
- 1组件的概念理解
- 2Docker的一个简单例子(二)_最简单的docker案例
- 3服务器端通过nginx部署项目(含websoket)_websocket服务端配置项
- 4SpringBoot + RabbitMQ 死信队列中出现Execution of Rabbit message listener failed.的错误解决_execution of rabbit message listener failed, and t
- 5【常见总线接口协议】学习笔记1_axi ahb spi iic
- 6自然语言处理(NLP)-第三方库(工具包):NLTK(更适合英文数据集,在中文数据集上效果不好)【命名实体识别、分词、词性标注、依存句法分析、语义角色标注、语料库】_nltk库命名实体识别器
- 7谷歌裁员1.2万人,CEO年薪达15亿,网友:“地表最强 CEO !”
- 8java获取当前的具体时间(年月日时分秒)_java获取当前时间年月日时分秒
- 9Hexo bamboo主题配置(三)_hexo theme bamboo
- 10启动rabbitmq_rabbirmq启动
【无标题】人工智能_人工智能的研究背景
赞
踩
《人工智能》课程结课报告
班级:大数据管理与应用191 学号:190215133 姓名:胡方宇
摘要:随着科学技术的不断发展,人们越来越希望自己生活在一个安全的环境下,尤其是自己的人身安全以及财产安全,人脸识别技术孕育而生。人脸识别是生物识别技术的一一种形式,它涉及模式识别,计算机视觉,心理学及生理学及认知科学等方面,在计算机的辅助下实现身份识别,是基于人独有的特征进行身份验证的有效手段。人脸识别也是指对于给定一幅人脸作为输入,在待识别的数据库中寻找匹配,在数据库中找到与输人人脸致的人脸图像。
关键词:人工智能;人脸识别
第1章 绪论
1.1 研究背景与意义
在处于高速发展的现代社会中,“快速、便捷、安全”成为当代社会的代名词。随着计算机视觉技术和光电技术的快速发展,人们越来越希望自己生活在一个安全的环境下,尤其是自
己的人身安全以及财产安全。其中人工智能技术的开发和运用成为重点和热点。在人工智能领域中,人脸识别技术的研究已经成为一个热门研究领域。人脸识别技术具有广泛的应用前景,在国家安全、军事安全和公共安全领域智能门禁、智能视频监控、公安布控、海关身份验证、司机驾照验证等都是典型的应用;在民事和经济领域,各类银行卡、金融卡、信用卡、储蓄卡的持卡人的身份验证,社会保险人的身份验证等都具有重要的应用价值。
1.2 国内外研究现状
人脸识别系统的研究始于20世纪60年代,80年代后随着计算机技术和光学成像技术的发展得到提高,而真正进入初级的应用阶段则在90年后期,并且以美国、德国和日本的技术实现为主;人脸识别系统成功的关键在于是否拥有尖端的核心算法,并使识别结果具有实用化的识别率和识别速度;“人脸识别系统”集成了人工智能、机器识别、机器学习、模型理论、专家系统、视频图像处理等多种专业技术,同时需结合中间值处理的理论与实现,是生物特征识别的最新应用,其核心技术的实现,展现了弱人工智能向强人工智能的转化。【2】近十年以来,人脸识别已经发展成为最热门的生物特征识别技术(基于几何特征的人脸识别、基于子空间的人脸识别、基于弹性图匹配的人脸识别:Geroghiades等人提出的基于光照锥模型的多姿态、多光照条件人脸识别方法,应用于以支持向量机为代表的统计学习理论)。目前,很多国家展开了有关人脸识别的研究,主要有美国、欧洲、法国,芬兰、瑞士、日本等。另外,基于AdaBoost的人脸识别算法、基于彩色信息的方法、基于形状分析的方法以及多模态信息融合方法也有大量研究与实验。国内于二十世纪九十年代开始对人脸识别进行研究。
第2章 概要设计
2.1内容与要求
内容:设计一个简单的人脸识别程序,可以识别图像中的人脸。
要求:
- 输入图片地址,显示该图片。显示该图片所对应的人命
2. 允许连续识别,即提示用户是否继续识别,如果用户选择是,则允许用户上传图片,并再次进行识别。
3. 识别结束后,需要把识别后的内容保存到文本文件中。
4. 使用Python进行程序设计,在AI Studio进行调试运行。
2.2基础知识
卷积神经网络:卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。卷积神经网络具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类。随着深度学习理论的提出和数值计算设备的改进,卷积神经网络得到了快速发展,并被应用于计算机视觉、自然语言处理等领域。卷积神经网络的结构分为输入层、隐藏层和输出层。“在卷积神经网络中,网络结构能较好适应图像的结构;同时进行特征提取和分类,使得特征提取有助于特征分类;权值共享可以减少网络的训练参数,使得神经网络结构变得更简单、适应性更强要训练的权值参数的个数.由于同一特征通道上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。”【3】
第3章 详细设计
- 增加训练的轮数
测试的损失率降低,准确率增加。
- 增加每个人照片数
准确率增加
第4章 使用说明与运行结果

第5章 总结与展望
目前,人脸识别技术已经在很多领域上有了长足的发展,比如身份证、银行卡等等。而且随着科学技术的不断发展,人脸识别技术也将会获得更快的发展。可以帮助人们在各个领域实现信息安全。但是人脸识别技术也有很多的不足之处:识别精度低于指纹和虹膜、随着情况复杂检测率较低、由于人脸特征被泄露而对人的隐私造成威胁等等。因此需要对增加人脸识别的精度,同时增加其保密性。随着精度和保密性的不断提高,人脸识别技术会越来越被人们所接纳和广泛使用。
致 谢
经过十周的学习,我学习了人工智能的入门知识。这十周里,老师认真负责的讲好了每一堂课,每次都让我受益匪浅,学到了很多知识,依靠这些知识,我才能顺利的完成结课报告。在这最后,我真诚的感谢老师的细心指导。
参考文献
[1] 王万良.人工智能导论(第3版)[M].北京:高等教育出版社,2011.2
[2]“人工智能”,百度百科,https://baike.baidu.com/item/%E4%BA%BA%E8%84%B8%E8%AF%86%E5%88%AB/4463435?fr=aladdin#1
[3]“卷积神经网络总结”,百度文库,卷积神经网络总结 - 百度文库
附 录
# 设置要生成文件的路
data_root_path = '/home/aistudio/images/face'
# 所有类别的信息 class_detail = []
# 获取所有类别保存的文件夹名称,这里是['jiangwen', 'pengyuyan', 'zhangziyi']
class_dirs = os.listdir(data_root_path)
# 类别标签
class_label = 0
# 获取总类别的名称
father_paths = data_root_path.split('/')
#['', 'home', 'aistudio', 'images', 'face']
while True:
if father_paths[father_paths.__len__() - 1] == '':
del father_paths[father_paths.__len__() - 1]
else: break father_path = father_paths[father_paths.__len__() - 1]
# 把生产的数据列表都放在自己的总类别文件夹中
data_list_path = '/home/aistudio/%s/' % father_path
# 如果不存在这个文件夹,就创建
isexist = os.path.exists(data_list_path)
if not isexist: os.makedirs(data_list_path) # 清空原来的数据
with open(data_list_path + "test.list", 'w') as f:
pass with open(data_list_path + "trainer.list", 'w')
as f: pass
# 总的图像数量
all_class_images = 0
# 读取每个类别
for class_dir in class_dirs:
# 每个类别的信息
class_detail_list = {} test_sum = 0 trainer_sum = 0
# 统计每个类别有多少张图片
class_sum = 0
# 获取类别路径
path = data_root_path + "/" + class_dir
# 获取所有图片
img_paths = os.listdir(path)
for img_path in img_paths:
# 遍历文件夹下的每个图片
name_path = path + '/' + img_path
# 每张图片的路径
if class_sum % 10 == 0:
# 每10张图片取一个做测试数据
test_sum += 1
#test_sum测试数据的数目
with open(data_list_path + "test.list", 'a')
as f: f.write(name_path + "\t%d" % class_label + "\n")
#class_label 标签:0,1,2
else: trainer_sum += 1
#trainer_sum测试数据的数目
with open(data_list_path + "trainer.list", 'a')
as f: f.write(name_path + "\t%d" % class_label + "\n"
)#class_label 标签:0,1,2
class_sum += 1
#每类图片的数目
all_class_images += 1
#所有类图片的数目
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir
#类别名称,如jiangwen
class_detail_list['class_label'] = class_label
#类别标签,0,1,2
class_detail_list['class_test_images'] = test_sum
#该类数据的测试集数目
class_detail_list['class_trainer_images'] = trainer_sum
#该类数据的训练集数目
class_detail.append(class_detail_list) class_label += 1
#class_label 标签:0,1,2 # 获取类别数量
all_class_sum = class_dirs.__len__()
# 说明的json文件信息
readjson = {} readjson['all_class_name'] = father_path
#文件父目录
readjson['all_class_sum'] = all_class_sum
# readjson['all_class_images'] = all_class_images readjson['class_detail'] = class_detail jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))
with open(data_list_path + "readme.json",'w')
as f: f.write(jsons)
print ('生成数据列表完成!')
import paddle
import paddle.fluid
as fluid
import numpy
import sys
from multiprocessing
import cpu_count
import matplotlib.pyplot
as plt
# 定义训练的mapper # train_mapper函数的作用是用来对训练集的图像进行处理修剪和数组变换,返回img数组和标签
# sample是一个python元组,里面保存着图片的地址和标签。 ('../images/face/zhangziyi/20181206145348.png', 2)
def train_mapper(sample): img, label = sample
# 进行图片的读取,由于数据集的像素维度各不相同,需要进一步处理对图像进行变换
img = paddle.dataset.image.load_image(img)
#进行了简单的图像变换,这里对图像进行crop修剪操作,输出img的维度为(3, 100, 100)
img = paddle.dataset.image.simple_transform(im=img,
#输入图片是HWC
resize_size=100,
# 剪裁图片
crop_size=100, is_color=True,
#彩色图像
is_train=True)
#将img数组进行进行归一化处理,得到0到1之间的数值
img= img.flatten().astype('float32')/255.0 return img, label
# 对自定义数据集创建训练集train的reader
def train_r(train_list, buffered_size=1024):
def reader(): with open(train_list, 'r')
as f:
# 将train.list里面的标签和图片的地址方法一个list列表里面,中间用\t隔开' #../images/face/jiangwen/0b1937e2-f929-11e8-8a8a-005056c00008.jpg\t0'
lines = [line.strip()
for line in f]
for line in lines:
# 图像的路径和标签是以\t来分割的,所以我们在生成这个列表的时候,使用\t就可以了
img_path, lab = line.strip().split('\t')
yield img_path, int(lab)
# 创建自定义数据训练集的train_reader
return paddle.reader.xmap_readers(train_mapper, reader,cpu_count(), buffered_size)
# sample是一个python元组,里面保存着图片的地址和标签。 ('../images/face/zhangziyi/20181206145348.png', 2)
def test_mapper(sample): img, label = sample img = paddle.dataset.image.load_image(img) img = paddle.dataset.image.simple_transform(im=img, resize_size=100, crop_size=100, is_color=True, is_train=False) img= img.flatten().astype('float32')/255.0 return img, label
# 对自定义数据集创建验证集test的reader
def test_r(test_list, buffered_size=1024):
def reader():
with open(test_list, 'r') as f: lines = [line.strip()
for line in f]
for line in lines:
#图像的路径和标签是以\t来分割的,所以我们在生成这个列表的时候,使用\t就可以了
img_path, lab = line.strip().split('\t')
yield img_path, int(lab)
return paddle.reader.xmap_readers(test_mapper, reader,cpu_count(), buffered_size)
BATCH_SIZE = 32
# 把图片数据生成reader
trainer_reader = train_r(train_list="/home/aistudio/face/trainer.list")
train_reader = paddle.batch( paddle.reader.shuffle( reader=trainer_reader,buf_size=300),
batch_size=BATCH_SIZE) tester_reader = test_r(test_list="/home/aistudio/face/test.list")
test_reader = paddle.batch( tester_reader, batch_size=BATCH_SIZE)
train_data = paddle.batch(trainer_reader, batch_size=3)
sampledata=next(train_data())
print(sampledata)
def convolutional_neural_network(image, type_size):
# 第一个卷积--池化层
conv_pool_1 = fluid.nets.simple_img_conv_pool(input=image,
# 输入图像
filter_size=3,
# 滤波器的大小
num_filters=32,
# filter 的数量。它与输出的通道相同
pool_size=2,
# 池化层大小2*2
pool_stride=2,
# 池化层步长 act='relu')
# 激活类型 # Dropout主要作用是减少过拟合,随机让某些权重不更新 # Dropout是一种正则化技术,通过在训练过程中阻止神经元节点间的联合适应性来减少过拟合。
# 根据给定的丢弃概率dropout随机将一些神经元输出设置为0,其他的仍保持不变。
drop = fluid.layers.dropout(x=conv_pool_1, dropout_prob=0.5)
# 第二个卷积--池化层
conv_pool_2 = fluid.nets.simple_img_conv_pool(input=drop, filter_size=3, num_filters=64, pool_size=2, pool_stride=2, act='relu')
# 减少过拟合,随机让某些权重不更新
drop = fluid.layers.dropout(x=conv_pool_2, dropout_prob=0.5)
# 第三个卷积--池化层
conv_pool_3 = fluid.nets.simple_img_conv_pool(input=drop, filter_size=3, num_filters=64, pool_size=2, pool_stride=2, act='relu')
# 减少过拟合,随机让某些权重不更新
drop = fluid.layers.dropout(x=conv_pool_3, dropout_prob=0.5)
# 全连接层
fc = fluid.layers.fc(input=drop, size=512, act='relu')
# 减少过拟合,随机让某些权重不更新
drop = fluid.layers.dropout(x=fc, dropout_prob=0.5)
# 输出层 以softmax为激活函数的全连接输出层,输出层的大小为图像类别type_size个数
predict = fluid.layers.fc(input=drop,size=type_size,act='softmax')
return predict
def vgg_bn_drop(image, type_size):
def conv_block(ipt, num_filter, groups, dropouts):
return fluid.nets.img_conv_group( input=ipt,
# 具有[N,C,H,W]格式的输入图像
pool_size=2, pool_stride=2, conv_num_filter=[num_filter] * groups,
# 过滤器个数
conv_filter_size=3,
# 过滤器大小
conv_act='relu', conv_with_batchnorm=True,
# 表示在 Conv2d Layer 之后是否使用 BatchNorm
conv_batchnorm_drop_rate=dropouts,
# 表示 BatchNorm 之后的 Dropout Layer 的丢弃概率 pool_type='max')
# 最大池化
conv1 = conv_block(image, 64, 2, [0.0, 0]) conv2 = conv_block(conv1, 128, 2, [0.0, 0]) conv3 = conv_block(conv2, 256, 3, [0.0, 0.0, 0]) conv4 = conv_block(conv3, 512, 3, [0.0, 0.0, 0]) conv5 = conv_block(conv4, 512, 3, [0.0, 0.0, 0]) drop = fluid.layers.dropout(x=conv5, dropout_prob=0.5) fc1 = fluid.layers.fc(input=drop, size=512, act=None) bn = fluid.layers.batch_norm(input=fc1, act='relu') drop2 = fluid.layers.dropout(x=bn, dropout_prob=0.0) fc2 = fluid.layers.fc(input=drop2, size=512, act=None) predict = fluid.layers.fc(input=fc2, size=type_size, act='softmax')
return predict
image = fluid.layers.data(name='image', shape=[3, 100, 100], dtype='float32')#[3, 100, 100],表示为三通道,100*100的RGB图
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
print('image_shape:',image.shape)
# ##### 获取分类器,用cnn或者vgg网络进行分类type_size要和训练的类别一致 ########
predict = convolutional_neural_network(image=image, type_size=4)
# predict = vgg_bn_drop(image=image, type_size=4)
# 获取损失函数和准确率
cost = fluid.layers.cross_entropy(input=predict, label=label)
# 计算cost中所有元素的平均值
avg_cost = fluid.layers.mean(cost)
#计算准确率
accuracy = fluid.layers.accuracy(input=predict, label=label)
# 定义优化方法
optimizer = fluid.optimizer.Adam(learning_rate=0.001) # Adam是一阶基于梯度下降的算法,基于自适应低阶矩估计该函数实现了自适应矩估计优化器
optimizer.minimize(avg_cost) # 取局部最优化的平均损失
print(type(accuracy))
# 使用CPU进行训练
place = fluid.CPUPlace()
# 创建一个executor
exe = fluid.Executor(place)
# 对program进行参数初始化1.网络模型2.损失函数3.优化函数
exe.run(fluid.default_startup_program())
# 定义输入数据的维度,DataFeeder 负责将reader(读取器)返回的数据转成一种特殊的数据结构,使它们可以输入到 Executor
feeder = fluid.DataFeeder(feed_list=[image, label], place=place)#定义输入数据的维度,第一个是图片数据,第二个是图片对应的标签。
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
# 训练的轮数
EPOCH_NUM = 15 print('开始训练...')
#两种方法,用两个不同的路径分别保存训练的模型 # model_save_dir = "/home/aistudio/data/model_vgg" model_save_dir = "/home/aistudio/data/model_cnn"
for pass_id in range(EPOCH_NUM): train_cost = 0
for batch_id, data in enumerate(train_reader()):
#遍历train_reader的迭代器,并为数据加上索引batch_id
train_cost, train_acc = exe.run( program=fluid.default_main_program(),
#运行主程序
feed=feeder.feed(data),
#喂入一个batch的数据
fetch_list=[avg_cost, accuracy])
#fetch均方误差和准确率
all_train_iter=all_train_iter+BATCH_SIZE
all_train_iters.append(all_train_iter)
all_train_costs.append(train_cost[0])
all_train_accs.append(train_acc[0])
if batch_id % 10 == 0:
#每10次batch打印一次训练、进行一次测试
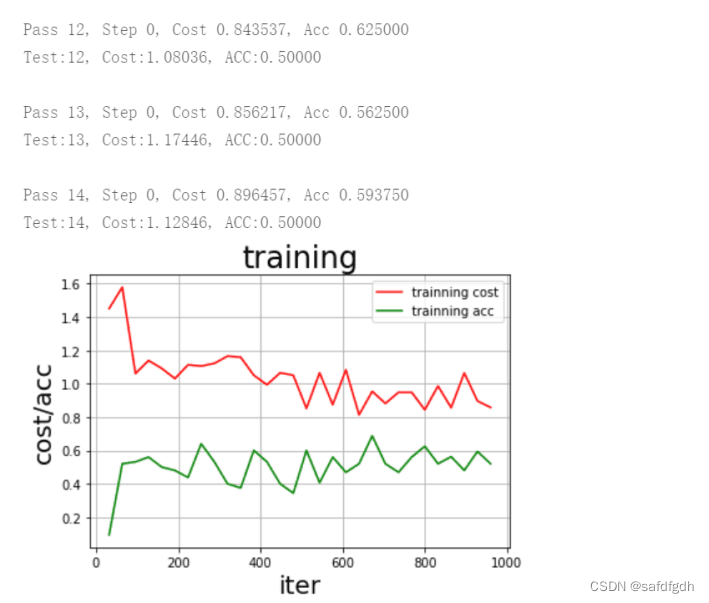
print("\nPass %d, Step %d, Cost %f, Acc %f" % (pass_id, batch_id, train_cost[0], train_acc[0]))
# 开始测试
test_accs = []
#测试的损失值
test_costs = []
#测试的准确率 # 每训练一轮 进行一次测试
for batch_id, data in enumerate(test_reader()):
# 遍历test_reader test_cost, test_acc = exe.run(program=fluid.default_main_program(),
# #运行测试主程序 feed=feeder.feed(data),
#喂入一个batch的数据 fetch_list=[avg_cost, accuracy])
#fetch均方误差、准确率 test_accs.append(test_acc[0])
#记录每个batch的误差 test_costs.append(test_cost[0])
#记录每个batch的准确率 # 求测试结果的平均值 test_cost = (sum(test_costs) / len(test_costs))
# 每轮的平均误差 test_acc = (sum(test_accs) / len(test_accs)
) # 每轮的平均准确率
print('Test:%d, Cost:%0.5f, ACC:%0.5f' % (pass_id, test_cost, test_acc))
# 如果保存路径不存在就创建
if not os.path.exists(model_save_dir): os.makedirs(model_save_dir)
# 保存训练的模型,executor 把所有相关参数保存到 dirname 中
fluid.io.save_inference_model(dirname=model_save_dir, feeded_var_names=["image"],
target_vars=[predict],
executor=exe) draw_train_process("training",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc")
print('训练模型保存完成!')
# coding:utf-8
import paddle.fluid as fluid
import numpy as np from PIL
import Image
import matplotlib.pyplot as plt
import paddle
# 使用CPU进行训练
place = fluid.CPUPlace()
# 定义一个executor
infer_exe = fluid.Executor(place) inference_scope = fluid.core.Scope()
#要想运行一个网络,需要指明它运行所在的域,确切的说: exe.Run(&scope)
#选择保存不同的训练模型
params_dirname ="/home/aistudio/data/model_cnn"
# params_dirname ='/home/aistudio/data/model_vgg'
# (1)图片预处理
def load_image(path): img = paddle.dataset.image.load_and_transform(path,100,100, False).astype('float32')
#img.shape是(3, 100, 100)
img = img / 255.0
return img infer_imgs = []
# 选择不同的图片进行预测
#infer_imgs.append(load_image('images/face/AngLee/al21.jpg')) # infer_imgs.append(load_image('images/face/CaseyAffleck/ka30.jpg')) infer_imgs.append(load_image('images/face/wu/liyifeng1.jpg')) # infer_imgs.append(load_image('/home/aistudio/images/face/qianfang/13.jpg'))
infer_imgs = np.array(infer_imgs) print('infer_imgs的维度:',infer_imgs .shape)
#fluid.scope_guard修改全局/默认作用域(scope), 运行时中的所有变量都将分配给新的scope
with fluid.scope_guard(inference_scope):
#获取训练好的模型
#从指定目录中加载 推理model(inference model)
[inference_program,
# 预测用的program
feed_target_names,
# 是一个str列表,它包含需要在推理 Program 中提供数据的变量的名称。
fetch_targets] = fluid.io.load_inference_model(params_dirname, infer_exe)
#fetch_targets:是一个 Variable 列表,从中我们可以得到推断结果。
#img = Image.open('images/face/AngLee/al21.jpg') #img = Image.open('images/face/CaseyAffleck/ka30.jpg')
img = Image.open('images/face/wu/liyifeng1.jpg')
# img = Image.open('/home/aistudio/images/face/qianfang/13.jpg')
plt.imshow(img) #根据数组绘制图像
plt.show()
#显示图像
# 开始预测
results = infer_exe.run( inference_program
, #运行预测程序 feed={feed_target_names[0]: infer_imgs},
#喂入要预测的数据 fetch_list=fetch_targets)
#得到推测结果
print('results:',np.argmax(results[0]))
# 训练数据的标签
label_list = ["CaseyAffleck","AngLee","wu","wujialong"]
print(results)
print("infer results: %s" % label_list[np.argmax(results[0])])

