
- 1基于Java+SpringBoot+vue+node.js的图书购物商城系统详细设计和实现_购物网站代码设计
- 2Ubuntu20.04安装教程_安装ubuntu20分区安装
- 3数据结构之Set和Map
- 4学习python需要多长时间?_pyqt6的库需要多久才能掌握
- 5Flutter学习笔记-与原生(iOS swift)交互_flutter调用ios原生几种通信方法
- 6Postman Post请求四种参数传递方式与Content-Type对应关系_postman content type
- 7python除法向下取整函数_除法:经典除法,向下取整除法和真除法
- 8文生视频Sora模型发布,是否引爆AI芯片热潮
- 9python pytorch模型转onnx模型(多输入+动态维度)_torch.onnx.export 多输入
- 10ChatGPT中文版Prompt提示工程超详细指南《提示工程高级技巧与技术》Github最新破万星项目Meta AI前工程师解密百万年薪提示工程师GPT-4模型优化利器(二)不定期更新_零样本提示谁提出的
可解释性的相关介绍
赞
踩
一、可解释性的元定义(Meta-definitions of Interpretability)
- The extent to which an individual can comprehend the cause of a model’s outcome. [1]
- The degree to which a human can consistently predict a model’s outcome. [2]
可解释性:Interpretability、explainability
关键词:Interpretability、explainability、XAI、black model、Interpretable Deep Learning(IDL)
常规理解:
- 解释模型的决策
- 揭示模型内部机制
- 将有意义的模型或数式引入系统,试图使复杂模型或算法显式化,以便用户有充分理由信任或不信任特定模型。
如下图,可解释模型与黑盒模型的对比,可以揭示可解释性研究的目的。

二、可解释性的重要性、必要性
(1)必要性
准确率与可解释性之间存在trade-off(权衡)的关系,如下图

实现可解释性,可以使用与模型无关的技术,比如局部模型LIME或部分依赖图PDP。为神经网络设计解释方法涉及的两个理由。
- 神经网络在隐藏层中学习特征和概念,这需要专门的工具来揭示它们。
- 模型无关的方法大多是“从外部”观察神经网络决策过程,但梯度可以实现计算效率更高的解释方法。
当模型预测的结果与实际使用有所偏差,即模型给出结果和决策者想知道的是有区别的时候,就需要可解释性。对于一些效果很好的模型,但在不一样的数据实例上却表现出较差的性能,人们也会想知道其中的缘由。对于可解释性的必要性,可以从以下三个方面进行说明。
1.知识
在深度学习中,决策是基于大量的权重和参数,而参数通常是模糊的,与真实的世界无关,这使得很难理解和解释深度模型的结果[3]。可解释性将有助于让算法与人类价值观保持一致,帮助人们做出更好的决策,并给予人们更多的控制权。另外,当我们真正理解了一个模型,就可以仔细它的缺陷。因为模型的解释能力可以帮助我们找出它可能存在的弱点,并基于此知识使其更加准确和可靠。最后,可解释性是人们以符合伦理道德的方式使用深度神经网络的关键[4]。因此可解释性是非常重要的。
可解释性是一种潜在的属性,不可直接衡量,且缺乏既定的衡量标准,解释的程度不完善,有必要寻求一些评价可解释性方法的技术。Weld和Bansal[5]讨论了解释性调试和可验证性。Doshi等人[6]试图采用基于人类参与和应用程度分离的评价方法满足解释需求。如下图,人越多,任务越复杂,对可解释性和特殊性的要求越大。
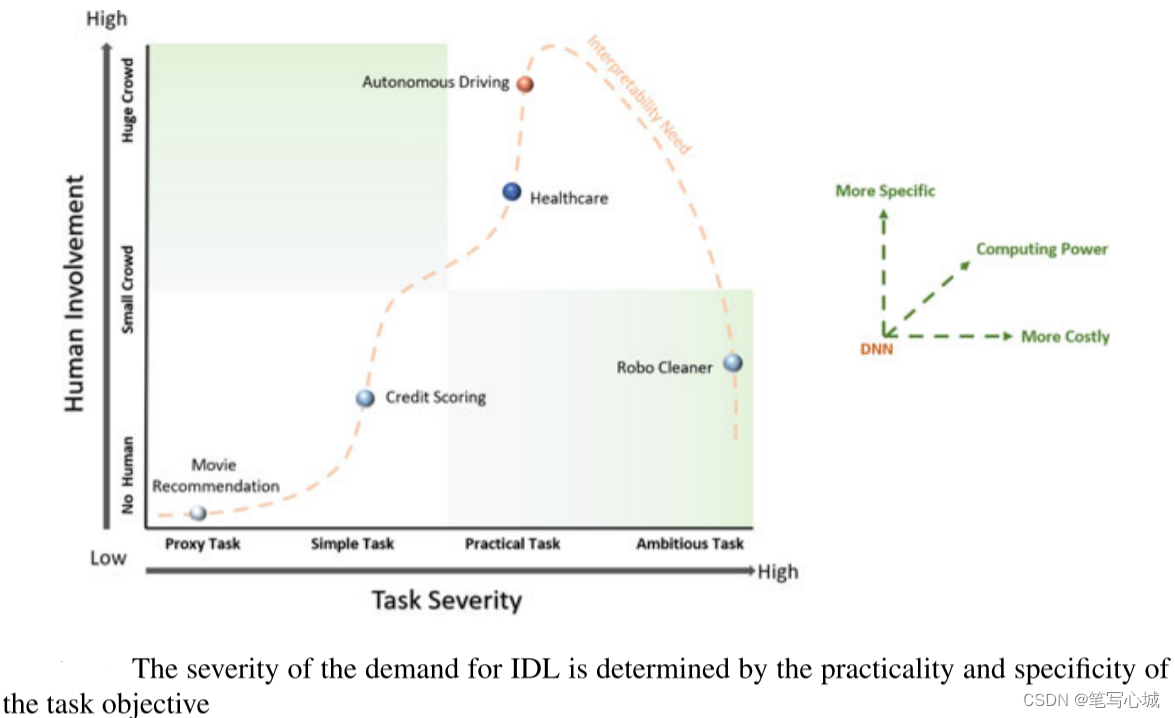
2.监管
研究界和商业之间的差距阻碍了最新深度学习模型在银行、金融、安全、卫生等行业的全面渗透,这些行业的流程在数字化转型方面一直滞后。这一问题通常出现在监管严格、不愿实施可能使其资产面临风险的技术的行业。即使有道德目的的保证,社会也必须确定该制度不会造成无意的伤害。随着可解释性需求的出现,如果认真对待可解释性需求并将其纳入立法,就必须理解其积极和消极的法律后果。Ribeiro等[7]在2016年的工作研究了任何分类器预测的可解释性,培养信任。
3.共识
目前为止,对于可解释性深度学习和评估技术还没有真正的共识。研究人员已经初步尝试开发基于推理的机器学习的评估策略。然而,深度学习模型,由于其更抽象的学习机制,使其研究人员已经认识到可解释性对道德标准和公平的影响。可解释性模型应该具有以下特征[8]。

(2)重要性
可解释性涉及各领域,对人类生活产生了巨大影响,如下图。

忽略系统的近似决策和可信结果变得更加困难,这种困境在于问题的不完全形式化,而且单一的指标(如分类准确度)对于大多数现实世界的任务来说都不够好。不完全性意味着关于问题的某些东西不能很好地建模[6]。当算法被用来自动做出决定时,可能会导致有害的歧视。算法透明性对于理解模型及其训练过程的动态是必要的。这是因为神经网络的目标函数具有实质上的非凸拓扑结构,深层网络无法提供真正新颖的答案,使模型的开放性受到了损害。这些都反映了可解释性研究的重要性。
三、可解释性策略和问题的基本概述
 四、可解释性研究的挑战
四、可解释性研究的挑战

参考文献
[1] Miller, T.: Explanation in artificial intelligence: insights from the social sciences. Artif. Intell. 267, 1–38 (2019)
[2] Kim, B., Khanna, R., Koyejo, O.O.: Examples are not enough, learn to criticize! criticism for
interpretability. Adv. Neural Inf. Process. Syst. 29 (2016)
[3] Angelov, P., Soares, E.: Towards explainable deep neural networks (XDNN). Neural Netw. 130, 185–194
[4] Geis, J.R., Brady, A.P., Wu, C.C., Spencer, J., Ranschaert, E., Jaremko, J.L., Langer, S.G., Kitts, A.B., Birch, J., Shields, W.F., et al.: Ethics of artificial intelligence in radiology: summary of
the joint European and North American multisociety statement. Can. Assoc. Radiol. J. 70(4),
329–334 (2019)
[5] Bansal, G.,Weld, D.: A coverage-based utility model for identifying unknown unknowns. In: AAAI Conference on Artificial Intelligence, vol. 32 (2018)
[6] Doshi-Velez, F., Kim, B.: Towards a rigorous science of interpretable machine learning (2017).
[7] Ribeiro, M.T., Singh, S., Guestrin, C.: “why should i trust you?” Explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining, pp. 1135–1144 (2016)
[8] Doshi-Velez, F., Kim, B.: Towards a rigorous science of interpretable machine learning (2017).

