
- 1记一次使用Notepad++正则表达式批量替换SQL语句
- 2【强化学习-医疗】医疗保健中的强化学习:综述_强化学习在医疗行业的应用
- 3【uni-app】tabbar自定义_uniapp 自定义tabbar
- 4Hadoop集群部署和启动与关闭_启动hadoop
- 5PCL在Mac上环境问题_mac m1配置pcl和vtk环境
- 6xhadmin多应用SaaS框架之智慧驾校H5+小程序v1.1.5正式发布!
- 7数模论文写作方法3|问题重述_数学建模问题重述
- 8【网站项目】游戏美术外包管理信息系统
- 9hadoop管理界面介绍和使用_hadoop8088界面详解
- 10腾讯专家献上技术干货,带你一览腾讯广告召回系统的演进_recall 95
一键虚拟换衣项目OOTDiffusion整合包发布
赞
踩
今天给大家分享个一键虚拟换装的项目。我们只需要上传模特图和服饰图就可以实现一键换装。我为大家准备了整合包和使用教程。(文章末尾自取)

配置要求
Windows
-
N卡显存8G以上
-
不支持cpu模式
Mac
该项目某些依赖项对MacOS的支持不好,所以这次整合包只有Windows版本的。Mac用户可以使用网页在线体验。
网页地址(需科学上网):https://huggingface.co/spaces/levihsu/OOTDiffusion
性能测试
这里用的是默认的参考图,使用全身模式,生成图片一张所需要的时间
-
RTX 2080 11min
-
RTX 3060 28s
-
RTX 4090 3s
机器有限,这里仅供参考,还是以大家自己实际的生成时长为准。
使用说明
半身模式
基础界面
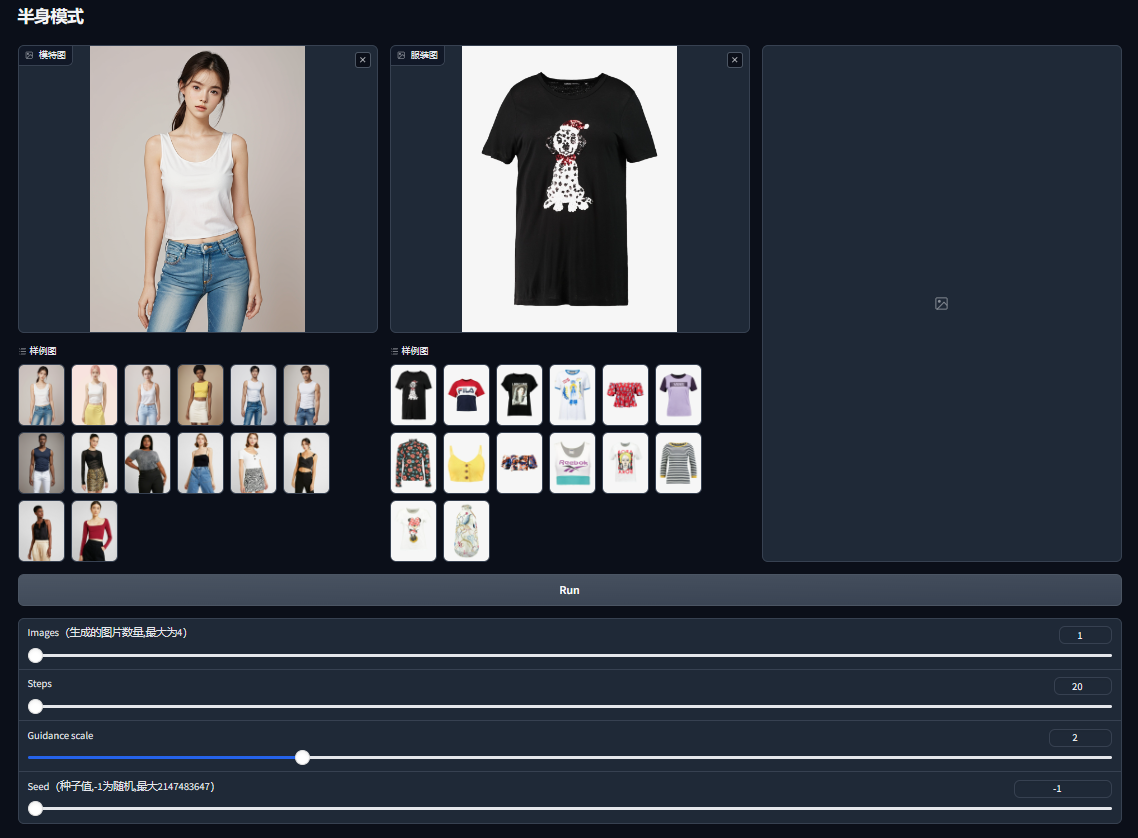
使用非常简单。准备好一张模特图、一张服装图,分别拖拽到对应的窗口中,点击Run就能得到换装后的图片。默认会有很多样例图可以直接使用。
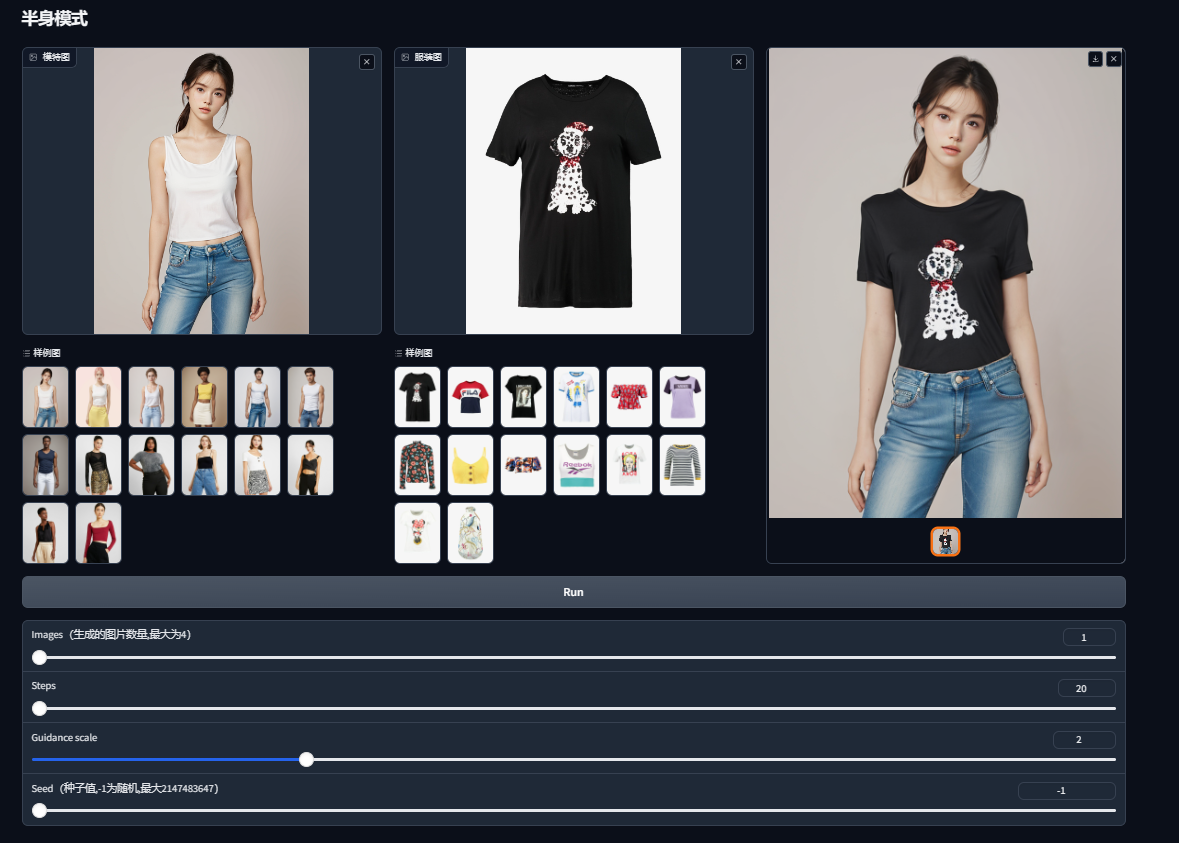
参数解析:
Images 生成图片的数量,默认为1。
Steps 步数,默认为20。Step值能够影响画面的完成度(Step越高,越会在后面的步数中倾向于渲染细节)。
Guidance scale 指导尺度。调整它可以更好的使用图像质量更好或更具备多样性。默认为2。
Seed 种子参数。默认为-1。
全身模式

全身模式的使用方式基本和半身模式类似。唯一不同的点在于需要注意下服装类别这个选项。

比如你上传的是上衣,你这里需要选择Upper-body。其他的参数和半身模式一样。
技术解析
OOTDiffusion主要使用了以下关键技术:
-
预训练的潜在扩散模型:利用预训练的潜在扩散模型确保生成图像的高逼真度和自然的试穿效果。
-
Outfitting UNet:设计了Outfitting UNet来学习服装的详细特征,实现服装特征的精确对齐。
-
Outfitting Fusion:在去噪UNet的自注意层中进行Outfitting融合,有效地将服装特征与目标人体对齐,避免冗余的变形过程。
-
Outfitting Dropout:在训练过程中引入Outfitting Dropout,通过无分类器的指导调整服装特征的强度,增强可控性。
-
CLIP文本反演:尝试通过CLIP文本反演学习服装特征,以保留服装细节。
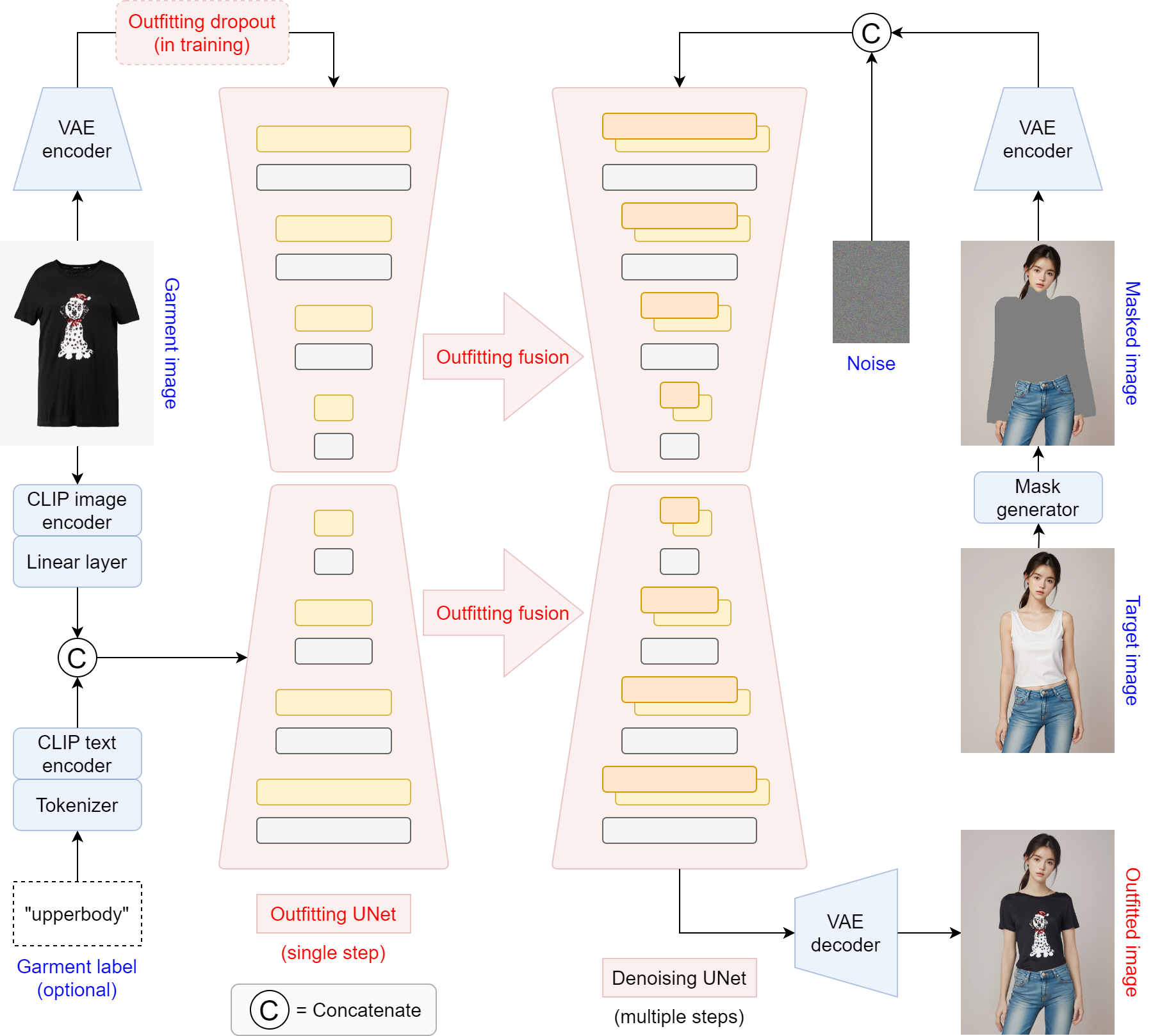
OOTDiffusion通过结合预训练的潜在扩散模型和自定义网络架构,实现了高逼真度和可控性的虚拟试穿效果。其中,通过Outfitting UNet学习服装的详细特征,再通过Outfitting Fusion将服装特征与目标人体精确对齐,避免了冗余的变形过程。在训练过程中引入Outfitting Dropout,通过无分类器的指导调整服装特征的强度,增强了试穿效果的可控性。
常见问题
服装换上去不合身怎么办?
试着调节下Guidance scale和Steps参数。多生成几个看下效果。项目还在测试阶段,不能保证所有的情况都能正确换装。
生成的速度很慢怎么办?
Steps看下是否设置的太高了。如果是默认的还是很慢,升级下机器配置吧。这个项目比较吃GPU。或者使用网页版在线使用。
整合包获取

关注公众号,发送【OOTDiffusion】关键字获取整合包

如果本文对您有帮助,还请给文章点个赞,感谢您的阅读。


