
- 1解读Lawyer LLaMA,延申专业领域大模型微调:数据集构建,模型训练
- 2基于Java+SpringBoot+vue+element实现校园疫情防控系统详细设计和实现
- 3分享一个很实用的技巧:一两行Python代码完成的骚操作_python代码怎样两行显示
- 4Docker-高级篇(1)-Dockerfile(核心&构建Redis&构建JDK8)_dockerfile 打包 jdk jar mysql redis
- 5C++处理栅格数据
- 6❤️技术改变命运!中秋一天搞完私活,4K到手,分享下经验!确实有技术啥都不愁!❤️_全栈开发 拿4k
- 7E: Unable to locate package
- 8互联网找工作该选择大公司还是小公司
- 9NLP中的语言模型
- 10线性插值(Linear Interpolation):线性插值、双线性插值
国内外主流大模型都具备有哪些特点?
赞
踩
该章节呢,我们主要是看一下关于国内外主流的大语言模型,通过它们都具备哪些特点,来达成对多模型有一个清晰的认知。对于 “多模型” 的 “多” ,大家一定要有个概念,很多小伙伴只知道 “ChatGPT” ,或者是只知道国内的一些大模型,对国外的大模型不是特别了解,所以该章节就提炼总结一下。
⭐ 火爆全网的大模型起点
目前市面上所有的大模型其实最早的时候,都是基于谷歌的 “Transformer技术” 也就是 “Transformer架构” 来设计的。大概在2017年的时候,谷歌发布了它的 T5模型 ,后续以 T5 为代表的各种大语言模型逐渐的衍生出来。包括 GPT3、GML130B ,以 Facebook 为代表的、开源的 LLaMa ,后来的 GPT4 ,以及中东的科研机构开发的 Falcon ,还有最新的 GPT4 的版本,包括多态模型、最新的大窗口模型,这些都是最近在更新的。
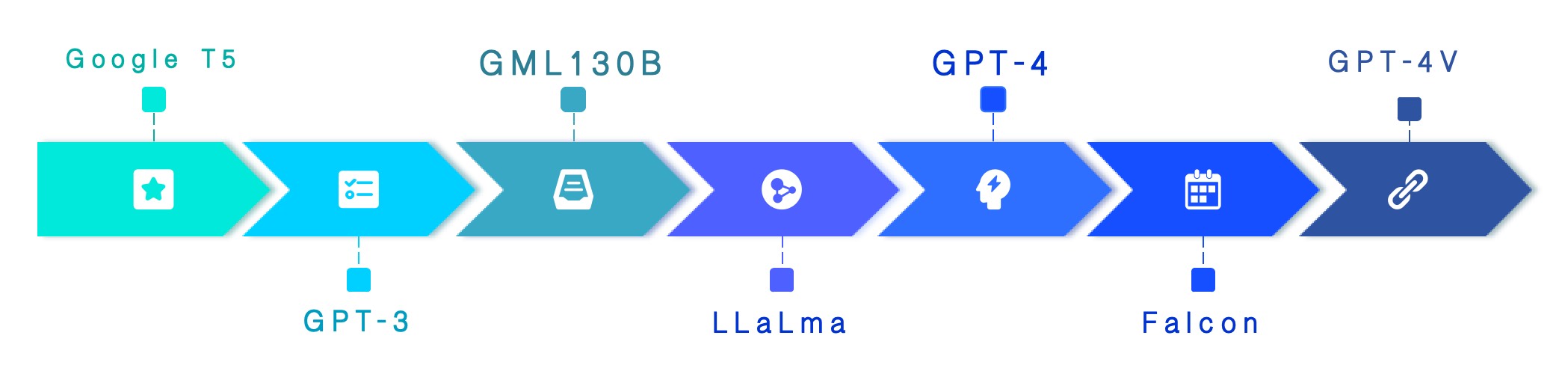
下图中所展示的大模型,就是经过简单提炼后所得出的结果,实际上市面上的大模型数量远不止于此,毕竟这是一个千模竞争的时代。左边所展示的主要是国外的一些常见的大模型, 右边的是国内的一些厂商的大模型。

从发布时间上来看,国外的这些大模型的发布要比我们国内早一些,基本上大家能说得上来名字、使用频率比较多的大模型都是在 2023年 的时候才开始发布的,整体上国内还是比国外的技术积累、水平、时间还是稍微落后的。
⭐ 国外主流LLM及其特点
先看国外的,比如 GPT-2 ,大概有15亿的训练参数。可能很多小伙伴对这里所谓的 参数 不是很理解,其实 “参数” 代表了一个模型的复杂程度,参数越大,就表示模型需要的容量空间和算力就非常的大,相应的能力也就会越强;相反,参数越小、需要的算力也就越小,能力就相对弱一些,能力的强弱主要是通过回答与提炼问题来体现的,在使用的过程中也能够体现出来。

- Google 的T5 大概有110亿的参数,最显著的特点就是可以 多任务微调,关键它还是开源的。
- OpenAI的GPT3.5 出现之后在市面上所带来的效果是非常惊人的,效果反馈也非常的好,它的参数更是达到了 1750亿 ,所需要的算力是之前很多模型的很多倍,相较于其他模型,GPT3.5的一个显著特点就是支持人工反馈的微调。
- 随后就是 Facebook 出台的 Meta OPT 模型,大概也是 1750亿 的参数,底模也是英文的。也就说,这个大模型在预训练的时候,使用的是大量的英文材料,所以在处理一些英文的问题时候,回答响应的会非常的好。
- LLaMA 的中文名字叫 “羊驼” ,熟悉开源的小伙伴可能对这个大模型比较的熟悉,它是目前比较主流且知名的开源大模型框架,在目前的开源大模型里面,参数比较大、效果比较好的开源大模型之一,一度被开发者评选为最受欢迎的大模型。
- 关于 GPT-4 ,其实从参数上我们也可以看出来,号称是史上最强大模型,参数足足有 1.8万亿,之所以在全球范围内这么火爆,不是没有原因的。最新版的GPT-4 虽然在参数上没有太大的变化,但是底模的数量相较于之前的版本也得到了大大的增加。
- VIcuna-13B 和 Falcon 这里就不做过多的介绍了,一个是开源的聊天机器人,一个是阿联酋先进技术研究委员会做出来的大模型。
从上面的介绍也可以看到,国外的这些大模型基本上都是 底模都是以英文为主 ,GPT-4其实也是以英文为主,但是因为它的底模足够的大,有使用到中文的语料去进行预训练。GPT-3和GPT-3.5涵盖了几乎所有互联网上2021年之前公开的知识,最新的GPT-4知识库更新到了了2023年。
⭐ 国内主流LLM及其特点
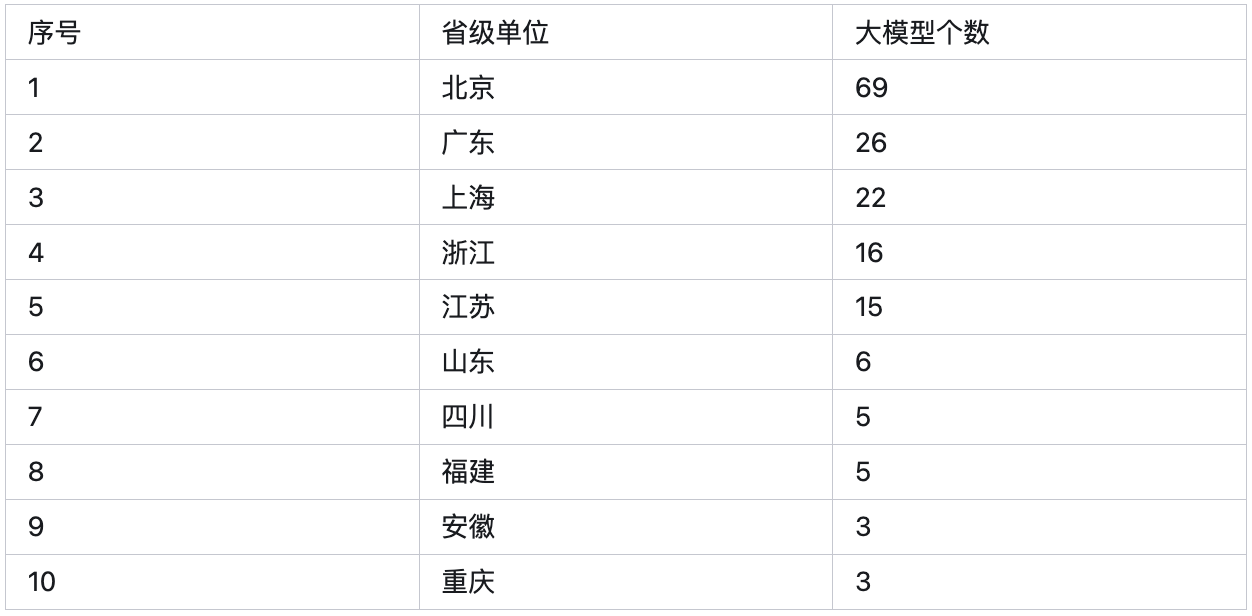
国内的主流大模型我们就简单的了解一下就好,毕竟咱们现在能排得上号的大模型简直太多了,据统计有3个或更多的机构发布了大模型的省和直辖市的地区都超过10个了,这还是2023年11月份之前统计的数据,相信现在的数量绝对更多。

- 首先就是由王小川开源的 “百川智能”,这个大模型的参数有 70亿,所以从参数的体量上来对比的话,相当于是 LLaMA 这样的大模型的一个水平。
- 百度的 文心一言 就相对来说大了很多了,在大模型上百度的投入还是非常大的,参数要超过2600亿,“文心大模型” 最显著的一个特点就是它所使用的 中文语料占据了85% 。
- 阿里的 通义千问 的参数在 70亿~700亿 ,总体的能力从参数上看相当于是 GPT3 ,相对来说略差了一些。
- ChatGLM6B 大概是 60亿 的参数,这里需要重点介绍一下的是,ChatGLM6B 的研究团队是清华大学的团队是国内、也是国际上 10B以下最强的中文开源项目,是 100亿参数以下 效果最好的大模型。
- 腾讯的 混元大模型 没有公布具体的参数,但是业界内的专家猜测其参数 超过了千亿 ,其核心特点就是 支持多模态 。多模态 的意思就是不仅支持文本生成,还支持图像生成,文生图、图生文的意思。这就意味着 混元大模型 的底模、参数和预训练更加的复杂化,不仅会训练文字,也会训练图片。
- MOSS 的参数有 160亿 ,是一款支持 多插件 的开源大模型;Aquila 与 PolyLM 这里也就不再过多的进行介绍了,Aquila 是首个中文数据合规的大模型,PolyLM则是对整个亚洲包括汉语在内的亚洲语种很友好的大模型。
国内的这些大模型大家可以看出来什么?没错,第一就是发布时间,几乎都是2023年发布的大模型,第二个就是对中文的支持非常的友好,要比海外的哪些大模型友好的非常多。
从 商用 的角度来看待这些大模型的话,有一些开源模型在商业的层面,效果不是特别的理想。比如说很多基于 LLaMA 实现的大模型,就是不支持商业场景的;但是清华团队研发的 ChatGLM6B 就是可以支持商用的,包括 百川智能、Falcon 这些都是支持商用,而且目前商用的效果还是非常不错的。
⭐ 全球大模型生态的发展
从以上的内容,我们也可以看出目前确实是属于一个由OpenAI 引爆的 “百模大战”、“千模大战”、“多模型大战” 的竞争局势。我们可以从 Hugging Face (中文名:抱脸)看一下,目前全球开源的大模型究竟有多少,可以更直观的了解当前大模型的一个现状。(HuggingFace相当于是大模型领域的GitHub)
在Hugging Face我们可以看到很多开源的大模型,它会将目前已知的开源大模型进行开源,大家千万不要觉得这是多此一举,相信当你知道目前已知的开源大模型的数量接近 六十万 的时候,就不会这么觉得了。
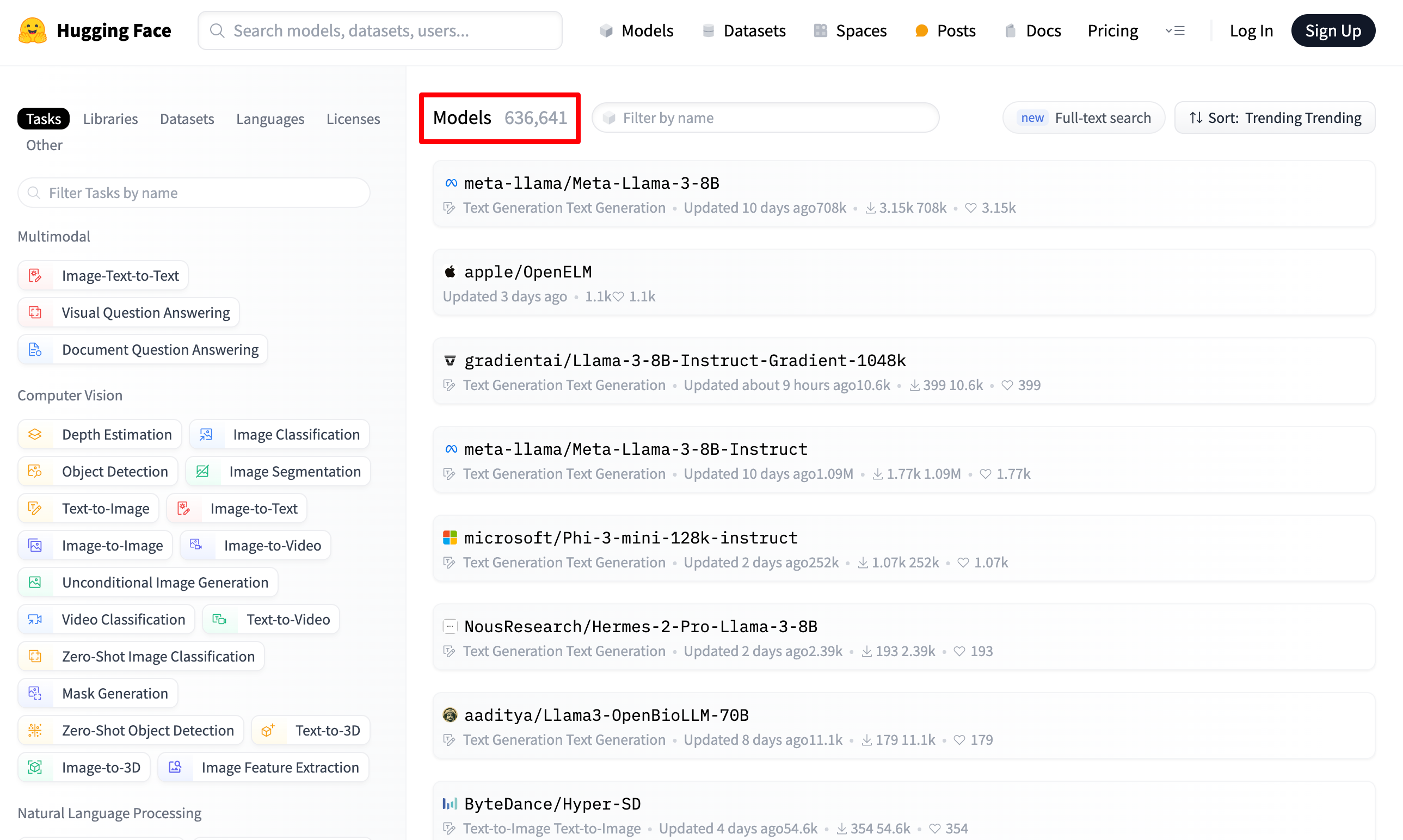
Hugging Face 所收集的大模型涵盖了很多层面,从 图生文 到 文生图 ,再到计算机视觉,从 语言分类 再到 文本分类 ,翻译、音频处理… 各种各样的大模型应有尽有。除了有很多支持的第三方库之外,还提供有大量的用于训练的数据集。(包括世界上所有的主流语言)

所以,我们可以看到整个 大模型的发展 还是非常的快的,生态也是非常的繁荣的。出了非常多之外,每个大模型也都具备有自己的特色。后续的内容也将会是以主流的大模型为主,比如说 LangChain ,毕竟六十多万的大模型也太吓人了。
好了,今天的内容就到这里了,下一章节将会为大家介绍一下 大模型的不足之处以及对应的解决方案 。

