
- 1GD32F103 USBD CDC移植_gd32 usb cdc
- 2超实用!整理了34个Python自动化办公库!
- 3【项目实战】Python实现深度神经网络RNN-LSTM分类模型(医学疾病诊断)
- 4手把手教你Studio One 6 mac下载,中文激活,音乐编曲工具,支持M1M2永久使用。
- 5git之分离头指针_头指针分离自
- 6STM32+hal+MPU6050读取陀螺仪,温度传感器数据_陀螺仪 温度传感器
- 7flutter2 删除不推荐使用的Scaffold.resizeToAvoidBottomPadding_scaffold resizetoavoidbottompadding
- 8Linux操作系统———系统调用_linux ring1和riong1
- 9[导入]Box.net再次开启免费注册!1GB免费空间
- 10开源 | GPU池化软件 V2.8.1 (AI人工智能训练平台、AI人工智能推理平台)_gpu池化管理平台
Hadoop概念以及架构介绍
赞
踩
1 hadoop的意义
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的未来进行高速运算和存储。
Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里
对于Hadoop分布式文件系统(HDFS)来说,大数据处理通过三份以上存储来支持数据的高可用性。
2 Hadoop优点
- 高可靠性:Hadoop按位存储和处理数据的能力值得信赖
- 高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中
- 高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快
- 高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配
- 低成本:与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,Hadoop是开源的,项目的软件成本因此会大大降低
3 Hadoop生态圈
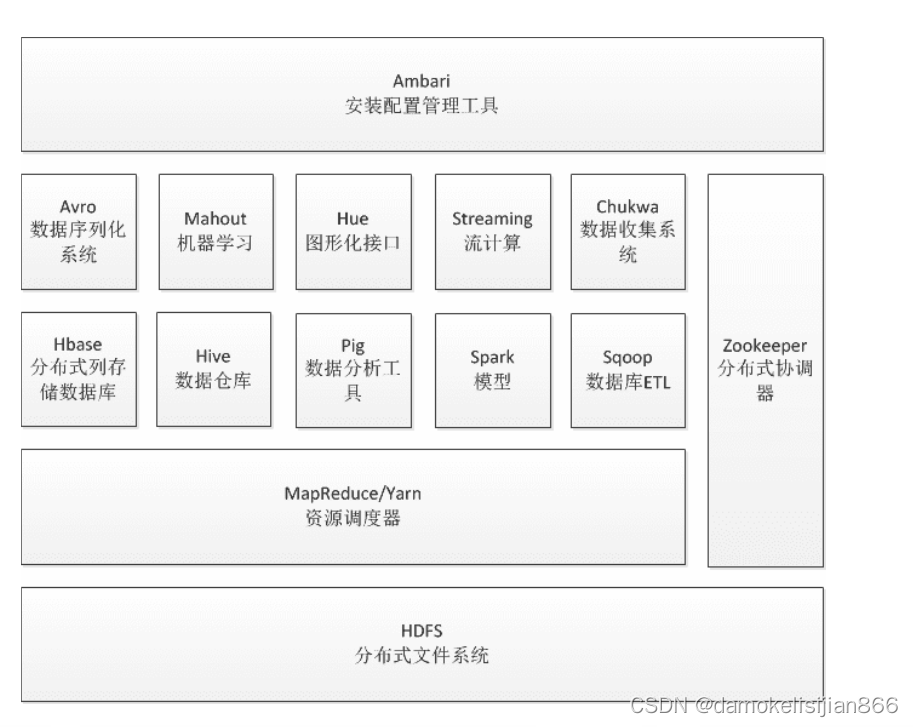
4 Hadoop的整体架构
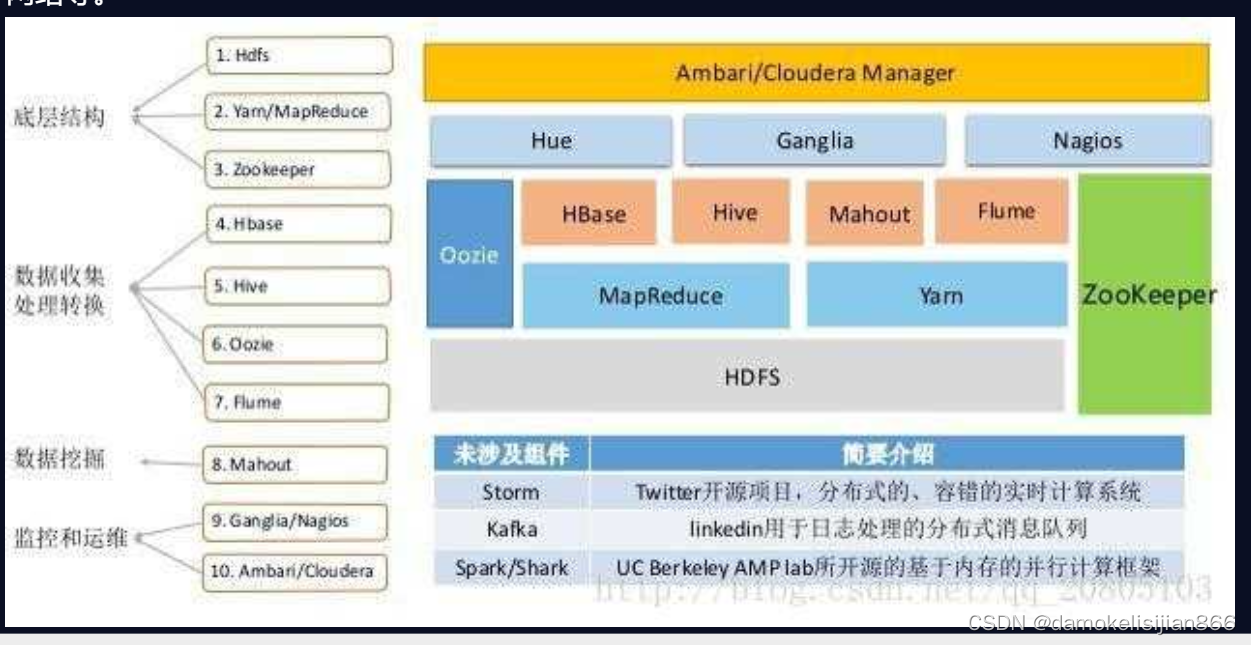
HDFS和MapReduce是Hadoop的两大核心,除此之外,Hbase、Hive这两个核心工具也随着Hadoop发展变得越来越重要。同时,在Hadoop2.0之后,在HDFS的基础上增加了YARN,是一个资源管理框架,在YARN上既可以放MapReduce,也可以防止其它的计算资源,主要是管理资源的,如CPU,硬盘,内存,网络等
5 Hadoop的组件介绍
5.1 HDFS
HDFS(hadoop Distributed File System)是分布式文件管理系统中的一种,用来管理多台机器上的文件,通过目录树来定位文件
HDF为主(Master)/从(Slave)架构:一个NameNode,多个DataNode
HDFS核心架构
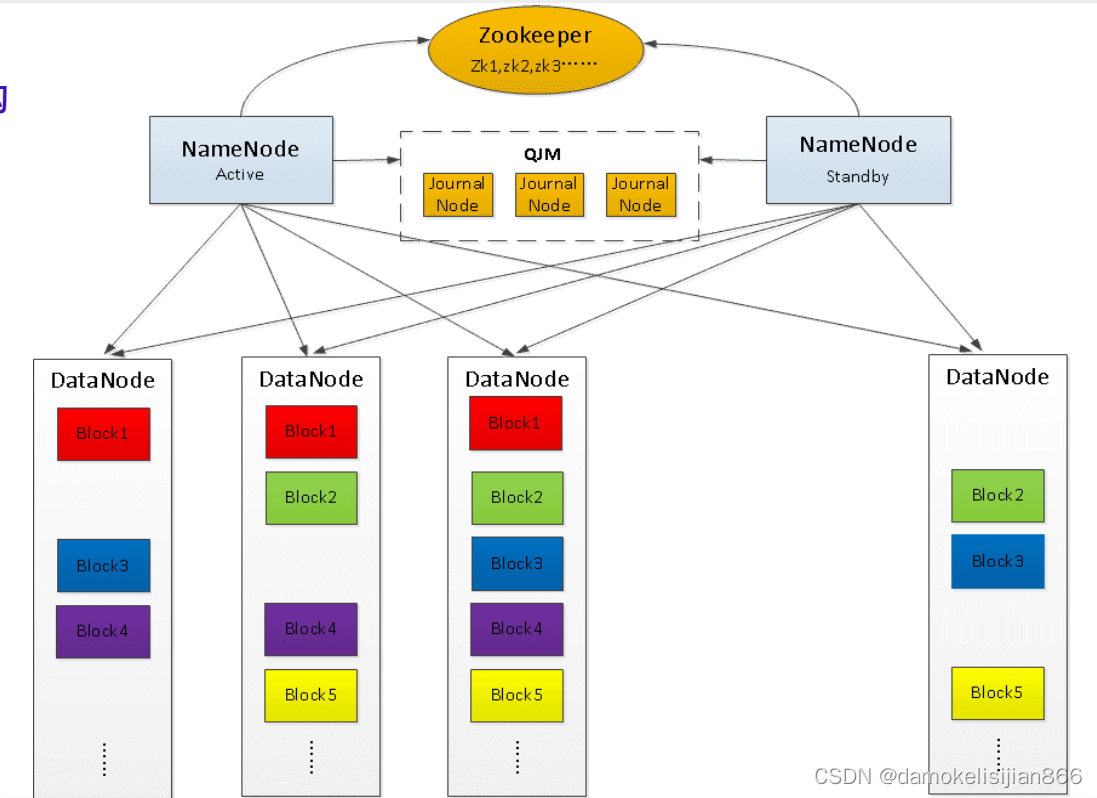
HDFS的几个核心概念
- NameNode:管理文件系统命名空间(打开、关闭、重命名文件和目录,还确定了文件块在哪个DataNode上的路径),管理客户端对文件的访问,配置副本策略(复制因子,可为某个文件单独设置),记录对文件系统命名空间或其属性的任何更改。
- DataNode:存储文件块(负责提供来自文件系统客户端的读写请求,还根据NameNode的指令执行块创建、删除和复制),上传至HDFS的文件在内部被分成一个或多个块,这些块存储在一组DataNode中。
- Block:块,文件存储处理的逻辑单元,默认是64M。
数据写入过程
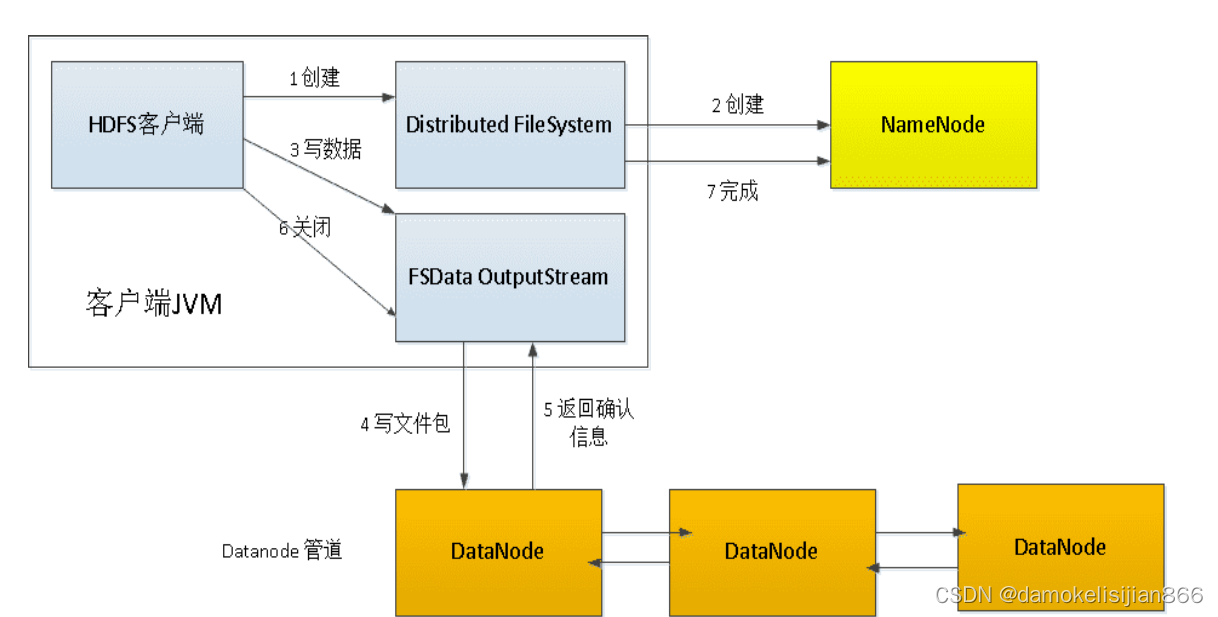
- Client向NameNode发起文件写入的请求
- NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息
- Client将文件划分为多个文件块,根据DataNode的地址信息,按顺序写入到每一个DataNode块中
数据读取过程
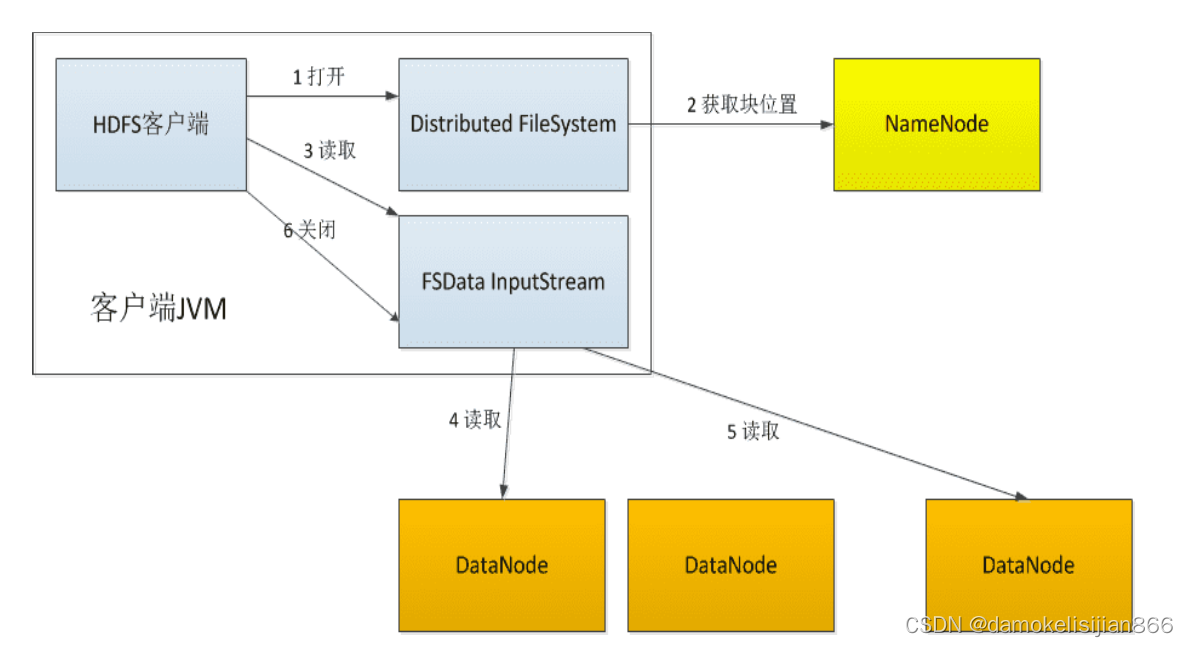
- Client向NameNode发起文件读取的请求
- NameNode返回文件存储的DataNode的信息
- Client读取文件信息
5.2 MapReduce
先举个比较形象的例子
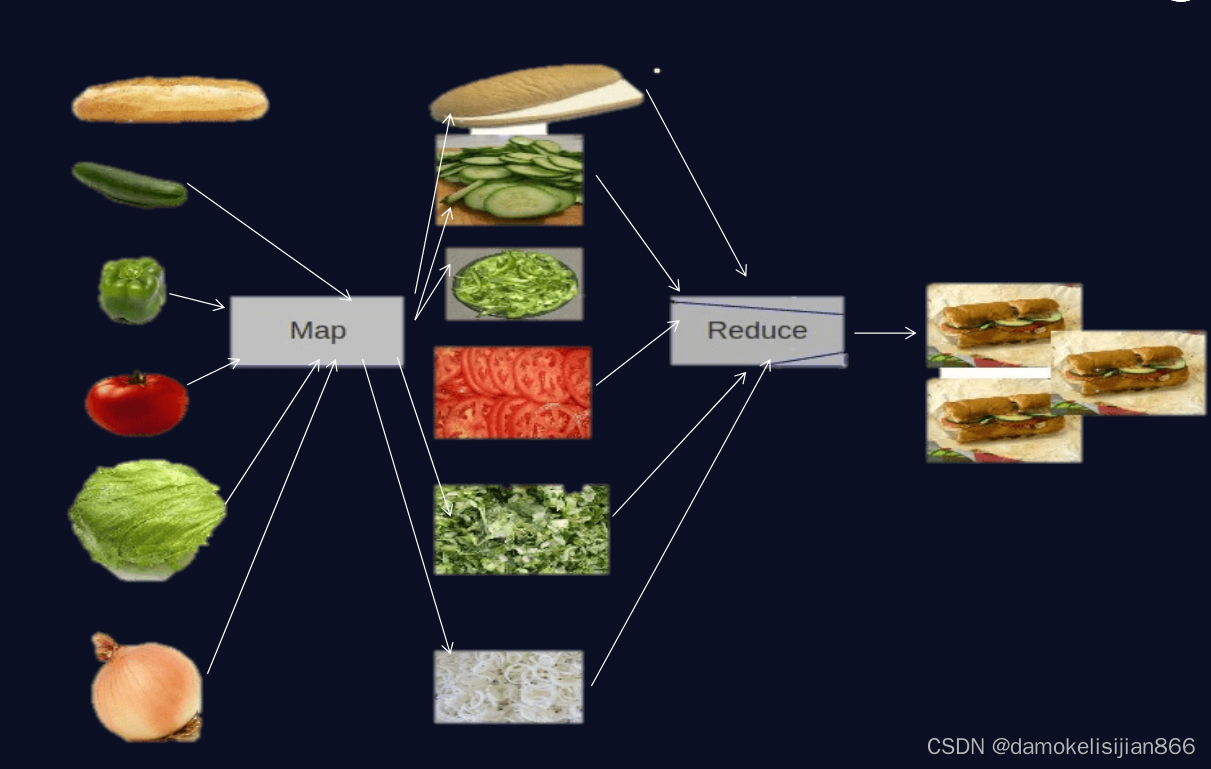
MapReduce是一个单独运行在主节点上的JobTracker和运行在每个集群从节点上的TaskTracker共同组成
HDFS和MapReduce共同组成Hadoop分布式系统体系结构的核心
HDFS在集群上实现了分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理
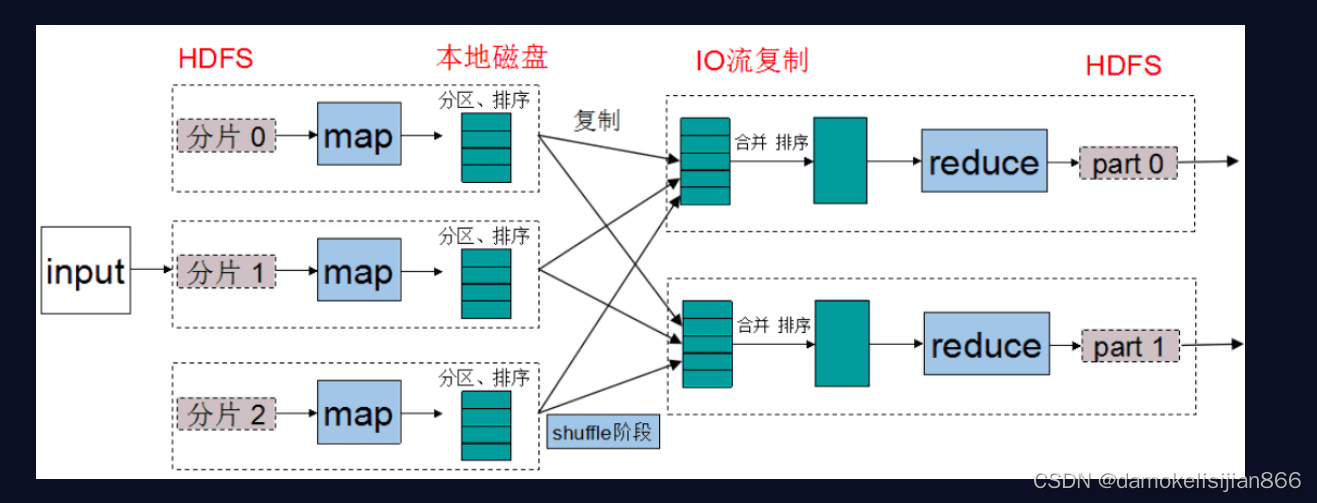
MapReduce V1架构
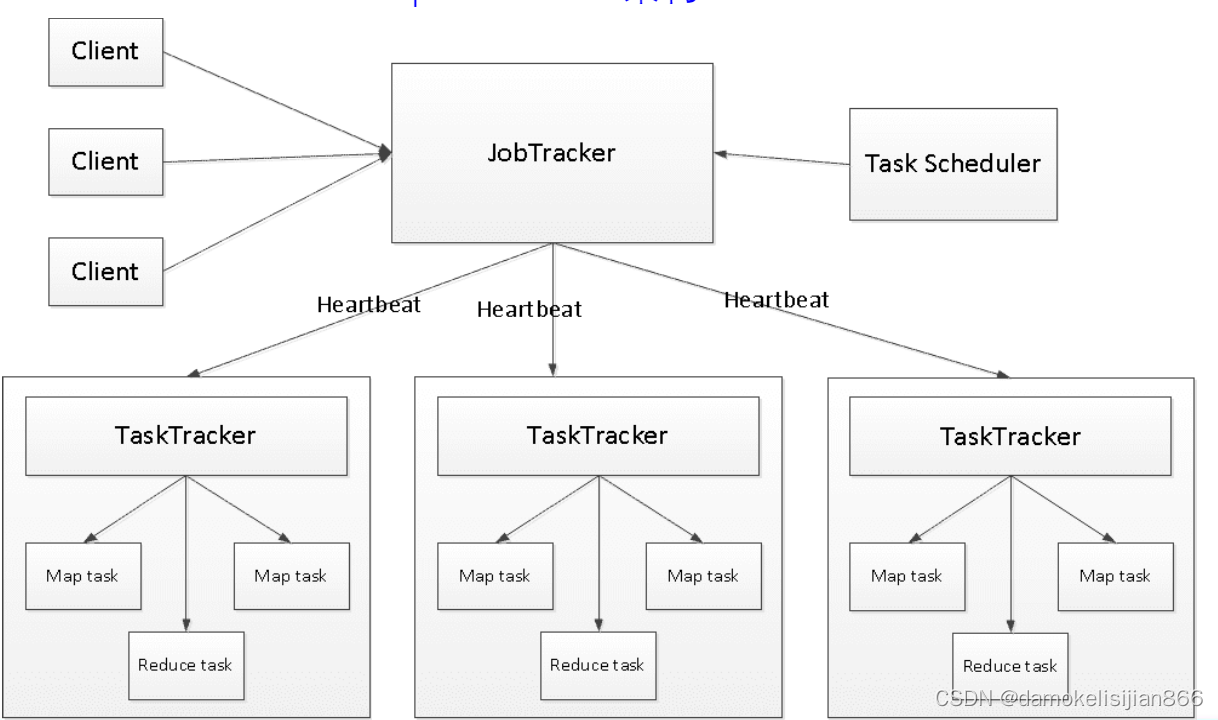
几个核心概念
- JobTracker:是主线程,它负责接收客户作业提交,调度任务到工作节点上运行,并提供诸如监控工作节点状态以及任务进度等管理功能。
- TaskTracker:后台程序,由jobtracker指派任务,实例化用户程序,在本地执行任务并周期性地向jobtracker汇报状态
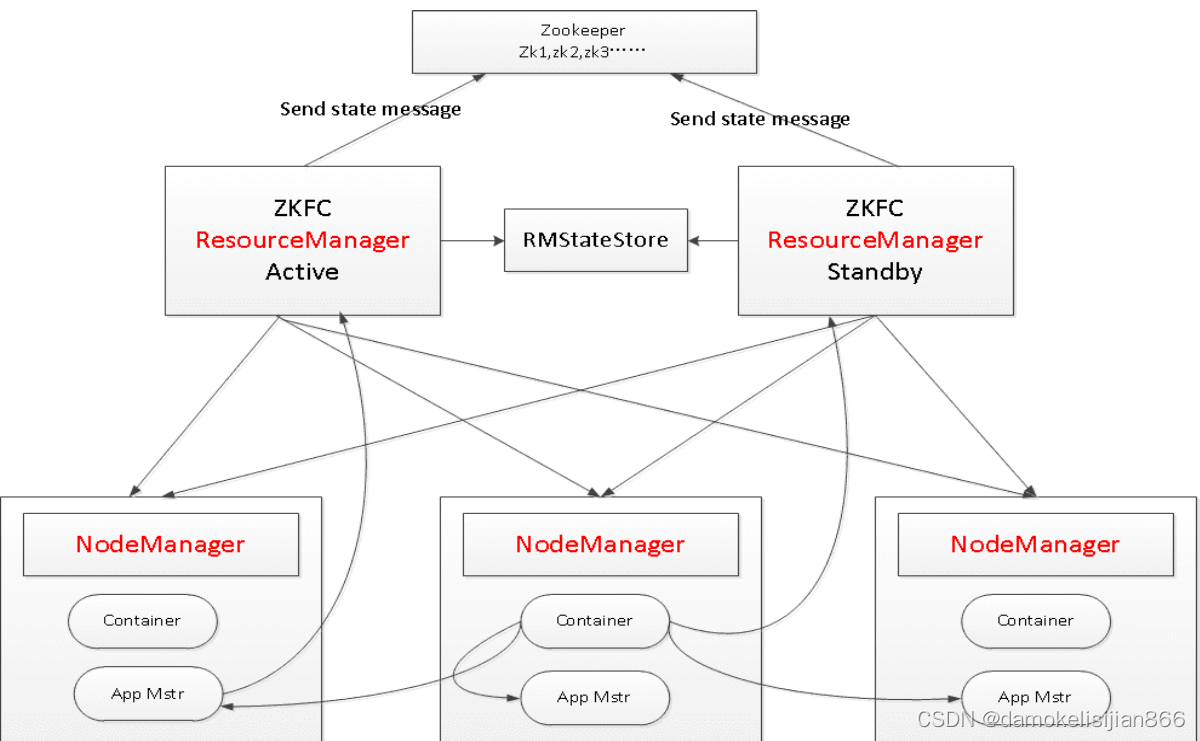
- ResourceManager:处理客户端请求,启动或监控ApplicationMaster,监控NodeManager,资源的分配与调度
- NodeManager:管理单个节点上的资源,处理来自ResoucceManager的命令,处理来自ApplicationMaster的命令。
- ApplicationMaster:管理在YARN内运行的每个应用程序实例,负责协调来自ResourceManager的资源,并通过NodeManager的监视容器的执行和资源使用(CPU、内存等的资源分配)
- Container:是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
MapReduce V2/Yarn架构
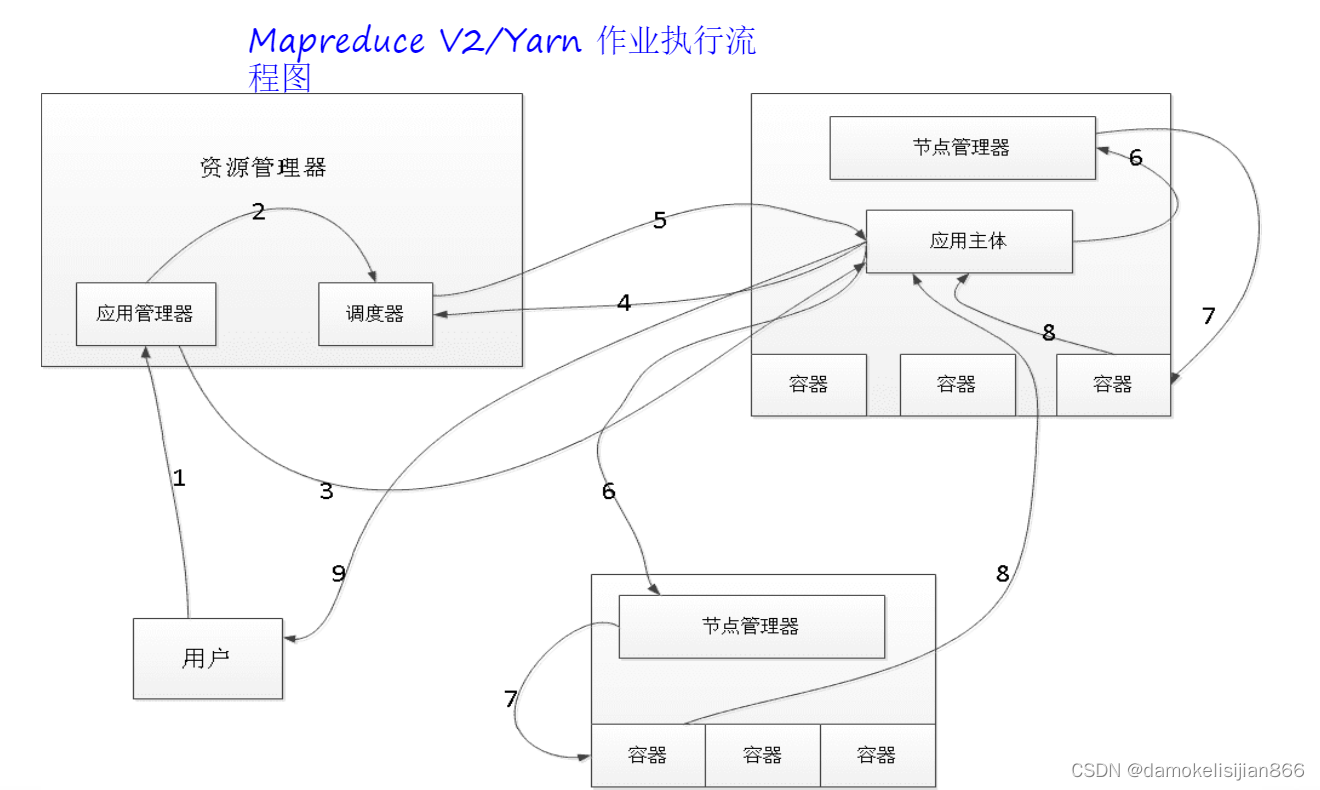
MapReduce V2/Yarn 作业执行流程
- 用户作业提交
- ResourceManager 收到作业请求,将该请求发给scheduler,调度器分配第一个container,然后资源管理器在该container内启动Application manager
- Application manager找一台nodeManager启动Application Master,计算任务所需的计算
- Application master向Application manager的scheduler申请运行任务所需的资源
- scheduler将资源封装发给Application master;
- Application master将获取到的资源分配给各个nodeManager,并创建容器
- 各个nodeManager得到任务和资源开始在容器执行map task和reduce task,map task和reduce task将执行结果反馈给Application master
- Application master将任务执行的结果反馈给application manager,applicationMaster向ResourceManager注销并关闭自己,application manager反馈结果给用户。
5.3 Yarn
Yarn是一个分布式资源管理系统,负责集群机器资源的隔离、分配和管理
Yarn在真个hadoop生态处理中心枢纽的位置,各种分布式计算框架(MR、spark、tez、Flink)可以运行在Yarn上,让各种计算框架无需各自实现资源分配机制,更加纯粹专注做分布式计算相关工作


