
热门标签
当前位置: article > 正文
【数据结构进阶】布隆(Bloom Filter)过滤器【哈希+位图的整合】_集合的数据结构基础过滤器
作者:凡人多烦事01 | 2024-05-05 13:17:13
赞
踩
集合的数据结构基础过滤器
布隆(Bloom Filter)过滤器【哈希+位图的整合】
1、什么是布隆过滤器?
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
布隆过滤器的优点:
时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
保密性强,布隆过滤器不存储元素本身
存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set集合)
布隆过滤器的缺点:
有点一定的误判率,但是可以通过调整参数来降低
无法获取元素本身
很难删除元素
2、布隆过滤器的使用场景
布隆过滤器可以告诉我们 “某样东西一定不存在或者可能存在”,也就是说布隆过滤器说这个数不存在则一定不存,布隆过滤器说这个数存在可能不存在(误判率)
- google的guava包中有对Bloom Filter的实现
- 网页爬虫对URL的去重,避免爬去相同的URL地址。
- 垃圾邮件过滤,从数十亿个垃圾邮件列表中判断某邮箱是否是垃圾邮箱。
- 解决数据库缓存击穿,黑客攻击服务器时,会构建大量不存在于缓存中的key向服务器发起请求,在数
据量足够大的时候,频繁的数据库查询会导致挂机。 - 秒杀系统,查看用户是否重复购买。
3、布隆过滤器添加和查询元素
添加元素
将要添加的元素分别通过k个哈希函数计算得到k个哈希值,这k个hash值对应位数组上的k个位置,然后将这k个位置设置为1。
查询元素
将要查询的元素分别通过k个哈希函数计算得到k个哈希值,这k个hash值对应位数组上的k个位置,如果这k个位置中有一个位置为0,则此元素一定不存在集合中,如果这k个位置全部为1,则这个元素可能存在。
4.布隆过滤器的模拟实现
package BloomFilter; import java.util.BitSet; /** * @author SunYuHang * @date 2023-01-01 12:09 * @ClassName : MyBloomFilter //类名 */ class SimpleHash{ public int cap; public int seed; public SimpleHash(int cap,int seed){ this.cap = cap; this.seed = seed; } //根据seed不同 创建不同的哈希函数 final int hash(String key){ int h; return (key == null)?0:(seed*(cap-1))&(h=key.hashCode())^(h>>>16); } } public class MyBloomFilter { public static final int DEFAULT_SIZE = 1<<20; //位图 public BitSet bitSet; //记录存了多少个数据 public int usedSize; public static final int[] seeds = {5,7,11,13,27,33}; public SimpleHash[] simpleHashes; public MyBloomFilter(){ bitSet = new BitSet(); simpleHashes = new SimpleHash[seeds.length]; for (int i = 0; i <simpleHashes.length; i++) { simpleHashes[i] = new SimpleHash(DEFAULT_SIZE,seeds[i]); } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
/** * 添加元素 到布隆过滤器 * @param val */ public void add(String val) { //让X个哈希函数 分别处理当前的数据 for (SimpleHash simpleHash : simpleHashes) { int index = simpleHash.hash(val); //把他们 都存储在位图当中即可 bitSet.set(index); } } /** * 是否包含val ,这里会存在一定的误判的 * @param val * @return */ public boolean contains(String val) { //val 一定 也是通过这个几个哈希函数去 看对应的位置 for (SimpleHash simpleHash : simpleHashes) { int index = simpleHash.hash(val); //只要有1个为 0 那么一定不存在 boolean flg = bitSet.get(index); if(!flg) { return false; } } return true; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
测试布隆过滤器
public static void main(String[] args) {
MyBloomFilter myBloomFilter = new MyBloomFilter();
myBloomFilter.add("hello");
myBloomFilter.add("hello2");
myBloomFilter.add("bit");
myBloomFilter.add("haha");
System.out.println(myBloomFilter.contains("hello"));
System.out.println(myBloomFilter.contains("hello3"));
System.out.println(myBloomFilter.contains("he"));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vRZ5cEYV-1672548382306)(C:\Users\17512\AppData\Roaming\Typora\typora-user-images\1672547600389.png)]](https://img-blog.csdnimg.cn/7b8e7c774ba3438894ad8bf62374a401.png)
guava实现布隆过滤器
首先在pom引入依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
然后就可以测试啦:
private static int size = 1000000;//预计要插入多少数据 private static double fpp = 0.01;//期望的误判率 private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp); public static void main(String[] args) { //插入数据 for (int i = 0; i < 1000000; i++) { bloomFilter.put(i); } int count = 0; for (int i = 1000000; i < 2000000; i++) { if (bloomFilter.mightContain(i)) { count++; System.out.println(i + "误判了"); } } System.out.println("总共的误判数:" + count); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
代码简单分析:
我们定义了一个布隆过滤器,有两个重要的参数,分别是 我们预计要插入多少数据,我们所期望的误判率,误判率不能为0。
我向布隆过滤器插入了0-1000000,然后用1000000-2000000来测试误判率。
运行结果:
............
1999501误判了
1999567误判了
1999640误判了
1999697误判了
1999827误判了
1999942误判了
总共的误判数:10314
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
现在总共有100万数据是不存在的,误判了10314次,我们计算下误判率
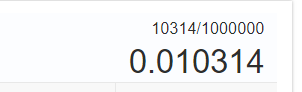
和我们定义的期望误判率0.01相差无几。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/539029
推荐阅读
相关标签

