
- 1top block unavailable for requested intra mode
- 2仪表盘,新增快捷筛选器组件
- 3工信部装备司文件首提数字孪生关键技术_数字孪生归哪个司局管
- 4Zynq UltraScale+ XCZU15EG 纯VHDL解码 IMX214 MIPI 视频,2路视频拼接输出,提供vivado工程源码和技术支持
- 5ESP32-CAM网络摄像头系列-01-基于RTSP协议的局域网视频推流/拉流的简单实现_espcam 视频流传输
- 6可变长子网掩码(VLSM)
- 7Android APP漏洞之战——非root环境下的抓包、脱壳、Hook_android漏洞挖掘
- 8开源情报 (OSINT)
- 9UV胶水能够粘接聚苯乙烯PS吗?需要注意哪些事项?又有哪些优势呢?
- 10文本领域的数据预处理技术、深度学习训练技巧以及Debug经验_数据处理文本动态技术
Transformer结构详解_transformer 结构
赞
踩
Transformer结构详解
1.ransformer整体结构
transformer的整体结构,下图是其用于中英文翻译的整体结构。
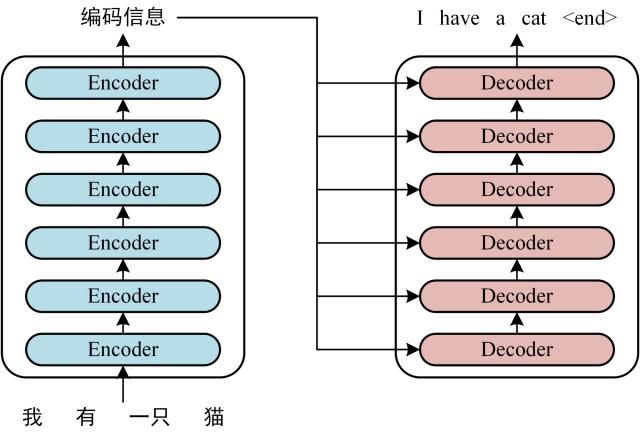
可以看到 Transformer由Encoder和Decoder两个部分组成,Encoder和Decoder都包含6个block。整体的工作流程如下:
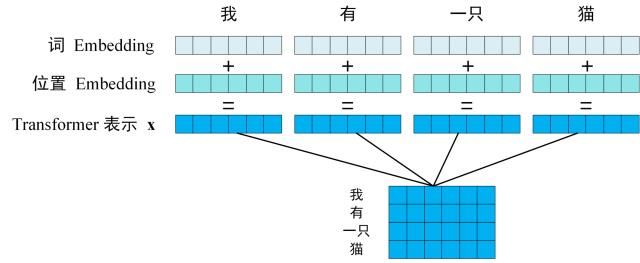
**第一步:**获取输入句子中每一个单词的表示向量 X,X由单词的Embedding(Embedding就是从原始数据提取出来的Feature)和单词卫视的Embedding相加得到。
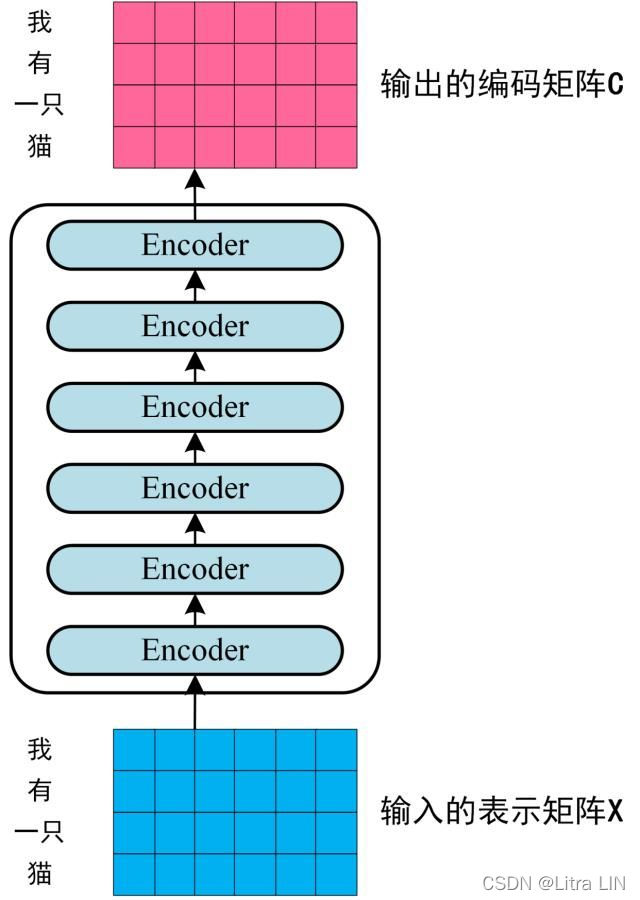
第二步骤: 将得到的单词表示向量矩阵(如上图所示,每一行是一个单词的表示 x)传入Encoder中,经过6个Encoder block后可以得到句子所有单词的编码信息矩阵C,如下图所示,单词向量矩阵用 X n × d X_{n\times d} Xn×d 表示,n是句子中单词个数,d是表示向量的维度(论文中d=512)。每一个Encoder block输出的矩阵维度与输入完全一致。

**第三步:**将Encoder输出的编码信息矩阵C传递到Decoder中,Decoder依次会根据当次翻译过的单词1~i翻译下一个单词i+1,如下图所示,在使用的过程中,翻译到单词i+1的时候需要通过 **Mask(掩盖)**操作遮挡住i+1之后的单词。

上图的Decoder接收了一个Encoder的编码矩阵C,然后首先输入一个翻译开始符’’,预测第一个单词’I’;然后输入翻译开始符’‘和单词’I’,预测单词’have’,以此类推,这是Transformer使用时候的大致流程,接下来是里面各个部分的细节。
2.Transformer的输入
Transformer中单词的输入表示x由单词Embedding和位置Embedding(Poxitional Encoding)相加得到。

2.1单词Embedding
单词的Embedding有很多方式可以获取,例如可以采用Word2Vec、Glove等算法预训练得到,也可以在Transformer中训练得到。
2.2 位置Embedding
Transformer中除了单词的Embedding,还需要使用位置Embedding表示单词出现在句子中的位置。 **因为Transformer不采用RNN的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于NLP来说非常重要。**所以,Transformer中使用位置Embedding保存单词在序列中的相对或绝对位置。
位置Embedding用PE来表示,PE的维度与单词Embedding是一样的,PE可以通过训练得到,也可以使用某种公式计算得到,在Transformer中采用了后者,位置Embedding的计算公式如下:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
1000
0
2
i
d
)
PE(pos,2i)=sin(\frac{pos}{10000^{\frac{2i}{d}}})
PE(pos,2i)=sin(10000d2ipos)
P E ( p o s , 2 i + 1 ) = c o s ( p o s 1000 0 2 i d ) PE(pos,2i+1)=cos(\frac{pos}{10000^{\frac{2i}{d}}}) PE(pos,2i+1)=cos(10000d2ipos)
其中,pos表示单词在句子中的位置,d表示PE的维度(与词Embedding一样),2i表示偶数的维度,2i+1表示奇数维度(即2i≤d, 2i+1≤d)。使用这种公式计算PE有以下的好处:
- 使PE能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子有20个单词,突然来了一个长度为21的句子,则使用公式计算的方法可以计算出第21位的Embedding。
- 可以让模型容易地计算出相对位置,对于固定长度的间距k,PE(pos+k)可以用PE(pos)计算得到。因为sin(A+B) = sin(A)cos(B)+cos(A)sin(B),cos(A+B) = cos(A)cos(B)-sin(A)sin(B)。
将单词的词Embedding和位置Embedding相加,就可以得到单词的表示向量x,x就是Transformer的输入。
3.self-attention(自注意机制)

上图是Transformer的内部结构图,左侧为Encoder block,右侧为Decoder block。红色圈中的部分为Multi-Head Attention。是由多个self-attention组成的,可以看到Encoder block包含一个Multi-Head Attention(其中有一个用到Masked)。Multi-Head Attention上方还包括一个Add & Norm层,Add表示残差连接(Residual Connection)用于防止网格退化,Norm表示Layer Normalization,用于对每一层的激活自豪进行归一化。
因为self-attention是Transformer的重点,所以我们将重点关注Multi-Head Attention以及self-attention,首先详细了解以下self-attention内部逻辑。
3.1 self-attention结构

上图是self-attention的结构,在计算的时候需要哦那个到矩阵Q(查询),K(键值),V(值),在实际中,self-attention接收的是输入(单词的表示向量x组成的矩阵X)或者上一个Encoder block的输出,而Q,K,V正是通过self-attention的输入进行线性变换得到的。
3.2 Q,K,V的计算
self.attention的输入用矩阵X进行表示,则可以使用线性变换矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示, 注意:X,Q,K,V的每一行都表示一个单词。

3.3self-atttention的输出
得到Q,K,V之后就可以计算出self-attention的输出了,计算的公式如下:
A
t
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Atttention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
Atttention(Q,K,V)=softmax(dk
QKT)V
其中,
d
k
d_k
dk是Q,K矩阵的行数,即向量维度。公式中计算矩阵Q,K每一行向量的内积,为了防止内积过大,因此除以
d
k
d_k
dk的平方根。Q乘以K的转置后,得到的矩阵行列数都为n,n为句子单词数,这个矩阵可以表示为单词之间的attention强度,下图为Q乘以
K
T
K^T
KT,1234表示句子中的单词。

得到 Q K T QK^T QKT之后,使用softmax计算每一个单词对于其他单词的attention系数,公式中的softmax是对矩阵的每一行进行softmax,即每一行的和都变为1.

得到 Softmax 矩阵之后可以和V相乘,得到最终的输出Z。

上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出
Z
1
Z_1
Z1等于所有单词 i 的值
V
i
V_i
Vi根据 attention 系数的比例加在一起得到,如下图所示:

3.4 Multi-Head Attention
在上一步中,我们已经知道怎么通过self-attention计算得到输出矩阵Z。然后Multi-Head Attention是由多个self-attention组合形成的,下面是原论文中的Multi-Head Attention的结构图。

从上图可以看到Multi-Head Attention包含多个self-attention层,首先将输入X分别传递到h个不同的self-attention中,计算得到h个输出矩阵Z,下图是h=8时候的情况,此时会得到8个输出矩阵Z。

得到8个输出矩阵 Z 1 到 Z 8 Z_1到Z_8 Z1到Z8之后,Mulit-Head Attention将它们拼接在一起(concat),然后传入一个Linear层,得到Multi-Head Attention最终的输出Z。

可以看到Multi-Head Attention输出的矩阵Z与其他输入的矩阵X的维度是一样的。
4.Encoder的结构

上图中红色部分是Transformer的Encoder block结构,可以看到是由Multi-Head Attention,Add & Norm,Feed Forward, Add & Norm组成的,刚刚已经了解了Multi-Head Attention的计算过程,现在了解一下Add & Norm和Feed Forward部分。
4.1 Add & Norm
Add & Norm层由Add 和Norm两部分组成,其计算公式如下:
L
a
y
e
r
N
o
r
m
(
X
+
M
u
l
t
i
H
e
a
d
A
t
t
e
n
t
i
o
n
(
X
)
)
L
a
y
r
N
o
r
m
(
X
+
M
u
l
t
i
H
e
a
d
A
t
t
e
n
t
i
o
n
(
X
)
)
LayerNorm(X+MultiHeadAttention(X))\\ LayrNorm(X+MultiHeadAttention(X))
LayerNorm(X+MultiHeadAttention(X))LayrNorm(X+MultiHeadAttention(X))
其中,X表示Multi-Head Attention或者Feed Forward的输入,MultiHeadAttention(X)和FeedForward(X)是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在ResNet中经常用到。
Norm值的是Layer他Normalization,通常用于RNN结构,Layer Normalization会将每一层神经元的输入都转成均值方差都一样的,这杨可以加快收敛。
4.2 Feed Forward
Feed Forward层较简单,是一个两层的全连接,第一层的激活函数为ReLU,第二层不适用激活函数,对应的公式如下:
m
a
x
(
0
,
X
W
1
+
b
1
)
W
2
+
b
2
max(0,XW_1+b_1)W_2+b_2
max(0,XW1+b1)W2+b2
X是输入,Feed Forward最终得到的输出矩阵的维度与X一致。
4.3 组成Encoder
通过上面描述的Multi-Head Attention,Feed Forward,Add & Norm就可以构造出一个Encoder block,Encoder block接收矩阵 X n × d X_{n\times d} Xn×d
并输出一个矩阵 O n × d O_{n\times d} On×d。通过多个Encoder block叠加就可以组成Encoder。
第一个Encoder block的输入为句子单词的表示向量矩阵,后续Encoder block的输入时前一个Encoder block的输出,最后一个Encoder block输出就是 编码信息矩阵C,这一矩阵后续会用到Decoder中。
5.Decoder结构

上图中红色部分为Transformer 的Deocder block结构,与Encoder block相似,但是存在一些区别:
- 包含两个Multi-Head Attention层
- 第一个Multi-Head Attention采用了Masked操作
- 第二个Multi-Head Attention层的K,V矩阵使用Encoder的 编码信息矩阵进行计算,而Q使用上一个Decoder block的输出计算。
- 最后一个softmax层计算下一个翻译单词的概率。
5.1 第一个Multi-Head Attention
Decoder block 的第一个Multi-Head Attention采用了Masked操作,因为在翻译的过程中是顺序翻译的,即翻译完第一个单词,次啊可以翻译第i+1个单词,通过Masked操作可以防止在预测第i个单词的时候之后i+1个单词之后的信息,下面以”我有一只猫“翻译成"I have a cat"为例,了解一下MAsked操作。
下面的描述中使用了类似 Teacher Forcing 的概念,不熟悉 Teacher Forcing 的童鞋可以参考以下上一篇文章Seq2Seq 模型详解。在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 “” 预测出第一个单词为 “I”,然后根据输入 " I" 预测下一个单词 “have”。

Decoder 可以在训练的过程中使用 Teacher Forcing 并且并行化训练,即将正确的单词序列 ( I have a cat) 和对应输出 (I have a cat ) 传递到 Decoder。那么在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住,注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用 0 1 2 3 4 5 分别表示 " I have a cat "。
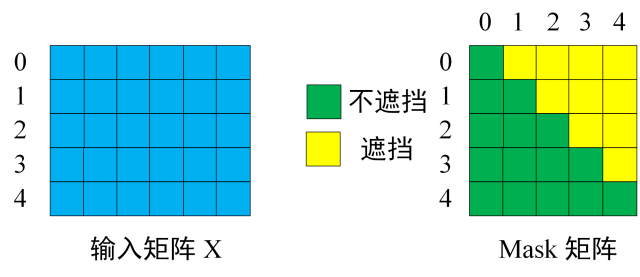
第一步:是 Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 " I have a cat" (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。
第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵X计算得到Q,K,V矩阵。然后计算Q和 K T K^T KT和 Q K T QK^T QKT。
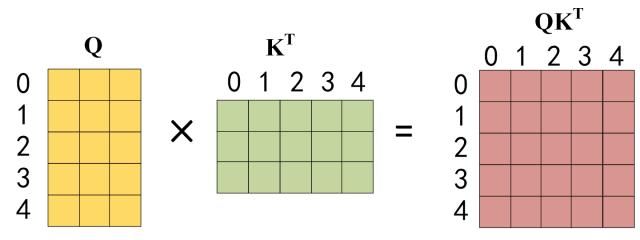
第三步:在得到 Q K T QK^T QKT之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
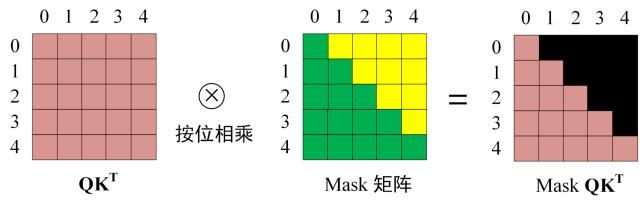
得到 Mask Q K T QK^T QKT之后在 Mask Q K T QK^T QKT上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。
第四步:使用 Mask Q K T QK^T QKT与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量 Z 1 Z_1 Z1是只包含单词 1 信息的。
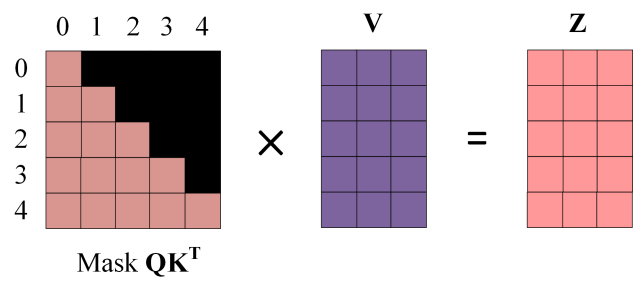
第五步:通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵 Z i Z_i Zi,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出 Z i Z_i Zi 然后计算得到第一个 Multi-Head Attention 的输出Z,Z与输入X维度一样。
5.2 第二个 Multi-Head Attention
Decoder block 第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
根据 Encoder 的输出 C计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
5.3 Softmax 预测输出单词
Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词 0 的输出 Z0 只包含单词 0 的信息,如下:
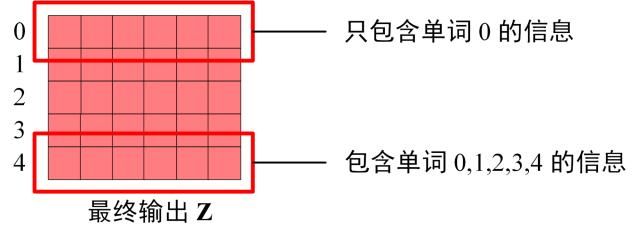
Softmax 根据输出矩阵的每一行预测下一个单词:
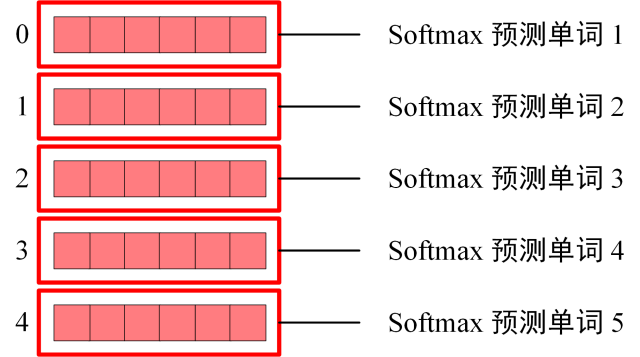
这就是 Decoder block 的定义,与 Encoder 一样,Decoder 是由多个 Decoder block 组合而成。
6. Transformer 总结
- Transformer 与 RNN 不同,可以比较好地并行训练。
- Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
- Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
- Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。


