果是将图片在这三个分类器:ClassNet,ObjectNet,PartNet的得分各取一个权重相加得到最终得分,作为最终预测结果。
4 性能比较和分析
表1我们列出了以上提到的各类深度学习算法在数据库CUB200-2011[2] 上的分类准确率。分类准确率定义为所有类别分类准确度的平均值。CUB200-2011数据库包含11778张来自200种不同鸟类的图片,提供丰富的类别标签(Image-level labels)、对象边界框(Bounding boxes)、属性标注(Attribute annotations)以及局部区域标记(Part landmarks)。其中5994张图片用于训练,5794张用于测试。由于大部分的细粒度分类方法都在这个数据库上做了实验。因此采用算法在该数据集上的表现来粗略评估这些算法的性能好坏。可以看到,部分算法在分类时采用了边界框和局部区域标注等信息,但大部分的算法仅仅依靠类别标签进行分类预测。弱监督的学习算法减轻了人工标注的成本,增加了算法实用性,是该领域算法研究的重要趋势。
我们将这些细粒度图像分类算法分为三类,分别是基于局部区域定位与对齐的方法,基于多个网络集合的方法和基于视觉注意力的方法。总体上来看,基于局部区域定位与对齐的算法在细粒度分类上占据优势,这种趋势是具有很好的解释性的。细粒度分类与普通的图像分类的最大差异就是图像间的差异隐藏在微小的局部区域。在普通的图像分类上占据优势的网络模型,在细粒度分类上的分类效果可能并不理想。因此,以普通分类模型为基础,在模型的设计、候选区域与特征的选择、以及针对不同局部区域训练不同的分类器,这几个方面着重进行改进与创新,都取得了很不错的效果。尤其值得注意的是,局部区域的定位与检测方案,是整个方法的核心。这些方法一般遵循这样的流程:首先使用selective search方法从一张图片中产生大量的候选区域,这种方法产生的候选区域准确率低,召回率高,存在很多噪声。因此一般先用在预训练好的卷积神经网络模型进行一次筛选。之后将在筛选后的图片区域中进行局部区域的定位与检测,找出具有区分性的局部区域,将这些局部区域分成几个部分分别进行分类训练,得到各个局部区域的分类器,最后的预测将综合考虑所有这些具有区分性的局部区域的预测结果.
基于视觉注意力的算法模拟了人类观察世界的过程,人类观察物体时,一般是先观察整体,仔细再观察某个局部区域,或者开始时就观察局部区域,以进行物体分类。该类算法也取得了不错的效果并不断有新的注意力算法提出。不过算法的分类性能的提升并不算高,如果在模型的设计上有更大的创新,将来或许能取得较大的突破。而基于多个网络集合的方法目前来看处于弱势,与上面的一些算法采用多个分类器模型对局部区域分类的原理不同,该类算法所采用的多个神经网络模型一般各司其职,具有不同的功能,协调配合,才能完成整个分类过程。
值得一提的是,已经开始有算法借助于强化学习技术来进行细粒度的图像分类。初始的分类结果并不满意,通过对分类的结果进行反馈给模型用于模型的改进,不断进行这个过程最后得到稳定的预测。目前来说强化学习在细粒度分类领域的应用还处于初始阶段。我们期待强化学习技术更好地应用于细粒度的图像分类从而产生新的突破。
表1 基于深度特征学习的细粒度图像分类算法在数据库CUB200-2011上的性能比较
| 算法 | CNN模型 | 训练时使用标注信息 | 测试时使用标注信息 | 准确率(%) |
| Part-based R-CNN | AlexNet | BBox+Parts | - | 73.5 |
| Part-based R-CNN | AlexNet | BBox+Parts | BBox+Parts | 76.37 |
| Multiple granularity CNN | VGGNet | BBox | - | 83.0 |
| FCN attention | GoogLeNet | BBox | - | 84.3 |
| Bilinear CNN | VGGNet | BBox | BBox | 85.1 |
| Subset FL | AlexNet | - | - | 77.5 |
| Two-level attemtion | AlexNet | - | - | 77.9 |
| Multiple granularity CNN | VGGNet | - | - | 81.7 |
| FCN attention | GoogLeNet | - | - | 82.0 |
| Bilinear CNN | VGGNet | - | - | 84.1 |
| PDFR | VGGNet | - | - | 84.54 |
| OPAM | VGGNet | - | - | 85.83 |
| MA-CNN | VGGNet | - | - | 86.5 |
5 结论
深度学习的迅速发展使得细粒度的图像分类技术成为了研究热门。本文对近几年基于深度特征学习的一些细粒度图像分类方法进行了分析。相比早期的人工设计特征,基于深度学习模型得到的特征具有更强的表达性,因此能达到更好的分类效果。文章将基于深度特征学习的方法分为了四类,并针对每一种类型方法都给出了具有代表性的几个细粒度分类方法。这些方法大部分是以弱监督的方式进行训练学习,这也反映了细粒度图像分类的发展趋势。弱监督的学习方式不依赖于额外的标注信息而仅使图像的类别标签,从而避免了繁重的人工标注操作,因此这些弱监督的方法更加具有实用意义。
参考文献(References)
- LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436−444
- Wah C, Branson S, Welinder P, Perona P, Belongie S. The Caltech-UCSD Birds-200-2011 Dataset, Technical Report CNS-TR-2011-001, California Institute of Technology, Pasadena, CA, USA, 2011
- Khosla A, Jayadevaprakash N, Yao B P, Li F F. Novel dataset for fine-grained image categorization. In: Proceedings of the 1st Workshop on Fine-Grained Visual Categorization (FGVC), IEEE Conference on Computer Vision and Pattern Recognit-ion (CVPR). Springs, USA: IEEE, 2011
- Krause J, Stark M, Deng J, Li F F. 3D object representations for fine-grained categorization. In: Proceedings of the 2013 IE-EE International Conference on Computer Vision Workshops (ICCVW). Sydney, Australia: IEEE, 2013. 554−561
- Zhao B, Feng J, Wu X, et al. A survey on deep learning-based fine-grained object classification and semantic segmentatio-n[J]. International Journal of Automation and Computing, 2017, 14(2):119-135
- Maji S, Rahtu E, Kannala J, et al. Fine-grained visual classification of aircraft[J]. HAL - INRIA, 2013
- Lowe D G. Object recognition from local scale-invariant features. In: Proceedings of the 7th IEEE International Conference on Computer Vision. Kerkyra, Greece: IEEE, 1999.1150−1157
- Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Computer Soci-ety Conference on Computer Vision and Pattern Recognition. San Diego, USA: IEEE, 2005. 886−893
- J´ egou H, Douze M, Schmid C, P´ erez P. Aggregating local descriptors into a compact image representation. In: Proceedi-ngs of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 2010.3304-33-11
- Perronnin F, Dance C. Fisher kernels on visual vocabularies for image categorization. In: Proceedings of the 2007 IEEE Co-nference on Computer Vision and Pattern Recognition. Minneapolis, USA: IEEE, 2007. 1−8
- Sánchez J, Perronnin F, Mensink T, Verbeek J. Image classification with the Fisher vector: theory and practice. International Journal of Computer Vision, 2013, 105(3): 222−245
- Nilsback M E, Zisserman A. Automated flower classification over a large number of classes. In: Proceedings of the 6th Indi-an Conference on Computer Vision, Graphics & Image Processing. Bhubaneswar, India: IEEE, 2008. 722−7297
- Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, L. D. Jackel. Backpropagation applied to han-dwritten zip code recognition. Neural Computation, vol.1, no.4, pp.541–551, 1989
- J. Deng, W. Dong, R. Socher, L. J. Li, K. Li, F. F. Li. ImageNet: A large-scale hierarchical image database. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Miami, USA, pp.248–255, 2009
- A. Krizhevsky, I. Sutskever, G. E. Hinton. ImageNet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems 25, NIPS, Lake Tahoe, USA, pp.1097–1105, 2012
- Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. Computer Science, 2014
- C. Szegedy, W. Liu, Y. Q. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich. Going deeper with convolutions. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Boston, USA, pp.1–9, 2014
- A. S. Razavian, H. Azizpour, J. Sullivan, S. Carlsson. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition Workshops, IEEE, Columbus, USA, pp.5-12–519, 2014
- L. X. Xie, R. C. Hong, B. Zhang, Q. Tian. Image classification and retrieval are ONE. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, ACM, New York, USA, pp.3–10, 2015
- L. X. Xie, L. Zheng, J. D. Wang, A. Yuille, Q. Tian. Inter-active: Inter-layer activeness propagation. In Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition, IEEE, Las Vegas, USA, pp.270–279, 2016.
- T. Berg, P. N. Belhumeur. POOF: Part-based one-vs-one features for fine-grained categorization, face verification, and attri-bute estimation. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Portland, USA, p-p.955–962, 2013
- J. X. Liu, A. Kanazawa, D. Jacobs, P. Belhumeur. Dog breed classification using part localization. In Proceedings of the 12-th European Conference on Computer Vision, Springer, Florence, Italy, vol.7572, pp.172–185, 2012
- S. L. Yang, L. F. Bo, J.Wang, L. G. Shapiro. Unsupervised template learning for fine-grained object recognition. Advances in Neural Information Processing Systems 25, NIPS, Lake Tahoe, USA, pp.3122–3130, 2012
- E. Gavves, B. Fernando, C. G. M. Snoek, A. W. M. Smeulders, T. Tuytelaars. Fine-grained categorization by alignments. In Proceedings of IEEE International Conference on Computer Vision, IEEE, Sydney, Australia, pp.1713–1720, 2013
- Y. N. Chai, V. Lempitsky, A. Zisserman. BiCoS: A Bi-level co-segmentation method for image classification. In Proceedin-gs of IEEE International Conference on Computer Vision, IEEE, Barcelona, Spain, pp.2579–2586, 2011
- N. Zhang, J. Donahue, R. Girshick, T. Darrell. Part-based R-CNNs for fine-grained category detection. In Proceedings of th-e 13th European Conference on Computer Vision, Springer, Zurich, Switzerland, vol.8689, pp.834–849, 2014
- R. Girshick, J. Donahue, T. Darrell, J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentati-on. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Columbus, USA, pp.580–587, 2014
- J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, A. W. M. Smeulders. Selective search for object recognition. Internatio-nal Journal of Computer Vision, vol.104, no.2, pp.154–171, 2013
- Zhang X, Xiong H, Zhou W, et al. Picking deep filter responses for fine-grained image recognition[C]// IEEE Conferen-ce on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016:1134-1142
- H. Zheng, J. Fu, T. Mei and J. Luo. Learning multi-attention convolutional neural network for fine-grained image recog-nition. 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2018, pp. 5219-5227
- Z. Y. Ge, C. McCool, C. Sanderson, P. Corke. Subset feature learning for fine-grained category classification. In Proceedin-gs of IEEE Conference on Computer Vision and Pattern Recognition Workshops, IEEE, Boston, USA, pp.46–52, 2015
- Wang D, Shen Z, Shao J, et al. Multiple granularity descriptors for fine-grained categorization[C]// IEEE International C-onference on Computer Vision. IEEE Computer Society, 2015:2399-2406
- T. Y. Lin, A. RoyChowdhury, S. Maji. Bilinear CNN models for fine-grained visual recognition. In Proceedings of IEEE In-ternational Conference on Computer Vision, IEEE, Santiago, Chile, pp.1449–1457, 2015
- T. J. Xiao, Y. C. Xu, K. Y. Yang, J. X. Zhang, Y. X. Peng, Z. Zhang. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Boston, USA, pp.842–850, 2015
- X. Liu, T. Xia, J. Wang, Y. Q. Lin. Fully convolutional attention localization networks: Efficient attention localization for f-ine-grained recognition. arXiv:1603.06765, 2016
- Sermanet P, Frome A, Real E. Attention for fine-grained categorization[J]. Computer Science, 2015, 10(1):224-30
- Ba J, Mnih V, Kavukcuoglu K. Multiple object recognition with visual attention[J]. Computer Science, 2014
- V. Mnih, N. Heess, A. Graves, K. kavukcuoglu. Recurrent models of visual attention. Advances in Neural Information Proc-essing Systems 27, Montr´ eal, Canada, pp.2204–2212, 2014
- Peng Y, He X, Zhao J. Object-part attention model for fine-grained image classification[J]. IEEE Transactions on Image Processing, 2017, PP(99):1-1
- Zhou B, Khosla A, Lapedriza A, et al. Learning deep features for discriminative localization[C]// IEEE Conference on C-omputer Vision and Pattern Recognition. IEEE Computer Society, 2016:2921-2929
- Nadler B, Coifman R R, Kevrekidis I G. Diffusion Maps, spectral clustering and eigenfunctions of Fokker-Planck operators [C]// International Conference on Neural Information Processing Systems. MIT Press, 2005:955-962

