
热门标签
当前位置: article > 正文
RMSpro优化器中rho与decay 两参数的区别(keras)_rmsprop decay
作者:凡人多烦事01 | 2024-05-05 12:25:08
赞
踩
rmsprop decay
最近在学习 efficienet 使用了 RMSProp 优化器,但是在 keras 使用的时候发现了问题
keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=None, decay=0.0)
- 1
RMSprop的初始化中有rho与decay两个参数,但是这两个参数都是衰减因子,那他们之间的区别在哪里呢,官方链接也没有详细解释,
后来在看到一篇回答时才突然了解
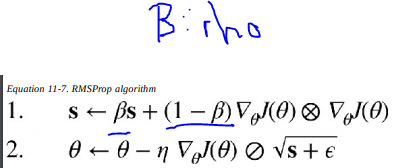
可以看到rho就是图中的B参数,B参数是本身就在RMSProp中的衰减因子,而作为decay,它的作用原理是在每个epoch之后对learning rate固定衰减,与算法本身无光,所以在Adam与SGD这些其他的优化器中的原理是相同中
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/538866
推荐阅读
相关标签

