
- 1一文读懂AI大模型发展历程_openai公司 大模型发展阶段
- 2Sql注入以及靶场演示_sql靶场
- 3python模块的加载方式有几种_python动态加载模块、类、函数
- 4微信小程序将高德地图转为腾讯地图的自行车路线规划
- 5hcie数通和云计算选哪个好?
- 6编写更好的 Java 单元测试的 7 个技巧_java单元测试可配置化
- 7浅谈“归一化”处理_归一化处理是什么意思
- 8禁止使用计算机热点,设置Windows 10 禁止自动连接Wifi热点
- 9上手开发鸿蒙OS上的ArkTs应用(一)_arkts 编译器 开发环境
- 10win10 msys2 vs2015 ffmpeg3.3.3 编译 带x264 aac_error: x264 not found using pkg-config
后门攻击与对抗样本攻击的比较研究
赞
踩
目录
一、Introduction
1.什么是后门攻击?
部分论文的解释:
(1)神经网络后门攻击[1]:对于任意的神经网络模型 M、其训练过程 P 和攻击算法 A,模型 M 经算法 A 攻击后得到模型 M'或训练过程 P经算法 A 后训练得到模型 M',当 M'满足条件① 和条件②时,称算法 A 为神经网络后门攻击算法。
① 对于正常输入,模型 M'与模型 M 表现相同。
② 对于触发输入,模型 M'将会发生错误,产生攻击者期望的输出。
神经网络后门攻击植入后门实质上是通过对模型进行修改实现的,实施神经网络后门攻击将导致模型向攻击者期待的方向发生变化。模型发生变化是为了在模型中留下“陷门”,使修改后的模型对触发输入敏感,使任何触发输入在模型的推理过程中发生攻击者设计的错误
(2)后门攻击[2]的目的则是使模型学习到攻击者指定的内容, 其对正常样本仍旧具有良好的测试效果, 但对于中毒样本则会输出攻击者预先设定的标签。
后门攻击也具有以下特点:
复杂性:模型在训练阶段涉及更多的步骤, 包括数据采集、数据预处理、模型构建、模型训练、模型保存、模型部署等等
隐蔽性:后门攻击对于正常样本来说没有异常, 只有当样本具有后门触发器时才会发生异常, 因此用户在使用时难以察觉, 此外, 后门攻击注入的中毒样本通常非常之少, 仅需 0.5%左右。
实际性:后门攻击保证模型在正常测试集上仍具有良好效果, 因此经过后门攻击的模型很大概率会部署并投入使用。
(3)我的理解:攻击者在模型的训练阶段,对训练数据修改或者直接对模型的部分参数进行修改,使得模型完成训练后,对正常的测试数据集有正确的输出,而对于中毒样本输出攻击者指定的内容。(对某些模型输入的输出结果,掌握在我手里,我想输出什么就输出什么)
2.什么是对抗样本攻击?
对抗性输入攻击[3-4]也称逃逸(evasion)攻击,是一种通过构造对抗性输入,从而使神经网络模型发生错误的攻击方式。该攻击通过对模型的输入进行人类不易察觉的修改,使正常的神经网络模型行为异常。现有的对抗性输入攻击可分为无目标攻击与有目标攻击。前者仅简单地希望模型发生错误,后者希望模型将修改后的输入即对抗性输入推理为特定目标。(你的模型虽然很厉害,但是面对我的对抗样本,你的模型也是是非不分)

图1 对抗样本概念图
3.后门攻击与对抗样本攻击的区别
(1)攻击的阶段上:对抗样本攻击在模型的推理阶段,也就是对训练好的模型进行攻击。后门攻击则是在模型训练的阶段进行攻击。
(2)在对模型的影响上:对抗样本攻击的是欺骗模型,让模型对一些对抗样本做出错误判断;后门攻击则是为了诱导模型,让模型对一些中毒数据输出为攻击者想要的结果。
4.补充数据投毒攻击
数据投毒攻击[5-8]则主要存在于模型的训练阶段, 通过对训练数据进行修改也即投毒, 对模型产生影响和破坏,使模型的泛化性能变差, 也即在测试集上的效果变差, 模型不能进行有效的学习, 甚至无法收敛。(我不干别的,我就是不想让你的模型训练成功)

表1 不同攻击算法的比较
二、思维导图
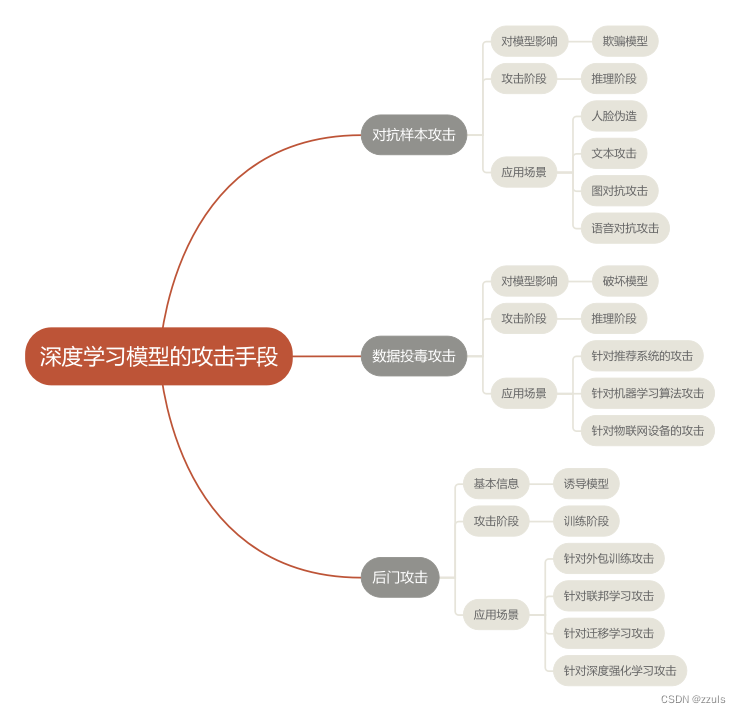
图2 思维导图
三、应用场景
1.对抗样本攻击应用场景
(1)人脸伪造:Bose 等人[9]对人脸识别算法进行攻击,通过在原始图像中加入人眼不可区分的微量干扰后,使得人脸无法被检测算法所定位.图4(a)为原始图像﹐检测算法可以准确定位,图4(b)为对抗样本,已经成功绕开了人脸检测算法.

图3 对抗人脸检测
Song 等人[10]更进一步采用对抗样本攻击人脸识别系统,并使其识别到指定的错误类别.如表1所示,从原始样本生成的相似对抗样本均被识别为指定的错误类别.

表2 对抗人脸识别
(2)文本攻击:文本对抗的工作也越来越多,并且文本对抗的成本更低,只需要增删改几个词,就有可能导致模型的识别结果出错.Gao等人[11]对文本分类模型进行了黑盒攻击,提出了DeepWordBug 算法.通过DeepWordBug对文本进行扰动,可以使得:
1)基于Word-ISTM的模型识别率降低68%
2)基于Char-CNN的模型识别率降低48%.
具体攻击方式如下:
DeepWordBug 算法会先选择最可能改变模型分类的英文单词,然后将该英文单词进行扰动,从而使得文本分类模型识别错误.例如图4中通过将Place改成Plcae,heart改成herat后,识别模型将就正面的评价识别成了负面.
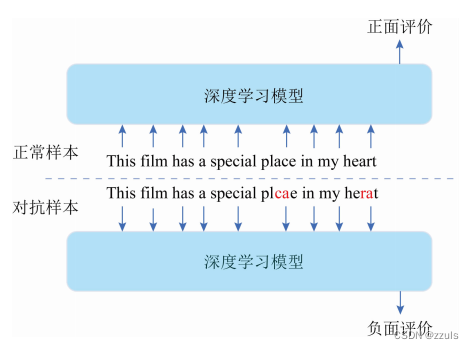
图4 文本攻击
(3)图对抗攻击:Zigner等人[12]提出了针对图深度学习模型的对抗攻击方法,是首个在属性图上的对抗攻击研究。他们的研究结果表明:
1)通过操纵图结构和节点特征,可以显著降低节点分类的准确率;
2) 通过保持重要的数据特征,例如度分布、特征共现,可以确保扰动不被察觉;
3) 攻击方法是可迁移的.
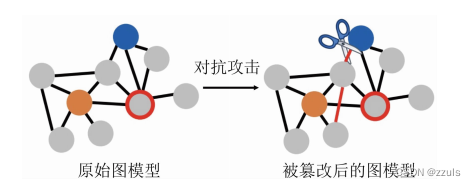
图5 图攻击
(4)语音对抗攻击: Wei [13] 介绍对抗样本相关概念的基础上, 选取语音识别中的文本内容识别、声纹身份识别 两个典型任务, 按照从白盒攻击到黑盒攻击、从数字攻击到物理攻击、从特定载体到通用载体的顺序, 采取从易到难、逐步贴 近实际场景的方式, 系统地梳理了近年来比较典型的语音对抗样本的攻击方法。
2.后门攻击的应用场景
(1)外包训练:由于神经网络特别是卷积神经网络需要大 量的训练数据和数百万个权重,对其进行训练也就需要大量的算力。对大多数人和企业来说,选择将模型的训练外包给服务商是更加合理的 选择。在这种场景下,攻击者对模型的训练过程有完全的控制,可以在不受限制的情况下构造后门。最早的 BadNets[14]的简单攻击就是针对该场 景提出的,但是这种场景最显著的问题是攻击者的能力过大,攻击现实性较低
(2)迁移学习:直接控制或间接影响预训练模型的再训练过程,利用数据中毒等手段植入后门,如 Trojaning Attack[15]和 Clean-Label Attack[16]两种攻击方法。在Trojaning Attack 中,攻击者对于再训练过程具有完全的控制,同时可以访问预训练模型,可以自由选取训练样本对模型进行再训练。Clean-Label Attack 中攻击者不能直接控制再训练过程,但能通过上传“干净”的中毒样本间接影响模型的再训练。另一方面,攻击者可以自行构造中毒预训练模型,使受害者对中毒模型进行再训练,从而把后门植入受害者自行再训练生成的目标模型中。
(3)强化深度学习:Yang 等在文献[17]中提出针对深度强化 学习的后门攻击,利用输入间的顺序依赖性,该后门的触发可在极短的时间内完成,只需一次触发就能长久地影响模型的性能。而
(4)联邦学习:联邦学习构造了一个能使成千上万的参与者在保密自身数据的情况下共同训练模型的框架。在训练中,中央服务器将训练集的随机子集分发给各参与者,由各参与者在本地进行训练,然后将更新的模型提交给服务器,由服务器根据参与者提交模型的平均对联合模型进行更新。同时,为了保护参与者本地模型的机密性,联邦学习采用了安全聚合的方式。例如,文献[18]利用了联邦学习场景下参与者可本地训练更新模型的特点,由攻击者在本地训练中毒模型提交服务器。同时因为该中毒模型在安全聚合机制下是保密的,这使得无法对该中毒模型进行异常检测,使中毒模型不易被发现
3.典型的神经网络后门攻击相关研究

表3 典型的神经网络后门攻击相关研究
四、总结体会
今天的论文阅读主要是概念性的,是对后门攻击、数据投毒攻击和对抗样本攻击的总体理解,它们让模型失去其原有的正常功能。理解了三种常见的人工智能模型攻击手段:对抗样本攻击,数据投毒攻击和后门攻击的基本概念,和他们攻击方式的比较,并且知道了他们之间的区别和联系。其次就是研究了对抗样本攻击和后门攻击的应用场景。因为这三种攻击涉及到的知识点较多,所以技术和算法方面还没有看太多,后面要针对性的看,看看文章提到的参考文献,再对这次文章进行扩充。之后的话,还要考虑,这些模型攻击技术是否可以用于人工智能的数据隐私保护问题,并用严谨的实验论证自己的idea是否可靠。
除了以上之外,今天也学会了如何更规范的写阅读心得,感谢老师的指导,养成良好的写作习惯对未来编写论文也有很大的帮助。
五、reference
[1]Qingyin TAN, Yingming ZENG, Ye HAN, Yijing LIU, Zheli LIU. Survey on backdoor attacks targeted on neural network[J]. Chinese Journal of Network and Information Security, 2021, 7(3): 46-58.
[2]Qingyin TAN, Yingming ZENG, Ye HAN, Yijing LIU, Zheli LIU. Survey on backdoor attacks targeted on neural network[J]. Chinese Journal of Network and Information Security, 2021, 7(3): 46-58.
[3]C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, R. Fergus. Intriguing properties of neural networks. ArXiv: 1312.6199, 2013
[4] SZEGEDY C, ZAREMBA W, SUTSKEVER I, et al. Intriguing properties of neural networks[J]. arXiv preprint arXiv:1312.6199, 2013.
[5] Barreno M, Nelson B, Sears R, et al. Can Machine Learning Be Secure? [C]. The 2006 ACM Symposium on Information, computer and communications security, 2006: 16-25.
[6] Biggio B, Nelson B, Laskov P. Support Vector Machines under Adversarial Label Noise[C]. Asian conference on machine learning, 2011: 97-112.
[7] M. Kloft, P. Laskov. Online anomaly detection under adversarial impact[C]. The Thirteenth International Conference on Artificial Intelligence and Statistics, 2010: 405-412.
[8] A. Shafahi, R. Huang, M. Najibi, et al. Poison frogs! Targeted clean-label poisoning attacks on neural networks[C]. Advances in Neural Information Processing Systems, 2018: 6103-6113
[9]Bose A,Aarabi P. Adversarial attacks on face detectors using neural net based constrained optimization[C]//Proc of the 20th Int Workshop on Multimedia Signal Processing(MMSP). Piscataway,NJ:IEEE,2018
[10]Song Qing,Wu Yingqi,Yang Lu. Attacks on state-of-theart face recognition using attentional adversarial attack generative network[J]. arXiv preprint arXiv:181112026,2018
[11]Gao Ji,Lanchantin J ,Soffa M,et al.Black-box generation of adversarial text sequences to evade deep learning classifiers[C]//Proc of Security and Privacy Workshops(SPW).Piscataway,NJ:IEEE,2018:50-56
[12]Zugner D,Akbarnejad A,Günnemann S. Adversarialattacks on neural networks for graph data[C]//Proc of the24th Int Conf on Knowledge Discovery &. Data Mining(KDD). New York:ACM,2018
[13]WEI Chunyu,SUN Meng,ZOU Xia,ZHANG Xiongwei.Reviews on the Attack and Defense Methods of Voice Adversarial Examples[J].Journal of Cyber Security,2022,7(1):100-113
[14] GUT, DOLAN-GAVITT B, GARG S. BadNets: ldentifying vulne-rabilities in the machine learning model supply chain[J]. arXiv pre-print arXiv:1708.06733,2017.
[15]LIU Y, MA S,AAFER Y, et al. Trojaning attack on neural net-works[R]. 2017.
[16]SHAFAHI A, HUANG W R,NAJIBI M, et al. Poison Frogs! tar-geted clean-label poisoning attacks on neural networks[C]l/lAd-vances in Neural Information Processing Systems. 2018: 6103-6113.
[17]YANG Z,IYER N, REIMANN J, et al. Design of intentional back-doors in sequential models[J]. arXiv preprint arXiv: 1902.09972,2019.
[18]BAGDASARYAN E,VEIT A,HUA Y, et al. How to backdoorfederated learning[J]. arXiv preprint arXiv: 1807.00459,2018.

