- 1Android开发6年,面试腾讯我才发现这些知识点竟然没掌握全?(Android面试题大全篇)
- 2windows系统下重启springboot项目时,提示端口被占用,却找不到占用端口的程序_springboot启动端口被占用,确定没有被占用
- 3NLP-BERT 谷歌自然语言处理模型:BERT-基于pytorch_bert github
- 4距离度量常见四种距离方式的及KNN算法对鸢尾花分类_knn距离度量方式
- 5基于spring boot+maven+opencv 实现的图像深度学习java人脸识别jsp源代码Mysql_基于spring boot + maven + opencv 实现的图像深度学习
- 6人工智能算法原理与代码实战:自然语言处理的基本原理与实现_中文自然语言处理基础与实战的算法的思想
- 7windows安装mongodb6.x并设置用户名密码_windows设置mongo密码
- 8USACO Section 4.3 Letter Game_信游戏在家里和电视上都很流行。在游戏的一个版本中,每个字母都有一个值,你收
- 9热门不再!科技大厂放缓招聘,美国计算机专业学生求职四处碰壁
- 10基于FPGA的交通灯_基于fpga使用verilog的交通信号灯论文结论
打造自动答题小程序 - 从爬到答的全流程解析【附完整代码】_python 爬虫url不变题目刷新如何自动答题
赞
踩
引言
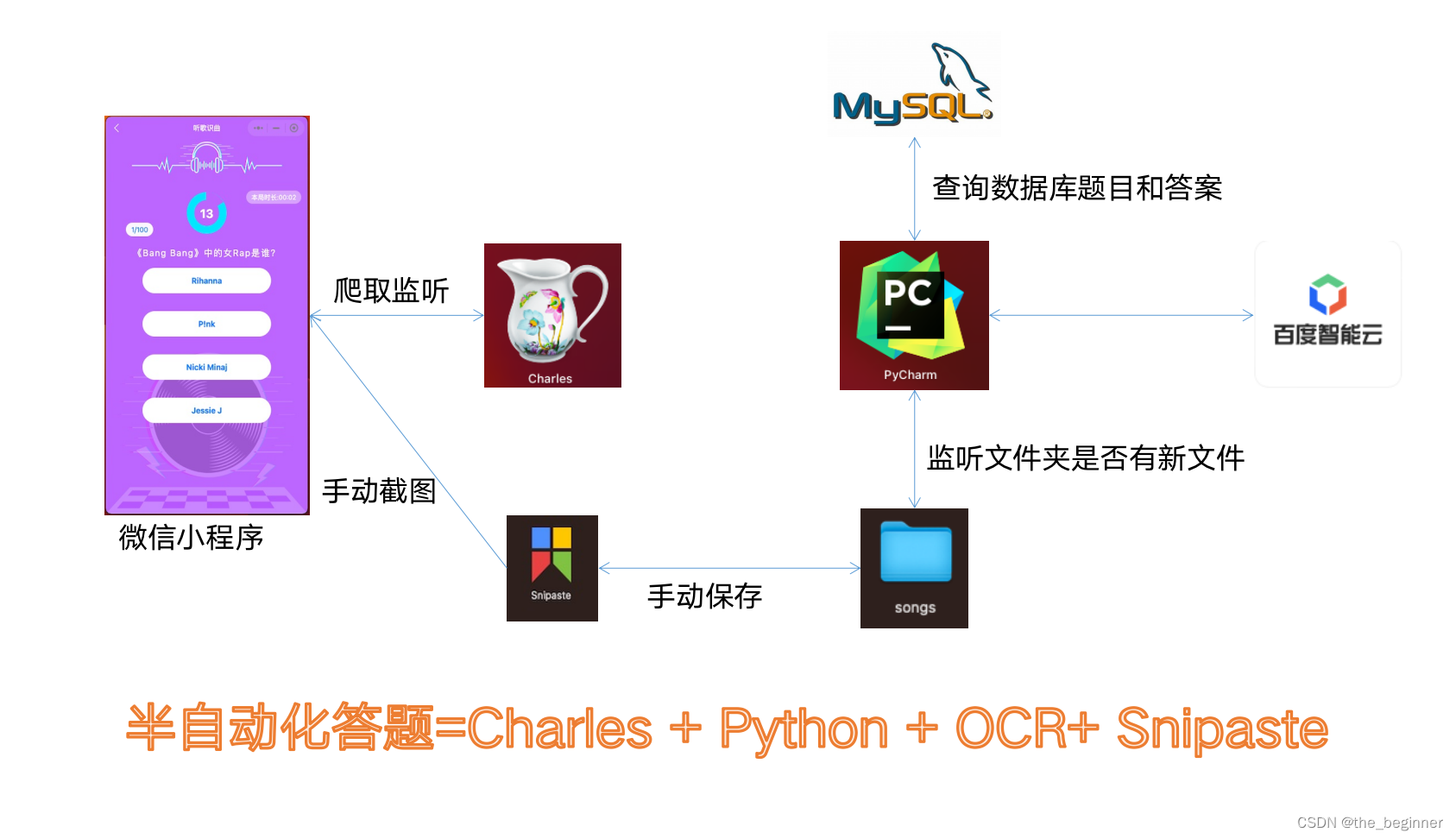
随着数字化时代的到来,各种线上活动层出不穷。最近,公司举办了一场线上好声音活动,其中包含一个猜歌名的互动环节。这一环节不仅考验了参与者的音乐知识储备,更在一定程度上挑战了他们的反应速度。作为一名技术爱好者,我自然想到了一个问题:能否利用技术手段,实现自动答题,从而在竞争中取得优势?本文将详细解析我如何利用爬虫技术、OCR识别以及自动化点击工具,打造了一款自动答题小程序。
场景分析
首先,我们需要对猜歌名活动的流程进行分析。参与者在听到一段音乐后,需要在给定的四个选项中选择一个。题目类型多样,包括猜歌名、猜歌曲作者、猜歌曲年代等。答题结束后,系统会根据答对题目的数量和答题时间进行排名。由于竞争激烈,许多参与者会反复练习,以提高答题速度和准确性。
解决思路
为了实现自动答题,我们需要解决以下几个关键问题:
如何获取题目和答案?
如何识别题目并匹配答案?
如何模拟点击屏幕,选择正确答案?
针对这些问题,我们提出了以下解决方案:
使用爬虫工具爬取小程序中的题目和答案,并将它们存储到数据库中。
利用OCR技术识别题目中的文字,并通过比对数据库中的答案,找到正确答案。
使用自动化点击工具模拟点击屏幕,选择正确答案。
工具选择
在实现自动答题小程序的过程中,我们选择了以下工具:
Charles爬虫工具
Charles是一个强大的网络调试工具,它可以帮助我们捕获和分析小程序中的网络请求和响应数据。通过Charles,我们可以爬取到小程序中的题目和答案信息。
PyCharm编译工具
PyCharm是一款优秀的Python集成开发环境,它提供了丰富的功能,如代码编辑、调试、版本控制等。我们使用PyCharm来编写和调试自动答题小程序。
百度OCR文字识别技术
OCR(Optical Character Recognition,光学字符识别)技术可以识别图片中的文字信息。我们选择使用百度OCR技术来识别题目中的文字,为后续匹配答案提供数据支持。
PyAutoGUI自动点击工具
PyAutoGUI是一个Python库,它可以模拟鼠标和键盘操作。我们使用PyAutoGUI来模拟点击屏幕,选择正确答案。
实现过程
1. 爬取题目和答案
首先,我们使用Charles工具对小程序进行抓包分析,找到题目和答案的网络请求。通过分析请求和响应数据,我们可以提取出题目和答案的信息,并将它们存储到数据库中。
2. 识别题目并匹配答案
在答题过程中,我们需要识别题目中的文字,并与数据库中的答案进行匹配。为了实现这一功能,我们利用百度OCR技术识别题目中的文字,并将其与数据库中的答案进行比对。通过比对,我们可以找到正确答案。
3. 模拟点击屏幕选择答案
找到正确答案后,我们需要模拟点击屏幕来选择它。这里,我们使用PyAutoGUI库来模拟鼠标操作。通过设置鼠标的位置和点击事件,我们可以实现自动点击屏幕,选择正确答案。
心得体会
- Charles爬取工具 :这个工具第一次接触,而且我是Mac系统,在使用上与Windows还是有很多不同;印象中有一点是Charles开了代理,有时候就没法上网了。关于代理的本质以及细节,这一块我了解到也是比较浅显,后面有需要会做系统分析和研究,现在有很多使用教程,大同小异,大家感兴趣可以搜索和查阅。这个软件正版是要收费的,当然如果能找到“学习版”也很好。
- Pycharm编译工具 :第一次在Mac上使用,一些细节还是花了不少时间,比如Python工程路径的配置,因为之前都是在Windows做开发,项目紧,也没有注意这些细节,一直用的同一个工程路径、Python环境,所以不会出错,这次换到Mac系统,不得不重新走了一遍流程,也算是一笔收获。
- 百度OCR文字识别技术:一开始我看到类似的解决方案,使用OCR识别技术去进行文字识别读取题目,然后解析处理,我会觉得有点多余。我觉得既然可以爬取到题目,为啥还多此一举呢?实际上,使用Charles爬取到的题目信息是有限的(可能是小程序服务器使用了某些加密技术),根本不是某些教程贴说的那样,在爬取到题目的时候,答案也出来了。你只能爬取到题干,答案要自己去匹配。这里太细节了,不阐述了。
总之,最后没有办法,还是用了百度OCR技术,这个也是我第一次结束。你别说,百度OCR真的很好用,识别很准确快速。相关的教程贴有很多,感兴趣的可以搜索研究,后面有需要我也可以写个教程贴。 - Pyautogui 自动点击:这个说老实话不是很好用,最后还是没有实现,我最终实现的效果是程序自动识别题目,输出正确答案,然后我再手动点击。是不是很鸡肋?我本来就知道答案的,这一波操作下来,只能更慢,冲榜无望…
在开发自动答题小程序的过程中,我收获了很多宝贵的经验。首先,我了解了如何使用爬虫工具抓取小程序中的题目和答案信息。其次,我学会了利用OCR技术识别图片中的文字信息,为自动答题提供了数据支持。最后,我掌握了如何使用自动化点击工具模拟鼠标操作,实现了自动答题的功能。
虽然最终实现的自动答题小程序并没有完全达到预期的效果,但它让我深刻体会到了技术的魅力和挑战。我相信在未来的学习和工作中,我会继续探索和应用新技术,为解决实际问题提供更多的解决方案。
结语
通过本次实践,我不仅掌握了爬虫技术、OCR识别以及自动化点击工具的使用方法,还锻炼了自己的实践能力和解决问题的能力。我相信这些经验和技能将对我未来的学习和工作产生积极的影响。同时,我也期待在未来的技术探索中,能够不断挑战自己,实现更多的创新和突破。
代码部分
1.爬取首页信息
这一页没什么敏感信息。代码可直接运行。

import requests,json url = "https://stm.leyoutb.com/api/Voicemeetapi/getBasedata" headers = { "Host": "stm.leyoutb.com", "Connection": "keep-alive", "Content-Length": "55", "xweb_xhr": "1", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 MicroMessenger/6.8.0(0x16080000) NetType/WIFI MiniProgramEnv/Mac MacWechat/WMPF MacWechat/3.8.4(0x13080410)XWEB/31009", "Content-Type": "application/json", "Accept": "*/*", "Sec-Fetch-Site": "cross-site", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Dest": "empty", "Referer": "https://servicewechat.com/wx0aa6aff20be54418/1/page-frame.html", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9" } data={"data":"PNRtUqSXzYx6PZS0cjkNQUxm8VObCMlBUysI9gC8oZ4="} response = requests.post(url, headers=headers,data=json.dumps(data)) print(response.status_code) response_dict = response.json() print(json.dumps(response_dict, indent=1, ensure_ascii=False))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
2.爬取用户信息
这一部分比较敏感,我用的自己的信息(工号信息)
用户信息正确的爬取结果(本人)
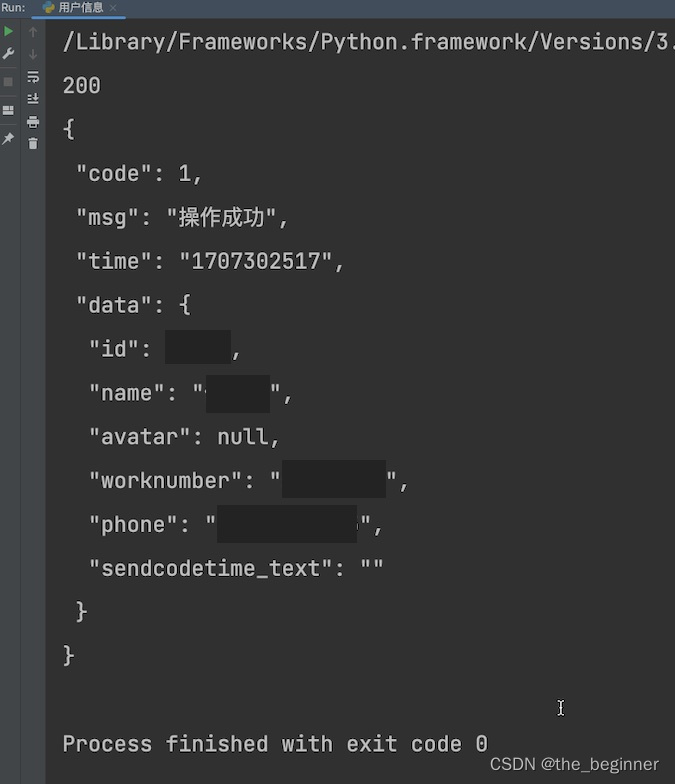
去爬取的,大家可以根据自己的id去改变data的值。
import requests,json url = "https://stm.leyoutb.com/api/Voicemeetapi/getUserdata" headers = { "Host": "stm.leyoutb.com", "Connection": "keep-alive", "Content-Length": "99", "xweb_xhr": "1", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 MicroMessenger/6.8.0(0x16080000) NetType/WIFI MiniProgramEnv/Mac MacWechat/WMPF MacWechat/3.8.4(0x13080410)XWEB/31009", "Content-Type": "application/json", "Accept": "*/*", "Sec-Fetch-Site": "cross-site", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Dest": "empty", "Referer": "https://servicewechat.com/wx0aa6aff20be54418/1/page-frame.html", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9" } #根据个人调整data的值,data很复杂,Charles可以直接看到 data={"data":"根据需要改动"} response = requests.post(url, headers=headers,data=json.dumps(data)) print(response.status_code) response_dict = response.json() print(json.dumps(response_dict, indent=1, ensure_ascii=False))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
本人data信息

3.爬取排行榜信息
涉及公司同事姓名,已经马赛克。
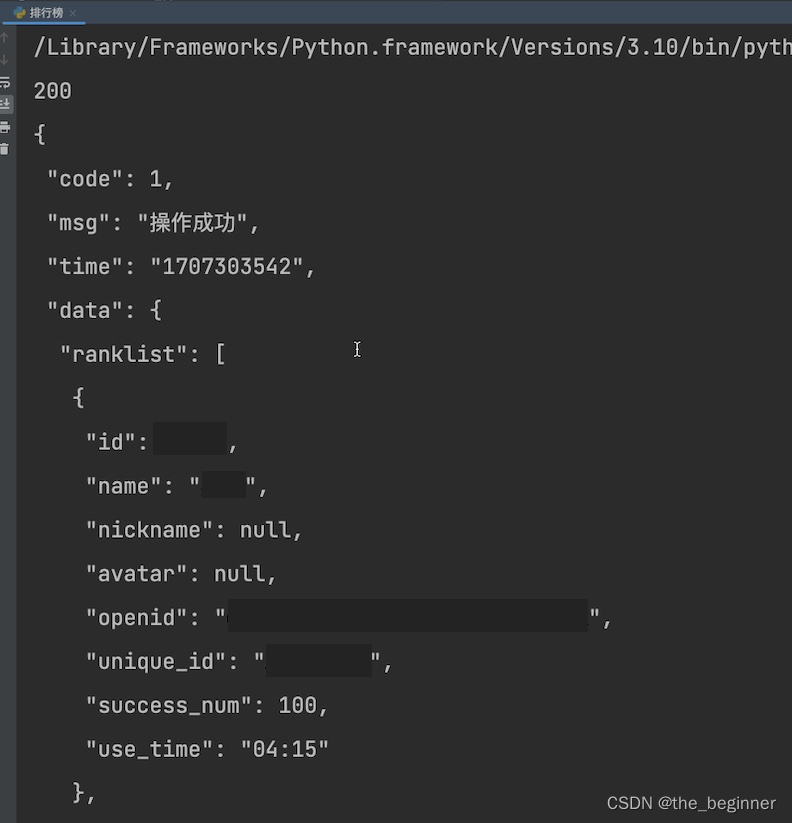
import requests,json url = "https://stm.leyoutb.com/api/Voicemeetapi/getRanklist" headers = { "Host": "stm.leyoutb.com", "Connection": "keep-alive", "Content-Length": "119", "xweb_xhr": "1", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 MicroMessenger/6.8.0(0x16080000) NetType/WIFI MiniProgramEnv/Mac MacWechat/WMPF MacWechat/3.8.4(0x13080410)XWEB/31009", "Content-Type": "application/json", "Accept": "*/*", "Sec-Fetch-Site": "cross-site", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Dest": "empty", "Referer": "https://servicewechat.com/wx0aa6aff20be54418/1/page-frame.html", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9" } #根据个人调整data的值,data很复杂,Charles可以直接看到 data={"data":"根据需要改动"} response = requests.post(url, headers=headers, json=data) print(response.status_code) response_dict = response.json() print(json.dumps(response_dict, indent=1, ensure_ascii=False))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4.获取题目和答案
每一次运行脚本,相当于答题者重新开始一次答题,可以获取题库中100题的题干以及正确答案,通过不断运行该脚本,就能爬取到题库全部到题目和答案,需要注意的是这里的题目的顺序是随机的。
也就是说小程序出现的题目的顺序并不是按照爬取结果的顺序来的,这里我还没有搞明白小程序的出题顺序是怎样的。
import requests import json url = "https://stm.leyoutb.com/api/Voicemeetapi/getVoicelist" headers = { "xweb_xhr": "1", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 MicroMessenger/6.8.0(0x16080000) NetType/WIFI MiniProgramEnv/Mac MacWechat/WMPF MacWechat/3.8.4(0x13080410)XWEB/31009", "Content-Type": "application/json", "Accept": "*/*", "Sec-Fetch-Site": "cross-site", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Dest": "empty", "Referer": "https://servicewechat.com/wx0aa6aff20be54418/1/page-frame.html", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9" } data = {"data":"PNRtUqSXzYx6PZS0cjkNQS9tUDIBNN81UU8lOpcHWmBy4vcfoPSqj0MNBM6JCflE3ZsUgveoj+aUyaWEo8FsrQ=="} # 这里填写你的数据 response = requests.post(url, headers=headers, data=json.dumps(data),verify=False) print(response.status_code) response_dict = response.json() print(json.dumps(response_dict, indent=1, ensure_ascii=False))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
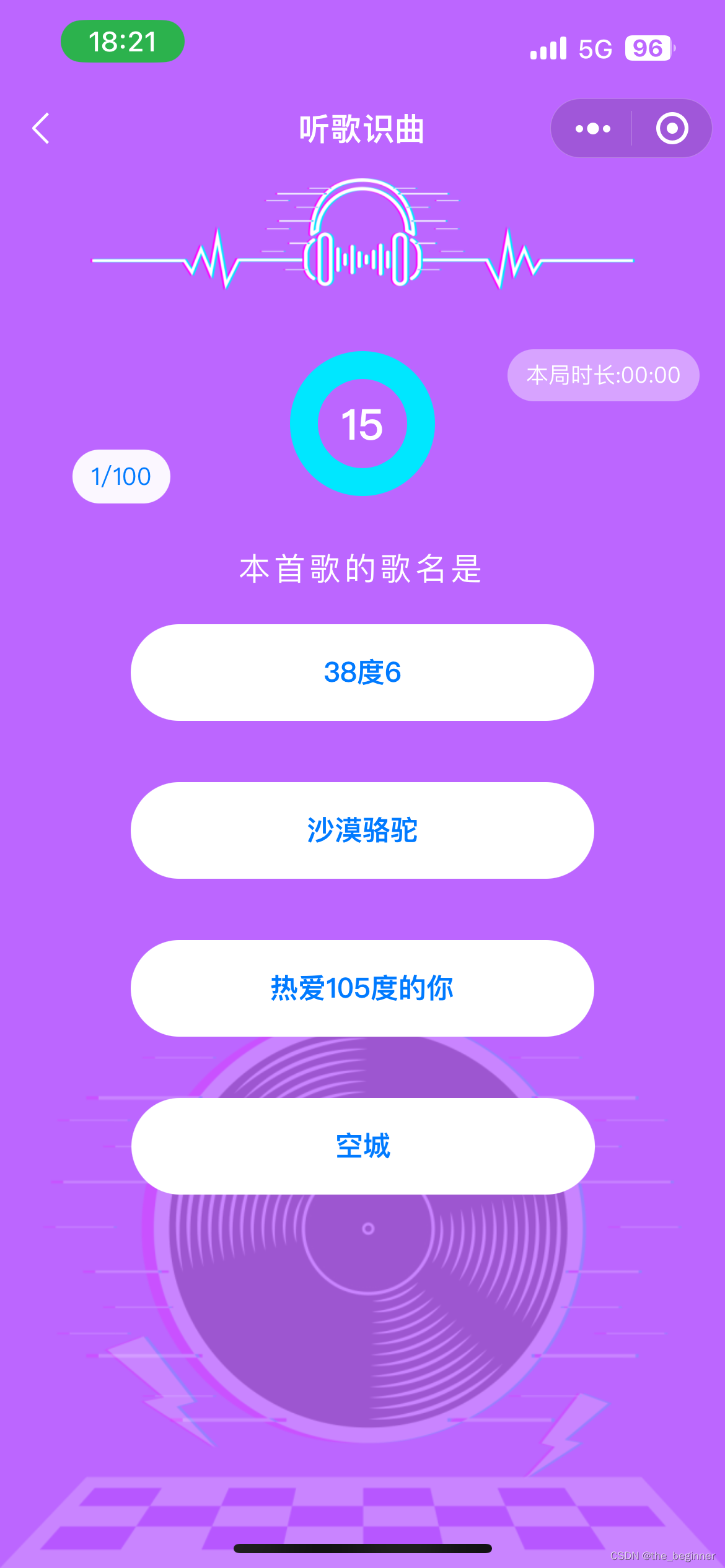
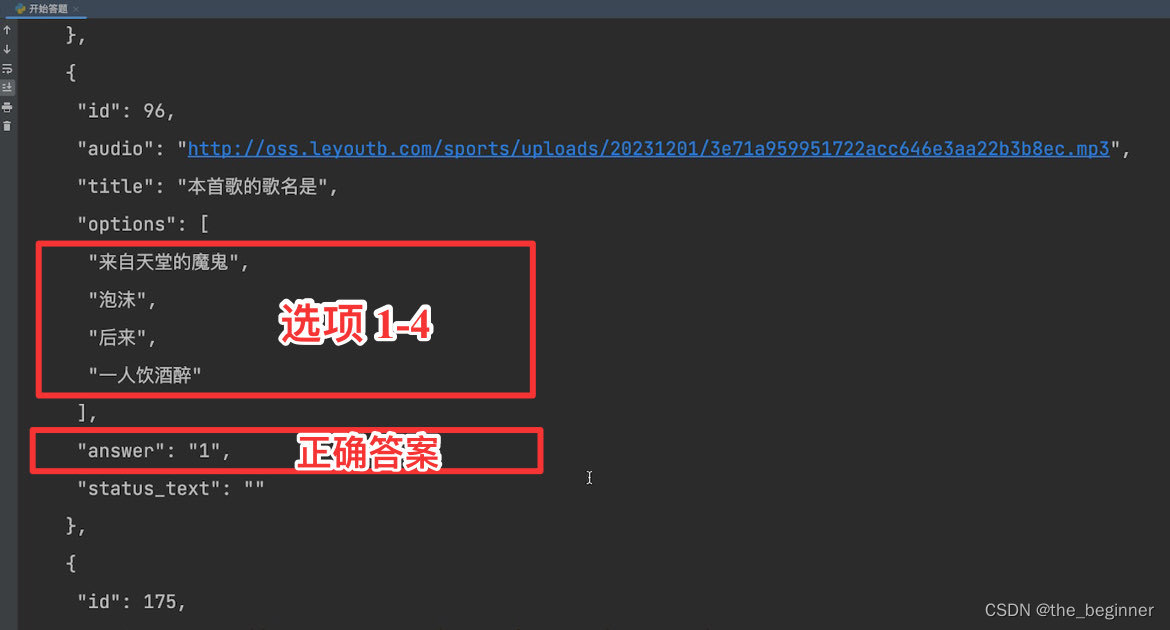
这样只需要根据程序的提示,选择正确的答案即可。
上面的代码比较松散,接下来是比较结构化的代码
本地监听-自动答题
import socket,time,os,re server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server_socket.bind(('localhost',2000)) # 绑定到本地的8888端口 server_socket.listen(1) # 最多允许1个连接 print('Listening on port 2000...') while True: #获取题目 client_socket, client_address = server_socket.accept() # 等待客户端连接 #当前时间 current_time = time.time() formatted_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(current_time)) print("当前时间:", formatted_time) print(f'Received connection from {client_address}') data = client_socket.recv(150) # 接收数据,每次最多接收1024字节 data_str = data.decode('utf-8') # 将字节类型的数据转换为字符串 # print(type(data_str),'\n',data_str) mp3_name = re.search(r'/([^/]+)\.mp3', data_str).group(1) print("mp3_name:",mp3_name+'.mp3') #获取答案 #查询数据库或者json文档 #查到 未查到 #提交答案 post或者模拟点击 #client_socket.close() # 关闭客户端连接 def query_db(song_name,db_name,tb_name): """ :param song_name: 歌曲名称 :param db_name: 数据库名称 :param tb_name: 数据表名称 :return: ansewer 歌曲答案 功能: 如果歌曲名称=='', 根据歌曲名称,查询数据库对应的数据表,返回歌曲答案 """
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
本地监听-更新题库
import socket,time server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server_socket.bind(('localhost',8000)) # 绑定到本地的8888端口 server_socket.listen(1) # 最多允许1个连接 print('Listening on port 8000...') while True: client_socket, client_address = server_socket.accept() # 等待客户端连接 # 当前时间 current_time = time.time() formatted_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(current_time)) print("当前时间:", formatted_time) print(f'Received connection from {client_address}') data = client_socket.recv(1024) # 接收数据,每次最多接收1024字节 # 处理接收到的数据,你可以将其打印出来或进行其他操作 print(data) client_socket.close() # 关闭客户端连接
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
本地题库
import sqlite3 """ 建立数据库song.db 建立数据表 表名称 song_info 列名:id audio answer 类型均为char字符串 """ import sqlite3 # 连接数据库,如果不存在则创建 conn = sqlite3.connect('song.db') cursor = conn.cursor() # 创建数据表 song_info cursor.execute(''' CREATE TABLE IF NOT EXISTS song_info ( id TEXT PRIMARY KEY, audio TEXT, title TEXT, answer TEXT ) ''') # 提交事务并关闭连接 conn.commit() conn.close() # 重新连接数据库 conn = sqlite3.connect('song.db') cursor = conn.cursor() # 查询数据表 song_info 的所有内容 cursor.execute("SELECT * FROM song_info") rows = cursor.fetchall() # 打印数据表的内容 for row in rows: print(row) # 关闭连接 conn.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
截图程序
import pyautogui
try:
# 设置截图区域,格式为 (left, top, width, height)
region = (100, 100, 300, 200)
# 截取指定区域
screenshot = pyautogui.screenshot(region=region)
# 保存截图到文件
screenshot.save('screenshot_region.png')
except Exception as e:
print(e)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
python_gui
import time import pyautogui for i in range(5, 0, -1): print(i) time.sleep(1) # 获取当前鼠标指针的坐标位置 x, y = pyautogui.position() print("当前鼠标指针的坐标位置为:", x, y) """ answer 1: 201 339 answer 2: 201 430 answer 3: 201 516 answer 4: 201 601 """
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
OCR识别截图、读取题目
import keyboard #pip install keyboard import time #built-in module from aip import AipOcr #pip install baidu-aip from PIL import ImageGrab #pip install pillow (PIL is short for pillow) keyboard.wait(hotkey='f1') keyboard.wait(hotkey='ctrl+c') time.sleep(0.1) image = ImageGrab.grabclipboard() image.save('screen.png') with open('ocr_content.txt','r',encoding='utf-8') as f: r = f.readlines() content_list = r content = ' '.join(content_list) APP_ID = 'XXXXXXXXX' API_KEY = 'YYYYYYYYY' SECRET_KEY = 'ZZZZZZZZZ' client = AipOcr(APP_ID,API_KEY,SECRET_KEY) with open('screen.png','rb') as f: image = f.read() text = client.basicAccurate(image) result= text["words_result"] for i in result: content = content + i["words"] content = content content = content + '\n' with open('ocr_content.txt','w',encoding = 'utf-8') as f: f.write(content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
整体逻辑