
- 1打造个性化github主页 二 WakaTime - 动态统计你的工作量_怎么通过wakatime美化github
- 2树莓派科学小实验4B--08_倾斜传感器、干簧管、震动传感器_三个传感器树莓派实验
- 3OPENCV面试题
- 4CTF之逆向Reverse入门推荐学习知识点总结面向新手小白_ctf reverse
- 5springboot集成sse实现后端流式输出消息_springboot流式
- 6Android开发—基于OpenCV实现相机实时图像识别跟踪,入职3个月的Android程序员面临转正_opencv实时图像追踪
- 7小程序云函数调用_小程序云函数抓包
- 86个超级实用的免费网盘搜索网站分享_盘131
- 9遍历HashMap的五种方式_hashmap遍历
- 10kafka基础知识
大数据毕业设计Python+Spark知识图谱视频推荐系统 视频情感分析 视频预测系统 视频推荐系统 视频可视化 视频爬虫 视频数据分析 计算机毕业设计 Python毕业设计 人工智能 知识图谱_pythonb站数据分析推荐系统
赞
踩
研究意义
随着互联网的快速发展,人们面临着海量的视频内容,如何从这些繁杂的视频中找到自己感兴趣的内容成为一个重要的问题[1]。推荐系统作为一种解决信息过载问题的重要工具,能够根据用户的历史行为和偏好,预测用户可能感兴趣的内容,并对其进行推荐。在视频推荐领域,基于Hadoop和Spark的大数据框架的应用越来越广泛,它们能够处理大规模的视频数据,并对其进行深入的分析和挖掘。
本文旨在研究并设计一个基于Hadoop+Spark的视频推荐系统,该系统能够有效地利用大数据技术,对海量的视频数据进行处理和分析,并根据用户的行为和偏好进行视频推荐。与传统的推荐系统相比,基于Hadoop+Spark的视频推荐系统具有更高的处理能力和准确性,能够提供更加个性化的视频推荐服务[2]。
国内外研究综述
在国内,许多视频分享平台如Bilibili、爱奇艺、腾讯视频等都推出了自己的推荐系统,以提供个性化的视频推荐服务[3]。这些平台通常采用基于用户行为分析的推荐算法,根据用户的观看历史、点赞、评论等行为,挖掘用户的兴趣和偏好,并为其推荐相关的视频内容[4]。此外,国内的一些科研机构和高校也在推荐系统领域开展了相关研究,如清华大学、中国科学院计算技术研究所等。
在国外,推荐系统得到了广泛应用,不仅在视频领域,还在电商、新闻、音乐等领域得到应用[5]。在视频推荐领域,一些知名的视频分享平台如YouTube、Netflix等也推出了自己的推荐系统,根据用户的观看历史和偏好为其推荐相关的视频内容。此外,一些科研机构和高校也在推荐系统领域开展了相关研究,如斯坦福大学、麻省理工学院等[6]。
在基于Hadoop和Spark的视频推荐系统方面,一些国内外的研究机构和企业在大数据处理和分析方面进行了深入研究,并取得了一定的成果。例如,国外的Netflix利用Hadoop和Spark构建了一个大规模的推荐系统,能够处理海量的用户行为数据和视频数据,并为其用户推荐相关的视频内容[7]。在国内,一些企业如阿里巴巴、腾讯等也在大数据处理和分析方面进行了深入研究,并推出了一些基于Hadoop和Spark的大数据产品和服务。
综上所述,推荐系统在国内外得到了广泛应用,不仅在视频领域,还在其他领域得到应用。在基于Hadoop和Spark的视频推荐系统方面,一些国内外的研究机构和企业已经取得了一定的成果,但是随着大数据技术的不断发展,还需要进一步研究和探索更加准确、高效的视频推荐算法和系统[8]。
主要内容
- Python爬虫模块:selenium采集海量bilibili视频并对视频数据进行智能分类、数据清洗;
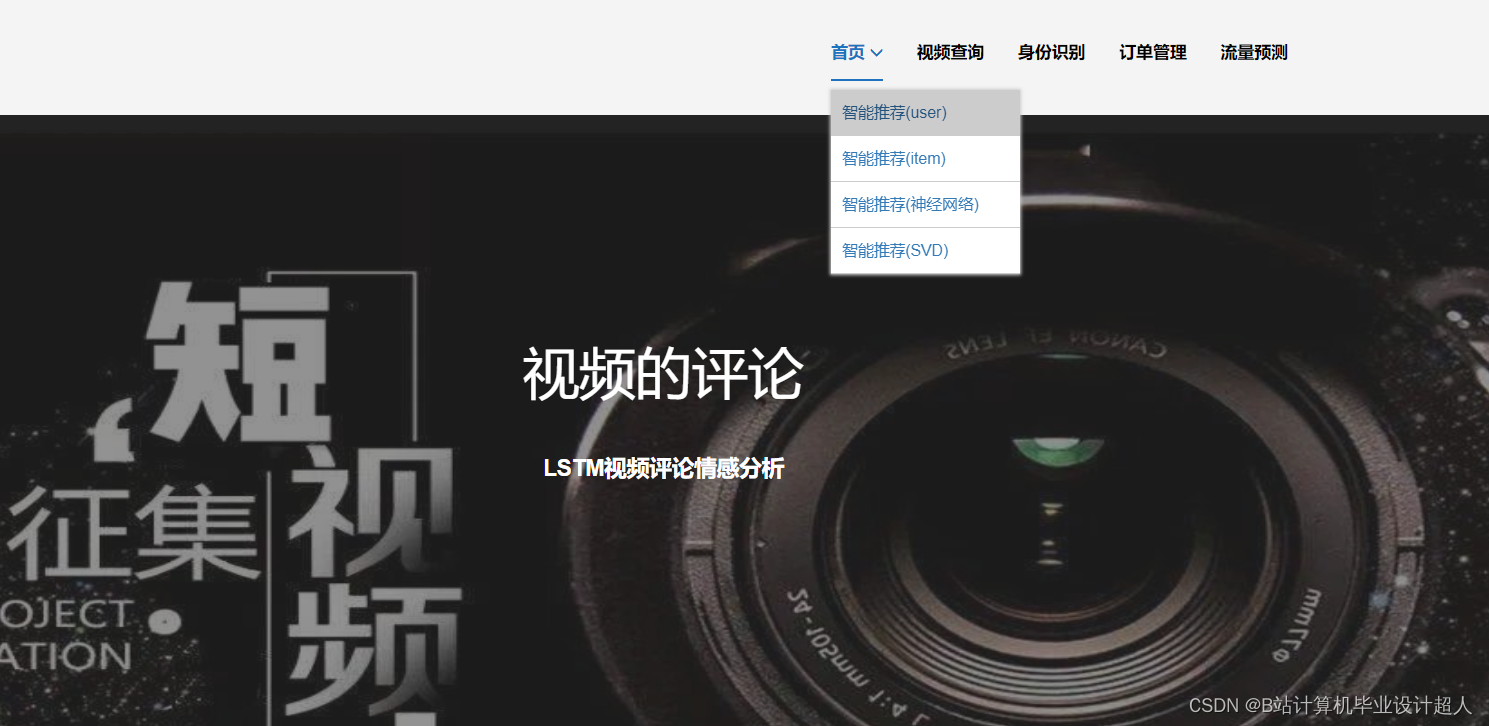
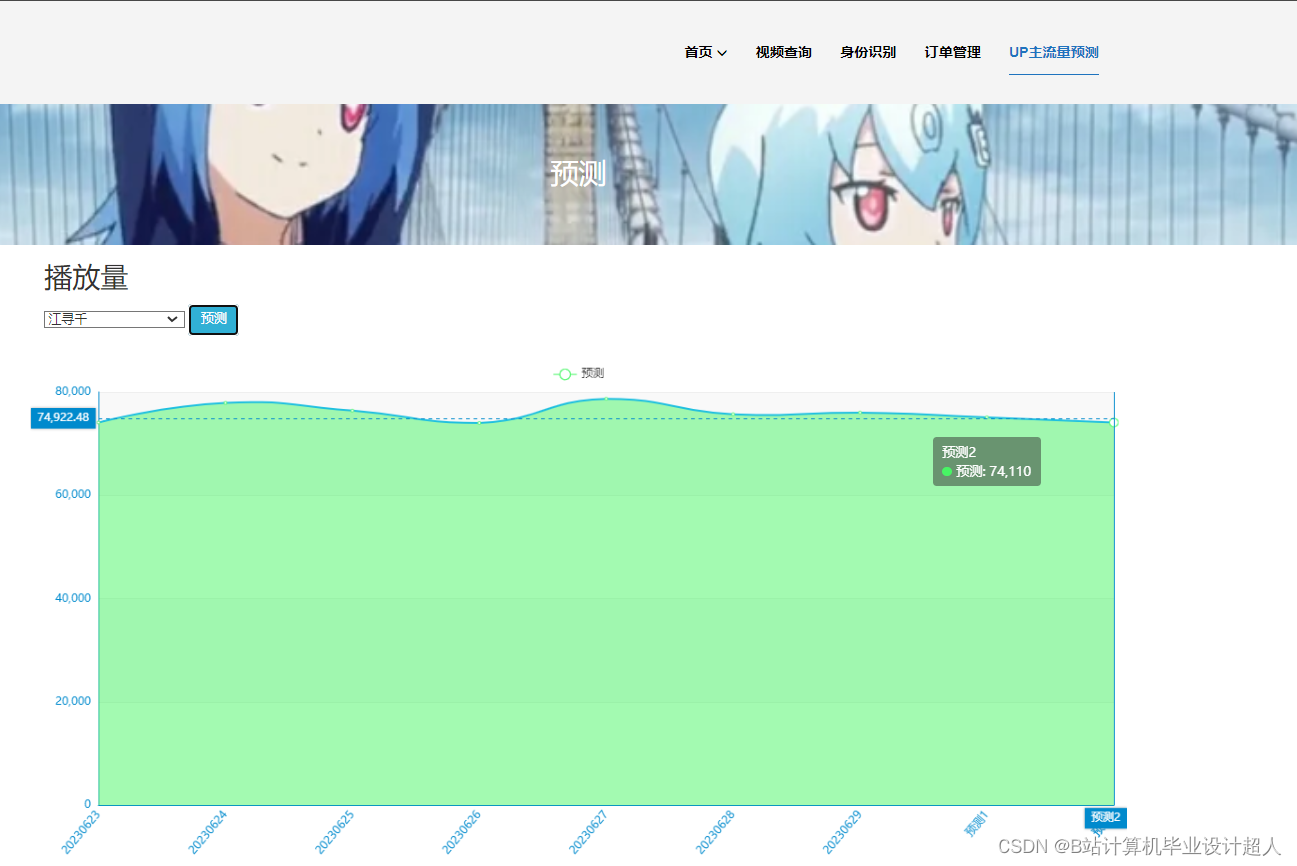
- 门户系统模块:个性化视频推荐、视频流量预测、视频VIP支付宝沙箱支付开通、视频评论情感分析、用户注册/登录、短信验证码修改密码、AI身份证认证识别、视频搜索等;
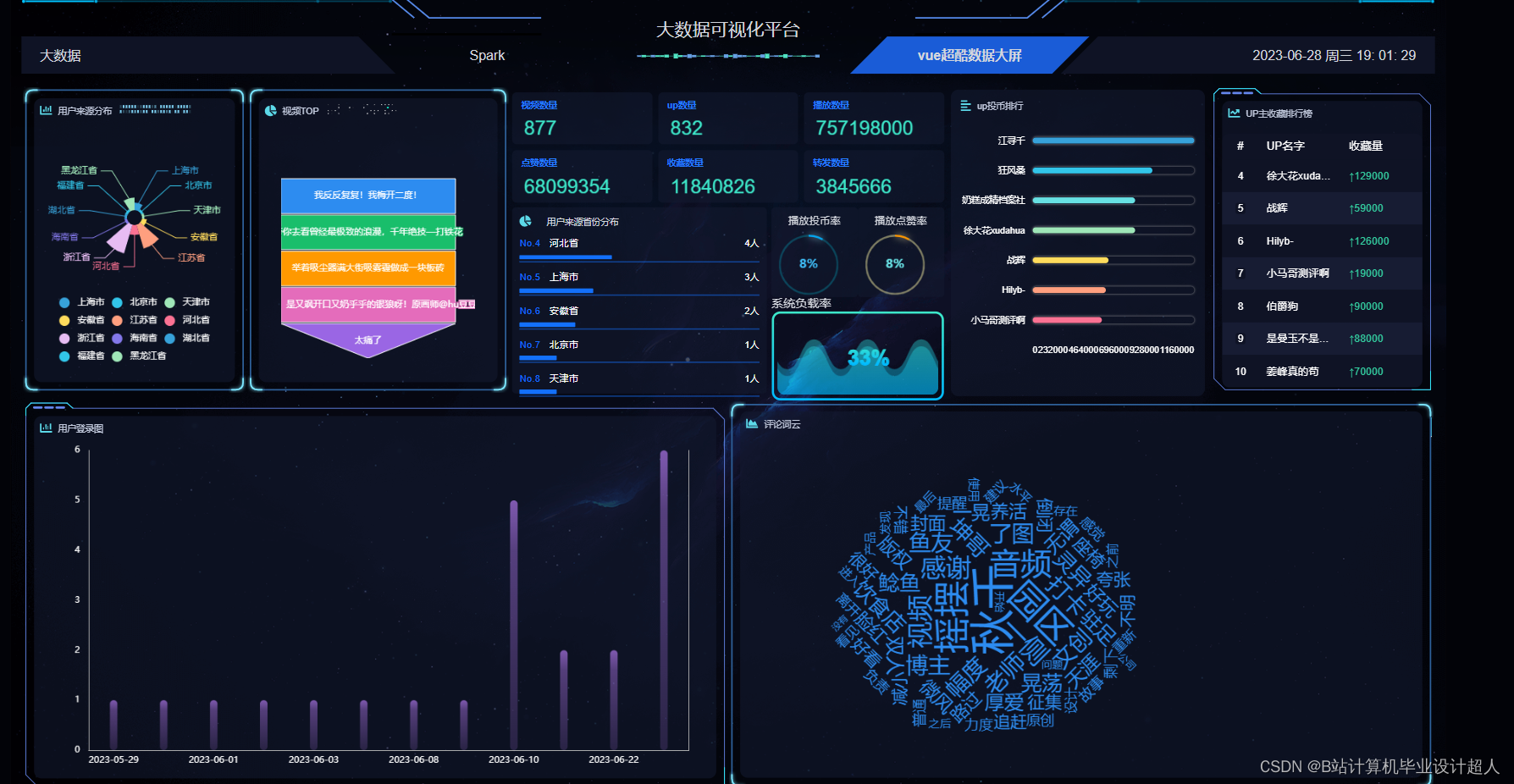
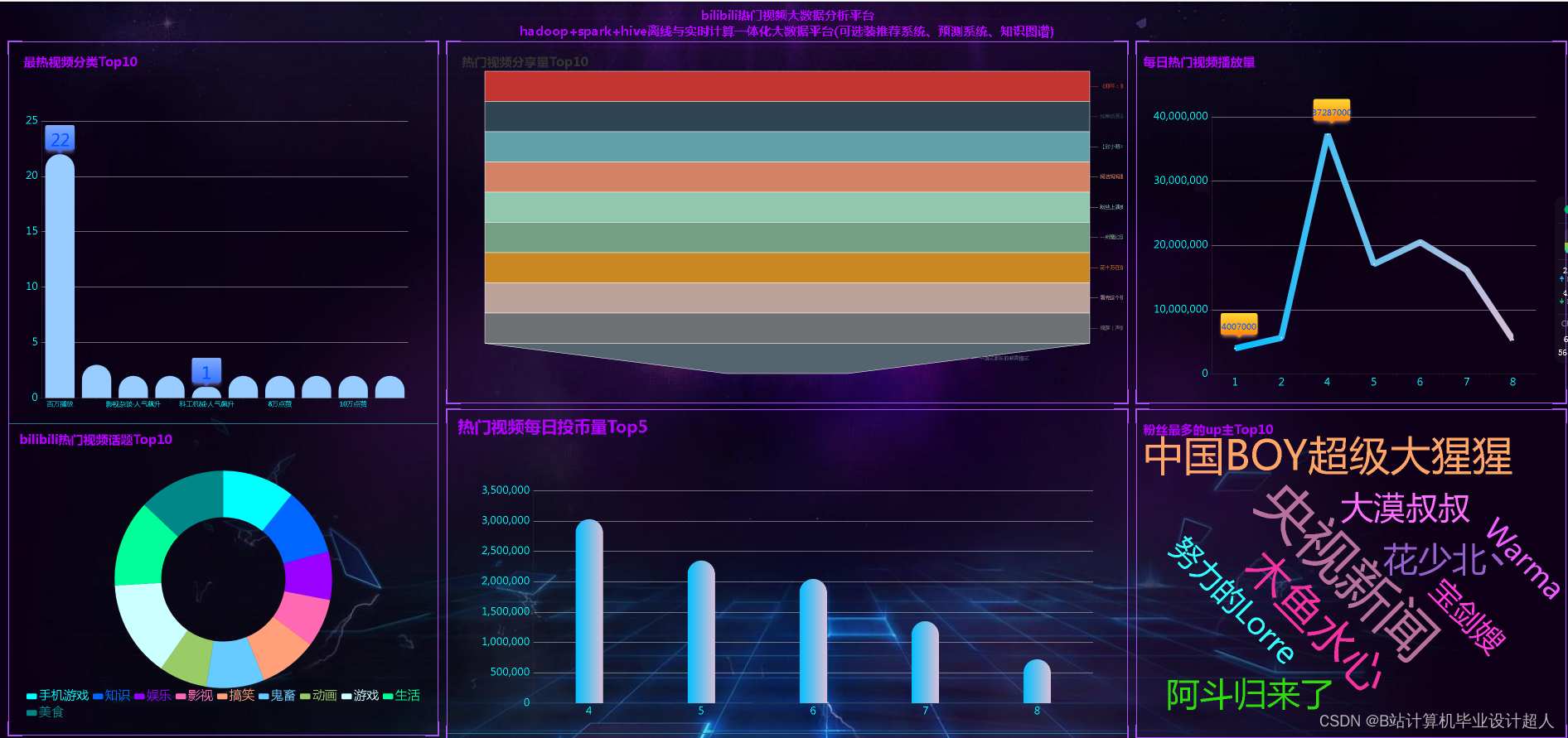
- 大屏可视化模块:视频分类分析、热门话题分析、投币量分析、分享量分析、播放量分析、视频词云等;
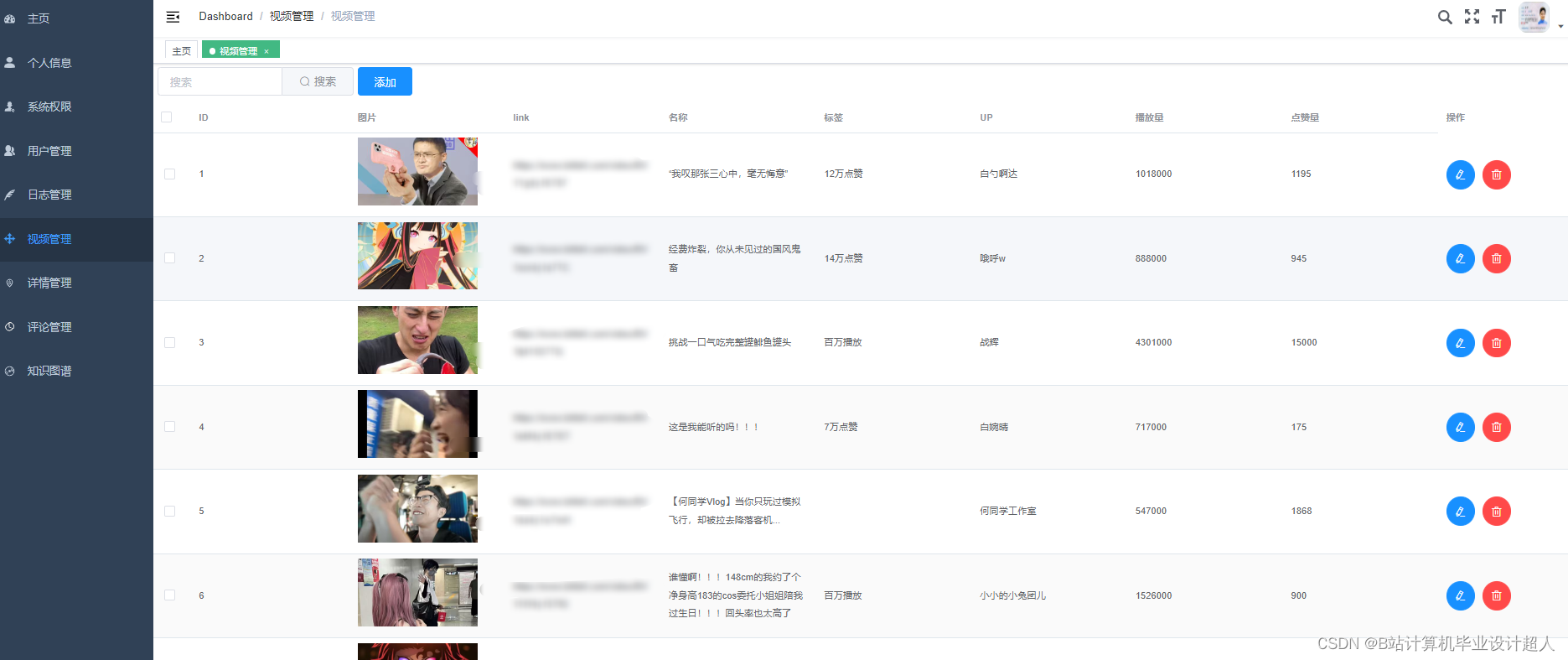
- 后台管理模块:用户管理、权限管理、视频管理、知识图谱、评论管理、订单管理;
拟解决的问题
- 协同过滤算法冷启动问题
- 视频知识图谱构建关联
- 推算效率低需要优化参数
- B站海量采集视频反爬问题
- 分析与可视化互相转化问题
- 数据库数据量大查询慢问题
预期成果
- Linux虚拟机环境一台含hadoop、spark、hive等大数据组件。
- Hive离线数据仓库操作脚本
- Spark实时计算代码
- Springboot+vue.js开发的web推荐系统、可视化系统代码
- Mysql数据库脚本
创新点
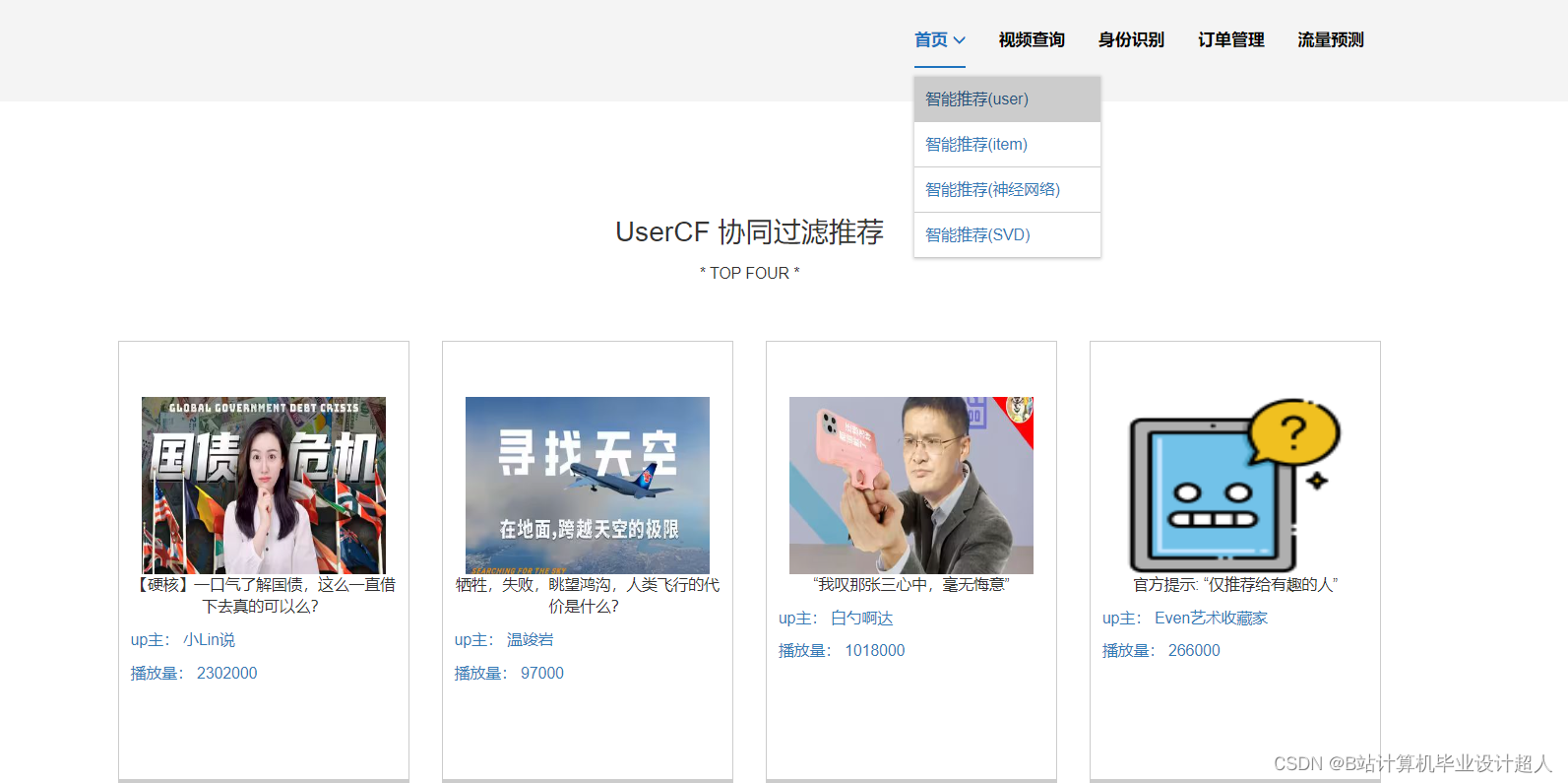
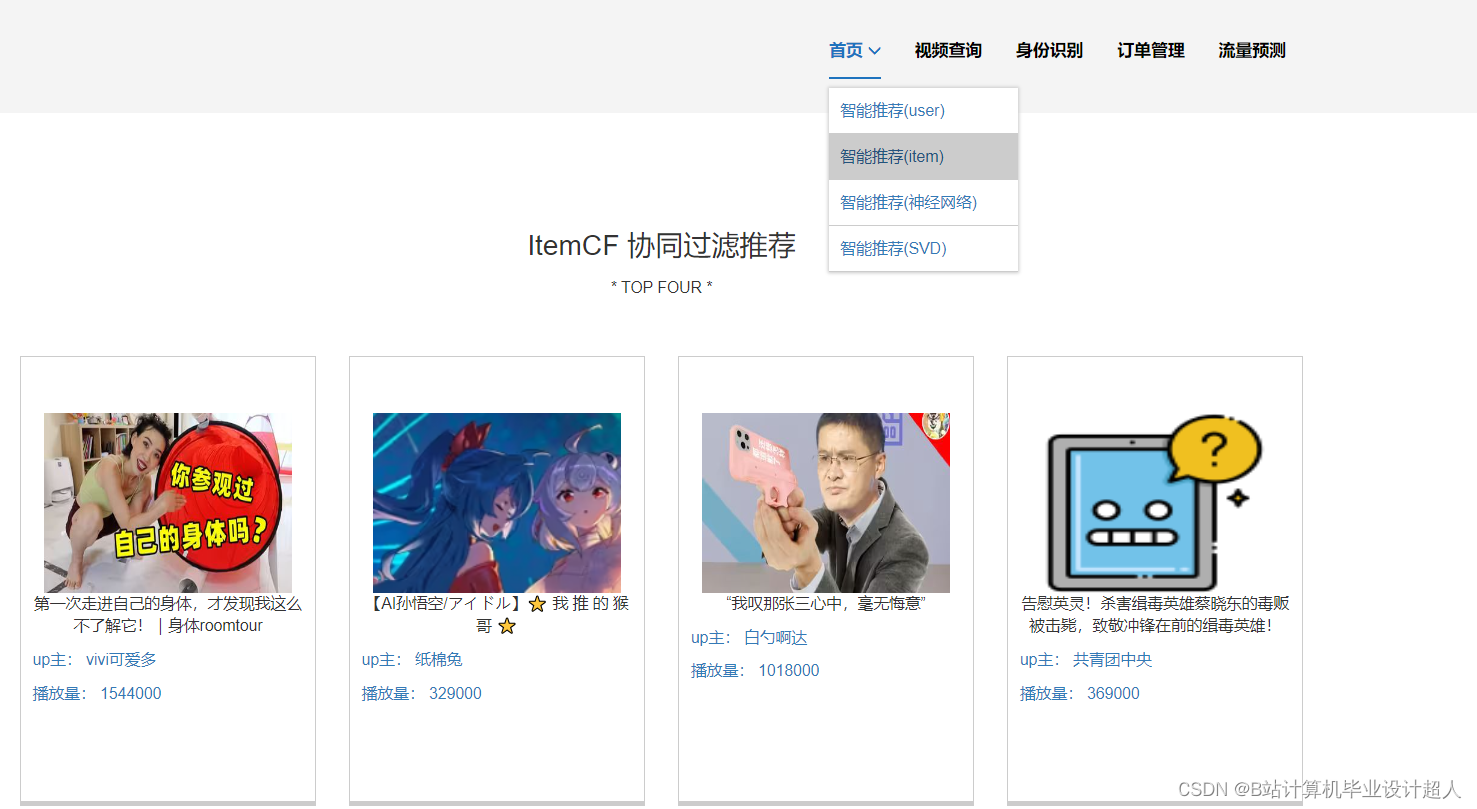
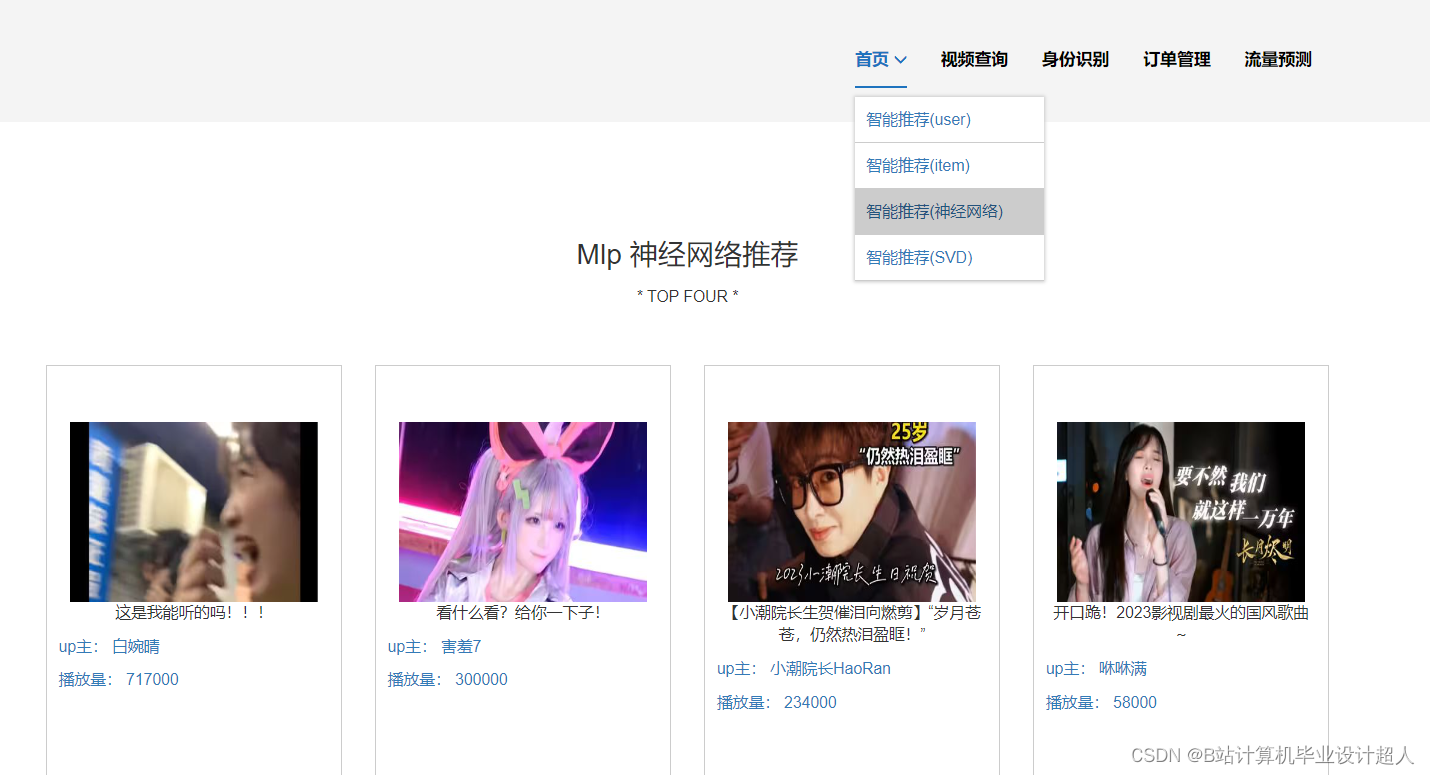
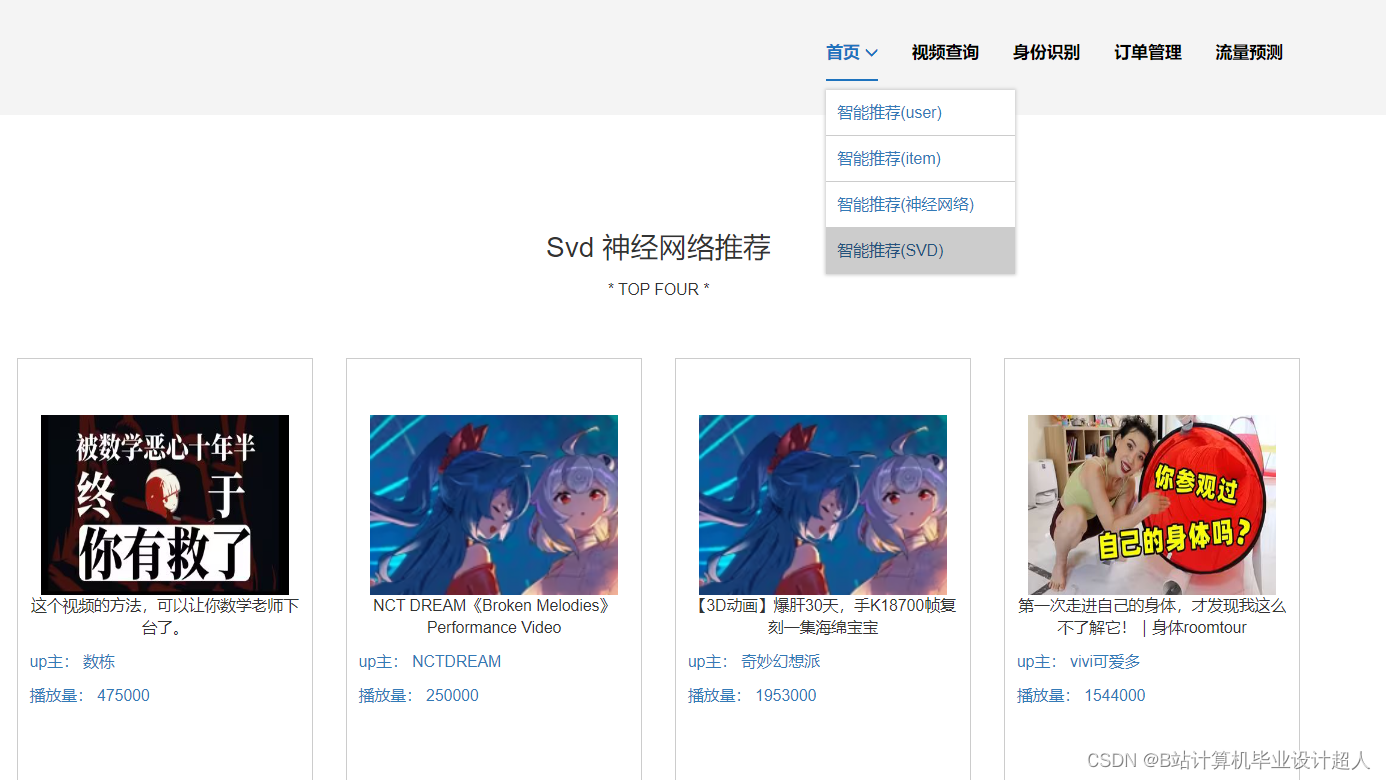
- 提供4种机器学习推荐算法进行个性化视频推荐:协同过滤推荐算法(基于用户、物品)、SVD混合神经网络推荐、多层感知MLP模型、知识图谱推荐
- Python采集海量bilibili视频数据
- Spark+hive离线计算、实时计算实现echarts可视化大屏
- 卷积神经网络KNN进行视频流量预测
- 支付宝沙箱支付(模拟视频开通付费VIP)
- Lstm模型对评论进行情感分析
- 手机短信验证码(用户修改密码功能)
- AI识别身份证(用户认证)
- 视频知识图谱关系图(neo4j)
进度安排
- 文献综述和研究背景分析(1-2个月):收集相关文献和资料,了解视频推荐系统的研究现状和发展趋势。
- 方法和系统设计(3-4个月):确定研究方法和系统设计方案,包括Python爬虫采集视频数据、用户行为分析、推荐算法设计和系统架构等。
- 系统实现和测试(5-6个月):搭建Hadoop+Spark的大数据虚拟机环境,编写代码实现视频推荐系统、大数据可视化分析,并进行系统测试和性能优化。
- 论文撰写和整理(7-8个月):撰写论文初稿,整理研究成果,包括实验结果和分析、讨论等。
- 论文修改和完善(9-12个月):对论文进行修改和完善,包括文字润色、格式调整、审稿意见回应等。
参考文献
[1] 基于短视频内容理解的用户偏好预测模型研究[D]. Muhammad Irbaz Siddique.北京交通大学,2023
[2] 基于人像聚类的短视频推荐系统的研究与实现[D]. 郝艳峰.辽宁大学,2022
[3] 基于前景理论的视频推荐方法研究[D]. 李天鹏.河南财经政法大学,2021
[4] 高校视频公开课点播平台智能推荐系统的设计与实现[D]. 陈汉福.华南理工大学,2022
[5] 基于物品协同过滤的个性化视频推荐算法改进研究[D]. 卜旭松.宁夏大学,2021
[6] 基于图论的个性化视频推荐算法研究[D]. 陈壁生.华南理工大学,2023
[7] 基于深度观看兴趣网络的视频推荐系统设计与实现[D]. 刘端阳.北京邮电大学,2021
[8] 基于用户行为分析的短视频推荐算法研究[D]. 李志强.辽宁石油化工大学,2022
[9] 基于兴趣融合扩散的视频推荐系统的研究与实现[D]. 时琦涵.辽宁大学,2023
[10] 基于云同步的视频推荐系统的系统实现[D]. 程娟.上海交通大学,2022
[11] 智能冰箱推荐系统设计[J]. 李楠;简钰轩;闭祖松;龚蕾;刘子豪;范佳乐.物联网技术,2022(12)
[12] 基于神经网络的推荐系统模型分析[J]. 张珍珍.电子技术,2023(01)
[13] 基于用户画像的课程学习视频推荐系统研究与设计[J]. 陈玉帛;项慨;王顺驰;何希;李娅琴;邹正;李玉婷.现代信息科技,2023(09)
[14] 一种基于标签值分布强化学习推荐系统设计[J]. 张元群.中国科技信息,2023(11)
[15] 个性化学习资源推荐系统设计[J]. 万鑫;冯韵;肖艳;王思力.福建电脑,2023(10)
[16] 智能观影推荐系统设计[J]. 朱卫东;李子龙;乔良才.网络安全和信息化,2022(02)
[17] 一种泊车服务推荐系统的设计[J]. 磨春妗;黎飞;谢燕芳;程登;张森.现代工业经济和信息化,2022(03)
[18] 基于个性化需求的图书馆书籍智能推荐系统的设计与实现研究[J]. 李方园.信息记录材料,2021(12)
[19] 新闻推荐系统研究综述[J]. 孟开元;岳宇航;曹庆年.软件导刊,2021(01)
[20] 面向个性化学习的慕课资源推荐系统开发[J]. 孔令圆;彭琰;郑汀华;马华.计算机时代,2021(07)
程序运行流程
1.Selenium自动化Python爬虫工具采集bilibili视频数据约1000万条存入.csv文件作为数据集;
2.使用pandas+numpy或MapReduce对数据进行数据清洗,生成最终的.csv文件并上传到hdfs;
3.使用hive数仓技术建表建库,导入.csv数据集;
4.离线分析采用hive_sql完成,实时分析利用Spark之Scala完成;
5.统计指标使用sqoop导入mysql数据库;
6.使用flask+echarts进行可视化大屏开发;
7.使用协同过滤算法、SVD神经网络、MLP感知层模型等算法实现个性化视频推荐;
8.使用卷积神经网络KNN、CNN实现视频流量预测;
9.搭建springboot+vue.js前后端分离web系统进行个性化推荐界面、流量预测界面等实现;


核心算法代码分享如下:
- # -*- codeing = utf-8 -*-
- # 创建预测所需要的数据用
- #
- import datetime
-
- import numpy as np
- import pandas as pd
- import json
- from db import db_util
-
- d = db_util()
- db, cursor = d.get_conn()
-
- def insert_flow(name, n):
- sd1 = datetime.date(2023, 6, 22) # 把数字字符变换成日期类型,赋值给一个变量
-
- v = 52000
- for i in range(1, n + 1):
- sd1 = sd1 + datetime.timedelta(days=1) # 加某个天数相加之后的日期
- # print(i)
- v1 = v+np.random.randint(5000, high=10000)
- sql = "insert into tb_flow(name,name2, v) values('%s', '%s', %f)"\
- % (sd1.strftime('%Y%m%d'), name, v1)
- cursor.execute(sql)
- db.commit()
- print("end..")
-
- if __name__ == '__main__':
- insert_flow('田花花', 7)


