
- 1都说B站难爬?这也不难!_为什么爬虫爬不到哔哩哔哩的
- 2ios浏览器 图片size过大(长度6000px) 设置translateZ(0)/translate3d(0,0,0),会模糊
- 3编写一个脚本,可以定时5分钟关闭Windows系统
- 4蓝桥杯51单片机LED控制_按键按下速度控制led的亮
- 5T265学习之路(1)---环境搭配及Realsense_viewer安装_realsense-viewer
- 6Codeforces 296D. Greg and Graph (Floyd)_n distinct integers 1 , 2 , … , x 1 ,x 2 ,
- 7python雷达成像(SAR)仿真:(三)徙动校正+方位压缩(完结)_sar方位向压缩
- 8数据优先于模型:默默无闻的英雄们,他们解锁了真正的AI成果
- 9Docker:(七)dockerfile优化小技巧_dockerfile 构建镜像优化
- 10【软考系统规划与管理师笔记】第7篇 IT服务运营管理_系统规划与管理师 运营管理
深度学习(14)神经网络的优化-优化器,动量,自适应学习率,批量归一化_自适应学习率与深度学习
赞
踩
综述:神经网络的优化-优化器,动量,自适应学习率,批量归一化
最近学习了《神经网络与深度学习》(By Michael Nielsen / Dec 2019)链接:
https://tigerneil.gitbooks.io/neural-networks-and-deep-learning-zh/content/
根据学习总结将讨论与神经网络优化有关的以下概念:
- 优化面临的挑战
- 动量
- 适应性学习率
- 参数初始化
- 批量归一化
优化面临的挑战
当谈论神经网络中的优化时,我们其实是在讨论非凸优化问题****(non-convex optimization)。
与之对应,凸优化(Convex optimization)中,函数只有一个最优值,对应于全局最优值(最大值或最小值)。对于凸优化问题,没有局部最优的概念,这使得它们相对容易解决-这些是本科和研究生课程中的常见入门优化问题。
非凸优化涉及具有多个最优值的函数,其中只有一个是全局最优值。根据损失曲面loss surface,很难找到全局最优值
对于神经网络,我们这里所说的曲线或曲面称为损失曲面。由于我们试图使网络的预测误差最小,因此我们需要在此损失曲面上找到全局最小值-这是神经网络训练的目的。
-
针对神经网络训练,有很多相关问题需要考虑:
-
使用的合理学习率是多少?太小的学习率将花费太长时间才能收敛,而太大的学习率将意味着网络将不会收敛。
-
我们如何避免陷入局部最优?一个局部最优可能被特别陡峭的损失函数所包围,并且可能难以“逃脱”该局部最优。
-
如果损失曲面形态发生变化怎么办?即使我们可以找到全局最小值,也无法保证它将永远保持全局最小值。举个栗子:在不代表实际数据分布的数据集上进行训练时,将其应用于新数据时,损失曲面将有所不同。这就是为什么使训练和测试数据集要能够代表总数据分布如的重要原因之一。另一个很好的例子是数据由于其动态特性而习惯性地发生变化,例如,用户对流行音乐或电影的偏好会每天和每月都会改变。
-
-
幸运的是,解决这些挑战已经存在很多方法。
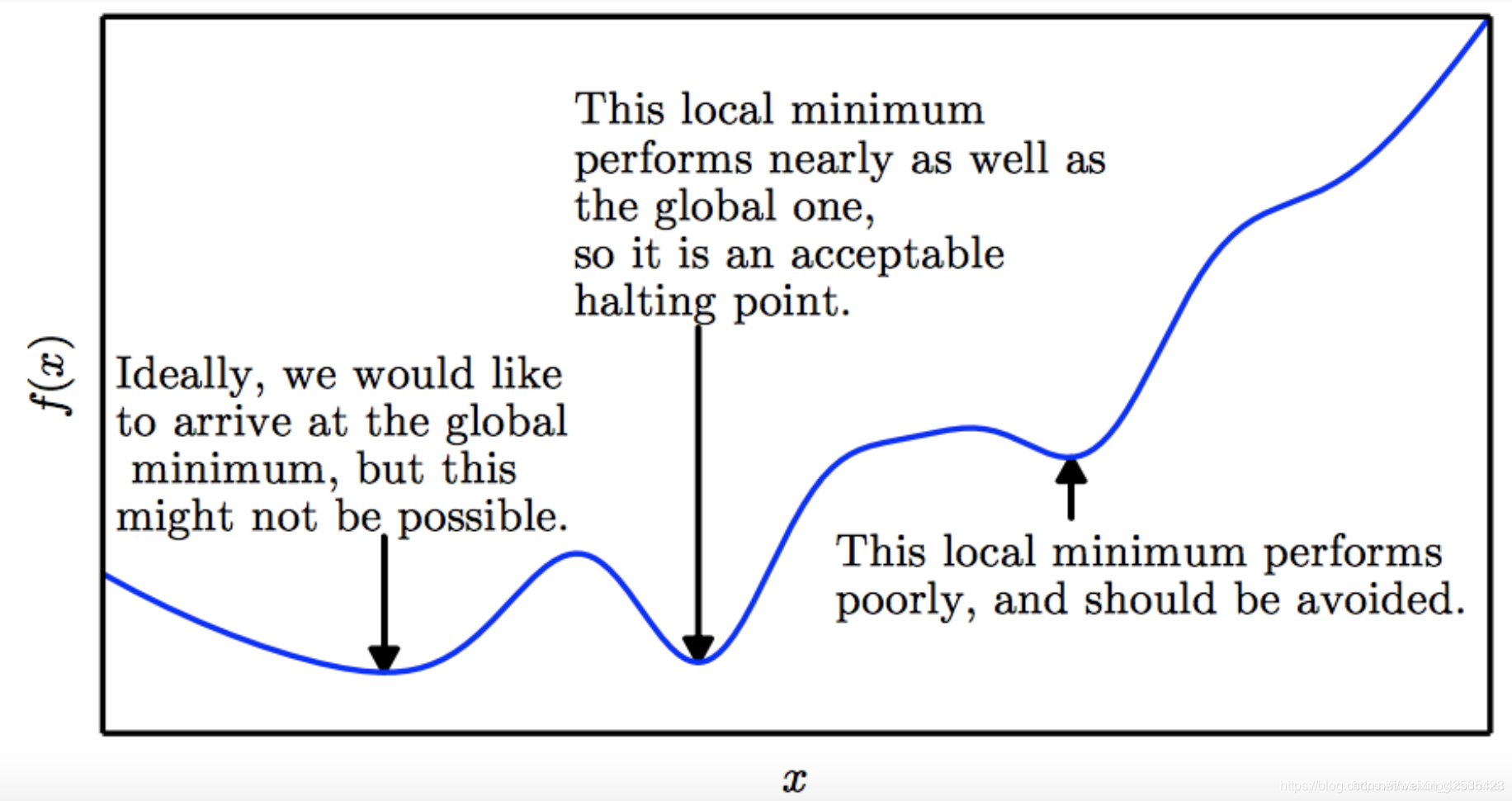
局部最优
以前,局部最小值被视为神经网络训练中的主要问题和挑战。如今,研究人员发现,当使用足够大的神经网络时,大多数局部最小值会产生较低的误差, 也就是cost,因此,找到真实的全局最小值并不是特别重要-误差较低的局部最小值是可接受的呀。请看下图:
鞍点
最近的研究表明,在高维度上,鞍点比局部极小值更有可能出现。鞍点也比局部最小值更具挑战,因为接近鞍点时,梯度可能非常小。因此,梯度下降在此就不会去更新网络,训练将停止。
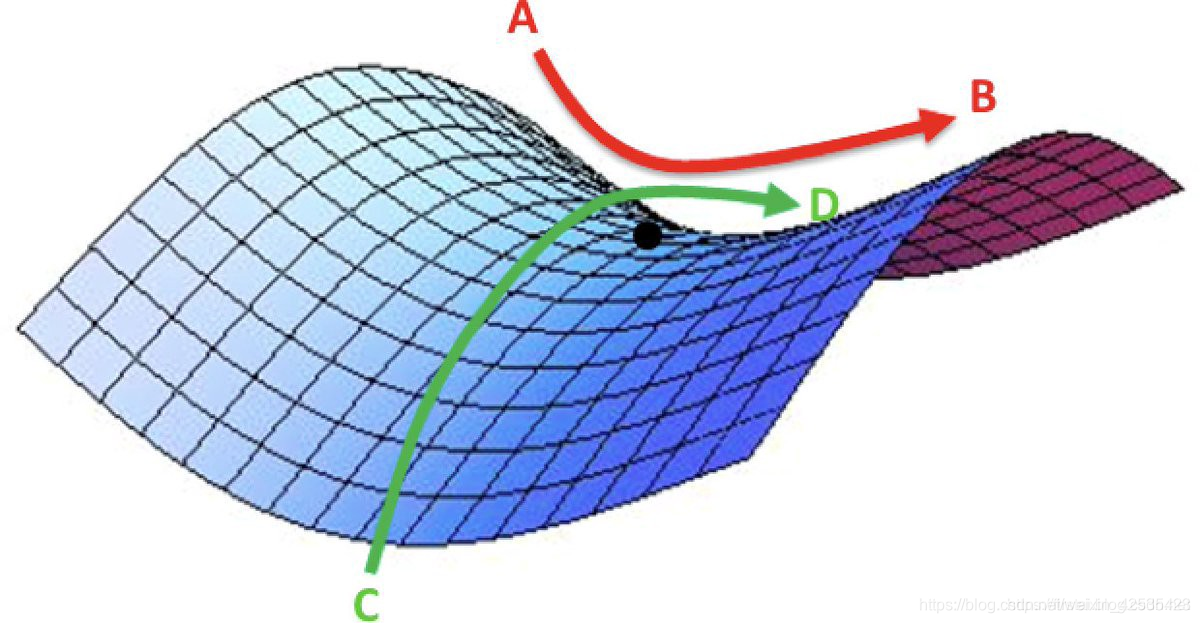
鞍点—同时是局部最小值和局部最大值。A-B方向是最小,C-D方向是最大;
- 1
- Rosenbrook函数是一个通常用于测试优化算法在鞍点上性能的示例函数。该函数由以下公式描述:

其全局最小值为

这是一个非凸函数,全局最小值位于一个长而狭窄的山谷中。查找山谷相对容易,但是由于平坦的山谷,很难收敛到全局最小值,因此,山谷的梯度很小,因此基于梯度的优化过程很难收敛。

具有两个变量的Rosenbrock函数的图。这里a = 1,b = 100,最小值零在(1,1)
- 1

Rosenbrock的三个变量函数的动画
- 1
病态/非良置-情况/Poor Conditioning
误差函数的特殊形式可能成为一个重要的代表性问题。长期以来,人们一直注意到误差函数的导数通常是ill-conditioned的。这种不良情况反映在包含许多鞍点和平坦区域的错误情况中。
为了理解这一点,我们可以看一下Hessian矩阵 -一个标量值函数的二阶偏导数的方阵。Hessian描述了许多变量的函数的局部曲率。

可以使用Hessian确定给定的固定点是否为鞍点。如果Hessian在该位置是indefinite,则该固定点就是一个鞍点。也可以通过查看特征值以类似的方式进行推理。
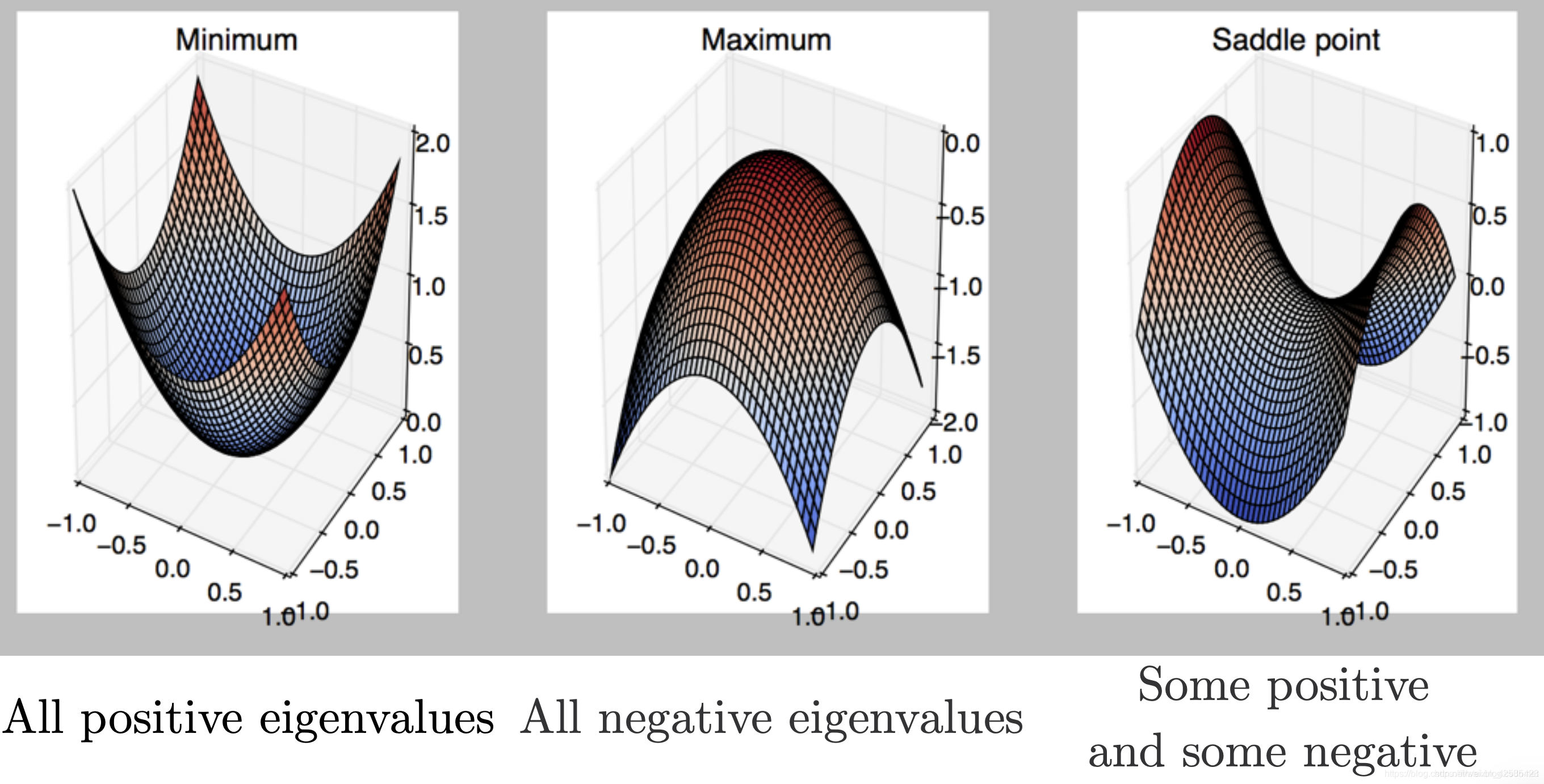
计算和存储完整的Hessian矩阵需要O(n²)内存,这对于诸如神经网络的损失函数之类的高维函数是不可行的。对于这种情况,经常使用truncated-Newton算法和quasi-Newton算法。后一种算法使用近似于Hessian的算法;BFGS是最流行的quasi-Newton拟牛顿算法之一。
通常对于神经网络,Hessian矩阵的poorly conditioned-输出随输入的微小变化而迅速变化。这是不希望看到的特性,因为这意味着优化过程不是特别稳定。在这些环境中,尽管存在强梯度,但学习仍然很慢,因为振荡会减慢学习过程。
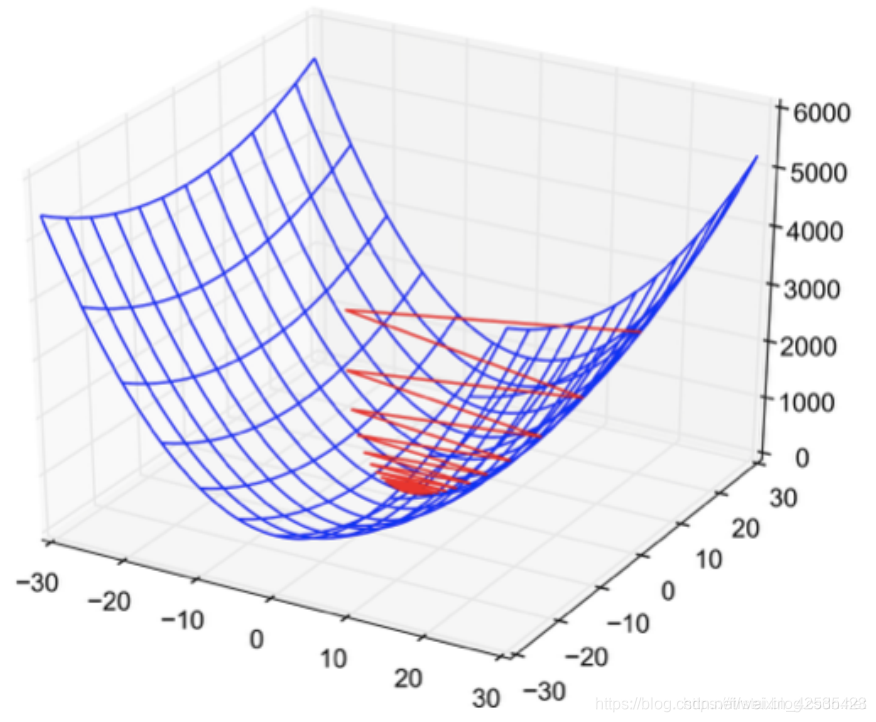
梯度消失/爆炸
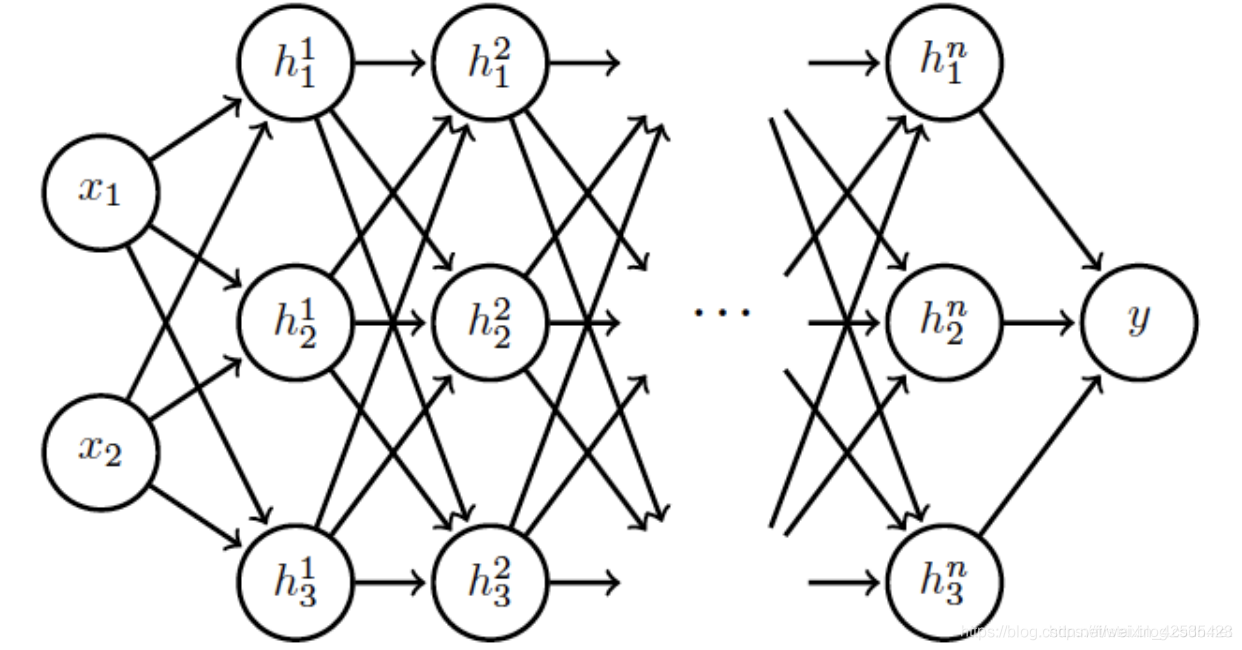
到目前为止,我们仅讨论了目标函数的结构(在这种情况下为损失函数)及其对优化过程的影响。神经网络的架构还有其他问题,这与深度学习应用特别相关。
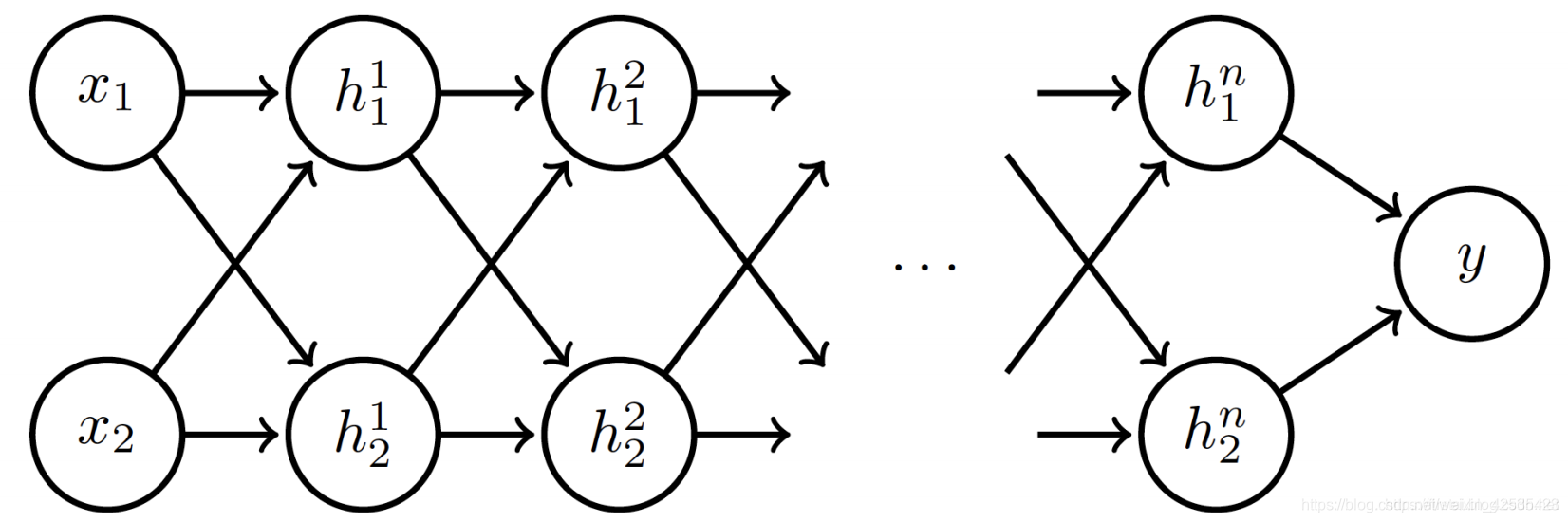
上面的结构是具有n个隐藏层的深度神经网络的示例。当第一层的features通过网络传播时,它们会进行仿射变换(affine transformations),然后是激活函数,如下所述:
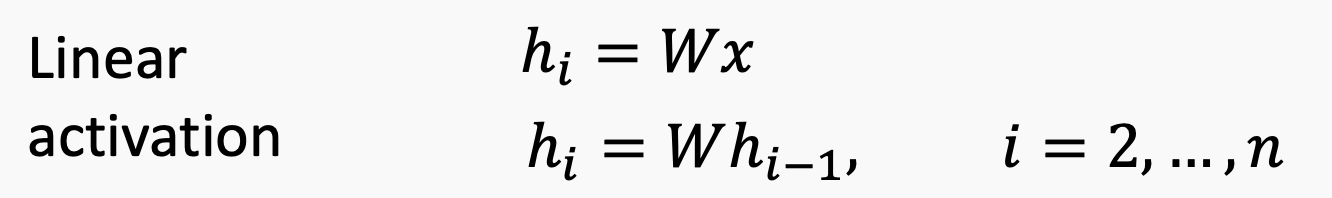
上面的等式适用于单层。我们可以编写一个n层网络的输出:

根据a和b的大小,以上公式现在有两种可能的情况:

如果值大于1,则对于较大的n(深层神经网络),梯度值将在通过网络传播时迅速爆炸。除非实现了梯度修剪,否则爆炸的梯度会导致“悬崖”(如果超过某个阈值,则将对梯度进行修剪)。
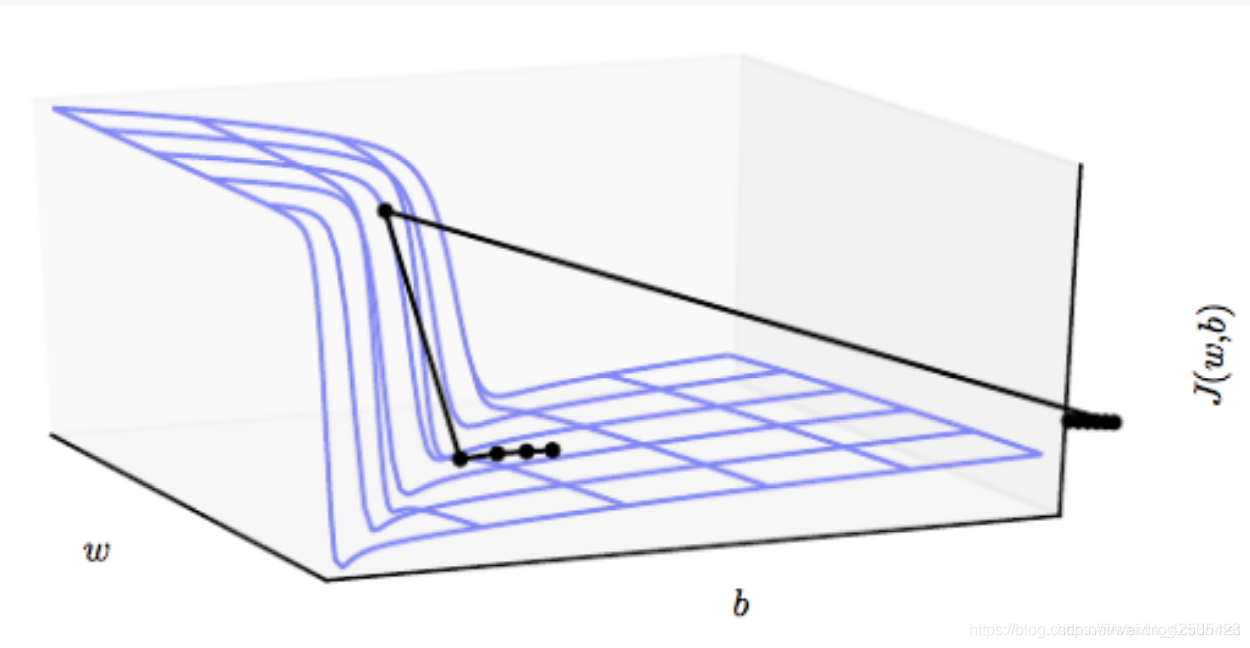
- 修剪与未修剪梯度的示例
梯度裁剪规则:

如果值小于1,则梯度将迅速趋于零。如果计算机能够存储无限小的数字,那么这将不是问题,但是计算机只能将值存储到有限的小数位数。如果梯度值变得小于此值,它将仅被识别为零。
那么我们该怎么办呢?我们发现神经网络注定要拥有大量的局部最优值,通常都包含尖锐和平坦的谷地,这会导致学习停滞和学习不稳定unstable。
现在,我将从动量开始讨论一些方法,以帮助缓解刚才讨论的有关神经网络优化的问题。
动量
动量(Momentum)又称线性动量(Linear Momentum)。在经典力学中,动量(是指国际单位制中的单位为kg·m/s ,量纲MLT⁻¹)表示为物体的质量和速度的乘积,是与物体的质量和速度相关的物理量,指的是运动物体的作用效果。动量也是矢量,它的方向与速度的方向相同。一般而言,一个物体的动量指的是这个物体在它运动方向上保持运动的趋势。
动量:物体在它运动方向上保持运动的趋势
随机梯度下降(SGD)存在一个振荡的问题,这种振荡是由没有充分利用曲率信息的更新引起的。当曲率高时,这会导致SGD变慢。
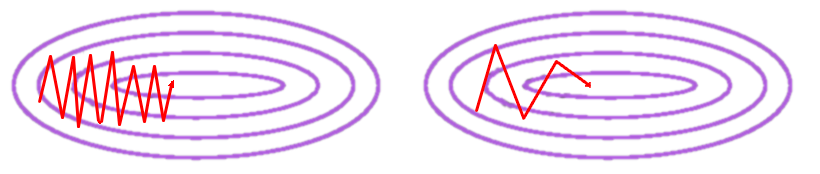
(左)香草SGD,(右)动量SGD。Goodfellow et al.(2016年)
- 1
通过采用平均梯度,我们可以获得更快的优化路径。这有助于抑制振荡,因为相反方向的梯度被抵消了。
正如开头的介绍,动量这个名字来源于这样一个事实,即它类似于物理学中的线性动量的概念。具有运动的对象(在这种情况下,这是优化算法正在运动的大致方向)具有一定的惯性,导致它们趋于沿运动方向运动。因此,如果优化算法沿一般方向移动,则动量会导致其“抵抗”方向的变化,这会导致高曲率表面的振动衰减。
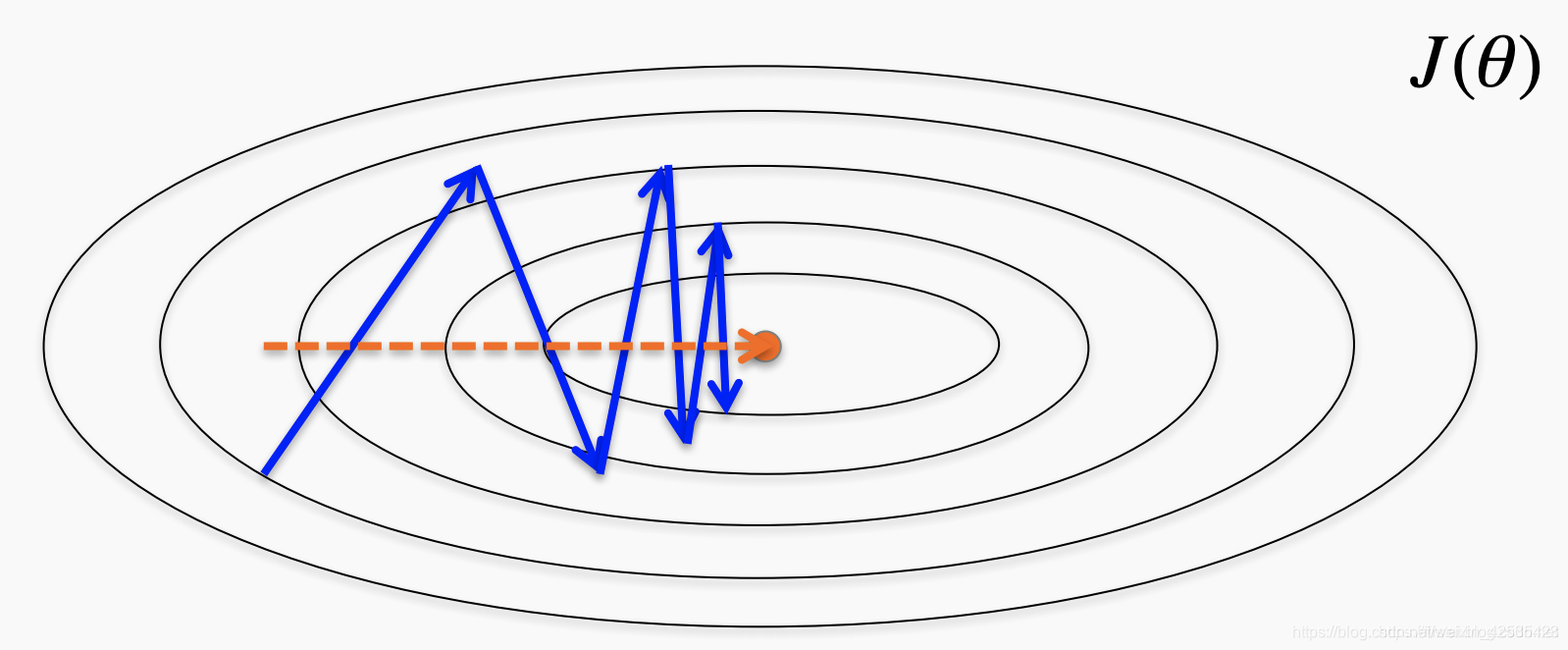
趋于沿运动方向
- 1
动量是目标函数中的一个附加项,它是一个介于0到1之间的值,它通过尝试从局部最小值处跳转而增加了向最小值迈进的步长。如果动量项较大,则学习率应保持较小。 动量的大值也意味着收敛将很快发生。但是,如果动量和学习率都保持较大值,那么您可能会大步跳过最小值。较小的动量值不能可靠地避免局部最小值,并且还可能减慢系统的训练速度。如果梯度保持方向变化,则动量还有助于平滑变化。正确的动量值可以通过随机设置和尝试或通过交叉验证来确定。
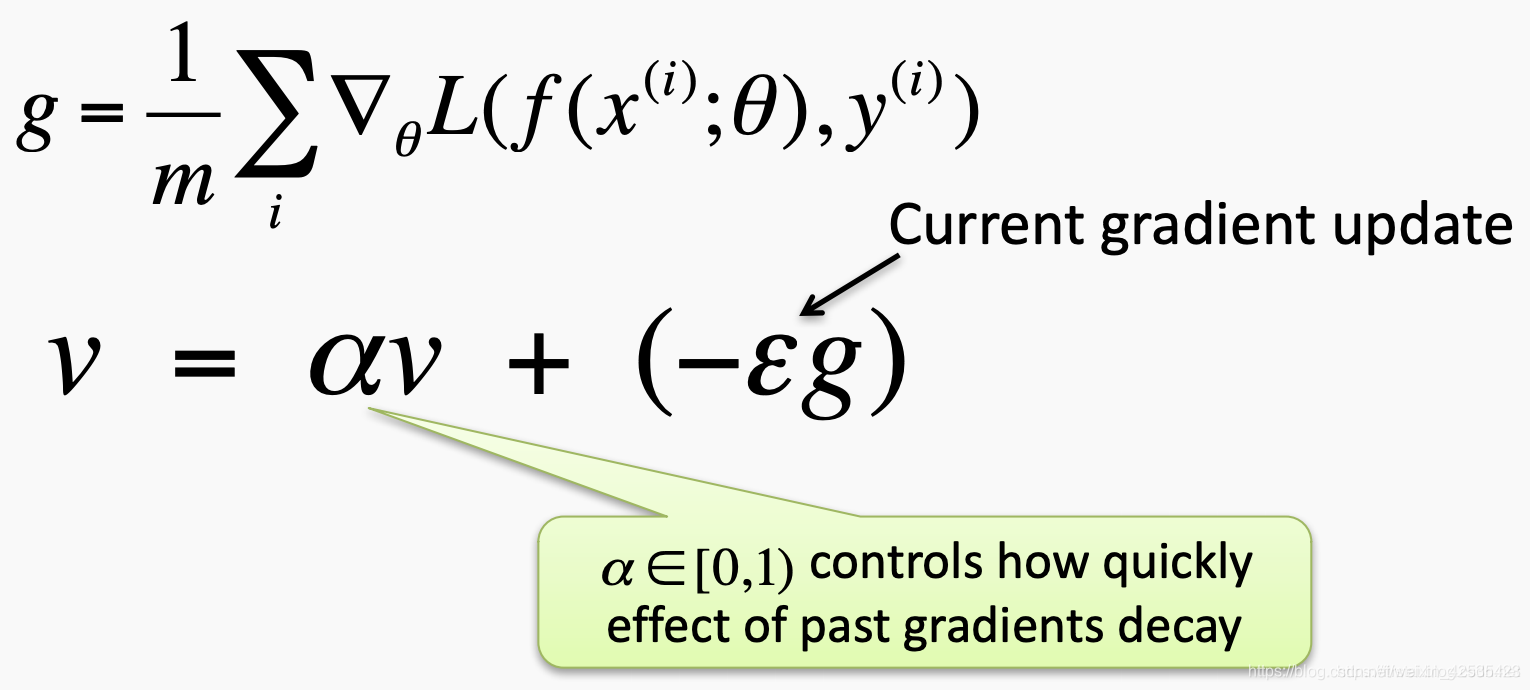
动量使用历史梯度来更新值,如以下公式所示。与动量相关的值v通常被称为“velocity速度”。更多的权重将应用于最近的梯度,从而创建梯度的指数平均值。
计算梯度:
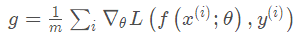
更新速度:
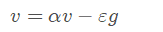
更新参数:
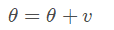
我们可以看到增加动量对优化算法的影响(看下图)。前几次更新没有显示比原始SGD真正的优势-因为我们没有以前的梯度可用于更新。随着更新次数的增加,我们的动量开始增强,并更快的收敛。
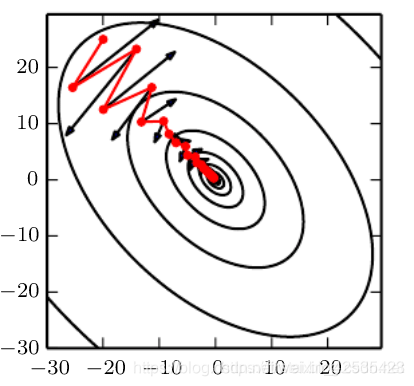
不带动量的SGD(黑色)与带动量的SGD(红色)
- 1
另一种动量是内Nesterov动量,我们将对其进行简要讨论。
Nesterov动量
Sutskever,Martens等人在2013年”On the importance of initialization and momentum in deep learning”中对Nesterov动量进行了很好的描述和讨论。
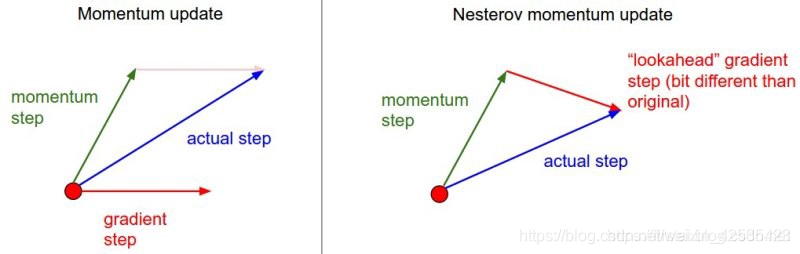
主要区别在于经典动量中**,您首先校正速度,然后根据该速度大步前进(然后重复),但是在Nesterov动量中,您首先更新速度方向,然后对速度矢量进行校正根据新位置**(然后重复)。

差异是微妙的,但实际上,它可以产生很大的差异。

这个概念可能很难理解,以下是传统动量更新和Nesterov动量之间差异的直观表示。
适应性学习率
沿垂直方向的振荡-沿参数2的学习速度必须慢一些, 为每个参数使用不同的学习率?
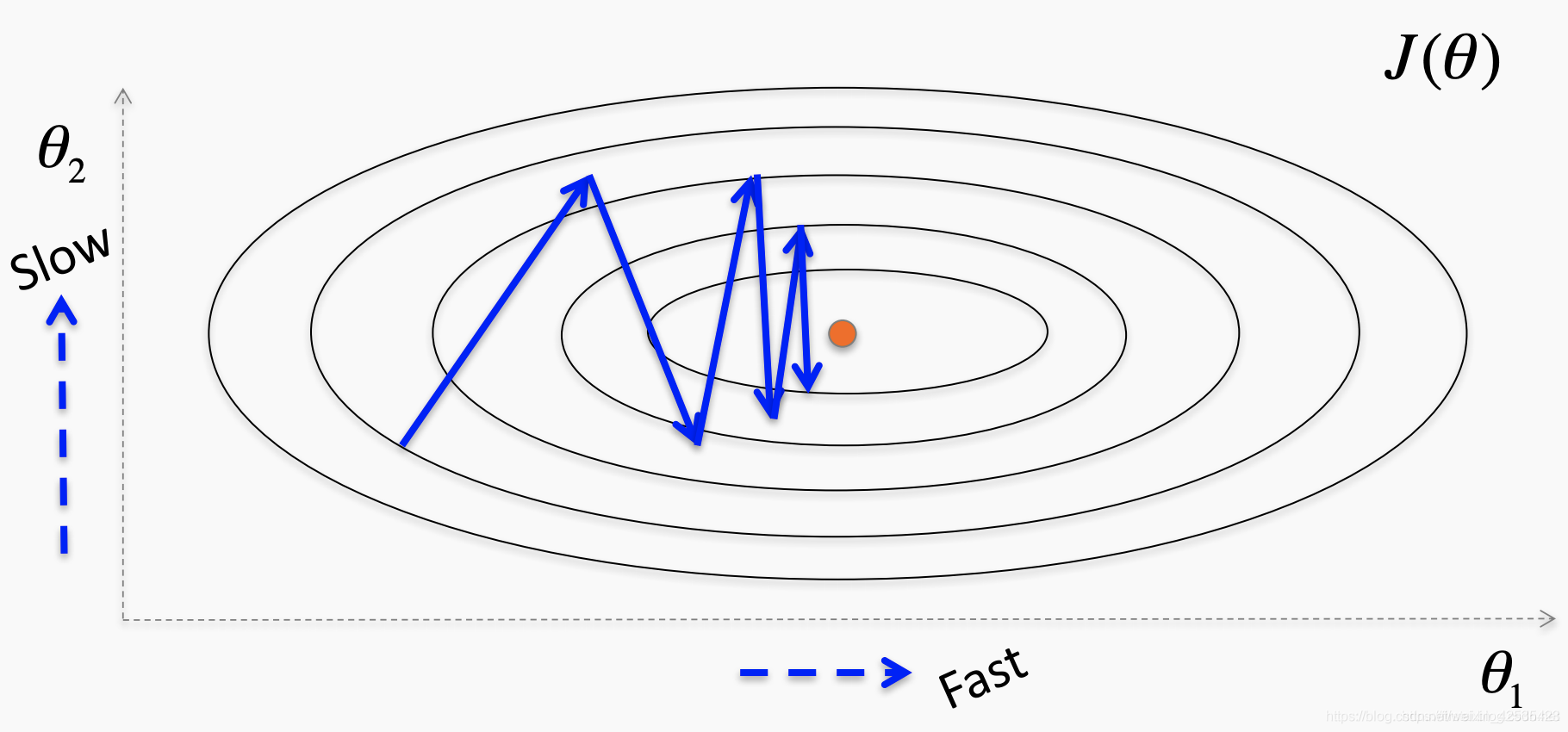
AdaGrad
动量增加了误差函数斜率的更新,并相应地提速了SGD。AdaGrad使更新适应每个单独的参数,以根据其重要性执行更大或更小的更新。

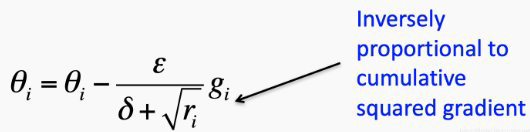
- Adagrad的主要好处之一是,它无需手动调整学习速度,并可以沿缓慢倾斜的方向取得更大的进步。
- AdaGrad的主要缺点是分母中平方梯度的累加:由于每个加法项都是正数,所以累加和在训练期间不断增长。反过来,这导致学习率下降,并最终变得无限小,这时该算法不再能够获取其他知识。
RMSProp
对于非凸问题,AdaGrad可能会过早降低学习率。我们可以使用指数加权平均值进行梯度累积。
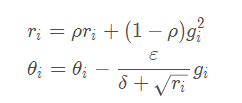
Adam
Adam是RMSprop和动量的组合(类似地,Nadam指RMSprop和Nesterov动量的组合)。Adam指的是 自适应矩估计 ,它是当今用于神经网络的最流行的优化器。
Adam计算每个参数的自适应学习率。除了存储像Adadelta和RMSprop这样的历史平方梯度vt的指数衰减平均值之外,Adam还保留了历史梯度的指数衰减平均值,类似于动量。


参数初始化
在前面的部分中,我们研究了如何最佳地导航神经网络目标函数的损失曲面,以便收敛到全局最优值(或可接受的良好局部最优值)。现在,我们将研究如何操纵网络本身以辅助优化过程。
网络权重的初始化是训练神经网络的重要且通常被忽略的一步。 与不好的初始化相关的多个问题可能会降低网络性能。
以我们初始化为所有零值的网络为例。在这种情况下会发生什么?网络实际上根本不会学习任何东西。即使在进行梯度更新之后,由于我们计算梯度更新的固有方式,所有权重仍将为零。
想象一下,我们实施了该解决方案并解决了这个问题,然后决定将网络初始化都设置为相同的值0.5。现在会发生什么?网络实际上会学到一些东西,但是我们过早地规定了神经单元之间某种形式的对称性。
通常,通过根据 正态分布随机分配权重 来避免以任何形式的神经结构为前提是一个好主意。这通常在Keras中通过指定随机状态来完成(该状态具有随机性,但可确保测量结果可重复)。
初始化的数值范围应该是多少?如果我们为权重选择较大的值,则可能导致梯度爆炸。另一方面,较小的权重值可能会导致梯度消失。有一个最佳点可以提供这两者之间的最佳折衷,但是不能先验地知道,必须通过反复试验来推断。
Xavier初始化
Xavier初始化是分配网络权重的一种简单启发式方法。对于每个经过的层,我们希望方差保持相同。这有助于我们防止信号爆炸到高值或消失为零。换句话说,我们需要以使输入和输出的方差保持相同的方式来初始化权重。
权重是从具有零均值和特定方差的分布中得出的。对于具有m个输入的完全连接层:
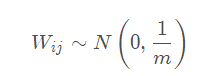
值m有时称为fan-in(扇入?):输入神经元的数量(权重张量中的输入单位)。
重要的是要记住,这是一种启发式方法,因此没有特别的理论支持-仅凭经验观察到它表现良好。您可以在此处阅读原始论文。
He Normal初始化
He Normal初始化与Xavier初始化基本相同,区别在于方差乘以两倍。
在这种方法中,权重的初始化要考虑前一层的大小,这有助于更快,更有效地实现cost function的全局最小值。权重仍然是随机的,但是范围取决于神经元先前层的大小。这提供了受控的初始化,因此可以更快更有效地进行梯度下降。
对于ReLU,建议:
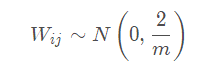
Bias 初始化
Bias 初始化是指应如何初始化神经元的Bias。我们已经描述了权重应该以某种形式的正态分布随机初始化(以打破对称性),但是我们应该如何应对Bias呢?
简而言之,初始化Bias 的最简单且常用的方法是将其设置为零-因为不对称破坏是由权重中的较小随机数提供的。对于ReLU非线性,有些人喜欢对所有Bias使用较小的常量值(例如0.01),因为这样可以确保所有ReLU单元在开始时均会触发,从而获得并传播一定的梯度。但是,尚不清楚这是否能提供一致的改进,更常见的是将Bias设置为零。
Bias初始化的一个主要问题是避免隐藏单元内的初始化饱和-例如在ReLU中,可以通过将偏置初始化为0.1而不是零来实现。
预初始化Pre-Initialization
初始化权重的另一种方法是使用预初始化。这对于用于图像处理的卷积网络很常见。该技术涉及导入已经训练的网络(例如VGG16)的权重,并将其用作要训练的网络的初始权重。不就是transfer learning么
该技术仅对于与训练网络相似的数据的网络才真正可行。例如,VGG16是为图像分析而开发的,如果您打算分析图像,但数据集中的数据样本很少,则预初始化可能是一种可行的方法。这是迁移学习背后的基本概念,但是术语预初始化和迁移学习不一定是同义词。
批归一化Batch Normalization
到目前为止,我们已经研究了使用动量和自适应学习率来导航神经网络的损失曲面的方法。为了最小化网络中的先验偏差,我们还研究了几种参数初始化方法。在本节中,我们将研究如何操纵数据本身以帮助我们进行模型优化。
为此,我们将研究Batch Normalization及其可用于帮助优化神经网络的一些方法。
特征归一化
特征归一化(Feature Normalization)正好是它所说的,它涉及在应用学习算法之前对特征进行归一化。这涉及重新缩放功能,通常在预处理期间完成。
根据“Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”一文,使用特征缩放比不使用可以更快地梯度下降并收敛。
有几种缩放数据的方法。一种常用方法是 min-max normalization ,缩放到[0,1]或[-1,1]范围。这是通过将每个值减去最小值,然后根据数据集中存在的值的范围对其进行缩放来完成的。如果数据分布高度不均匀,则可能导致许多值聚集在一个位置。如果发生这种情况,有时可以通过采用特征变量的对数来缓解(因为这有使异常值柔和的趋势,因此它们对分布的影响较小)。
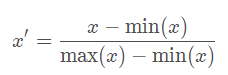
另一个常用的方法是mean normalization,它与min-max normalization基本相同,只是从每个值中减去平均值。这是比较不常见的一个。
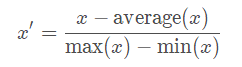
特征标准化(Feature standardization)使数据中每个特征的值具有零均值(当减去分子中的均值时)和单位方差。此方法已广泛用于许多机器学习算法(通常是涉及基于距离的算法)中的标准化。一般的计算方法是确定每个特征的分布平均值和标准偏差。接下来,我们从每个特征中减去平均值。然后,我们将每个特征的值(均值已减去)除以其标准偏差。
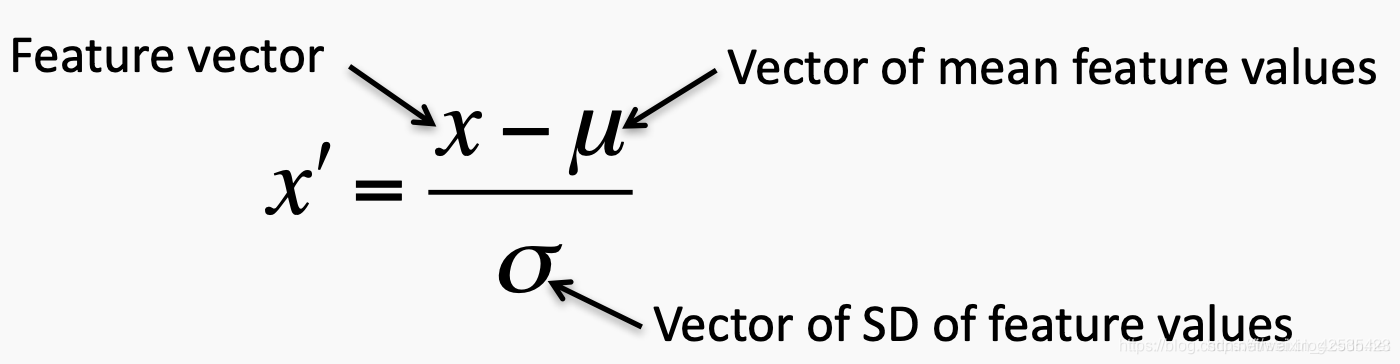
通过执行归一化,我们 改善了数据集的distortion (例如,一个特征与另一个特征相比的伸长率),并使数据更加均匀。
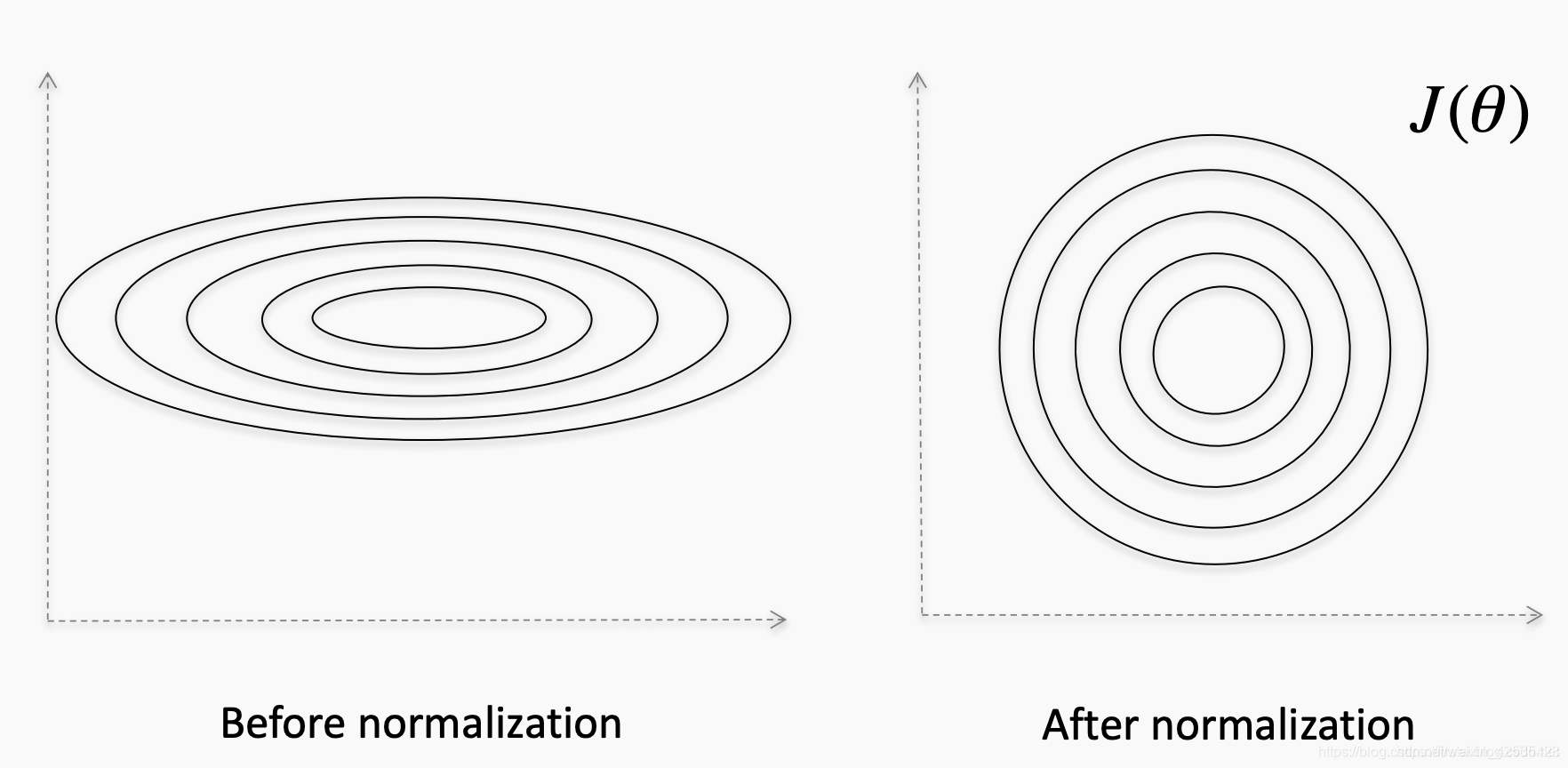
内部协方差平移Internal Covariance Shift
这个想法也来自前面提到的论文 “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”.
作者定义了Internal Covariance Shift:
We define Internal Covariate Shift as the change in the distribution of network activations due to the change in network parameters during training.
这可能有点含糊,这里我们详细解释一下。在神经网络中,第一层的输出进入第二层,第二层的输出进入第三层,依此类推。当层的参数发生更改时,到后续层的输入分布也会更改。
输入分布的这些变化对于神经网络可能是个问题,因为它倾向于减慢学习速度,尤其是可能具有大量层次的深度神经网络。
公认的是,如果输入已被白化(即零均值,单位方差)并且不相关,并且内部协变量平移导致相反的结果,则网络收敛速度会更快。
- 批归一化是一种旨在减轻神经网络内部协变量平移的方法。
批归一化
批归一化是对神经网络其他层的特征标准化思想的扩展。如果输入层可以从标准化中受益,那么为什么其他网络层不可以呢?
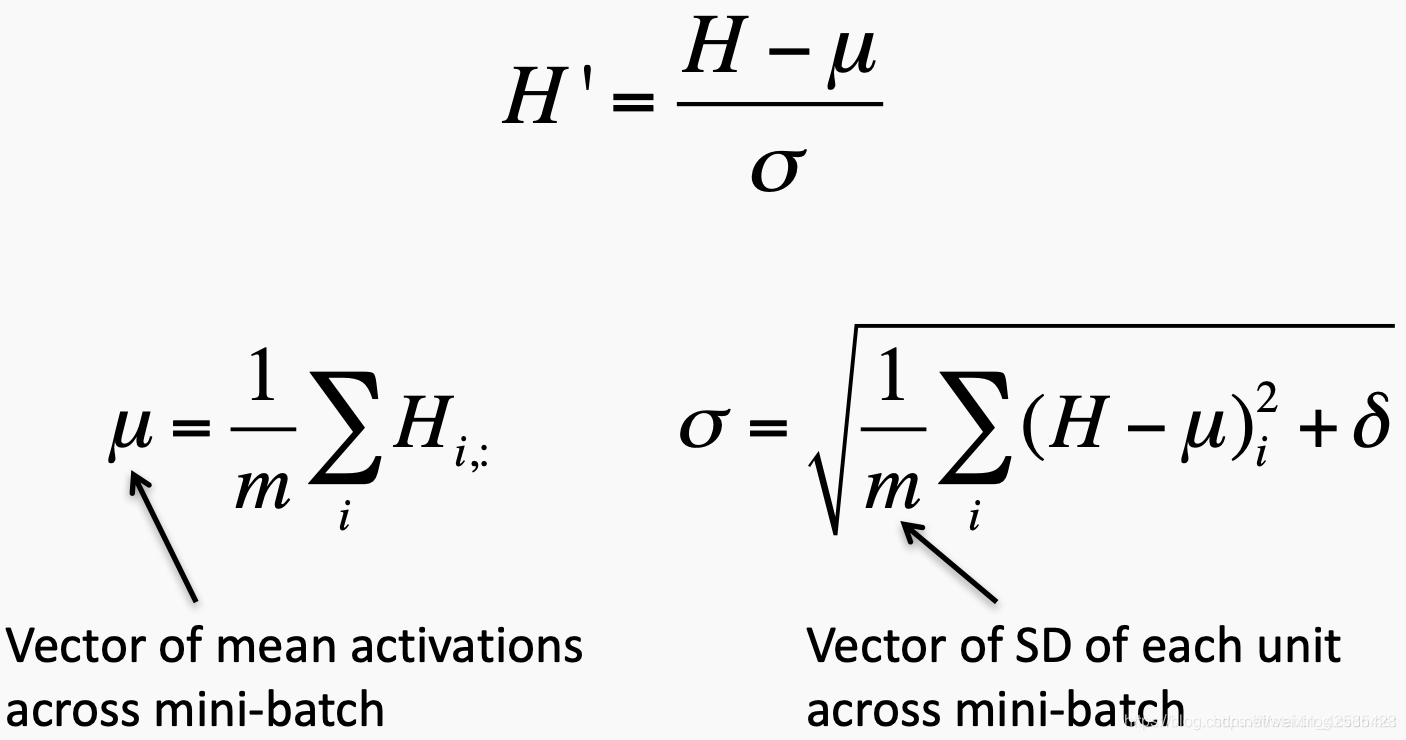
为了提高神经网络的稳定性,批归一化通过减去批平均值并除以批标准偏差来归一化先前激活层的输出。
- 批归一化允许网络的每一层自己独立于其他层进行学习。
但是,在通过一些随机初始化的参数进行激活输出的这种shift/scale之后,下一层的权重不再是最佳的。如果SGD(随机梯度下降)是使损失函数最小化的一种方法,则它将取消此标准化。
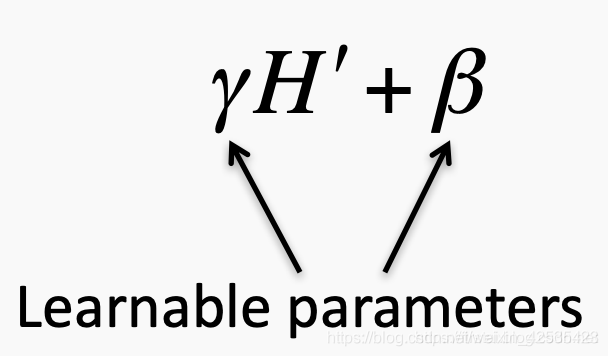
因此,批归一化将两个可训练的参数添加到每一层,因此将归一化的输出乘以“标准差”参数(γ),并添加“均值”参数(β)。换句话说,批归一化允许SGD通过为每次激活仅更改这两个权重来进行denormalization,而不是通过更改所有权重来失去网络的稳定性。
此过程称为批归一化变换 batch normalization transform。
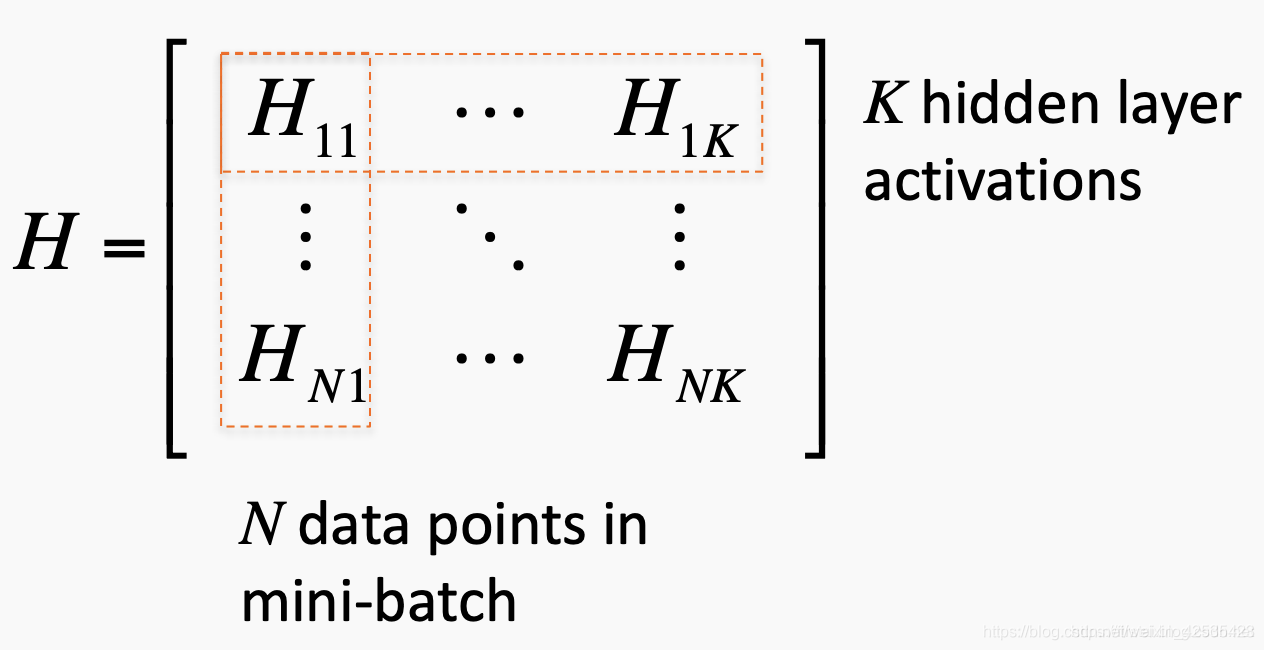
为了直观地说明这一点,我们可以分析下图。我们正在看紧随输入层之后的第一个隐藏层。对于N个小批量中的每一个,我们都可以计算输出的平均值和标准偏差。
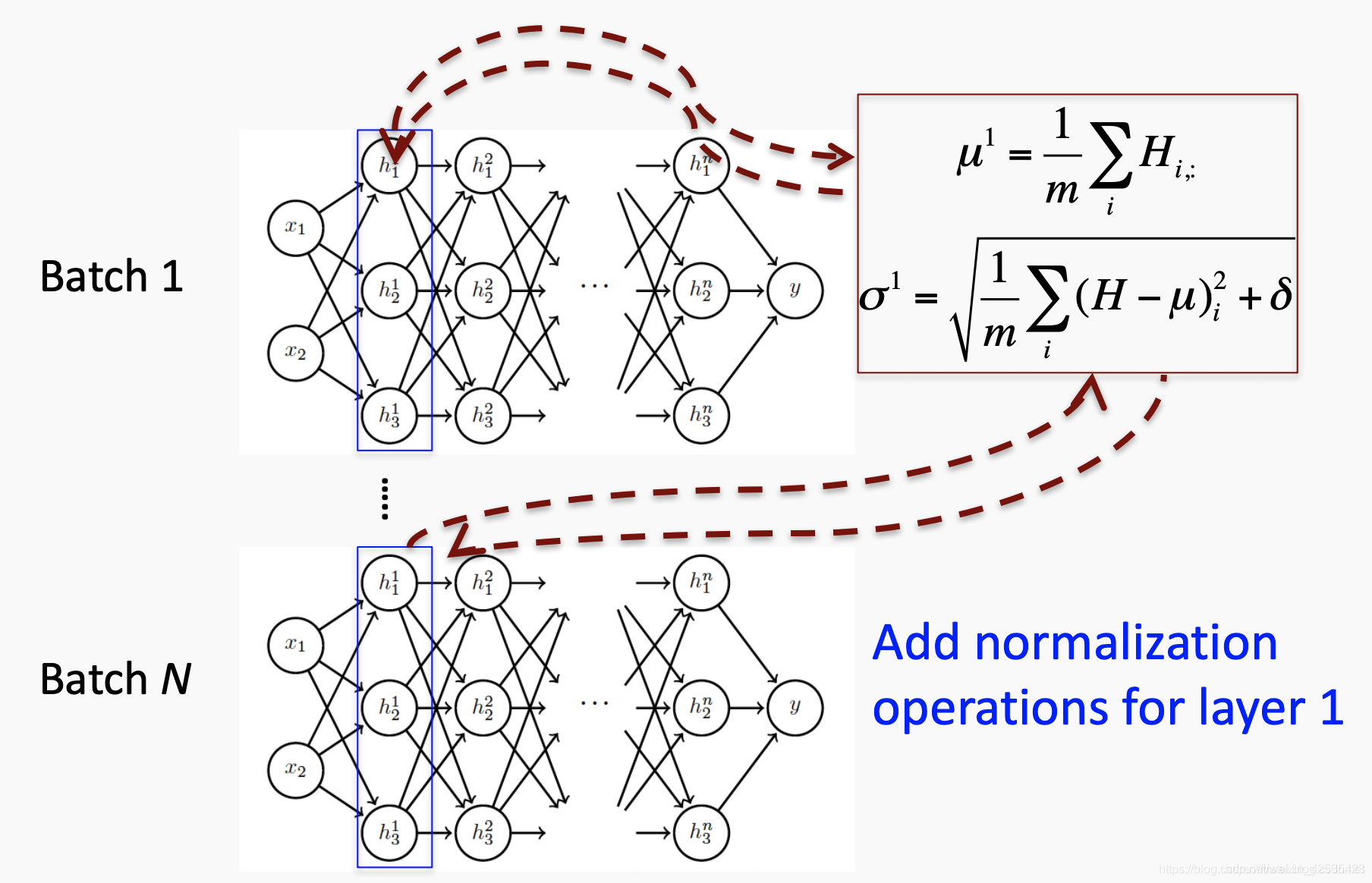
随后对所有后续隐藏层重复此操作。此后,我们可以区分N个迷你批次的联合损失,然后通过归一化操作反向传播。
批归一化可减少过度拟合,因为它具有轻微的正则化效果。与dropout类似,它为每个隐藏层的激活添加了一些噪音。
在测试期间,平均值和标准偏差将替换为训练期间收集的运行平均值。这与使用整体统计信息而不是小批量统计信息相同,因为这可以确保输出确定性地取决于输入。
- 使用batch normalization有几个优点:
- 减少internal covariant shift。 减少梯度对参数或它们的初始值的比例的依赖性。
- 对模型进行正则化,减少对dropout,光度畸变photometric distortions,局部响应归一化和其他正则化技术的需求。
- 允许使用饱和非线性和较高的学习率。

