- 1第十三届安徽省大学生程序设计大赛_K基地安全(树形DP)_程序设计植被保护题
- 2LeetCode 135:分发糖果
- 3uni-popup(实现自定义弹窗提示、交互)
- 4HCIP(BGP的聚合、反射器、联邦)_bgp聚合器
- 5day5-基于内容的推荐算法--物品画像和用户画像_pgc物品画像
- 6知识分享系列二:云原生技术_容器云原生技术
- 7有趣的大模型之我见 | Claude AI
- 8Git Rebase 操作的分析与整理_git rebase 临时分支
- 9毕业设计 STM32单片机的蓝牙智能计步器手环_蓝牙计步模块
- 10大数据毕业设计Python+Spark知识图谱视频推荐系统 视频情感分析 视频预测系统 视频推荐系统 视频可视化 视频爬虫 视频数据分析 计算机毕业设计 Python毕业设计 人工智能 知识图谱_pythonb站数据分析推荐系统
合合信息acge模型获C-MTEB第一,文本向量化迎来新突破_stella-mrl论文
赞
踩
前言: 在当今时代,大型语言模型以其惊人的发展速度和广泛的应用前景,正成为全球科技界的瞩目焦点。这些模型的强大能力,源自于背后默默支撑它们的Embedding技术——一种将语言转化为机器可理解的数值向量的关键技术。随着大型语言模型的不断突破,Embedding模型的重要性日益凸显,成为推动人工智能领域向前发展的核心动力。在这个充满无限可能的领域,每一次技术的飞跃都预示着新的变革和机遇。
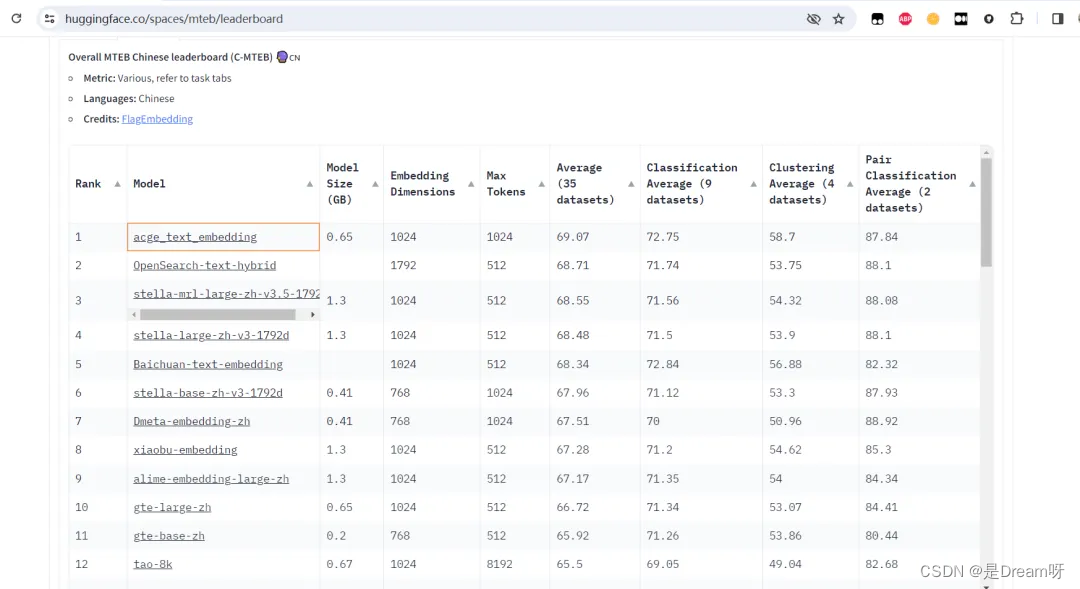
在最近落幕的MTEB中文榜单(C-MTEB) 竞赛中,合合信息凭借其创新的文本向量化模型acge_text_embedding,登顶榜单第一。
一、文本嵌入模型及其评估指标MTEB
1.Embedding技术是什么
Embedding就是指文本嵌入模型,说的通俗一点,如果有一本巨大的字典,这本字典里包含了世界上所有的单词,每个单词都有它独特的编号。现在,我们要让计算机理解语言,我们不能直接给它一堆单词,它也看不懂,因为它只会处理数字和逻辑。所以,我们需要一种方法,把每个单词转换成一个数字,这样计算机就能处理了。
Embedding技术就像是这个字典的现代版,但它不是简单地给每个单词一个编号,而是给每个单词一个复杂的数字“指纹”。 这个“指纹”是一个由很多数字组成的向量,就像是一串数字序列。这个序列能够捕捉到单词的很多特性,比如它的意思、它在句子中的作用,甚至是它的情感色彩。如果我们有“快乐”和“悲伤”这两个词,Embedding技术会生成两个不同的向量。尽管这两个词在字典里可能紧挨着,但它们的向量会相差很远,因为它们表达的情感是相反的,计算机可以通过比较这两个向量的距离,来理解这两个词在情感上的不同。
2.C-MTEB比赛含金量有多高
MTEB(Massive Text Embedding Benchmark)是衡量文本嵌入模型(Embedding模型)的评估指标的合集,是目前业内评测文本向量模型性能的重要参考。 MTEB中文榜单是一个在自然语言处理领域具有极高声誉的竞赛平台,专注于评估和推动中文文本向量化技术的发展,涵盖了分类、聚类、检索、排序、文本相似度、STS等6个经典任务,共计35个数据集,为深度测试中文语义向量的全面性和可靠性提供了可靠的实验平台。
该榜单汇集了全球范围内的顶尖科研机构、技术公司和专业团队,他们利用最新的技术和算法来构建能够高效处理和理解中文文本的模型。在这样的竞赛环境中,合合信息发布的文本向量化模型acge_text_embedding能够脱颖而出,夺得第一名,这一成就无疑是对合合信息技术实力和创新能力的有力证明,不仅体现在模型的性能上,更在于其对未来发展趋势的洞察和把握。
MTEB中文榜单的评估标准全面而严格,不仅考察模型的准确率,还包括模型的效率、稳定性、可扩展性等多个维度。acge模型能够在这些方面都达到顶尖水平,充分展现了其全面而卓越的综合实力。作为MTEB中文榜单的第一名,不仅代表了合合信息的技术成就,也为整个中文自然语言处理领域的发展做出了重要贡献,那就一起来了解一下acge模型的独特之处吧~
二、acge模型有什么独特之处
1.五种模型对比分析
MTEB中文榜单(C-MTEB)中有很多模型,要看就看最好的,咱们直接取前五名来横向对比一下,看一看这五个模型的区别,以及合合信息的acge模型,究竟有什么过人之处可以独占鳌头。
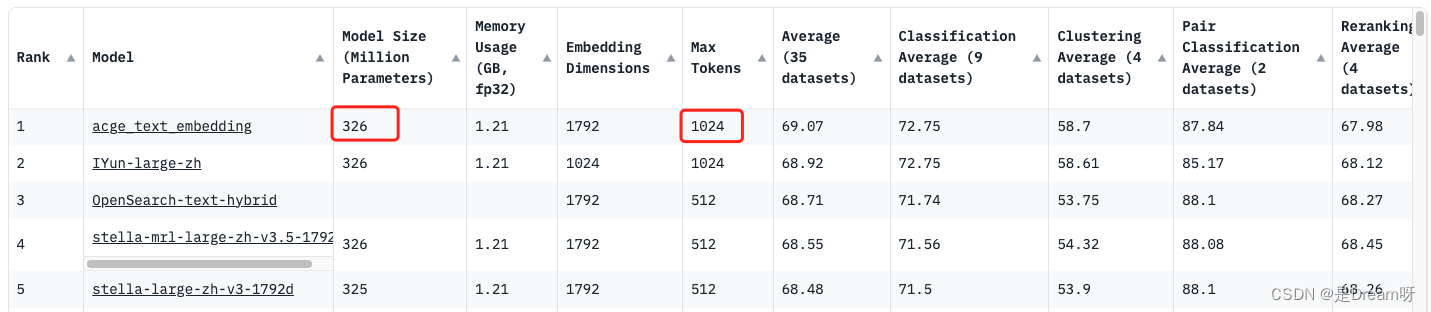
第一名:acge_text_embedding
- 模型大小: 拥有
326 Million Parameters,模型较小,占用资源少,又便于部署和维护。 - 分类任务性能: 在分类任务上,acge的平均准确率(Average)为
72.75%,在所有模型中排名最高,显示出其在处理分类任务时的卓越性能。 - 向量维度: 模型输入文本长度为
1024,可以捕捉更丰富的语言信息,满足绝大部分场景的需求。
第二名:IYun-large-zh
- 模型大小: 与acge_text_embedding相似,拥有
326 Million Parameters。 - 分类任务性能: 在分类任务上的平均准确率为
68.92%,略低于acge。 - 聚类任务性能: 表现良好,但同样略低于acge。
第三名:OpenSearch-text-hybrid
- 模型大小: 较大的模型,拥有
1792 Million Parameters,会导致更高的计算和存储需求。 - 分类任务性能: 平均准确率为
68.71%,聚类任务性能也表现不错,但整体上不如acge。
第四名:stella-mrl-large-zh-v3.5-1792
- 模型大小: 与OpenSearch-text-hybrid相同,为
1792 Million Parameters。 - 性能: 在分类和聚类任务上的平均准确率分别为
68.55%和68.45%,虽然表现良好,但仍不及acge_text_embedding。
第五名:stella-large-zh-v3-1792d
- 模型大小: 也是
1792 Million Parameters,较大模型的一员。 - 性能: 在分类任务上的平均准确率为
68.48%,聚类任务上为68.26%,整体性能在这些模型中稍显逊色。
2.acge模型优势出众
文本向量化模型acge_text_embedding在多个方面展现出了显著的优势:
- 性能卓越: 在分类任务上的平均准确率位居榜首,显示出acge在文本分类方面的显著优势。
- 资源效率: 模型较小,占用资源少,使得其在保持高性能的同时,也具有良好的资源效率,同时又便于部署和维护。
- 向量表示能力: 模型支持的输入文本长度为
1024,这是一个相对较高的维度,能够捕捉到文本数据中的丰富特征,提供更为精细的文本表示,更精确地表达文本信息,满足绝大部分场景的需求。 - 综合来看: 综合考虑性能和资源消耗,acge是一个平衡了效率和准确性的优秀模型。
acge模型不仅适用于分类任务,还适用于聚类任务,具有良好的通用性和适应性,能够应对多种不同的NLP任务,在多个数据集上都能保持稳定的性能,对于不同的数据集具有良好的适应性和泛化能力。acge模型在各个方面均展现出了显著的优势,使得它在文本向量化领域具有很高的实用价值和竞争力,此外,acge模型还支持可变输出维度,让企业能够根据具体场景去合理分配资源。
三、acge模型应用场景
合合信息发布的文本向量化模型acge_text_embedding以其高分类和聚类分数,在文本处理领域展现出强大的应用潜力,应用场景也是十分宽泛。
1. 热点事件的舆论分析与预测
当下互联网自媒体发展迅速,随着短视频的爆火,舆论消息传播十分迅速,舆论的产生会带来很强烈的公众的讨论和反应。acge模型可以对这些讨论进行实时的分类和聚类分析,将舆论分为支持、反对、中立等不同类别,并对每个类别中的讨论点进行聚类,以识别主要的争议点和关注焦点。
当我们作为参与者时,在分析新政策或者新活动的公众反应时,模型可以识别出不同群体的担忧点,如经济影响、社会公平等,并将这些担忧点进一步细分,为我们提供深入的洞察,帮助我们更好地理解大众的意见并优化实行的措施。
2. 个性化健康信息推荐系统
随着健康意识的提高,我们越来越关注个性化的健康信息。acge模型可以应用于健康相关的文本数据,如医疗新闻、研究论文、用户健康咨询等,通过分类和聚类,为用户推荐与其健康状况和兴趣相匹配的信息。
对于糖尿病患者,模型可以识别出与糖尿病管理相关的文章和讨论,如饮食建议、运动计划、新药物信息等,并将这些信息进行 分类和聚类,以便为用户提供定制化的内容推荐。 模型采用无监督学习方法,将提取的信息按照主题和内容进行分组。这样,用户可以根据自己的需求,快速找到感兴趣的信息类别。
3. 电商产品评论分析
当我们网购时,用户生成的评论是评估产品好坏和满意度的最主要依据,往往也是影响我们抉择最重要的一点。acge模型可以应用于这些评论数据,通过其高分类分数,将评论按照正面、中立和负面情感进行分类。同时,模型还可以对评论中提到的产品特性和用户需求进行聚类,帮助商家了解消费者的真实反馈。比如最近很热门的小米汽车,我们便可以依据该模型将评论中提到的千米加速、最高时速、最大功率等不同方面的反馈进行归类和对比总结。
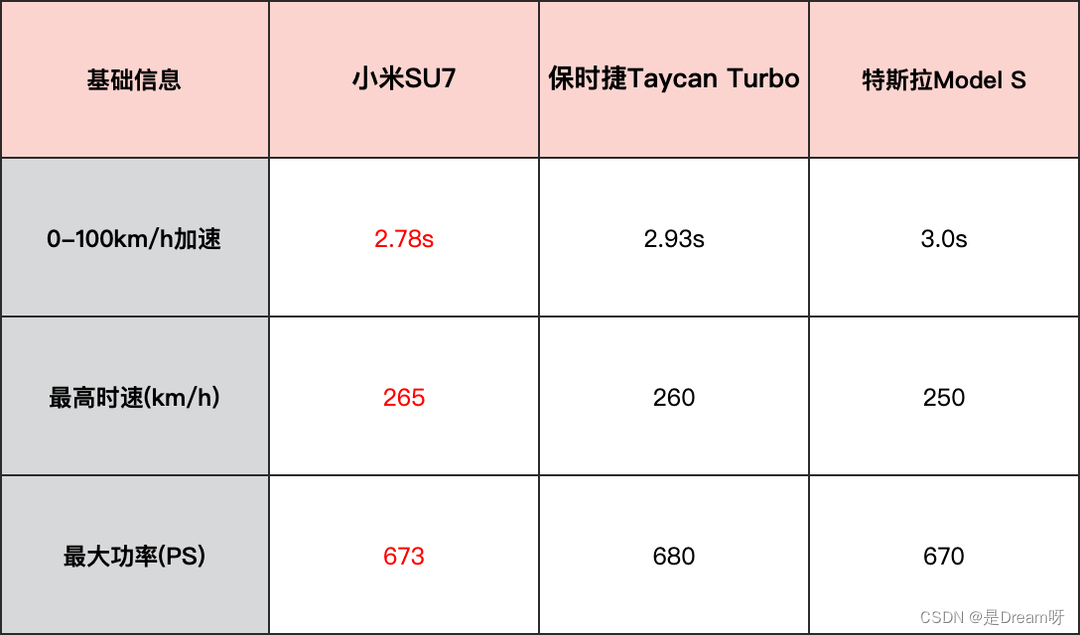
模型首先会识别评论文本中的关键信息,如产品特性、使用体验等。然后,利用其聚类功能,将相似的反馈聚集在一起,形成清晰的用户需求图谱。这样,作为生产厂家我们就可以针对性地改进产品和服务,提升用户满意度;而作为消费者,我们更可以清晰地了解到商品的优点缺点及大众观点,帮助我们更加合理的做出选择。
四、OCR云服务产品TextIn
最后,欢迎各位感兴趣的朋友访问 合合信息旗下的OCR云服务产品——TextIn的官方网站,了解更多关于智能文字识别产品和技术的信息,体验智能图像处理、文字表格识别、文档内容提取等产品,心动不如行动,快去试试吧:TextIn智能文字识别产品