
- 1触摸精灵,触动精灵,按键精灵等精灵对接本地AI免费OCR识别返回x,y中间坐标,把处理交给电脑,让手机放松,别再给打包者交钱了_触摸精灵 图像识别 文件
- 2风光储燃料电池微网仿真:并离网切换+二次调频 | 新能源并入直流母线 | 网侧采用VSG控制,风光储燃料电池微网仿真:并离网切换与二次调频,新能源直流母线集成,VSG控制实现网侧优化_新能源调频仿真搭建
- 3自然语言处理中注意力机制综述
- 4通用VS垂直,未来谁将领跑?
- 5Git:vscode内部集成的可视化git工具功能介绍和使用说明_vscode git可视化
- 6【长度测量】基于matlab机器视觉单幅图像长度测量【含Matlab源码 4055期】_matlab分析图片中线条长度
- 7二叉树第一期:树与二叉树的概念
- 8什么是会话劫持以及如何阻止它_cookie劫持如何解决
- 9【安全】linux audit审计使用入门_audit linux
- 10数据结构----排序总结_数据结构排序总结
利用sklearn库决策树模型对iris数据多分类并进行评估_利用sklearn自带的iris数据集构建决策树
赞
踩
1.导入所需要的库
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.datasets import load_iris
2.加载iris数据
- iris = load_iris()
-
- x, y = iris.data, iris.target
在这里我们输出前十行的iris.data看看
print(x[:10,:])
3.使用sklearn库对iris数据集进行乱序切分为训练集和测试集(7:3比例)
- from sklearn.model_selection import train_test_split
-
- from sklearn.metrics import classification_report
-
- x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.3)
切分训练集和测试集这里我们使用train_test_split(),test_size为测试集所占的比例。
sklearn的train_test_split()各函数参数含义解释(非常全) - The-Chosen-One - 博客园
4.使用决策树模型对测试集进行分类
- decisionTree = DecisionTreeClassifier()
-
- decisionTree.fit(x_train, y_train)#训练决策树
-
- y_predict = decisionTree.predict(x_test)#在x_test上进行测试
5.利用classification_report()对分类的结果进行评估
print(classification_report(y_test,y_predict))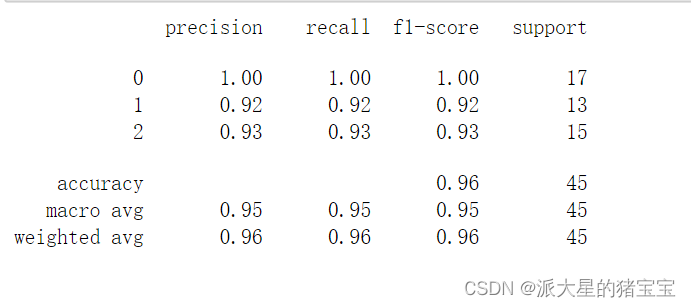
详细介绍见博客https://blog.csdn.net/weixin_48964486/article/details/122881350
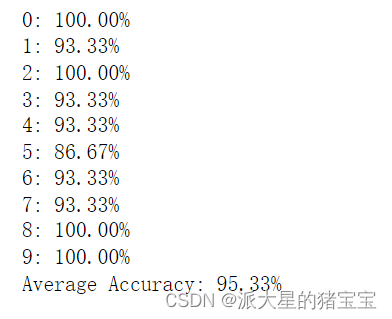
6.使用sklearn库的决策树模型对iris数据集进行10折交叉验证,评估每折的正确率,并计算平均准确率:
K折交叉验证:将训练集分成K份,每次用其中一份做测试集,其余的k-1份作为训练集,循环k次,取每次训练结果的平均值作为评分。
- from sklearn.model_selection import cross_val_score# 声明决策树模型
-
- decisionTree = DecisionTreeClassifier() #定义决策树模型
-
- # K折交叉验证(K=10)
-
- scores = cross_val_score(decisionTree,x,y,cv=10) #算出10折交叉验证每折的准确率
-
- # 打印10次准确率
-
- for i, score in enumerate(scores):
-
- print('{:d}: {:.2f}%'.format(i, 100*score))
-
- # 打印平均准确率
-
- print('Average Accuracy: {:.2f}%'.format(100*scores.mean()))

7.修改决策树模型中的参数(如criterion、max_depth、spliter等)评估10折交叉验证下的平均准确率,至少验证4组不同参数的决策树模型
- params_list = (
-
- {'criterion': 'gini', 'max_depth': None, 'splitter': 'best'},
-
- {'criterion': 'gini', 'max_depth': None, 'splitter': 'random'},
-
- {'criterion': 'entropy', 'max_depth':None,'splitter':'best'},
-
- {'criterion': 'gini', 'max_depth':5,'splitter':'best'}
-
- )
-
- for params in params_list:# 声明决策树模型
-
- print('model params:', params)
-
- decisionTree=DecisionTreeClassifier(criterion=params['criterion'],max_depth=params['max_depth'],splitter=params['splitter'])
-
- # K折交叉验证(K=10)
-
- scores =cross_val_score(decisionTree,x,y,cv=10) # 你的代码
-
- # 打印平均准确率
-
- print('Average Accuracy: {:.2f}%'.format(100*scores.mean()))

下面是参数的介绍:
class_weight : 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
criterion : gini或者entropy,前者是基尼系数,后者是信息熵;
max_depth : int or None, optional (default=None) 设置决策随机森林中的决策树的最大深度,深度越大,越容易过拟合,推荐树的深度为:5-20之间;
max_features: None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的;
max_leaf_nodes : 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。
min_impurity_split: 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
min_samples_leaf : 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
min_samples_split : 设置结点的最小样本数量,当样本数量可能小于此值时,结点将不会在划分。
min_weight_fraction_leaf: 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。
splitter : best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中,默认的”best”适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐”random” 。
————————————————
原文链接:https://blog.csdn.net/qq_39885465/article/details/104523125
关于参数的介绍详细博客:https://www.cnblogs.com/juanjiang/p/11003369.html
8.分析决策树模型中的参数对平均准确率的影响
max_depth限制树的最大深度,超过设定深度的树枝全部剪掉 这是用得最广泛的剪枝参数,在高维度低样本量时非常有效。决策树多生长一层,对样本量的需求会增加一倍,所以限制树深度能够有效地限制过拟合。
criterion参数是用来设置不纯度的判决方法,默认的criterion参数使用的是‘gini’基尼系数,还可以设置为‘entropy’信息增益。比起基尼系数,信息熵对不纯度更加敏感,对不纯度的惩罚最强。对于高维数据或者噪音很多的数据,信息熵很容易过拟合,基尼系数在这种情况下效果往往比较好。
random_state用来设置分枝中的随机模式的参数,默认None,在高维度时随机性会表现更明显,低维度的数据(比如鸢尾花数据集),随机性几乎不会显现。输入任意整数,会一直长出同一棵树,让模型稳定下来。

