
- 1FPGA硬件逻辑和数字IC中笔试面试常考的Verilog语言实现分频问题(包含偶数分频、计数分频、小数分频和任意整数分频)_整数分频和小数分频
- 2Python中wordcloud模块如何生成特定形状的词云图 以心形词云图为例_wordcloud生成心形图片
- 3Stable Diffusion XL 现已推出——有什么新功能?
- 48年测试人该告诉你:同样是点工,凭什么他拿月薪20k,你却只有10k?_8年测试可以拿多少
- 5Spring Boot 系列 —— Spring Webflux_springboot + 通义千问 + flux
- 6Python 人脸识别实现(三种方式)_python人脸识别
- 7Lambda表达式下访问外部变量_lambda表达式里面怎么用外部变量
- 8MySQL 8.0.34 和 Navicat Premium 12 安装配置教程(手把手 超详细图文教程)_navicat premium12
- 9规定长度的上升子序列的个数_特定长度的上升子序列个数
- 10x-ray社区版简单使用教程_winxray使用教程
图论算法<六>:数据结构之图Graph详解及代码实现
赞
踩
1、图的定义
图(graph)是一种非线性数据结构,由顶点(vertex)和边(edge)组成。我们可以将图 抽象地表示为一组顶点 和一组边的集合。如果将顶点看作节点,将边看作连接各个节点的引用(指针),我们就可以将图看作一种从链表拓展而来的数据结构。如图所示,相较于线性关系(链表)和分治关系(树),网络关系(图)的自由度更高,因而更为复杂。
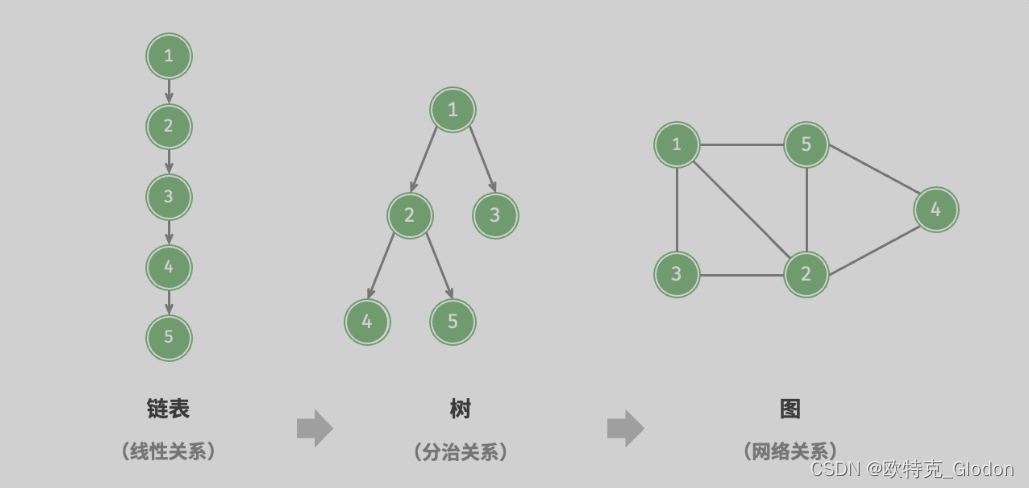
2、图的类型
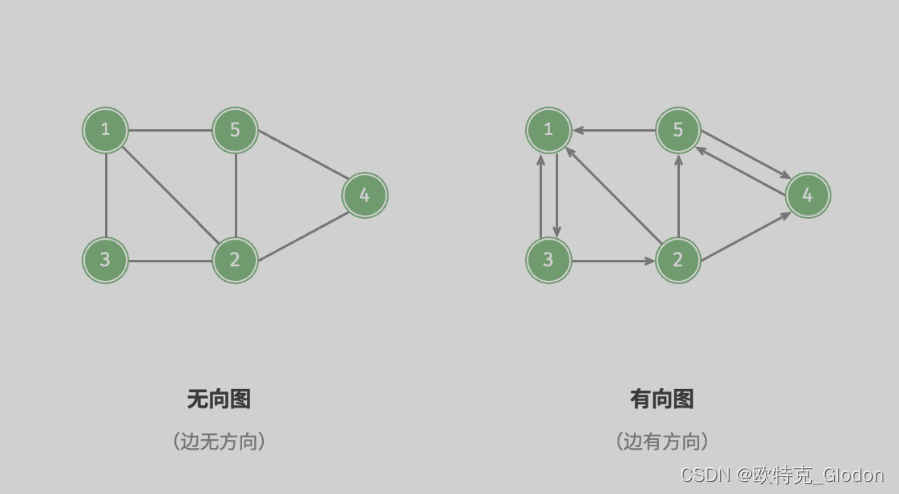
1)根据边是否具有方向,可分为无向图(undirected graph)和有向图(directed graph),如图 9-2 所示。
- 在无向图中,边表示两顶点之间的“双向”连接关系,例如微信或 QQ 中的“好友关系”。
- 在有向图中,边具有方向性,即两个方向的边是相互独立的,例如微博或抖音上的“关注”与“被关注”关系。
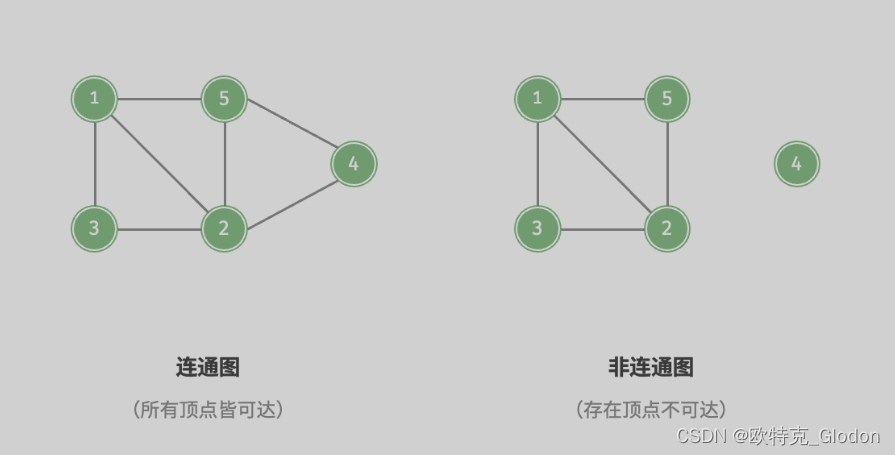
2)根据所有顶点是否连通,可分为连通图(connected graph)和非连通图(disconnected graph),如图所示。
- 对于连通图,从某个顶点出发,可以到达其余任意顶点。
- 对于非连通图,从某个顶点出发,至少有一个顶点无法到达。
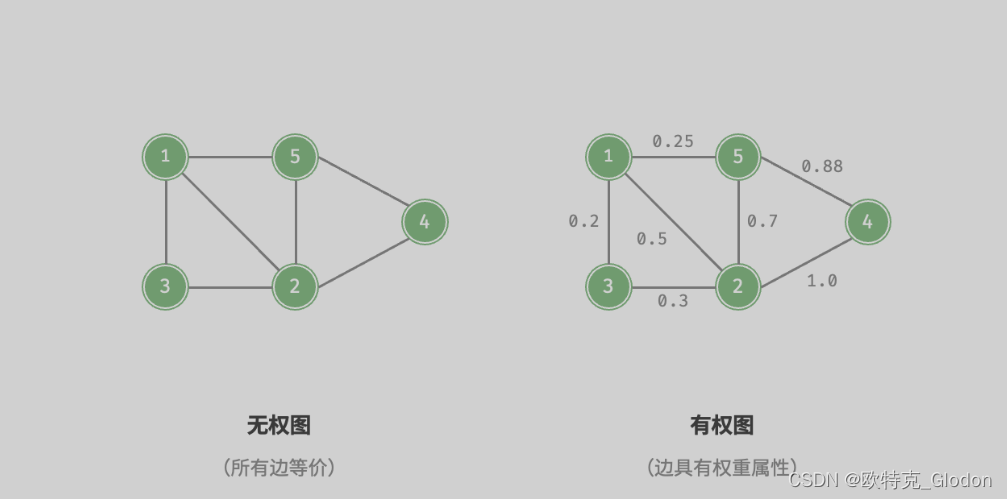
3)可以为边添加“权重”变量,从而得到如图 9-4 所示的有权图(weighted graph)。例如在《王者荣耀》等手游中,系统会根据共同游戏时间来计算玩家之间的“亲密度”,这种亲密度网络就可以用有权图来表示。
3、图的常用术语
图数据结构包含以下常用术语。
- 邻接(adjacency):当两顶点之间存在边相连时,称这两顶点“邻接”。在图 9-4 中,顶点 1 的邻接顶点为顶点 2、3、5。
- 路径(path):从顶点 A 到顶点 B 经过的边构成的序列被称为从 A 到 B 的“路径”。在图 9-4 中,边序列 1-5-2-4是顶点 1 到顶点 4 的一条路径。
- 度(degree):一个顶点拥有的边数。对于有向图,入度(in-degree)表示有多少条边指向该顶点,出度(out-degree)表示有多少条边从该顶点指出。
4、图的表示
图的常用表示方式包括“邻接矩阵”和“邻接表”。以下使用无向图进行举例。
4.1 邻接矩阵
设图的顶点数量为 n,邻接矩阵(adjacency matrix)使用一个 n*n大小的矩阵来表示图,每一行(列)代表一个顶点,矩阵元素代表边,用 1或 0 表示两个顶点之间是否存在边。
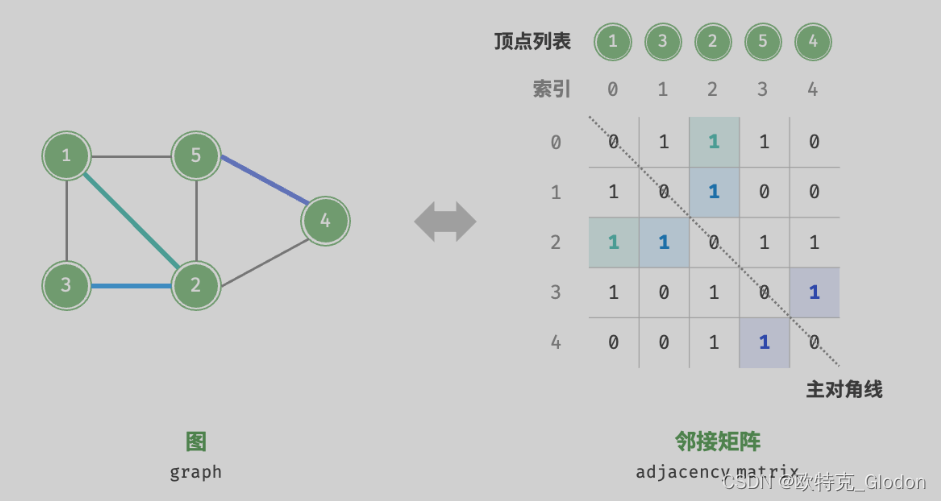
邻接矩阵具有以下特性。
- 顶点不能与自身相连,因此邻接矩阵主对角线元素没有意义。
- 对于无向图,两个方向的边等价,此时邻接矩阵关于主对角线对称。
- 将邻接矩阵的元素从1和 0替换为权重,则可表示有权图。
使用邻接矩阵表示图时,我们可以直接访问矩阵元素以获取边,因此增删查改操作的效率很高,但内存占用较多。
4.2 邻接表
邻接表(adjacency list)使用n个链表来表示图,链表节点表示顶点。第i个链表对应顶点i,其中存储了该顶点的所有邻接顶点(与该顶点相连的顶点)。下图展示了一个使用邻接表存储的图的示例。
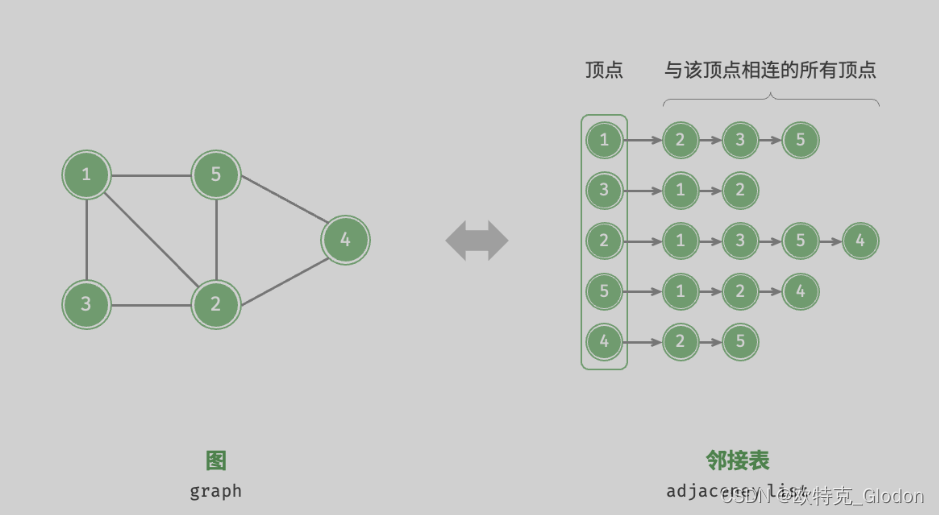
邻接表仅存储实际存在的边,而边的总数通常远小于 n² ,因此它更加节省空间。然而,在邻接表中需要通过遍历链表来查找边,因此其时间效率不如邻接矩阵。
5、图的基础实现
5.1 基于邻接矩阵的实现
给定一个顶点数量为n的无向图,则各种操作的实现方式如下:
- 初始化
- 添加或删除边
- 添加删除顶点
/* 基于邻接矩阵实现的无向图类 */ class GraphAdjMat { vector<int> vertices; // 顶点列表,元素代表“顶点值”,索引代表“顶点索引” vector<vector<int>> adjMat; // 邻接矩阵,行列索引对应“顶点索引” public: /* 构造方法 */ GraphAdjMat(const vector<int> &vertices, const vector<vector<int>> &edges) { // 添加顶点 for (int val : vertices) { addVertex(val); } // 添加边 // 请注意,edges 元素代表顶点索引,即对应 vertices 元素索引 for (const vector<int> &edge : edges) { addEdge(edge[0], edge[1]); } } /* 获取顶点数量 */ int size() const { return vertices.size(); } /* 添加顶点 */ void addVertex(int val) { int n = size(); // 向顶点列表中添加新顶点的值 vertices.push_back(val); // 在邻接矩阵中添加一行 adjMat.emplace_back(vector<int>(n, 0)); // 在邻接矩阵中添加一列 for (vector<int> &row : adjMat) { row.push_back(0); } } /* 删除顶点 */ void removeVertex(int index) { if (index >= size()) { throw out_of_range("顶点不存在"); } // 在顶点列表中移除索引 index 的顶点 vertices.erase(vertices.begin() + index); // 在邻接矩阵中删除索引 index 的行 adjMat.erase(adjMat.begin() + index); // 在邻接矩阵中删除索引 index 的列 for (vector<int> &row : adjMat) { row.erase(row.begin() + index); } } /* 添加边 */ // 参数 i, j 对应 vertices 元素索引 void addEdge(int i, int j) { // 索引越界与相等处理 if (i < 0 || j < 0 || i >= size() || j >= size() || i == j) { throw out_of_range("顶点不存在"); } // 在无向图中,邻接矩阵关于主对角线对称,即满足 (i, j) == (j, i) adjMat[i][j] = 1; adjMat[j][i] = 1; } /* 删除边 */ // 参数 i, j 对应 vertices 元素索引 void removeEdge(int i, int j) { // 索引越界与相等处理 if (i < 0 || j < 0 || i >= size() || j >= size() || i == j) { throw out_of_range("顶点不存在"); } adjMat[i][j] = 0; adjMat[j][i] = 0; } /* 打印邻接矩阵 */ void print() { cout << "顶点列表 = "; printVector(vertices); cout << "邻接矩阵 =" << endl; printVectorMatrix(adjMat); } };

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
5.2 基于邻接表的实现
/* 基于邻接表实现的无向图类 */ class GraphAdjList { public: // 邻接表,key:顶点,value:该顶点的所有邻接顶点 unordered_map<Vertex *, vector<Vertex *>> adjList; /* 在 vector 中删除指定节点 */ void remove(vector<Vertex *> &vec, Vertex *vet) { for (int i = 0; i < vec.size(); i++) { if (vec[i] == vet) { vec.erase(vec.begin() + i); break; } } } /* 构造方法 */ GraphAdjList(const vector<vector<Vertex *>> &edges) { // 添加所有顶点和边 for (const vector<Vertex *> &edge : edges) { addVertex(edge[0]); addVertex(edge[1]); addEdge(edge[0], edge[1]); } } /* 获取顶点数量 */ int size() { return adjList.size(); } /* 添加边 */ void addEdge(Vertex *vet1, Vertex *vet2) { if (!adjList.count(vet1) || !adjList.count(vet2) || vet1 == vet2) throw invalid_argument("不存在顶点"); // 添加边 vet1 - vet2 adjList[vet1].push_back(vet2); adjList[vet2].push_back(vet1); } /* 删除边 */ void removeEdge(Vertex *vet1, Vertex *vet2) { if (!adjList.count(vet1) || !adjList.count(vet2) || vet1 == vet2) throw invalid_argument("不存在顶点"); // 删除边 vet1 - vet2 remove(adjList[vet1], vet2); remove(adjList[vet2], vet1); } /* 添加顶点 */ void addVertex(Vertex *vet) { if (adjList.count(vet)) return; // 在邻接表中添加一个新链表 adjList[vet] = vector<Vertex *>(); } /* 删除顶点 */ void removeVertex(Vertex *vet) { if (!adjList.count(vet)) throw invalid_argument("不存在顶点"); // 在邻接表中删除顶点 vet 对应的链表 adjList.erase(vet); // 遍历其他顶点的链表,删除所有包含 vet 的边 for (auto &adj : adjList) { remove(adj.second, vet); } } /* 打印邻接表 */ void print() { cout << "邻接表 =" << endl; for (auto &adj : adjList) { const auto &key = adj.first; const auto &vec = adj.second; cout << key->val << ": "; printVector(vetsToVals(vec)); } } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
6、图的遍历
树代表的是“一对多”的关系,而图则具有更高的自由度,可以表示任意的“多对多”关系。因此,我们可以把树看作图的一种特例。显然,树的遍历操作也是图的遍历操作的一种特例。
图和树都需要应用搜索算法来实现遍历操作。图的遍历方式也可分为两种:广度优先遍历和深度优先遍历。
6.1 广度优先遍历BFS
广度优先遍历是一种由近及远的遍历方式,从某个节点出发,始终优先访问距离最近的顶点,并一层层向外扩张。如图所示,从左上角顶点出发,首先遍历该顶点的所有邻接顶点,然后遍历下一个顶点的所有邻接顶点,以此类推,直至所有顶点访问完毕。
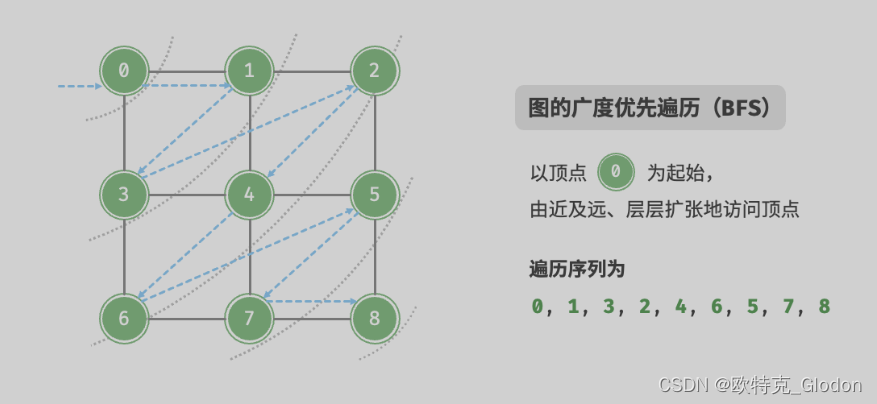
BFS算法通常借助队列来实现,代码如下所示。队列具有“先入先出”的性质,这与 BFS 的“由近及远”的思想异曲同工。
- 将遍历起始顶点 startVet 加入队列,并开启循环。
- 在循环的每轮迭代中,弹出队首顶点并记录访问,然后将该顶点的所有邻接顶点加入到队列尾部。
- 循环步骤 2. ,直到所有顶点被访问完毕后结束。
- 为了防止重复遍历顶点,我们需要借助一个哈希集合 visited 来记录哪些节点已被访问。
/* 广度优先遍历 */ // 使用邻接表来表示图,以便获取指定顶点的所有邻接顶点 vector<Vertex *> graphBFS(GraphAdjList &graph, Vertex *startVet) { // 顶点遍历序列 vector<Vertex *> res; // 哈希集合,用于记录已被访问过的顶点 unordered_set<Vertex *> visited = {startVet}; // 队列用于实现 BFS queue<Vertex *> que; que.push(startVet); // 以顶点 vet 为起点,循环直至访问完所有顶点 while (!que.empty()) { Vertex *vet = que.front(); que.pop(); // 队首顶点出队 res.push_back(vet); // 记录访问顶点 // 遍历该顶点的所有邻接顶点 for (auto adjVet : graph.adjList[vet]) { if (visited.count(adjVet)) continue; // 跳过已被访问的顶点 que.push(adjVet); // 只入队未访问的顶点 visited.emplace(adjVet); // 标记该顶点已被访问 } } // 返回顶点遍历序列 return res; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
6.2 深度优先遍历DFS
深度优先遍历是一种优先走到底、无路可走再回头的遍历方式。如图 9-11 所示,从左上角顶点出发,访问当前顶点的某个邻接顶点,直到走到尽头时返回,再继续走到尽头并返回,以此类推,直至所有顶点遍历完成。
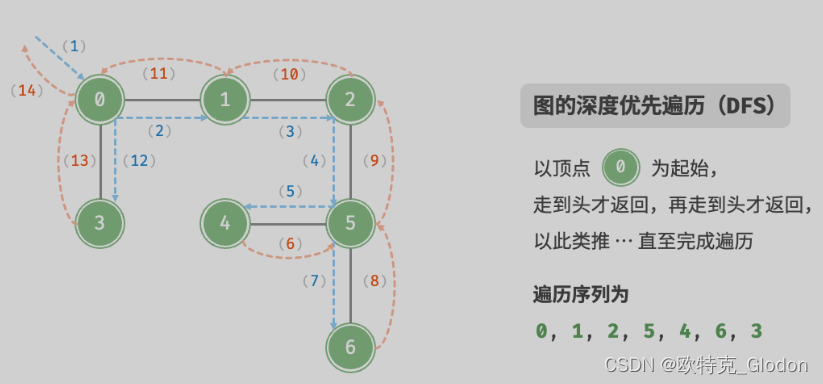
这种“走到尽头再返回”的算法范式通常基于递归来实现。与广度优先遍历类似,在深度优先遍历中,我们也需要借助一个哈希集合 visited 来记录已被访问的顶点,以避免重复访问顶点。
/* 深度优先遍历辅助函数 */ void dfs(GraphAdjList &graph, unordered_set<Vertex *> &visited, vector<Vertex *> &res, Vertex *vet) { res.push_back(vet); // 记录访问顶点 visited.emplace(vet); // 标记该顶点已被访问 // 遍历该顶点的所有邻接顶点 for (Vertex *adjVet : graph.adjList[vet]) { if (visited.count(adjVet)) continue; // 跳过已被访问的顶点 // 递归访问邻接顶点 dfs(graph, visited, res, adjVet); } } /* 深度优先遍历 */ // 使用邻接表来表示图,以便获取指定顶点的所有邻接顶点 vector<Vertex *> graphDFS(GraphAdjList &graph, Vertex *startVet) { // 顶点遍历序列 vector<Vertex *> res; // 哈希集合,用于记录已被访问过的顶点 unordered_set<Vertex *> visited; dfs(graph, visited, res, startVet); return res; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

