
热门标签
热门文章
- 1Android 5.0 ~ 14访问Android/data(obb)目录的方法_android14解锁data目录
- 2UiPath发送包含图片或表格的邮件_uipath邮件正文带图片
- 3Uipath Excel Application Scope详解
- 4使用Python和pymupdf创建简单的PDF阅读器_python开发的pdf阅读器
- 5linux/unix设计思想pdf,《深入理解Android内核设计思想》PDF版本下载
- 6EditPlus 正则表达式 实战_5_居民健康档案怎么用正则表达式写
- 7Base64 File transfer over a serial line/tty/linux_filetransfer base64
- 8vnc viewer 远程桌面,vnc viewer 远程桌面使用教程
- 9Soft Robotics:两栖环境下螃蟹仿生机器人的行走控制
- 10OpenCV4入门到进阶_opencv4教程
当前位置: article > 正文
Pytorch实战——气温预测(基础)附完整代码_pytorch 气温预测案例数据集
作者:凡人多烦事01 | 2024-04-04 10:33:59
赞
踩
pytorch 气温预测案例数据集
一. 数据集
http://链接:https://pan.baidu.com/s/1mVAIWZquUyaCpgj1K51o5A 提取码:abcd
该数据集记录了一年内的气温信息,我们将针对于此进行分析
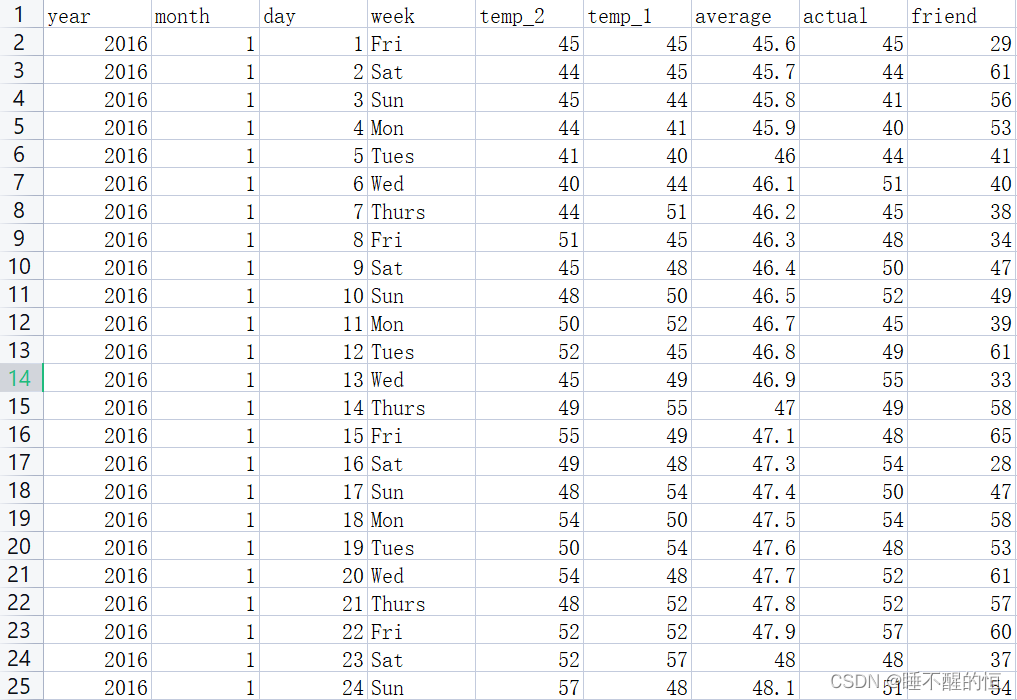
以上是部分数据情况,请查看
二.气温预测实战
2.1 读取数据,查看数据
- data = pd.read_csv("temps.csv")
- print(data.head()) #查看数据是什么样子的
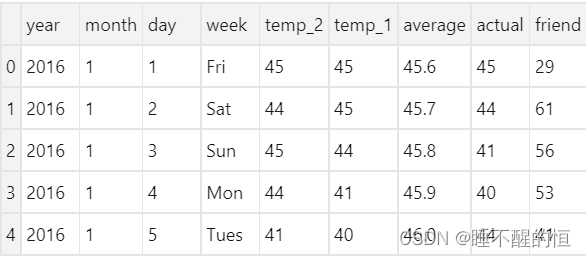
- year,moth,day,week分别表示的具体的时间
- temp_2:前天的最高温度值
- temp_1:昨天的最高温度值
- average:在历史中,每年这一天的平均最高温度值
- actual:这就是我们的标签值了,当天的真实最高温度
- friend:这是朋友的猜测值,不怎么重要,可看可不看
2.2 查看维度
print('查看数据维度:',data.shape)![]()
说明了一共有348条数据,9个特征
2.3 处理时间数据
- import datetime
- years = data['year']
- months = data['month']
- days = data['day']
- #转化为datetime格式
- date = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year,month,day in zip(years,months,days)]
- date = [datetime.datetime.strptime(date_1,'%Y-%m-%d') for date_1 in date ]
- print(date[:5])

此时可看到,时间数据都存在于一起
2.4 绘制特征图像
-
- #解下来进行绘图操作
- plt.style.use('fivethirtyeight')
- fig,((ax1,ax2),(ax3,ax4)) = plt.subplots(nrows=2, ncols=2, figsize= (10,10))
- fig.autofmt_xdate(rotation = 45)
-
- ax1.plot(date,data['actual'])
- ax1.set_xlabel(' ')
- ax1.set_ylabel('Temperature')
- ax1.set_title('Max Temp')
-
- ax2.plot(date, data['temp_1'])
- ax2.set_xlabel('')
- ax2.set_ylabel('Temperature')
- ax2.set_title('Previous Max Temp')
-
- ax3.plot(date, data['temp_2'])
- ax3.set_xlabel('Date')
- ax3.set_ylabel('Temperature')
- ax3.set_title('Two Days Prior Max Temp')
-
- ax4.plot(date, data['friend'])
- ax4.set_xlabel('Date')
- ax4.set_ylabel('Temperature')
- ax4.set_title('Friend Estimate')
-
- plt.tight_layout(pad=2)
- plt.show()
结果:
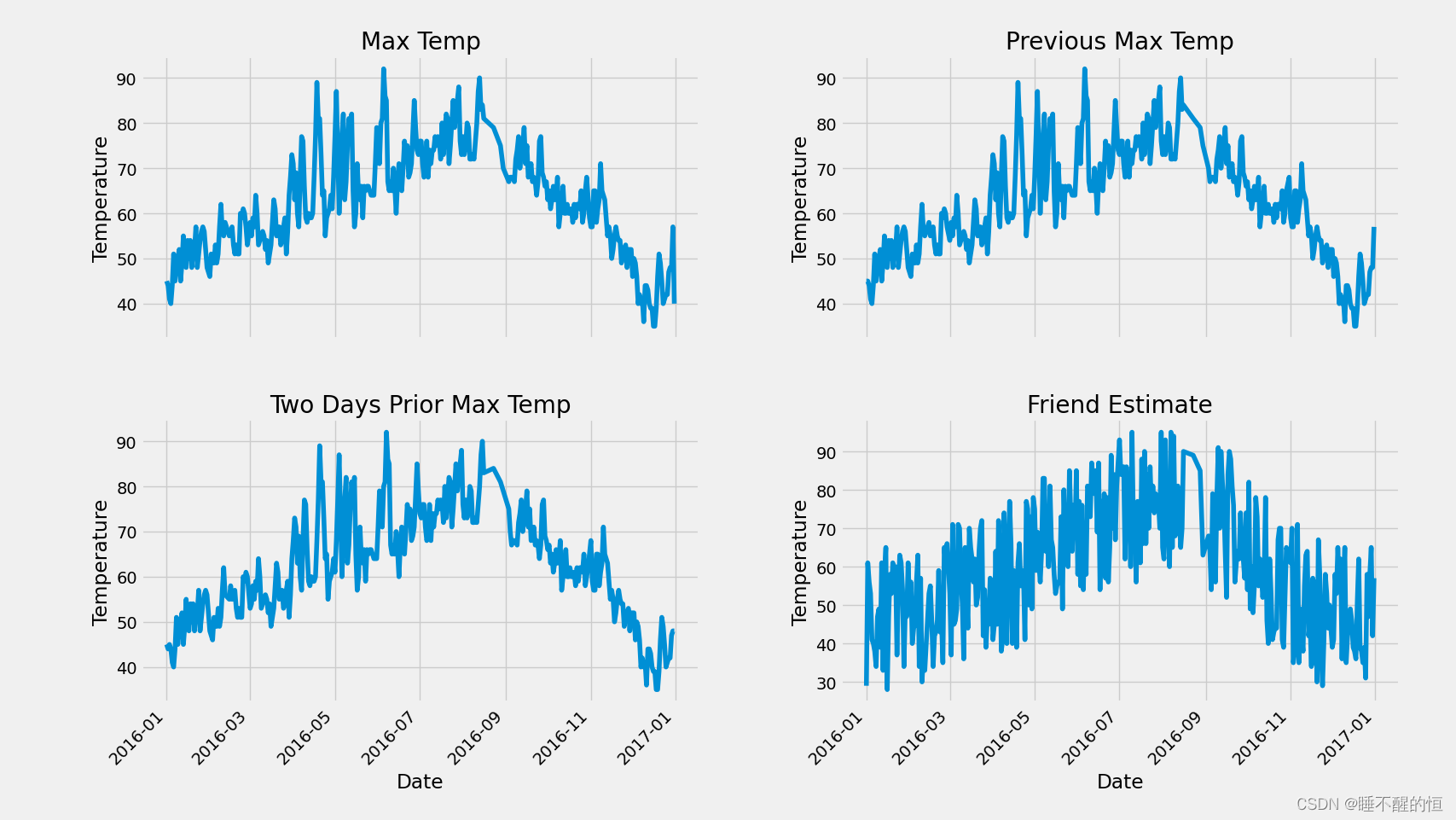
注意: 设置坐标倾斜角度,防止累计在一起,造成重叠。
2.5 对于字符串进行编码
在原数据集当中,因为在week列中存在字符串,并不是整数类型,所以这个时候进行编码处理,这里使用pandas中的get_dummies进行编码
- data = pd.get_dummies(data)
- print(data.head(5))
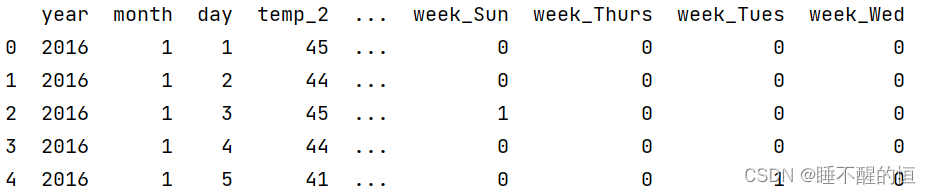
可见对于字符串进行了编码,对于存在的写为“1”,不存在的写为“0”
2.6 标签操作
对于标签,在该数据集当中也就是actual,我们先将其存入labels中,后将这一列在数据集当中删除,因为之后训练不会用该列。
- labels = np.array(data['actual'])
- data = data.drop('actual',axis=1)
- data_list = list(data.columns) #保存删除actual列后的名字
- #print(data_list)
2.7 归一化处理
在数据集当中,很明显数据集是大大小小的,有一些数值非常大,一些数值非常小,这个时候需要对其进行归一化,将所有数值按照权重、影响占比等缩放在(0,1)的范围当中
- from sklearn import preprocessing
- input_data = preprocessing.StandardScaler().fit_transform(data)
2.8 转化格式
将上述inpu_data,labels转化为tensor格式,pytorch可以运用这个格式。
- #转化为torch中的可用格式tensor
- x = torch.tensor(input_data , dtype= float)
- y = torch.tensor(labels , dtype=float)
2.8 构建网络模型
-
- #权重参数初始化
- weights = torch.randn((14,128),dtype=float,requires_grad=True)
- biases = torch.randn(128,dtype=float,requires_grad=True)
- weights2 = torch.randn((128,1),dtype=float,requires_grad=True)
- biases2 = torch.randn(1,dtype=float,requires_grad=True)
-
- learning_rate = 0.001
- losses = []
-
- for i in range(1000):
- #计算隐藏层
- hidden = x.mm(weights)+biases
- #给激活函数
- hidden = torch.relu(hidden)
- #预测
- predictions = hidden.mm(weights2)+biases2
- #计算损失
- loss = torch.mean((predictions - y) ** 2)
- losses.append(loss.data.numpy())
-
- if i % 100 == 0 :
- print('loss:',loss)
- loss.backward()
-
- #更新参数
- weights.data.add_(- learning_rate * weights.grad.data)
- biases.data.add_(- learning_rate * biases.grad.data)
- weights2.data.add_(- learning_rate * weights2.grad.data)
- biases2.data.add_(- learning_rate * biases2.grad.data)
- #记得清空权重参数,因为每次迭代会累计
- weights.grad.data.zero_()
- biases.grad.data.zero_()
- weights2.grad.data.zero_()
- biases2.grad.data.zero_()
首先要进行权重的初始化,来为后面的学习打下基础,切记需要将每一次迭代后的梯度进行清零,否则将会一直累加,影响结果。
各个参数的设置是根据前面的特征数量来进行确定,我们要进行128个神经元的设计,需要凑一个14*128的矩阵给weights,同理,最后预测结果为一个结果,所以我们要将weights2设置为128*1.
最终预测结果为:
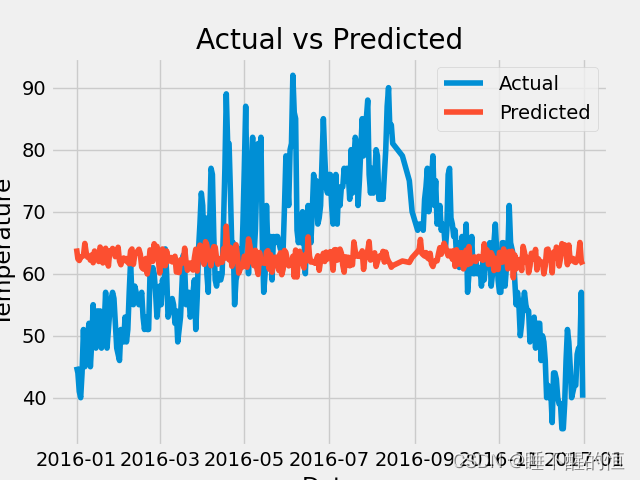
可见,使用该方法来进行预测时,其结果准确率不怎么高,下次我将更新神经网络,将准确率提高!谢谢观看!
完整代码如下:
- import numpy as np
- import pandas as pd
- import matplotlib
- import torch
- from matplotlib import pyplot as plt
-
- data = pd.read_csv("temps.csv")
- print(data.head()) #查看数据是什么样子的
- print('查看数据维度:',data.shape)
- # 接下来进行处理时间数据,因为此时数据中的数据不支持计算机进行特征提取
- import datetime
- years = data['year']
- months = data['month']
- days = data['day']
- #转化为datetime格式
- date = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year,month,day in zip(years,months,days)]
- date = [datetime.datetime.strptime(date_1,'%Y-%m-%d') for date_1 in date ]
- print(date[:5])
-
- #解下来进行绘图操作
- plt.style.use('fivethirtyeight')
- fig,((ax1,ax2),(ax3,ax4)) = plt.subplots(nrows=2, ncols=2, figsize= (10,10))
- fig.autofmt_xdate(rotation = 45)
-
- ax1.plot(date,data['actual'])
- ax1.set_xlabel(' ')
- ax1.set_ylabel('Temperature')
- ax1.set_title('Max Temp')
-
- ax2.plot(date, data['temp_1'])
- ax2.set_xlabel('')
- ax2.set_ylabel('Temperature')
- ax2.set_title('Previous Max Temp')
-
- ax3.plot(date, data['temp_2'])
- ax3.set_xlabel('Date')
- ax3.set_ylabel('Temperature')
- ax3.set_title('Two Days Prior Max Temp')
-
- ax4.plot(date, data['friend'])
- ax4.set_xlabel('Date')
- ax4.set_ylabel('Temperature')
- ax4.set_title('Friend Estimate')
-
- plt.tight_layout(pad=2)
- plt.show()
-
- #处理字符串数据
- data = pd.get_dummies(data)
- print(data.head(5))
-
- labels = np.array(data['actual'])
- data = data.drop('actual',axis=1)
- data_list = list(data.columns) #保存删除actual列后的名字
- #print(data_list)
- data = np.array(data)
- #非常明显,data数据大大小小,现在进行归一化
- from sklearn import preprocessing
- input_data = preprocessing.StandardScaler().fit_transform(data)
- # print(input_data[0]),这里采用sklearn中的归一化函数
- print(labels)
- #转化为torch中的可用格式tensor
- x = torch.tensor(input_data , dtype= float)
- y = torch.tensor(labels , dtype=float)
-
- #权重参数初始化
- weights = torch.randn((14,128),dtype=float,requires_grad=True)
- biases = torch.randn(128,dtype=float,requires_grad=True)
- weights2 = torch.randn((128,1),dtype=float,requires_grad=True)
- biases2 = torch.randn(1,dtype=float,requires_grad=True)
-
- learning_rate = 0.001
- losses = []
-
- for i in range(1000):
- #计算隐藏层
- hidden = x.mm(weights)+biases
- #给激活函数
- hidden = torch.relu(hidden)
- #预测
- predictions = hidden.mm(weights2)+biases2
- #计算损失
- loss = torch.mean((predictions - y) ** 2)
- losses.append(loss.data.numpy())
-
- if i % 100 == 0 :
- print('loss:',loss)
- loss.backward()
-
- #更新参数
- weights.data.add_(- learning_rate * weights.grad.data)
- biases.data.add_(- learning_rate * biases.grad.data)
- weights2.data.add_(- learning_rate * weights2.grad.data)
- biases2.data.add_(- learning_rate * biases2.grad.data)
- #记得清空权重参数,因为每次迭代会累计
- weights.grad.data.zero_()
- biases.grad.data.zero_()
- weights2.grad.data.zero_()
- biases2.grad.data.zero_()
-
- predicted = predictions.detach().numpy()
- print(predicted)
- print('*******')
- print(predictions)
- plt.plot(date, labels, label='Actual')
- plt.plot(date, predicted, label='Predicted')
- plt.xlabel('Date')
- plt.ylabel('Temperature')
- plt.title('Actual vs Predicted')
- plt.legend()
- plt.show()
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/358088
推荐阅读
相关标签

