
- 1八分钟就看懂 | 推荐系统 (协同过滤) 原来这么简单_协同过滤类推荐系统
- 2LibCurl HTTP部分详细介绍_libcurl设置 协议头
- 3每天看一个fortran文件(7)之寻找cesm边界层高度计算代码
- 4python实现强化学习_python中强化学习的概念
- 5头歌实践教学平台数据库原理与应用实训答案_头歌实践教学平台答案
- 6MySQL 自动根据年份动态创建范围分区_mysql 按年分区
- 7《自然语言处理的前沿探索:深度学习与大数据引领技术风潮》_采用最前沿的自然语言处理和大数据技术是什么
- 8使用Python的requests库,轻松实现网络爬虫和数据抓取_requests.models.response
- 9SQL语句,查询操作_sql 将最高工资的人和最低工资的人 查询出来
- 10Android 7.0中FileProvider
VALSE 2024特邀报告内容解析|多模态视觉融合方法:是否存在性能极限?
赞
踩
2024年视觉与学习青年学者研讨会(VALSE 2024)于5月5日到7日在重庆悦来国际会议中心举行。本公众号将全方位地对会议的热点进行报道,方便广大读者跟踪和了解人工智能的前沿理论和技术。欢迎广大读者对文章进行关注、阅读和转发。文章是对报告人演讲内容的理解或转述,可能与报告人的原意有所不同,敬请读者理解;如报告人认为文章与自己报告的内容差别较大,可以联系公众号删除。
江南大学吴小俊教授做了特邀报告《多模态视觉融合方法:是否存在性能极限?》,本文对其报告的内容进行了总结。
1.报告人人简介
吴小俊,国际模式识别协会会士(IAPR Fellow)、亚太人工智能协会会士(AAIA Fellow)、江南大学至善教授,主要从事模式识别与人工智能方面的研究。
2.报告概览
视觉融合是计算机视觉的重要研究方向。本报告以智慧城市为背景,介绍面向智慧城市的多模态视觉融合方法与研究进展。首先对智慧城市和深度学习进行简单回顾;然后介绍多模态视觉融合的主要框架、方法和研究进展。针对目前性能最好的视觉融合算法,探讨一种增强视觉融合性能的普适方法。同时,本报告将介绍视觉融合在图像质量增强、人脸特征点定位、目标检测、跟踪与识别、行为识别以及融合与视觉上下游任务互促等方面的应用研究。
3.内容整理
吴小俊教授的报告主要包含了如下四个部分,下面逐一加以介绍。
(1)深度学习与视觉融合简介
1)对深度学习的发展进行了总结。如图1所示,简洁明了的归纳了深度学习的发展历程,并对经典深度学习模型进行简要介绍。同时,还给出了深度学习面临的基本挑战,如数据方面存在小样本量问题和样本分布偏倚,深度学习在处理在线学习和无监督学习时存在困难,以及在表示不确定性方面表现不佳、容易受到对抗性示例的影响、黑盒问题导致深度学习模型缺乏解释性、参数数量庞大、存储需求高和计算复杂度高等。
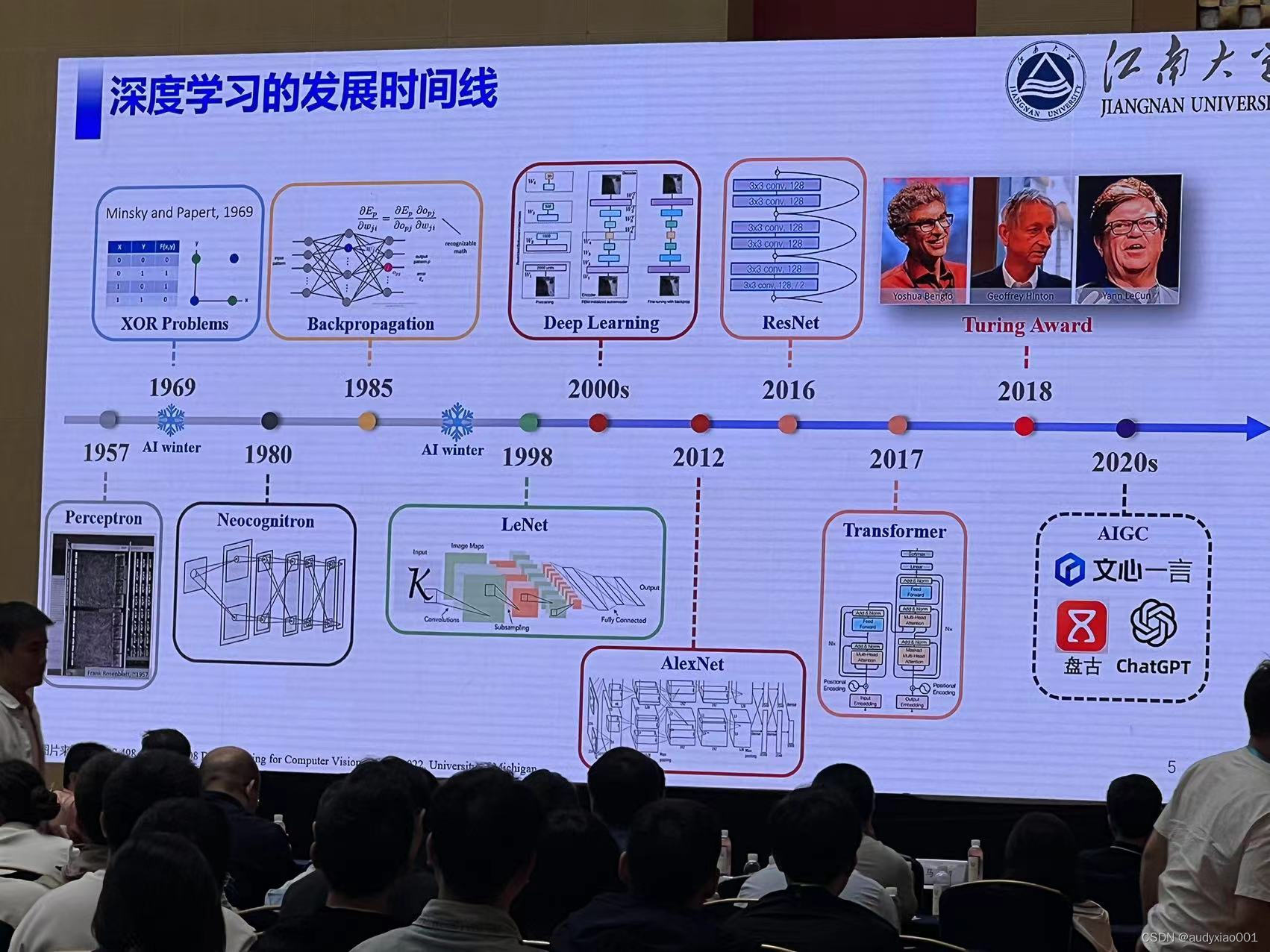
图 1 深度学习的发展历程
2)对视觉融合展开介绍。视觉融合旨在整合多源输入,生成综合性视觉信息,涵盖多模态、数字摄影、遥感等多类型融合任务,以提取更多互补特征。同时报告也给出了视觉融合的发展历程,如图2所示。报告指出视觉融合在图像增强、目标识别、态势评估、智能监控、机器人、人脸识别和医学图像分析等领域有广泛应用。
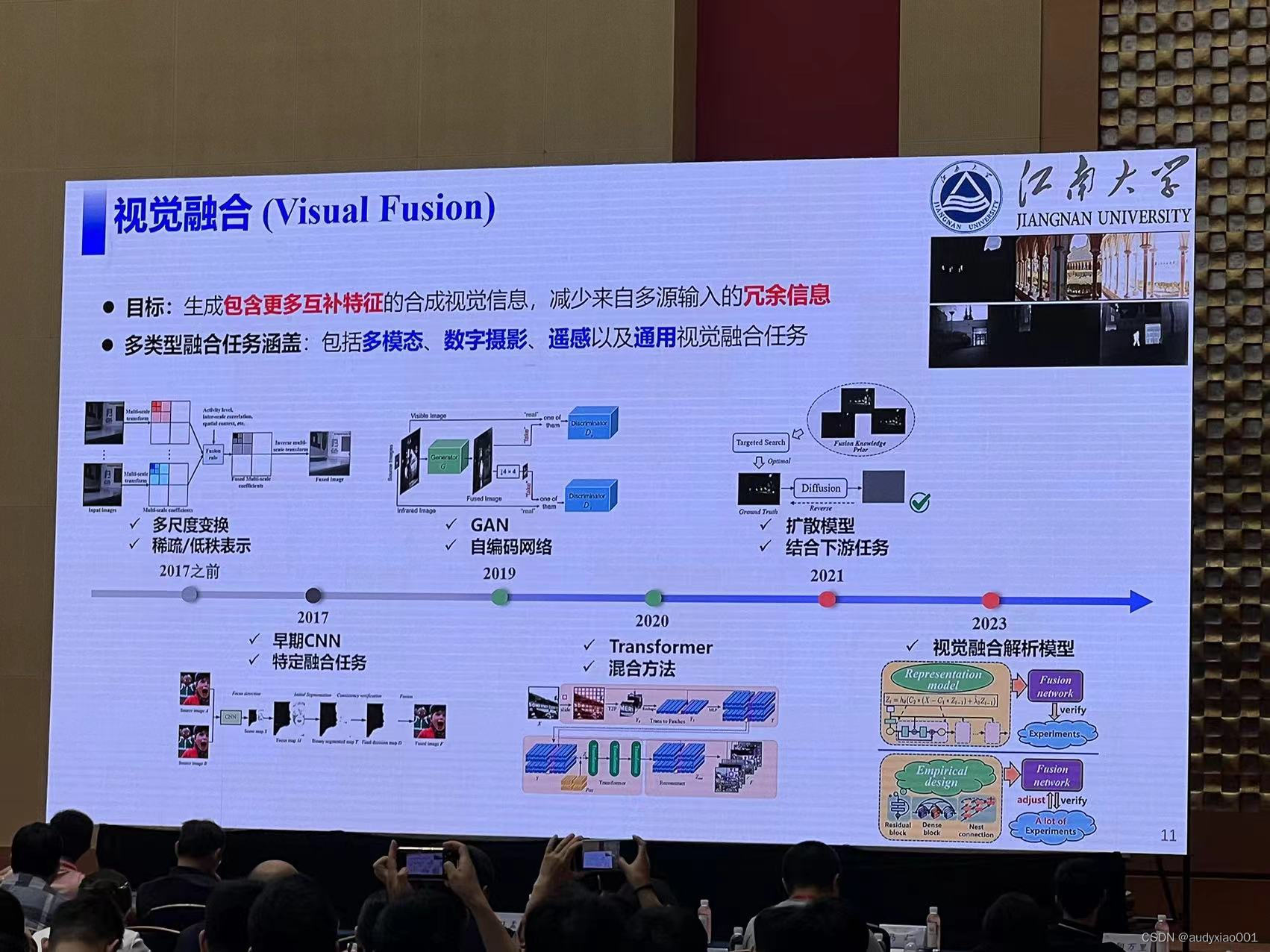
图 2 视觉融合的发展历程
(2)视觉融合方法的研究进展
1)首先讨论了视觉融合的非深度方法,包括拉普拉斯特征金字塔方法、基于频域变换的方法(如小波分析、小波包分析、复小波分析、Gabor变换、形态小波分析、曲线和轮变换)、基于代数变换的方法(如PCA、ICA、BT、HIS)、基于人工神经网络的方法、基于区域的多特征方法以及基于上下文的表征学习方法。
2)进一步介绍了视觉融合的深度方法,包括视觉融合自编码网络框架(如DenseFuse、NestFuse、RFN-Nest、图像/视频风格迁移)、视觉融合CNN框架(如预训练模型、CNN-MF、MuFusion)、视觉融合GAN框架(如V FusionGan、DDcGAN)、混合模型框架(如vSwinFusion、TGFuse、CrossFuse)、视觉融合扩散模型框架(如YDifIE、GMMT)以及视觉融合解析模型如(MDLatLRR、LRRNet)。
(3)视觉融合与下游任务的相互促进
1)首先,在配准和融合方面,视觉融合技术可以帮助提高图像或视频数据的配准质量和融合效果,从而增强下游任务的准确性和可靠性。
2)其次,在融合、分割、检测和跟踪等任务中,视觉融合可以为下游任务提供更丰富、更综合的信息,有助于提高这些任务的性能和效率。
3)此外,视觉融合还可以与其他模态数据进行互动,例如视觉与文本的融合。
(4)视觉融合方向的应用与总结
1)报告展示了一些视觉融合方面的成果,包括医学图像处理、多模态数据集(RGBD1K)、反无人机竞赛、VOT视觉目标跟踪竞赛、行为识别竞赛和视觉融合设备等。
2)报告指出尽管存在多种框架,但尚无通用框架。深度学习网络的自动设计为特定领域提供了借鉴,性能可能无极限。黎曼流形中的视觉信息处理将至关重要。未来,视觉融合与下游任务的协同设计或成为主流方向。

