
- 1123_hih123、pw
- 2Redis常用数据结构及应用场景_redis数据结构及应用场景
- 3UML中活动图、状态图、流程图的区别_uml状态图和流程图的区别
- 4iOS开发进阶(二十):Xcode 断点调试详解
- 5ZeroTier创建虚拟网络连通共享公网内网计算机_zeroriter做公网
- 6python方法定义的第一个参数是this_Python函数中如何定义参数
- 7Docker consul 容器服务更新与发现_consul 来记录docker 的容器状态
- 8GitHub从注册到上传静态网页(保姆级教程手把手教你上载自己的静态网页)_github 静态网页
- 92021 年云原生技术发展现状及未来趋势
- 10Spring boot使用一个接口实现任意一张表的增删改查
DSSM实战中文文本匹配任务_dssm 处理中文
赞
踩
引言
本文我们通过DSSM模型来完成中文文本匹配任务,其中包含了文本匹配任务的一般套路,后续只需要修改实现的模型。
数据准备
数据准备包括
- 构建词表(Vocabulary)
- 构建数据集(Dataset)
本次用的是LCQMC通用领域问题匹配数据集,它已经分好了训练、验证和测试集。
我们通过pandas来加载一下。
import pandas as pd
train_df = pd.read_csv(data_path.format("train"), sep="\t", header=None, names=["sentence1", "sentence2", "label"])
train_df.head()
- 1
- 2
- 3
- 4
- 5

数据是长这样子的,有两个待匹配的句子,标签是它们是否相似。
下面用jieba来处理每个句子。
def tokenize(sentence):
return list(jieba.cut(sentence))
train_df.sentence1 = train_df.sentence1.apply(tokenize)
train_df.sentence2 = train_df.sentence2.apply(tokenize)
- 1
- 2
- 3
- 4
- 5
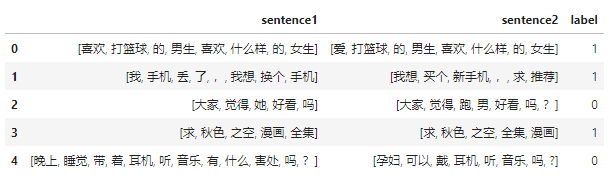
得到分好词的数据后,我们就可以得到整个训练语料库中的所有token:
train_sentences = train_df.sentence1.to_list() + train_df.sentence2.to_list()
train_sentences[0]
- 1
- 2
['喜欢', '打篮球', '的', '男生', '喜欢', '什么样', '的', '女生']
- 1
现在就可以来构建词表了,我们定义一个类:
UNK_TOKEN = "<UNK>" PAD_TOKEN = "<PAD>" class Vocabulary: """Class to process text and extract vocabulary for mapping""" def __init__(self, token_to_idx: dict = None, tokens: list[str] = None) -> None: """ Args: token_to_idx (dict, optional): a pre-existing map of tokens to indices. Defaults to None. tokens (list[str], optional): a list of unique tokens with no duplicates. Defaults to None. """ assert any( [tokens, token_to_idx] ), "At least one of these parameters should be set as not None." if token_to_idx: self._token_to_idx = token_to_idx else: self._token_to_idx = {} if PAD_TOKEN not in tokens: tokens = [PAD_TOKEN] + tokens for idx, token in enumerate(tokens): self._token_to_idx[token] = idx self._idx_to_token = {idx: token for token, idx in self._token_to_idx.items()} self.unk_index = self._token_to_idx[UNK_TOKEN] self.pad_index = self._token_to_idx[PAD_TOKEN] @classmethod def build( cls, sentences: list[list[str]], min_freq: int = 2, reserved_tokens: list[str] = None, ) -> "Vocabulary": """Construct the Vocabulary from sentences Args: sentences (list[list[str]]): a list of tokenized sequences min_freq (int, optional): the minimum word frequency to be saved. Defaults to 2. reserved_tokens (list[str], optional): the reserved tokens to add into the Vocabulary. Defaults to None. Returns: Vocabulary: a Vocubulary instane """ token_freqs = defaultdict(int) for sentence in tqdm(sentences): for token in sentence: token_freqs[token] += 1 unique_tokens = (reserved_tokens if reserved_tokens else []) + [UNK_TOKEN] unique_tokens += [ token for token, freq in token_freqs.items() if freq >= min_freq and token != UNK_TOKEN ] return cls(tokens=unique_tokens) def __len__(self) -> int: return len(self._idx_to_token) def __getitem__(self, tokens: list[str] | str) -> list[int] | int: """Retrieve the indices associated with the tokens or the index with the single token Args: tokens (list[str] | str): a list of tokens or single token Returns: list[int] | int: the indices or the single index """ if not isinstance(tokens, (list, tuple)): return self._token_to_idx.get(tokens, self.unk_index) return [self.__getitem__(token) for token in tokens] def lookup_token(self, indices: list[int] | int) -> list[str] | str: """Retrive the tokens associated with the indices or the token with the single index Args: indices (list[int] | int): a list of index or single index Returns: list[str] | str: the corresponding tokens (or token) """ if not isinstance(indices, (list, tuple)): return self._idx_to_token[indices] return [self._idx_to_token[index] for index in indices] def to_serializable(self) -> dict: """Returns a dictionary that can be serialized""" return {"token_to_idx": self._token_to_idx} @classmethod def from_serializable(cls, contents: dict) -> "Vocabulary": """Instantiates the Vocabulary from a serialized dictionary Args: contents (dict): a dictionary generated by `to_serializable` Returns: Vocabulary: the Vocabulary instance """ return cls(**contents) def __repr__(self): return f"<Vocabulary(size={len(self)})>"

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
可以通过build方法传入所有分好词的语句,同时传入min_freq指定保存最少出现次数的单词。
这里实现了__getitem__来获取token对应的索引,如果传入的是单个token就返回单个索引,如果传入的是token列表,就返回索引列表。类似地,通过lookup_token来根据所以查找对应的token。
vocab = Vocabulary.build(train_sentences)
vocab
- 1
- 2
100%|██████████| 477532/477532 [00:00<00:00, 651784.13it/s]
<Vocabulary(size=35925)>
- 1
- 2
我们的词表有35925个token。
有了词表之后,我们就可以向量化句子了,这里也通过一个类来实现。
class TMVectorizer: """The Vectorizer which vectorizes the Vocabulary""" def __init__(self, vocab: Vocabulary, max_len: int) -> None: """ Args: vocab (Vocabulary): maps characters to integers max_len (int): the max length of the sequence in the dataset """ self.vocab = vocab self.max_len = max_len def _vectorize( self, indices: list[int], vector_length: int = -1, padding_index: int = 0 ) -> np.ndarray: """Vectorize the provided indices Args: indices (list[int]): a list of integers that represent a sequence vector_length (int, optional): an arugment for forcing the length of index vector. Defaults to -1. padding_index (int, optional): the padding index to use. Defaults to 0. Returns: np.ndarray: the vectorized index array """ if vector_length <= 0: vector_length = len(indices) vector = np.zeros(vector_length, dtype=np.int64) if len(indices) > vector_length: vector[:] = indices[:vector_length] else: vector[: len(indices)] = indices vector[len(indices) :] = padding_index return vector def _get_indices(self, sentence: list[str]) -> list[int]: """Return the vectorized sentence Args: sentence (list[str]): list of tokens Returns: indices (list[int]): list of integers representing the sentence """ return [self.vocab[token] for token in sentence] def vectorize( self, sentence: list[str], use_dataset_max_length: bool = True ) -> np.ndarray: """ Return the vectorized sequence Args: sentence (list[str]): raw sentence from the dataset use_dataset_max_length (bool): whether to use the global max vector length Returns: the vectorized sequence with padding """ vector_length = -1 if use_dataset_max_length: vector_length = self.max_len indices = self._get_indices(sentence) vector = self._vectorize( indices, vector_length=vector_length, padding_index=self.vocab.pad_index ) return vector @classmethod def from_serializable(cls, contents: dict) -> "TMVectorizer": """Instantiates the TMVectorizer from a serialized dictionary Args: contents (dict): a dictionary generated by `to_serializable` Returns: TMVectorizer: """ vocab = Vocabulary.from_serializable(contents["vocab"]) max_len = contents["max_len"] return cls(vocab=vocab, max_len=max_len) def to_serializable(self) -> dict: """Returns a dictionary that can be serialized Returns: dict: a dict contains Vocabulary instance and max_len attribute """ return {"vocab": self.vocab.to_serializable(), "max_len": self.max_len} def save_vectorizer(self, filepath: str) -> None: """Dump this TMVectorizer instance to file Args: filepath (str): the path to store the file """ with open(filepath, "w") as f: json.dump(self.to_serializable(), f) @classmethod def load_vectorizer(cls, filepath: str) -> "TMVectorizer": """Load TMVectorizer from a file Args: filepath (str): the path stored the file Returns: TMVectorizer: """ with open(filepath) as f: return TMVectorizer.from_serializable(json.load(f))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
命名为TMVectorizer表示是用于文本匹配(Text Matching)的专门类,调用vectorize方法一次传入一个分好词的句子就可以得到向量化的表示,支持填充Padding。
同时还支持保存功能,主要是用于保存相关的词表以及TMVectorizer所需的max_len字段。
在本小节的最后,通过继承Dataset来构建专门的数据集。
class TMDataset(Dataset): """Dataset for text matching""" def __init__(self, text_df: pd.DataFrame, vectorizer: TMVectorizer) -> None: """ Args: text_df (pd.DataFrame): a DataFrame which contains the processed data examples vectorizer (TMVectorizer): a TMVectorizer instance """ self.text_df = text_df self._vectorizer = vectorizer def __getitem__(self, index: int) -> Tuple[np.ndarray, np.ndarray, int]: row = self.text_df.iloc[index] return ( self._vectorizer.vectorize(row.sentence1), self._vectorizer.vectorize(row.sentence2), row.label, ) def get_vectorizer(self) -> TMVectorizer: return self._vectorizer def __len__(self) -> int: return len(self.text_df)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
构建函数所需的参数只有两个,分别是处理好的DataFrame和TMVectorizer实例。
实现__getitem__方法,因为这个方法会被DataLoader调用,在该方法中对语句进行向量化。
max_len = 50
vectorizer = TMVectorizer(vocab, max_len)
train_dataset = TMDataset(train_df, vectorizer)
batch_size = 128
train_data_loader = DataLoader(train_dataset, batch_size=batch_size,shuffle=True)
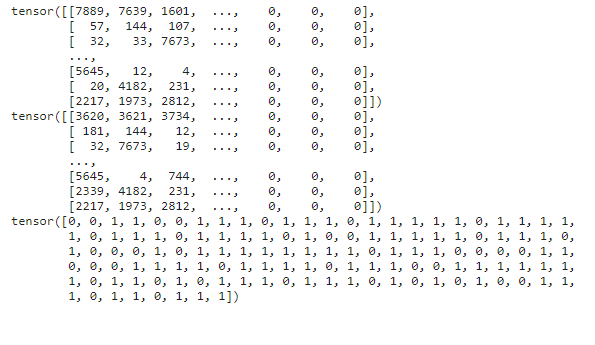
for setence1, setence12, label in train_data_loader:
print(setence1)
print(setence12)
print(label)
break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
构造模型
import torch.nn as nn import torch class DSSM(nn.Module): """The DSSM model implemention.""" def __init__( self, vocab_size: int, embedding_size: int, activation: str = "relu", internal_hidden_sizes: list[int] = [256, 128, 64], dropout: float = 0.1, ): """ Args: vocab_size (int): the size of the Vocabulary embedding_size (int): the size of each embedding vector activation (str, optional): the activate function. Defaults to "relu". internal_hidden_sizes (list[int], optional): the hidden size of inernal Linear Layer. Defaults to [256, 128, 64]. dropout (float, optional): dropout ratio. Defaults to 0.1. """ super().__init__() self.embedding = nn.Embedding(vocab_size, embedding_size) assert activation.lower() in [ "relu", "tanh", ], "activation only supports relu or tanh" if activation.lower() == "relu": activate_func = nn.ReLU() else: activate_func = nn.Tanh() self.dnn = nn.Sequential( nn.Dropout(dropout), nn.Linear(embedding_size, internal_hidden_sizes[0]), activate_func, nn.Dropout(dropout), nn.Linear(internal_hidden_sizes[0], internal_hidden_sizes[1]), activate_func, nn.Dropout(dropout), nn.Linear(internal_hidden_sizes[1], internal_hidden_sizes[2]), activate_func, nn.Dropout(dropout), ) self._init_weights() def forward(self, sentence1: torch.Tensor, sentence2: torch.Tensor) -> torch.Tensor: """Using the same network to compute the representations of two sentences Args: sentence1 (torch.Tensor): shape (batch_size, seq_len) sentence2 (torch.Tensor): shape (batch_size, seq_len) Returns: torch.Tensor: the cosine similarity between sentence1 and sentence2 """ # shape (batch_size, seq_len) -> (batch_size, seq_len, embedding_size) -> (batch_size, embedding_size) embed_1 = self.embedding(sentence1).sum(1) embed_2 = self.embedding(sentence2).sum(1) # (batch_size, embedding_size) -> (batch_size, internal_hidden_sizes[2]) vector_1 = self.dnn(embed_1) vector_2 = self.dnn(embed_2) # (batch_size, internal_hidden_sizes[2]) -> (batch_size, ) return torch.cosine_similarity(vector_1, vector_2, dim=1, eps=1e-8) def _init_weights(self) -> None: for layer in self.modules(): if isinstance(layer, nn.Linear): nn.init.xavier_uniform_(layer.weight)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
模型实现并不完全符合DSSM论文中的设定,比如没有采用词哈希,感觉用Embedding效果应该差不多,可能还更好。同时激活函数支持ReLU和Tanh,经过实验发现这里用ReLU的效果更好。
内部设计和DSSM论文中差不多,除了每层之后增加了Dropout,对于每层的大小和词嵌入维度也进行了一些修改。
在forward方法中首先计算整个序列的词嵌入,然后在序列长度上求和,相当于没有考虑序列中token的顺序。然后让两个语句经过同一个模型得到不同的表示,最后简单地计算它们的余弦相似度。
训练模型
定义指标:
def metrics(y: torch.Tensor, y_pred: torch.Tensor) -> Tuple[float, float, float, float]:
TP = ((y_pred == 1) & (y == 1)).sum().float() # True Positive
TN = ((y_pred == 0) & (y == 0)).sum().float() # True Negative
FN = ((y_pred == 0) & (y == 1)).sum().float() # False Negatvie
FP = ((y_pred == 1) & (y == 0)).sum().float() # False Positive
p = TP / (TP + FP).clamp(min=1e-8) # Precision
r = TP / (TP + FN).clamp(min=1e-8) # Recall
F1 = 2 * r * p / (r + p).clamp(min=1e-8) # F1 score
acc = (TP + TN) / (TP + TN + FP + FN).clamp(min=1e-8) # Accurary
return acc, p, r, F1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
定义参数:
args = Namespace( dataset_csv="text_matching/data/lcqmc/{}.txt", vectorizer_file="vectorizer.json", model_state_file="model.pth", save_dir=f"text_matching/dssm/model_storage", reload_model=False, cuda=True, learning_rate=5e-4, batch_size=128, num_epochs=10, max_len=50, embedding_dim=512, activation="relu", dropout=0.1, internal_hidden_sizes=[256, 256, 128], min_freq=2, print_every=500, verbose=True, )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
把参数统一管理,也可以保存到json中以便后续使用。
然后创建数据集
if args.cuda: device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") else: device = torch.device("cpu") print(f"Using device: {device}.") vectorizer_path = os.path.join(args.save_dir, args.vectorizer_file) train_df = build_dataframe_from_csv(args.dataset_csv.format("train")) test_df = build_dataframe_from_csv(args.dataset_csv.format("test")) dev_df = build_dataframe_from_csv(args.dataset_csv.format("dev")) if os.path.exists(vectorizer_path): print("Loading vectorizer file.") vectorizer = TMVectorizer.load_vectorizer(vectorizer_path) else: print("Creating a new Vectorizer.") train_sentences = train_df.sentence1.to_list() + train_df.sentence2.to_list() vocab = Vocabulary.build(train_sentences, args.min_freq) print(f"Builds vocabulary : {vocab}") vectorizer = TMVectorizer(vocab, args.max_len) vectorizer.save_vectorizer(vectorizer_path) train_dataset = TMDataset(train_df, vectorizer) test_dataset = TMDataset(test_df, vectorizer) dev_dataset = TMDataset(dev_df, vectorizer)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
定义模型:
model = DSSM( vocab_size=len(vectorizer.vocab), embedding_size=args.embedding_dim, activation=args.activation, internal_hidden_sizes=args.internal_hidden_sizes, dropout=args.dropout, ) print(f"Model: {model}") model_saved_path = os.path.join(args.save_dir, args.model_state_file) if args.reload_model and os.path.exists(model_saved_path): model.load_state_dict(torch.load(args.model_saved_path)) print("Reloaded model") else: print("New model") model = model.to(device) model_save_path = os.path.join( args.save_dir, f"{datetime.now().strftime('%Y%m%d%H%M%S')}-model.pth" )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
加载数据集、定义优化器、损失函数:
train_data_loader = DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=True
)
dev_data_loader = DataLoader(dev_dataset)
test_data_loader = DataLoader(test_dataset)
optimizer = torch.optim.Adam(model.parameters(), lr=args.learning_rate)
criterion = nn.CrossEntropyLoss()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
相似标签为1或0,这里当成二分类任务,因为模型的输出是余弦相似度,余弦相似度取值为-1到1,但一般0.4左右的值就可以认为是相似度不大了。所以采用CrossEntropyLoss而不是BCELoss;前者期望有2个输出特征,后者期望一个输出特征,通过是否大于0来判断类别,一般需要是sigmoid的输出。
定义评估函数和训练函数,如上所述,这里通过torch.stack构造了两个输出特征。
def evaluate(data_iter: DataLoader, model: DSSM) -> Tuple[float, float, float, float]: y_list, y_pred_list = [], [] model.eval() for x1, x2, y in tqdm(data_iter): x1 = x1.to(device).long() x2 = x2.to(device).long() y = torch.LongTensor(y).to(device) similarity = model(x1, x2) disparity = 1 - similarity output = torch.stack([disparity, similarity], 1).to(device) pred = torch.max(output, 1)[1] y_pred_list.append(pred) y_list.append(y) y_pred = torch.cat(y_pred_list, 0) y = torch.cat(y_list, 0) acc, p, r, f1 = metrics(y, y_pred) return acc, p, r, f1 def train( data_iter: DataLoader, model: DSSM, criterion: nn.CrossEntropyLoss, optimizer: torch.optim.Optimizer, print_every: int = 500, verbose=True, ) -> None: model.train() for step, (x1, x2, y) in enumerate(tqdm(data_iter)): x1 = x1.to(device).long() x2 = x2.to(device).long() y = torch.LongTensor(y).to(device) # the similarity between x1 and x2 similarity = model(x1, x2) # the disparity between x1 and x2 disparity = 1 - similarity # CrossEntropyLoss requires two class result output = torch.stack([disparity, similarity], 1).to(device) # output (batch_size, num_classes=2) # y (batch_size, ) loss = criterion(output, y) optimizer.zero_grad() loss.backward() optimizer.step() if verbose and (step + 1) % print_every == 0: # `torch.max` Returns a namedtuple (values, indices) where values is the maximum value of each row of the input tensor in the given dimension dim. # And indices is the index location of each maximum value found (argmax). # get the indices pred = torch.max(output, 1)[1] acc, p, r, f1 = metrics(y, pred) print( f" TRAIN iter={step+1} loss={loss.item():.6f} accuracy={acc:.3f} precision={p:.3f} recal={r:.3f} f1 score={f1:.4f}" )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
同时用torch.max返回的最大值对应的索引来表示预测的类别,0表示负类,1表示正类,所以torch.stack([disparity, similarity], 1)必须把表示不相似的disparity放在0的位置,不要搞错了。
开始训练:
best_f1 = 0.0 for epoch in range(args.num_epochs): train( train_data_loader, model, criterion, optimizer, print_every=args.print_every, verbose=args.verbose, ) print("Begin evalute on dev set.") with torch.no_grad(): acc, p, r, f1 = evaluate(dev_data_loader, model) if best_f1 < f1: best_f1 = f1 torch.save(model.state_dict(), model_save_path) print( f"EVALUATE [{epoch+1}/{args.num_epochs}] accuracy={acc:.3f} precision={p:.3f} recal={r:.3f} f1 score={f1:.4f} best f1: {best_f1:.4f}" )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
每训练完一个轮次后在验证集上进行验证,确保验证集效果是逐步变好的。
最后在测试集上验证,这里分别用训练完的模型和f1 score最好的模型在测试集上测试:
model.eval()
acc, p, r, f1 = evaluate(test_data_loader, model)
print(f"TEST accuracy={acc:.3f} precision={p:.3f} recal={r:.3f} f1 score={f1:.4f}")
model.load_state_dict(torch.load(model_save_path))
model.to(device)
acc, p, r, f1 = evaluate(test_data_loader, model)
print(f"TEST accuracy={acc:.3f} precision={p:.3f} recal={r:.3f} f1 score={f1:.4f}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
...
TRAIN iter=1000 loss=0.532778 accuracy=0.789 precision=0.820 recal=0.869 f1 score=0.8439
80%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 1493/1866 [00:25<00:06, 60.49it/s]
TRAIN iter=1500 loss=0.533075 accuracy=0.797 precision=0.795 recal=0.880 f1 score=0.8354
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [00:31<00:00, 59.61it/s]
Begin evalute on dev set.
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8802/8802 [00:11<00:00, 755.99it/s]
EVALUATE [10/10] accuracy=0.647 precision=0.639 recal=0.676 f1 score=0.6570 best f1: 0.6668
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12500/12500 [00:18<00:00, 662.33it/s]
TEST accuracy=0.715 precision=0.660 recal=0.887 f1 score=0.7571
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12500/12500 [00:19<00:00, 654.56it/s]
TEST accuracy=0.500 precision=0.500 recal=1.000 f1 score=0.6667
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
从结果可以看到,最后在测试集上的准确率为71.7%,效果还行,因为模型比较简单。后续我们尝试不同的模型来优化这个效果。
同时可以看到验证集上f1 score最好的模型效果反而不比最后训练好的模型。

