
- 1docker-compose redis_docker-compose redis
- 2MYSQL中的14个神仙功能
- 3PyTorch学习之:深入理解神经网络
- 4win11病毒和防护功能显示‘页面不可用’的解决方法_windows defender页面不可用
- 5LeetCode-994. 腐烂的橘子【广度优先搜索 数组 矩阵】
- 6365天深度学习训练营-第T6周:好莱坞明星识别_label_mode='categorical
- 7openstack运维_查看openstack各个模块服务状态nova-conductor重启不了
- 8【Flutter从入门到实战】 ⑥、Flutter的StatefulWidget的生命周期didUpdateWidget调用机制、基础的Widget-普通文本Text、富文本Rich、按钮、图片的使用_flutter didupdatewidget
- 9决策树之C4.5(详细版终结版)_决策树c4.5代码实现
- 10SpringBoot+消息队列RocketMQ(基于阿里云)_aliyun.openservices onsmessagetrace
40 深度学习(四):卷积神经网络|深度可分离卷积|colab和kaggle的基础使用_kaggle卷积
赞
踩
卷积神经网络
卷积神经网络的基本结构 1:
(卷积层+(可选)池化层) * N+全连接层 * M(N>=1,M>=0)
卷积层的输入和输出都是矩阵,全连接层的输入和输出都是向量,在最后一层的卷积上,把它做一个展平,这样就可以和全连接层进行运算了,为什么卷积要放到前面,因为展平丧失了维度信息,因此全连接层后面不能再放卷积层。
卷积神经网络的基本结构 2:
(卷积层+(可选)池化层)N+反卷积层K
反卷积层用来放大,可以让输出和输入一样大,当输出和输入一样大时,适用场景是物体分割(因为我们就是要确定这个点属于哪一个物体)。
为什么要卷积
一般从两个角度进行回答这个问题:
- 参数过多内存装不下,比如说:图像大小 10001000 一层神经元数目为 10^6
,而如果采用全连接的话,全连接参数为 10001000*10^ 6=10^12, 一层就是 1 万亿个参数,内存是装不下这么多参数的。 - 参数过多容易过拟合,计算资源不足与容易过拟合,发生过拟合,我们就需要更多训练数据,但是很多时候我们没有更多的数据,因为获取数据需要成本。
而卷积通过使用参数共享的方法进行解决这种相关的问题。
主要的理论支持:
- 局部连接:图像的区域性—爱因斯坦的嘴唇附近的色彩等是相似的
- 参数共享与平移不变性:图像特征与位置无关—左边是脸,右边也是脸,这样无论脸放在什么地方都检查出来,刚好可以解决过拟合的问题(否则脸放到其他地方就检测不出来)
可参考链接
卷积的具体流程
这边由于在之前的博客也已经介绍过了,这边就不再介绍,但是会进行相关的参数介绍,到后面的代码当中需要我们去计算相关的层数 以及 相关的shape和参数的数目,到时候会体会的更深。
参数计算流程:链接
这边搬运一下计算公式:
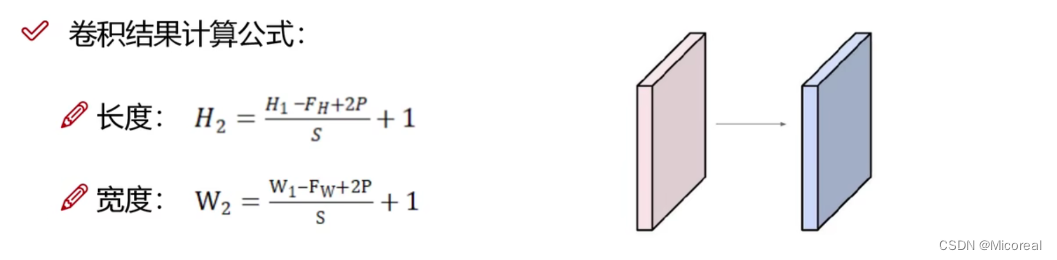
这个只是长宽,这边给出计算例子,如果有不太清楚的人,到时候可以可移步到代码部分进行学习:
格式:(B,H,W,C)
输入:(B,H,W,C)
kennel-size(3,3) stride=(1,1) padding=0 filter=32
输出:(B,((H-3+0)//1)+1,((W-3+0)//1)+1,filter)
参数的数目:kennel-size*通道*filter(个数)+ 偏置 = 3*3*C*32 + 32
- 1
- 2
- 3
- 4
- 5
- 6
卷积和池化的流程:链接
池化
卷积和池化的流程:链接
池化: 池化函数使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。本质是降采样,可以大幅减少网络的参数量。
池化技术的本质:在尽可能保留图片空间信息的前提下,降低图片的尺寸,增大卷积核感受视野,提取高层特征,同时减少网络参数量,预防过拟合。简单来说:等比例缩小图片,图片的主体内容丢失不多,依然具有平移,旋转,尺度的不变性,简单来说就是图片的主体内容依旧保存着原来大部分的空间信息。
一般池化也分为几种:
最大值池化:能够抑制网络参数误差造成的估计均值偏移的现象。
平均值池化:主要用来抑制邻域值之间差别过大,造成的方差过大。
特点
- 常使用不重叠、不补零
- 没有用于求导的参数
- 池化层参数为步长和池化核大小
- 用于减少图像尺寸,从而减少计算量
- 一定程度平移鲁棒,比如一只猫移动了一个像素的另外一张图片,我们先做池化,再做卷积,那么最终还是可以识别这个猫。
- 损失了空间位置精度
tensorflow代码
import matplotlib as mpl import matplotlib.pyplot as plt %matplotlib inline import numpy as np import sklearn import pandas as pd import os import sys import time import tensorflow as tf from tensorflow import keras from sklearn.preprocessing import StandardScaler import os # 数据准备 # ----------------------------------------------------------------------------- fashion_mnist = keras.datasets.fashion_mnist (x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data() x_valid, x_train = x_train_all[:5000], x_train_all[5000:] y_valid, y_train = y_train_all[:5000], y_train_all[5000:] print(x_valid.shape, y_valid.shape) print(x_train.shape, y_train.shape) print(x_test.shape, y_test.shape) scaler = StandardScaler() # 注意这边和之前的不一样,这边最后面的reshape变成了28,28,1,相比于之前多了个1,符合基础的形状(B,H,W,C) x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1) x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1) x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1) # ----------------------------------------------------------------------------- # 模型准备 # ----------------------------------------------------------------------------- model = keras.models.Sequential() #添加卷积层,filters输出有多少通道,就是有多少卷积核,kernel_size卷积核的大小, # padding是否加上padding,same代表输出和输入大小一样,1代表通道数目是1 model.add(keras.layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='selu', input_shape=(28, 28, 1))) model.add(keras.layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='selu')) #添加池化层,pool_size是窗口大小,步长默认和窗口大小相等 model.add(keras.layers.MaxPool2D(pool_size=2)) #为了缓解损失,所以filters翻倍 model.add(keras.layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='selu')) model.add(keras.layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='selu')) model.add(keras.layers.MaxPool2D(pool_size=2)) model.add(keras.layers.Conv2D(filters=128, kernel_size=3, padding='same', activation='selu')) model.add(keras.layers.Conv2D(filters=128, kernel_size=3, padding='same', activation='selu')) model.add(keras.layers.MaxPool2D(pool_size=2)) model.add(keras.layers.Flatten()) model.add(keras.layers.Dense(128, activation='selu')) model.add(keras.layers.Dense(10, activation="softmax")) model.compile(loss="sparse_categorical_crossentropy", optimizer = "sgd", metrics = ["accuracy"]) model.summary() # -----------------------------------------------------------------------------

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
输出:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 下载过程略 (5000, 28, 28) (5000,) (55000, 28, 28) (55000,) (10000, 28, 28) (10000,) Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 28, 28, 32) 320 conv2d_1 (Conv2D) (None, 28, 28, 32) 9248 max_pooling2d (MaxPooling2 (None, 14, 14, 32) 0 D) conv2d_2 (Conv2D) (None, 14, 14, 64) 18496 conv2d_3 (Conv2D) (None, 14, 14, 64) 36928 max_pooling2d_1 (MaxPoolin (None, 7, 7, 64) 0 g2D) conv2d_4 (Conv2D) (None, 7, 7, 128) 73856 conv2d_5 (Conv2D) (None, 7, 7, 128) 147584 max_pooling2d_2 (MaxPoolin (None, 3, 3, 128) 0 g2D) flatten (Flatten) (None, 1152) 0 dense (Dense) (None, 128) 147584 dense_1 (Dense) (None, 10) 1290 ================================================================= Total params: 435306 (1.66 MB) Trainable params: 435306 (1.66 MB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
需要值得关注的点就是上文所展示的参数的数目,以及相对应的每一层参数的大小,这边虽然不需要我们自己进行填写,但是也需要了解。
然后就是开始训练:
# 存储训练的参数 # ----------------------------------------------------------------------------- logdir = './cnn-selu-callbacks' if not os.path.exists(logdir): os.mkdir(logdir) output_model_file = os.path.join(logdir, "fashion_mnist_model.h5") callbacks = [ keras.callbacks.TensorBoard(logdir), keras.callbacks.ModelCheckpoint(output_model_file,save_best_only = True), keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3), ] history = model.fit(x_train_scaled, y_train, epochs=10, validation_data=(x_valid_scaled, y_valid), callbacks = callbacks) # ----------------------------------------------------------------------------- # 绘图 # ----------------------------------------------------------------------------- def plot_learning_curves(history): pd.DataFrame(history.history).plot(figsize=(8, 5)) plt.grid(True) plt.gca().set_ylim(0, 1) plt.show() plot_learning_curves(history) # ----------------------------------------------------------------------------- # 评估模型 model.evaluate(x_test_scaled, y_test, verbose = 0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
输出:
Epoch 1/10
1719/1719 [==============================] - 23s 7ms/step - loss: 0.4335 - accuracy: 0.8442 - val_loss: 0.3615 - val_accuracy: 0.8728
······
Epoch 10/10
1719/1719 [==============================] - 11s 6ms/step - loss: 0.0748 - accuracy: 0.9746 - val_loss: 0.2589 - val_accuracy: 0.9190
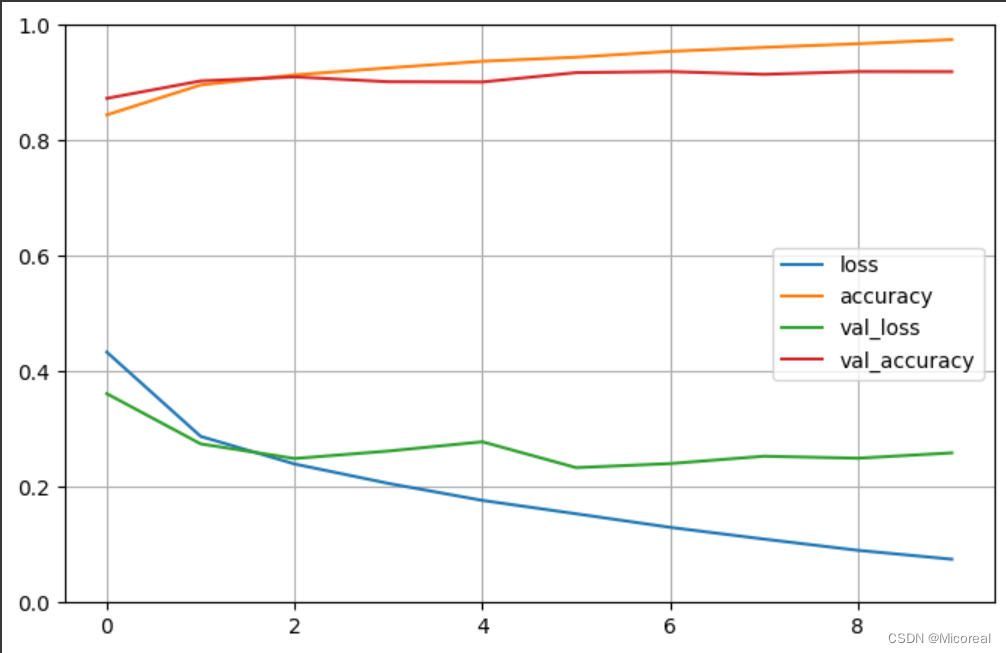
图片见下
[0.2659706473350525, 0.9179999828338623]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
selu相比于relu来说,他的效果更好,但是对于gpu不适合计算ex的函数,所以他的计算来说就会很慢。
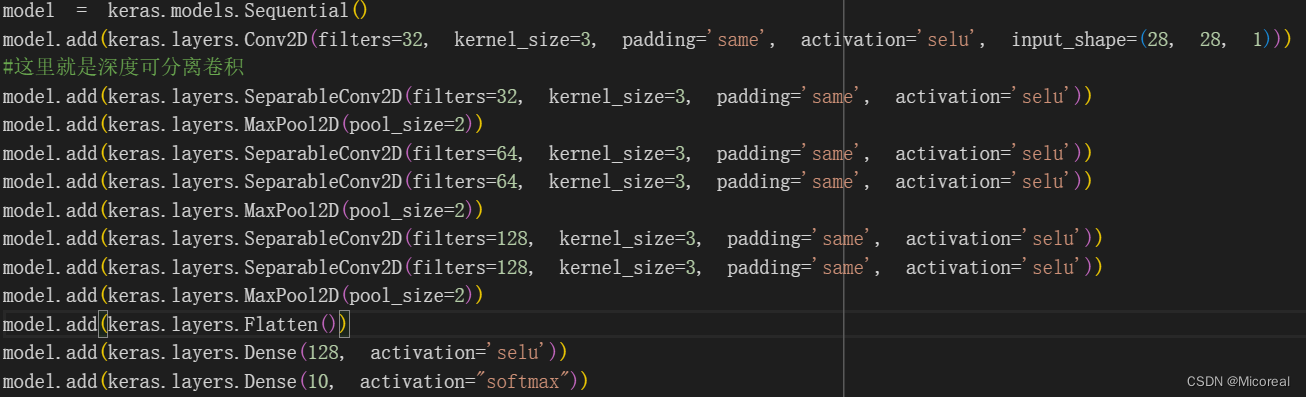
深度可分离卷积
深度可分离卷积是对于卷积的再一次升级,你可以看到其的所需要的参数量更加的小了,这个体会可以放到后面的代码环节进行体会。
原理介绍
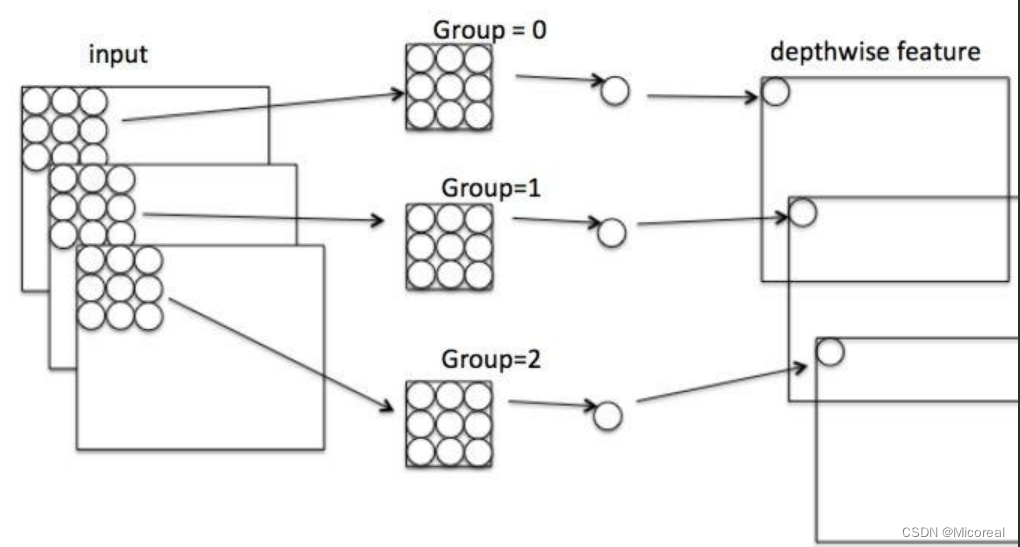
整个流程的过程,先按照图片进行介绍,一共是分为两步:
第一步:考虑的是图片本身的属性,他把图片按照通道进行分开,一层通道用一个kennel-size,然后使用kennel-size对一层一层进行卷积,得到同等通道的图,然后进行下一步。
第二步考虑的是通道的属性,将上一步的输出考虑上通道的属性,按照1 * 1 * C的kennel-size进行卷积,并且搭配上多个filter进行后面的升维计算。
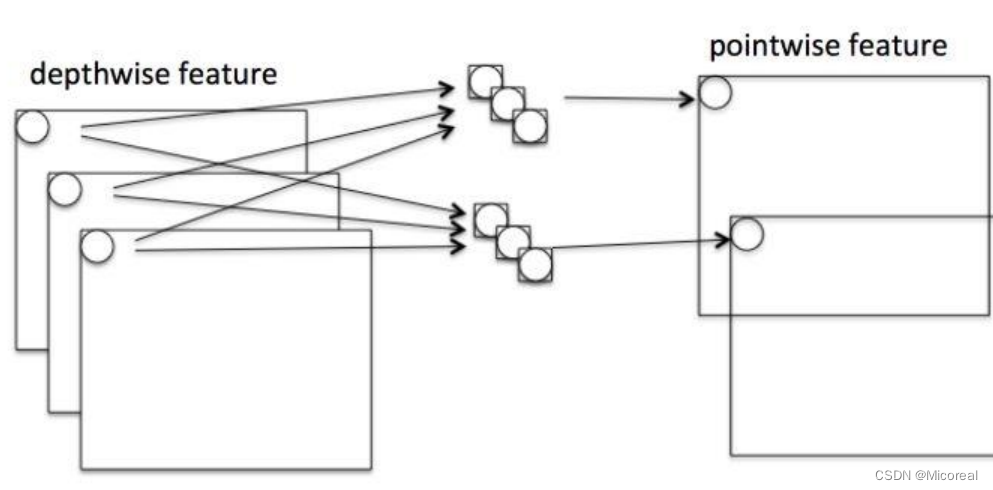
最后得到升维后的特征图片。
计算量对比
首先参数对比一般会先忽略掉偏置项b,因为相比之下偏置项b的量级太小:
对于普通的卷积来说,他的计算量需求:(kennel-size * kennel-size * H的滑动次数 * W的滑动次数 * C * filter)
而对于深度可分离卷积来说,他的计算量由两部分组成:
第一部分深度可分离:(kennel-size * kennel-size * H的滑动次数 * W的滑动次数 * C)
第二部分1 * 1 卷积:(1 * 1 * filter * H的滑动次数 * W的滑动次数)
两部分相加之后计算量会小于卷积,原因就是正常情况下我们的filter取的值是越来越大,甚至十分大的,所以这种的效果会更加好。
而相同的进行参数量对比,相信学习过上面的原理,大家也可以轻易写出相关的比较式子,这边留给大家。
参数量计算后面也会给出计算例子
代码
import matplotlib as mpl import matplotlib.pyplot as plt %matplotlib inline import numpy as np import sklearn import pandas as pd import os import sys import time import tensorflow as tf from tensorflow import keras from sklearn.preprocessing import StandardScaler import os # 数据准备 # ----------------------------------------------------------------------------- fashion_mnist = keras.datasets.fashion_mnist (x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data() x_valid, x_train = x_train_all[:5000], x_train_all[5000:] y_valid, y_train = y_train_all[:5000], y_train_all[5000:] print(x_valid.shape, y_valid.shape) print(x_train.shape, y_train.shape) print(x_test.shape, y_test.shape) scaler = StandardScaler() # 注意这边和之前的不一样,这边最后面的reshape变成了28,28,1,相比于之前多了个1,符合基础的形状(B,H,W,C) x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1) x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1) x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1) # ----------------------------------------------------------------------------- # 模型准备 # ----------------------------------------------------------------------------- model = keras.models.Sequential() model.add(keras.layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='selu', input_shape=(28, 28, 1))) #这里就是深度可分离卷积 model.add(keras.layers.SeparableConv2D(filters=32, kernel_size=3, padding='same', activation='selu')) model.add(keras.layers.MaxPool2D(pool_size=2)) model.add(keras.layers.SeparableConv2D(filters=64, kernel_size=3, padding='same', activation='selu')) model.add(keras.layers.SeparableConv2D(filters=64, kernel_size=3, padding='same', activation='selu')) model.add(keras.layers.MaxPool2D(pool_size=2)) model.add(keras.layers.SeparableConv2D(filters=128, kernel_size=3, padding='same', activation='selu')) model.add(keras.layers.SeparableConv2D(filters=128, kernel_size=3, padding='same', activation='selu')) model.add(keras.layers.MaxPool2D(pool_size=2)) model.add(keras.layers.Flatten()) model.add(keras.layers.Dense(128, activation='selu')) model.add(keras.layers.Dense(10, activation="softmax")) model.compile(loss="sparse_categorical_crossentropy", optimizer = "sgd", metrics = ["accuracy"]) model.summary() # -----------------------------------------------------------------------------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
输出:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 下载过程略 (5000, 28, 28) (5000,) (55000, 28, 28) (55000,) (10000, 28, 28) (10000,) Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 28, 28, 32) 320 separable_conv2d (Separabl (None, 28, 28, 32) 1344 eConv2D) max_pooling2d (MaxPooling2 (None, 14, 14, 32) 0 D) separable_conv2d_1 (Separa (None, 14, 14, 64) 2400 bleConv2D) separable_conv2d_2 (Separa (None, 14, 14, 64) 4736 bleConv2D) max_pooling2d_1 (MaxPoolin (None, 7, 7, 64) 0 g2D) separable_conv2d_3 (Separa (None, 7, 7, 128) 8896 bleConv2D) separable_conv2d_4 (Separa (None, 7, 7, 128) 17664 bleConv2D) max_pooling2d_2 (MaxPoolin (None, 3, 3, 128) 0 g2D) flatten (Flatten) (None, 1152) 0 dense (Dense) (None, 128) 147584 dense_1 (Dense) (None, 10) 1290 ================================================================= Total params: 184234 (719.66 KB) Trainable params: 184234 (719.66 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
然后就是开始训练模型
# 存储训练的参数 和 训练模型 # ----------------------------------------------------------------------------- logdir = './separable-cnn-selu-callbacks' if not os.path.exists(logdir): os.mkdir(logdir) output_model_file = os.path.join(logdir,"fashion_mnist_model.h5") callbacks = [ keras.callbacks.TensorBoard(logdir), keras.callbacks.ModelCheckpoint(output_model_file,save_best_only = True), keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3), ] history = model.fit(x_train_scaled, y_train, epochs=10, validation_data=(x_valid_scaled, y_valid), callbacks = callbacks) # ----------------------------------------------------------------------------- # 绘图 # ----------------------------------------------------------------------------- def plot_learning_curves(history): pd.DataFrame(history.history).plot(figsize=(8, 5)) plt.grid(True) plt.gca().set_ylim(0, 3) plt.show() plot_learning_curves(history) # ----------------------------------------------------------------------------- # 评估模型 # ----------------------------------------------------------------------------- model.evaluate(x_test_scaled, y_test, verbose = 0) # -----------------------------------------------------------------------------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
输出:
Epoch 1/10
1719/1719 [==============================] - 24s 7ms/step - loss: 2.2999 - accuracy: 0.1143 - val_loss: 2.2792 - val_accuracy: 0.0980
······
Epoch 10/10
1719/1719 [==============================] - 11s 6ms/step - loss: 0.4067 - accuracy: 0.8514 - val_loss: 0.3963 - val_accuracy: 0.8584
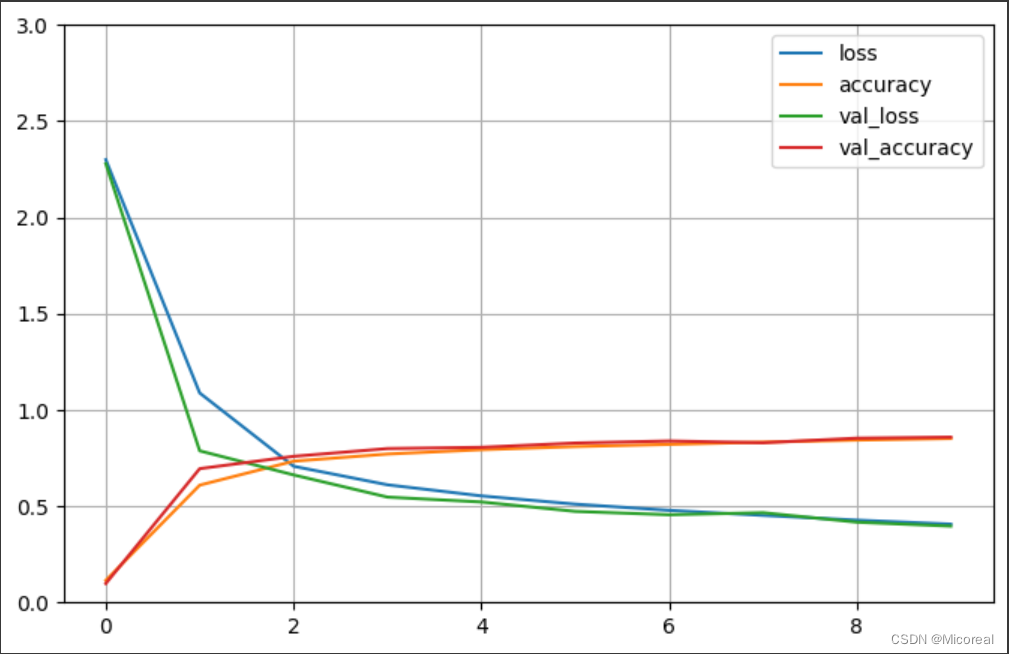
图片见下
[0.4277254343032837, 0.8440999984741211]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
图片:
参数计算例子
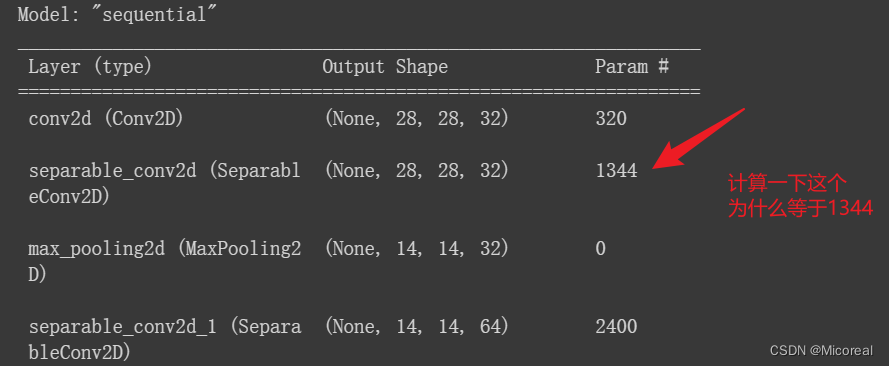
大小计算:
首先对于input(None,28,28,32)来说,经历SeparableConv2D(filters=32, kernel_size=3, padding='same', activation='selu')后得到的大小:
很简单可以理解:(None,28,28,32)第一个None取决于Batch-size,所以是None,第二个28,因为有个same,他自然加上padding,自然就还是28,第三个28同理,第四个32取决于上一个filters,最后自然得到了(None,28,28,32),这还是很简单的。
- 1
- 2
参数数量计算:
第一步深度可分离:
参数数量=kennel-size*kennel-size*C
所以自然就是 3*3*32=288
第二步1*1卷积:
参数数量=1*1*C*filter + b
所以自然就是 32*32+32 = 1056
最后两个相加 = 1344
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
后面可以自行计算一下子。
colab 和 kaggle
colab
首先关于colab的使用实际上和juptyer的使用十分相似,然后打开GPU的地方:
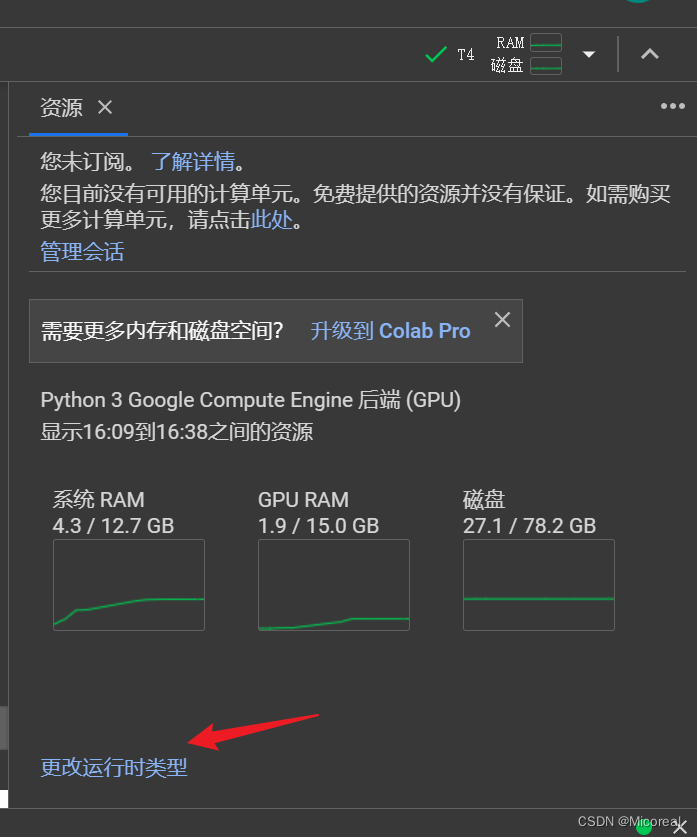
然后自然就有了。
下载文件呢?
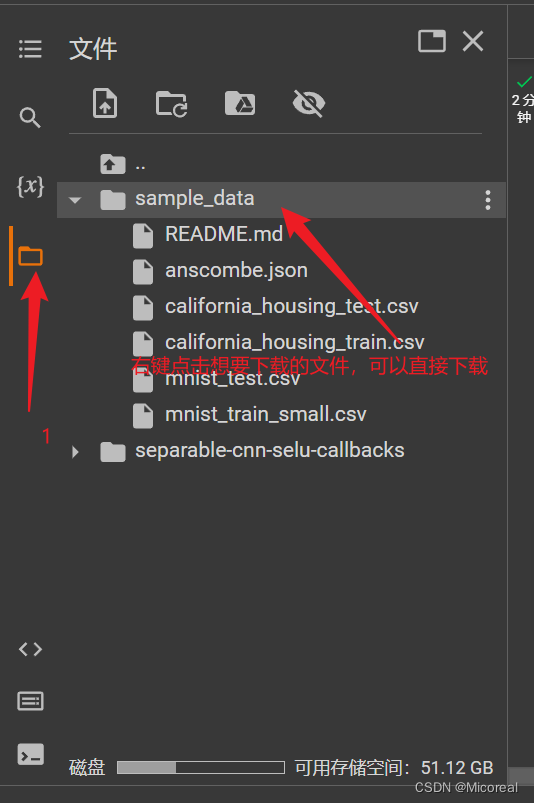
然后工作目录是在content文件夹当中
kaggle
使用gpu的地方
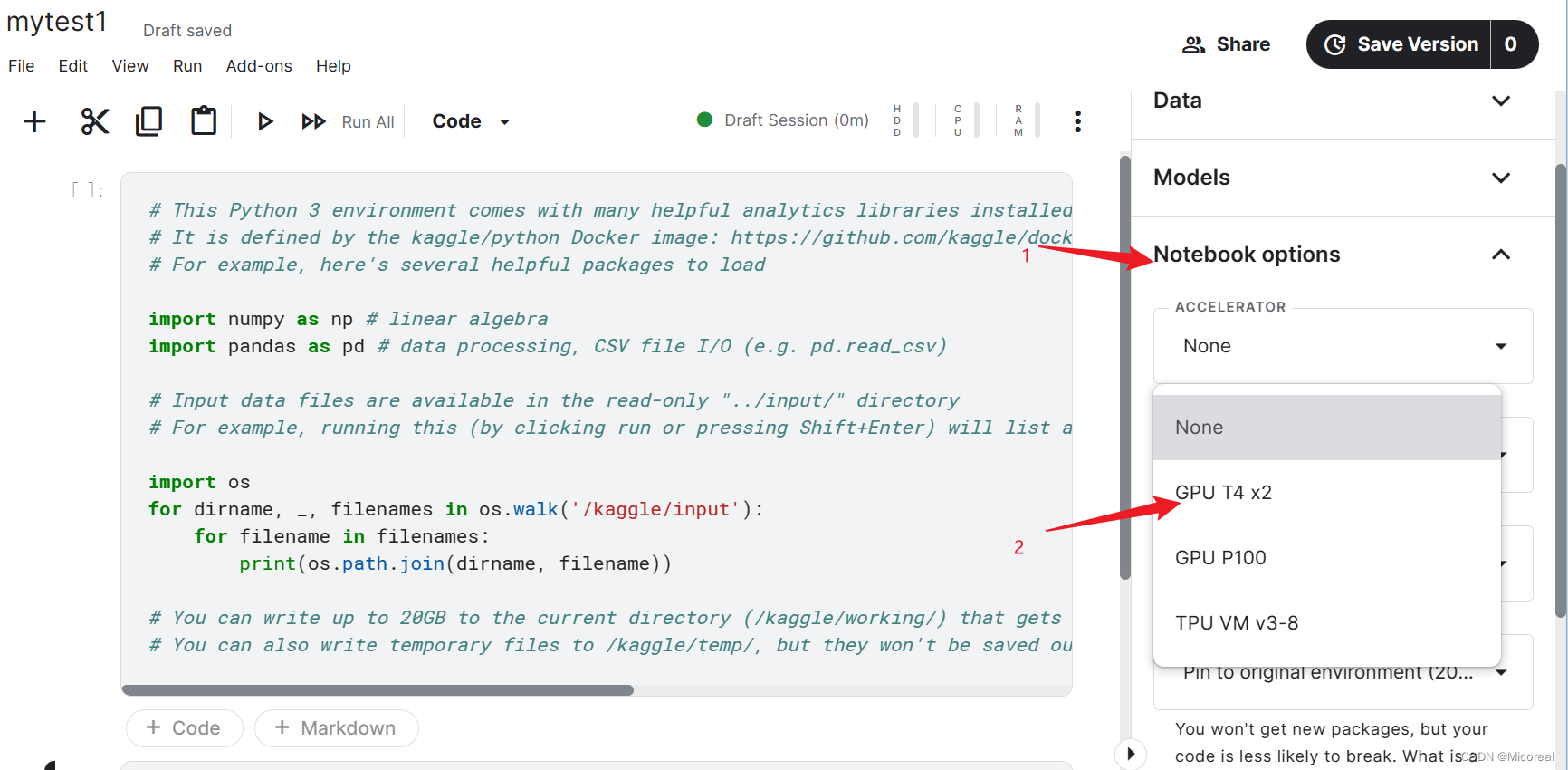
工作目录是再working当中,然后你导入了数据集后,数据集是放在…/input当中
如何在colab上使用kaggle的数据

这个需要记住
然后在colab当中的代码:
先挂载
from google.colab import drive
drive.mount('/content/gdrive/')
- 1
- 2
然后根据提示上传kaggle.json
from google.colab import files
files.upload()
- 1
- 2
第三步就是设置对应的kaggle.json
!pip install -q kaggle
!mkdir -p /content/drive/Kaggle/
!cp kaggle.json /content/drive/Kaggle/
!chmod 600 /content/drive/Kaggle/kaggle.json
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
- 1
- 2
- 3
- 4
- 5
- 6
- 7
检测是否成功:
!kaggle datasets list
- 1
然后比如说我们要下载这个数据集:

!kaggle datasets download -d slothkong/10-monkey-species
- 1
解压:
!unzip -o -d /content /content/10-monkey-species.zip
- 1

