
- 1Windows修改Rabbitmq端口号_windows rabbitmq 修改端口etc下只有个文档
- 2各个浏览器的详细信息-前端必须知道的知识
- 3基于rust的区块链实现_rust 区块链
- 4MySQL 数据库安装教程详解(linux系统和windows系统)_mysql安装
- 5怎么解决上台发言紧张的问题_不敢上台发言很紧张怎么办
- 6深度学习之基于Pytorch姿态估计的仰卧起坐计数系统
- 7用jframe给MySQL输入数据_编程实现利用 DataFrame 读写 MySQL 的数据
- 8用WebStorm编辑Markdown_webstorm 编辑.md文件
- 9基于MATLAB的Hybrid A*算法机器人路径规划_hybrida*代码matlab
- 10PMP第二章——项目管理过程_pmp项目管理步骤
基于LSTM搭建一个文本情感分类的深度学习模型:准确率往往有95%以上_lstm文本分类准确率不高的原因
赞
踩
基于情感词典的文本情感分类
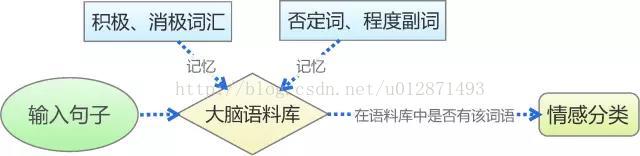
传统的基于情感词典的文本情感分类,是对人的记忆和判断思维的最简单的模拟,如上图。我们首先通过学习来记忆一些基本词汇,如否定词语有“不”,积极词语有“喜欢”、“爱”,消极词语有“讨厌”、“恨”等,从而在大脑中形成一个基本的语料库。然后,我们再对输入的句子进行最直接的拆分,看看我们所记忆的词汇表中是否存在相应的词语,然后根据这个词语的类别来判断情感,比如“我喜欢数学”,“喜欢”这个词在我们所记忆的积极词汇表中,所以我们判断它具有积极的情感。
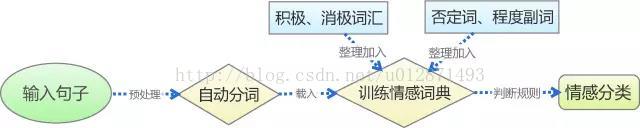
基于上述思路,我们可以通过以下几个步骤实现基于情感词典的文本情感分类:预处理、分词、训练情感词典、判断,整个过程可以如下图所示。而检验模型用到的原材料,包括薛云老师提供的蒙牛牛奶的评论,以及从网络购买的某款手机的评论数据(见附件)。
文本的预处理
由网络爬虫等工具爬取到的原始语料,通常都会带有我们不需要的信息,比如额外的Html标签,所以需要对语料进行预处理。由薛云老师提供的蒙牛牛奶评论也不例外。我们队伍使用Python作为我们的预处理工具,其中的用到的库有Numpy和Pandas,而主要的文本工具为正则表达式。经过预处理,原始语料规范为如下表,其中我们用-1标注消极情感评论,1标记积极情感评论。
句子自动分词
为了判断句子中是否存在情感词典中相应的词语,我们需要把句子准确切割为一个个词语,即句子的自动分词。我们对比了现有的分词工具,综合考虑了分词的准确性和在Python平台的易用性,最终选择了“结巴中文分词”作为我们的分词工具。
下表仅展示各常见的分词工具对其中一个典型的测试句子的分词效果:
测试句子:工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作
| 分词工具 | 测试结果 |
| 结巴中文分词 | 工信处/ 女干事/ 每月/ 经过/ 下属/ 科室/ 都/ 要/ 亲口/ 交代/ 24/ 口/ 交换机/ 等/ 技术性/ 器件/ 的/ 安装/ 工作 |
| 中科院分词 | 工/n 信/n 处女/n 干事/n 每月/r 经过/p 下属/v 科室/n 都/d 要/v 亲口/d 交代/v 24/m 口/q 交换机/n 等/udeng 技术性/n 器件/n 的/ude1 安装/vn 工作/vn |
| smallseg | 工信/ 信处/ 女干事/ 每月/ 经过/ 下属/ 科室/ 都要/ 亲口/ 交代/ 24/ 口/ 交换机/ 等/ 技术性/ 器件/ 的/ 安装/ 工作 |
| Yaha 分词 | 工信处 / 女 / 干事 / 每月 / 经过 / 下属 / 科室 / 都 / 要 / 亲口 / 交代 / 24 / 口 / 交换机 / 等 / 技术性 / 器件 / 的 / 安装 / 工作 |
载入情感词典
一般来说,词典是文本挖掘最核心的部分,对于文本感情分类也不例外。情感词典分为四个部分:积极情感词典、消极情感词典、否定词典以及程度副词词典。为了得到更加完整的情感词典,我们从网络上收集了若干个情感词典,并且对它们进行了整合去重,同时对部分词语进行了调整,以达到尽可能高的准确率。
我们队伍并非单纯对网络收集而来的词典进行整合,而且还有针对性和目的性地对词典进行了去杂、更新。特别地,我们加入了某些行业词汇,以增加分类中的命中率。不同行业某些词语的词频会有比较大的差别,而这些词有可能是情感分类的关键词之一。比如,薛云老师提供的评论数据是有关蒙牛牛奶的,也就是饮食行业的;而在饮食行业中,“吃”和“喝”这两个词出现的频率会相当高,而且通常是对饮食的正面评价,而“不吃”或者“不喝”通常意味着对饮食的否定评价,而在其他行业或领域中,这几个词语则没有明显情感倾向。另外一个例子是手机行业的,比如“这手机很耐摔啊,还防水”,“耐摔”、“防水”就是在手机这个领域有积极情绪的词。因此,有必要将这些因素考虑进模型之中。
文本情感分类
基于情感词典的文本情感分类规则比较机械化。简单起见,我们将每个积极情感词语赋予权重1,将每个消极情感词语赋予权重-1,并且假设情感值满足线性叠加原理;然后我们将句子进行分词,如果句子分词后的词语向量包含相应的词语,就加上向前的权值,其中,否定词和程度副词会有特殊的判别规则,否定词会导致权值反号,而程度副词则让权值加倍。最后,根据总权值的正负性来判断句子的情感。基本的算法如图。
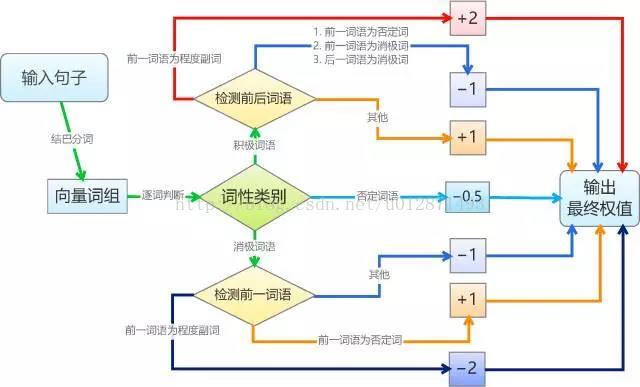
要说明的是,为了编程和测试的可行性,我们作了几个假设(简化)。假设一:我们假设了所有积极词语、消极词语的权重都是相等的,这只是在简单的判断情况下成立,更精准的分类显然不成立的,比如“恨”要比“讨厌”来得严重;修正这个缺陷的方法是给每个词语赋予不同的权值,我们将在本文的第二部分探讨权值的赋予思路。假设二:我们假设了权值是线性叠加的,这在多数情况下都会成立,而在本文的第二部分中,我们会探讨非线性的引入,以增强准确性。假设三:对于否定词和程度副词的处理,我们仅仅是作了简单的取反和加倍,而事实上,各个否定词和程度副词的权值也是不一样的,比如“非常喜欢”显然比“挺喜欢”程度深,但我们对此并没有区分。
在算法的实现上,我们则选用了Python作为实现平台。可以看到,借助于Python丰富的扩展支持,我们仅用了一百行不到的代码,就实现了以上所有步骤,得到了一个有效的情感分类算法,这充分体现了Python的简洁。下面将检验我们算法的有效性。
模型结果检验
作为最基本的检验,我们首先将我们的模型运用于薛云老师提供的蒙牛牛奶评论中,结果是让人满意的,达到了82.02%的正确率,详细的检验报告如下表

让我们惊喜的是,将从蒙牛牛奶评论数据中调整出来的模型,直接应用到某款手机的评论数据的情感分类中,也达到了81.96%准确率!这表明我们的模型具有较好的强健性,能在不同行业的评论数据的情感分类中都有不错的表现。

结论:我们队伍初步实现了基于情感词典的文本情感分类,测试结果表明,通过简单的判断规则就能够使这一算法具有不错的准确率,同时具有较好的强健性。一般认为,正确率达80%以上的模型具有一定的生产价值,能适用于工业环境。显然,我们的模型已经初步达到了这个标准。
困难所在
经过两次测试,可以初步认为我们的模型正确率基本达到了80%以上。另外,一些比较成熟的商业化程序,它的正确率也只有85%到90%左右(如BosonNLP)。这说明我们这个简单的模型确实已经达到了让人满意的效果,另一方面,该事实也表明,传统的“基于情感词典的文本情感分类”模型的性能可提升幅度相当有限。这是由于文本情感分类的本质复杂性所致的。经过初步的讨论,我们认为文本情感分类的困难在以下几个方面。
语言系统是相当复杂的
归根结底,这是因为我们大脑中的语言系统是相当复杂的。(1)我们现在做的是文本情感分类,文本和文本情感都是人类文化的产物,换言之,人是唯一准确的判别标准。(2)人的语言是一个相当复杂的文化产物,一个句子并不是词语的简单线性组合,它有相当复杂的非线性在里面。(3)我们在描述一个句子时,都是将句子作为一个整体而不是词语的集合看待的,词语的不同组合、不同顺序、不同数目都能够带来不同的含义和情感,这导致了文本情感分类工作的困难。
因此,文本情感分类工作实际上是对人脑思维的模拟。我们前面的模型,实际上已经对此进行了最简单的模拟。然而,我们模拟的不过是一些简单的思维定式,真正的情感判断并不是一些简单的规则,而是一个复杂的网络。
大脑不仅仅在情感分类
事实上,我们在判断一个句子的情感时,我们不仅仅在想这个句子是什么情感,而且还会判断这个句子的类型(祈使句、疑问句还是陈述句?);当我们在考虑句子中的每个词语时,我们不仅仅关注其中的积极词语、消极词语、否定词或者程度副词,我们会关注每一个词语(主语、谓语、宾语等等),从而形成对整个句子整体的认识;我们甚至还会联系上下文对句子进行判断。这些判断我们可能是无意识的,但我们大脑确实做了这个事情,以形成对句子的完整认识,才能对句子的感情做了准确的判断。也就是说,我们的大脑实际上是一个非常高速而复杂的处理器,我们要做情感分类,却同时还做了很多事情。
活水:学习预测
人类区别于机器、甚至人类区别于其他动物的显著特征,是人类具有学习意识和学习能力。我们获得新知识的途径,除了其他人的传授外,还包括自己的学习、总结和猜测。对于文本情感分类也不例外,我们不仅仅可以记忆住大量的情感词语,同时我们还可以总结或推测出新的情感词语。比如,我们只知道“喜欢”和“爱”都具有积极情感倾向,那么我们会猜测“喜爱”也具有积极的情感色彩。这种学习能力是我们扩充我们的词语的重要方式,也是记忆模式的优化(即我们不需要专门往大脑的语料库中塞进“喜爱”这个词语,我们仅需要记得“喜欢”和“爱”,并赋予它们某种联系,以获得“喜爱”这个词语,这是一种优化的记忆模式)。
优化思路
经过上述分析,我们看到了文本情感分类的本质复杂性以及人脑进行分类的几个特征。而针对上述分析,我们提出如下几个改进措施。
非线性特征的引入
前面已经提及过,真实的人脑情感分类实际上是严重非线性的,基于简单线性组合的模型性能是有限的。所以为了提高模型的准确率,有必要在模型中引入非线性。
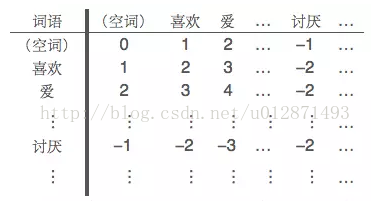
所谓非线性,指的是词语之间的相互组合形成新的语义。事实上,我们的初步模型中已经简单地引入了非线性——在前面的模型中,我们将积极词语和消极词语相邻的情况,视为一个组合的消极语块,赋予它负的权值。更精细的组合权值可以通过“词典矩阵”来实现,即我们将已知的积极词语和消极词语都放到同一个集合来,然后逐一编号,通过如下的“词典矩阵”,来记录词组的权值。
并不是每一个词语的组合都是成立的,但我们依然可以计算它们之间的组合权值,情感权值的计算可以阅读参考文献。然而,情感词语的数目相当大,而词典矩阵的元素个数则是其平方,其数据量是相当可观的,因此,这已经初步进入大数据的范畴。为了更加高效地实现非线性,我们需要探索组合词语的优化方案,包括构造方案和储存、索引方案。
情感词典的自动扩充
在如今的网络信息时代,新词的出现如雨后春笋,其中包括“新构造网络词语”以及“将已有词语赋予新的含义”;另一方面,我们整理的情感词典中,也不可能完全包含已有的情感词语。因此,自动扩充情感词典是保证情感分类模型时效性的必要条件。目前,通过网络爬虫等手段,我们可以从微博、社区中收集到大量的评论数据,为了从这大批量的数据中找到新的具有情感倾向的词语,我们的思路是无监督学习式的词频统计。
我们的目标是“自动扩充”,因此我们要达到的目的是基于现有的初步模型来进行无监督学习,完成词典扩充,从而增强模型自身的性能,然后再以同样的方式进行迭代,这是一个正反馈的调节过程。虽然我们可以从网络中大量抓取评论数据,但是这些数据是无标注的,我们要通过已有的模型对评论数据进行情感分类,然后在同一类情感(积极或消极)的评论集合中统计各个词语的出现频率,最后将积极、消极评论集的各个词语的词频进行对比。某个词语在积极评论集中的词频相当高,在消极评论集中的词频相当低,那么我们就有把握将该词语添加到消极情感词典中,或者说,赋予该词语负的权值。
举例来说,假设我们的消极情感词典中并没有“黑心”这个词语,但是“可恶”、“讨厌”、“反感”、“喜欢”等基本的情感词语在情感词典中已经存在,那么我们就会能够将下述句子正确地进行情感分类:
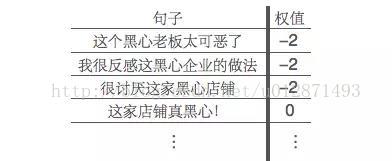
其中,由于消极情感词典中没有“黑心”这个词语,所以“这家店铺真黑心!”就只会被判断为中性(即权值为0)。分类完成后,对所有词频为正和为负的分别统计各个词频,我们发现,新词语“黑心”在负面评论中出现很多次,但是在正面评论中几乎没有出现,那么我们就将黑心这个词语添加到我们的消极情感词典中,然后更新我们的分类结果:
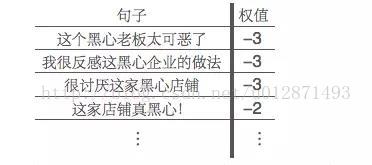
于是我们就通过无监督式的学习扩充了词典,同时提高了准确率,增强了模型的性能。这是一个反复迭代的过程,前一步的结果可以帮助后一步的进行。
综合上述研究,我们得出如下结论:
基于情感词典的文本情感分类是容易实现的,其核心之处在于情感词典的训练。
语言系统是相当复杂的,基于情感词典的文本情感分类只是一个线性的模型,其性能是有限的。
在文本情感分类中适当地引入非线性特征,能够有效地提高模型的准确率。
引入扩充词典的无监督学习机制,可以有效地发现新的情感词,保证模型的强健性和时效性。
在文本情感分类传统模型的思路简单易懂,而且稳定性也比较强,然而存在着两个难以克服的局限性:
一、精度问题,传统思路差强人意,当然一般的应用已经足够了,但是要进一步提高精度,却缺乏比较好的方法;
二、背景知识问题,传统思路需要事先提取好情感词典,而这一步骤,往往需要人工操作才能保证准确率,换句话说,做这个事情的人,不仅仅要是数据挖掘专家,还需要语言学家,这个背景知识依赖性问题会阻碍着自然语言处理的进步。
庆幸的是,深度学习解决了这个问题(至少很大程度上解决了),它允许我们在几乎“零背景”的前提下,为某个领域的实际问题建立模型。本文延续上一篇文章所谈及的文本情感分类为例,简单讲解深度学习模型。其中上一篇文章已经详细讨论过的部分,本文不再详细展开。
深度学习与自然语言处理
近年来,深度学习算法被应用到了自然语言处理领域,获得了比传统模型更优秀的成果。如Bengio等学者基于深度学习的思想构建了神经概率语言模型,并进一步利用各种深层神经网络在大规模英文语料上进行语言模型的训练,得到了较好的语义表征,完成了句法分析和情感分类等常见的自然语言处理任务,为大数据时代的自然语言处理提供了新的思路。
经过笔者的测试,基于深度神经网络的情感分析模型,其准确率往往有95%以上,深度学习算法的魅力和威力可见一斑!
关于深度学习进一步的资料,请参考以下文献:
[1] Yoshua Bengio, Réjean Ducharme Pascal Vincent, Christian Jauvin. A Neural Probabilistic Language Model, 2003
[2] 一种新的语言模型:http://blog.sciencenet.cn/blog-795431-647334.html
[3] Deep Learning(深度学习)学习笔记整理:http://blog.csdn.net/zouxy09/article/details/8775360
[4] Deep Learning:http://deeplearning.net
[5] 漫话中文自动分词和语义识别:http://www.matrix67.com/blog/archives/4212
[6] Deep Learning 在中文分词和词性标注任务中的应用:http://blog.csdn.net/itplus/article/details/13616045
语言的表达
建模环节中最重要的一步是特征提取,在自然语言处理中也不例外。在自然语言处理中,最核心的一个问题是,如何把一个句子用数字的形式有效地表达出来?如果能够完成这一步,句子的分类就不成问题了。显然,一个最初等的思路是:给每个词语赋予唯一的编号1,2,3,4...,然后把句子看成是编号的集合,比如假设1,2,3,4分别代表“我”、“你”、“爱”、“恨”,那么“我爱你”就是[1, 3, 2],“我恨你”就是[1, 4, 2]。这种思路看起来有效,实际上非常有问题,比如一个稳定的模型会认为3跟4是很接近的,因此[1, 3, 2]和[1, 4, 2]应当给出接近的分类结果,但是按照我们的编号,3跟4所代表的词语意思完全相反,分类结果不可能相同。因此,这种编码方式不可能给出好的结果。
读者也许会想到,我将意思相近的词语的编号凑在一堆(给予相近的编号)不就行了?嗯,确实如果,如果有办法把相近的词语编号放在一起,那么确实会大大提高模型的准确率。可是问题来了,如果给出每个词语唯一的编号,并且将相近的词语编号设为相近,实际上是假设了语义的单一性,也就是说,语义仅仅是一维的。然而事实并非如此,语义应该是多维的。
比如我们谈到“家园”,有的人会想到近义词“家庭”,从“家庭”又会想到“亲人”,这些都是有相近意思的词语;另外,从“家园”,有的人会想到“地球”,从“地球”又会想到“火星”。换句话说,“亲人”、“火星”都可以看作是“家园”的二级近似,但是“亲人”跟“火星”本身就没有什么明显的联系了。此外,从语义上来讲,“大学”、“舒适”也可以看做是“家园”的二级近似,显然,如果仅通过一个唯一的编号,是很难把这些词语放到适合的位置的。
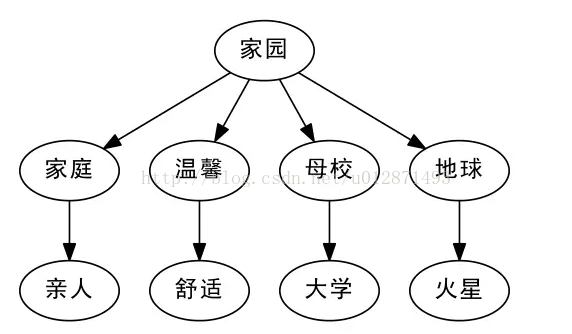
Word2Vec:高维来了
从上面的讨论可以知道,很多词语的意思是各个方向发散开的,而不是单纯的一个方向,因此唯一的编号不是特别理想。那么,多个编号如何?换句话说,将词语对应一个多维向量?不错,这正是非常正确的思路。
为什么多维向量可行?首先,多维向量解决了词语的多方向发散问题,仅仅是二维向量就可以360度全方位旋转了,何况是更高维呢(实际应用中一般是几百维)。其次,还有一个比较实际的问题,就是多维向量允许我们用变化较小的数字来表征词语。怎么说?我们知道,就中文而言,词语的数量就多达数十万,如果给每个词语唯一的编号,那么编号就是从1到几十万变化,变化幅度如此之大,模型的稳定性是很难保证的。如果是高维向量,比如说20维,那么仅需要0和1就可以表达220=1048576
(100万)个词语了。变化较小则能够保证模型的稳定性。
扯了这么多,还没有真正谈到点子上。现在思路是有了,问题是,如何把这些词语放到正确的高维向量中?而且重点是,要在没有语言背景的情况下做到这件事情?(换句话说,如果我想处理英语语言任务,并不需要先学好英语,而是只需要大量收集英语文章,这该多么方便呀!)在这里我们不可能也不必要进行更多的原理上的展开,而是要介绍:而基于这个思路,有一个Google开源的著名的工具——Word2Vec。
简单来说,Word2Vec就是完成了上面所说的我们想要做的事情——用高维向量(词向量,Word Embedding)表示词语,并把相近意思的词语放在相近的位置,而且用的是实数向量(不局限于整数)。我们只需要有大量的某语言的语料,就可以用它来训练模型,获得词向量。词向量好处前面已经提到过一些,或者说,它就是问了解决前面所提到的问题而产生的。另外的一些好处是:词向量可以方便做聚类,用欧氏距离或余弦相似度都可以找出两个具有相近意思的词语。这就相当于解决了“一义多词”的问题(遗憾的是,似乎没什么好思路可以解决一词多义的问题。)
而Word2Vec的实现,Google官方提供了C语言的源代码,读者可以自行编译。而Python的Gensim库中也提供现成的Word2Vec作为子库(事实上,这个版本貌似比官方的版本更加强大)。
表达句子:句向量
接下来要解决的问题是:我们已经分好词,并且已经将词语转换为高维向量,那么句子就对应着词向量的集合,也就是矩阵,类似于图像处理,图像数字化后也对应一个像素矩阵;可是模型的输入一般只接受一维的特征,那怎么办呢?一个比较简单的想法是将矩阵展平,也就是将词向量一个接一个,组成一个更长的向量。这个思路是可以,但是这样就会使得我们的输入维度高达几千维甚至几万维,事实上是难以实现的。(如果说几万维对于今天的计算机来说不是问题的话,那么对于1000x1000的图像,就是高达100万维了!)
事实上,对于图像处理来说,已经有一套成熟的方法了,叫做卷积神经网络(CNNs),它是神经网络的一种,专门用来处理矩阵输入的任务,能够将矩阵形式的输入编码为较低维度的一维向量,而保留大多数有用信息。卷积神经网络那一套也可以直接搬到自然语言处理中,尤其是文本情感分类中,效果也不错,相关的文章有《Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts》。但是句子的原理不同于图像,直接将图像那一套用于语言,虽然略有小成,但总让人感觉不伦不类。因此,这并非自然语言处理中的主流方法。
在自然语言处理中,通常用到的方法是递归神经网络或循环神经网络(都叫RNNs)。它们的作用跟卷积神经网络是一样的,将矩阵形式的输入编码为较低维度的一维向量,而保留大多数有用信息。跟卷积神经网络的区别在于,卷积神经网络更注重全局的模糊感知(好比我们看一幅照片,事实上并没有看清楚某个像素,而只是整体地把握图片内容),而RNNs则是注重邻近位置的重构,由此可见,对于语言任务,RNNs更具有说服力(语言总是由相邻的字构成词,相邻的词构成短语,相邻的短语构成句子,等等,因此,需要有效地把邻近位置的信息进行有效的整合,或者叫重构)。
说到模型的分类,可真谓无穷无尽。在RNNs这个子集之下,又有很多个变种,如普通的RNNs,以及GRU、LSTM等,读者可以参考Keras的官方文档:http://keras.io/models/,它是Python是一个深度学习库,提供了大量的深度学习模型,它的官方文档既是一个帮助教程,也是一个模型的列表——它基本实现了目前流行的深度学习模型。
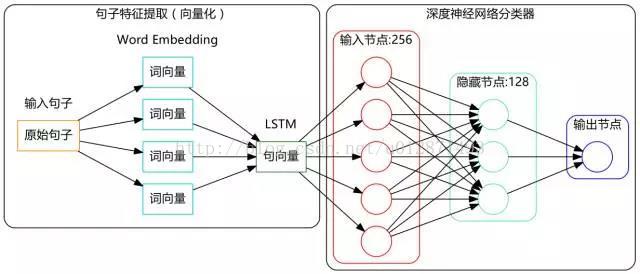
搭建LSTM模型
吹了那么久水,是该干点实事了。现在我们基于LSTM(Long-Short Term Memory,长短期记忆人工神经网络)搭建一个文本情感分类的深度学习模型,其结构图如下:
模型结构很简单,没什么复杂的,实现也很容易,用的就是Keras,它都为我们实现好了现成的算法了。
现在我们来谈谈有意思的两步。
第一步是标注语料的收集。要注意我们的模型是监督训练的(至少也是半监督),所以需要收集一些已经分好类的句子,数量嘛,当然越多越好。而对于中文文本情感分类来说,这一步着实不容易,中文的资料往往是相当匮乏的。笔者在做模型的时候,东拼西凑,通过各种渠道(有在网上搜索下载的、有在数据堂花钱购买的)收集了两万多条中文标注语料(涉及六个领域)用来训练模型。
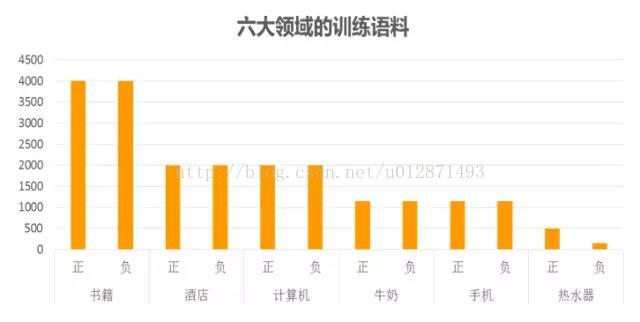
第二步是模型阈值选取问题。事实上,训练的预测结果是一个[0, 1]区间的连续的实数,而程序默认情况下会将0.5设为阈值,也就是将大于0.5的结果判断为正,将小于0.5的结果判断为负。这样的默认值在很多情况下并不是最好的。如下图所示,我们在研究不同的阈值对真正率和真负率的影响之时,发现在(0.391, 0.394)区间内曲线曲线了陡变。
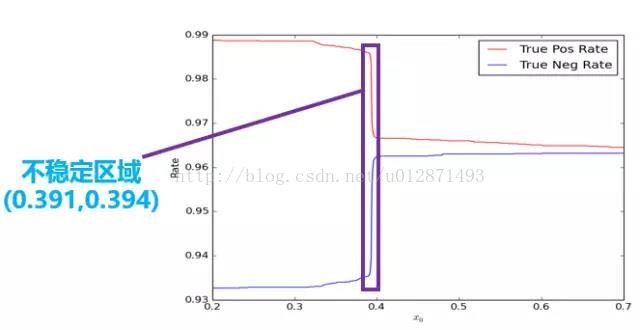
虽然从绝对值看,只是从0.99下降到了0.97,变化不大,但是其变化率是非常大的。正常来说都是平稳变化的,陡变意味着肯定出现了什么异常情况,而显然这个异常的原因我们很难发现。换句话说,这里存在一个不稳定的区域,这个区域内的预测结果事实上是不可信的,因此,保险起见,我们扔掉这个区间。只有结果大于0.394的,我们才认为是正,小于0.391的,我们才认为是负,是0.391到0.394之间的,我们待定。实验表明这个做法有助于提高模型的应用准确率。
说点总结
文章很长,粗略地介绍了深度学习在文本情感分类中的思路和实际应用,很多东西都是泛泛而谈。笔者并非要写关于深度学习的教程,而是只想把关键的地方指出来,至少是那些我认为是比较关键的地方。关于深度学习,有很多不错的教程,最好还是阅读英文的论文,中文的比较好的就是博客http://blog.csdn.net/itplus了,笔者就不在这方面献丑了。
下面是我的语料和代码。读者可能会好奇我为什么会把这些“私人珍藏”共享呢?其实很简单,因为我不是干这行的哈,数据挖掘对我来说只是一个爱好,一个数学与Python结合的爱好,因此在这方面,我不用担心别人比我领先哈。
语料下载,和采集到的评论数据,密码:dva4
搭建LSTM做文本情感分类的代码:
- import pandas as pd #导入Pandas
- import numpy as np #导入Numpy
- import jieba #导入结巴分词
- from keras.preprocessing import sequence
- from keras.optimizers import SGD, RMSprop, Adagrad
- from keras.utils import np_utils
- from keras.models import Sequential
- from keras.layers.core import Dense, Dropout, Activation
- from keras.layers.embeddings import Embedding
- from keras.layers.recurrent import LSTM, GRU
- from __future__ import absolute_import #导入3.x的特征函数
- from __future__ import print_function
- neg=pd.read_excel('neg.xls',header=None,index=None)
- pos=pd.read_excel('pos.xls',header=None,index=None) #读取训练语料完毕
- pos['mark']=1
- neg['mark']=0 #给训练语料贴上标签
- pn=pd.concat([pos,neg],ignore_index=True) #合并语料
- neglen=len(neg)
- poslen=len(pos) #计算语料数目
- cw = lambda x: list(jieba.cut(x)) #定义分词函数
- pn['words'] = pn[0].apply(cw)
- comment = pd.read_excel('sum.xls') #读入评论内容
- #comment = pd.read_csv('a.csv', encoding='utf-8')
- comment = comment[comment['rateContent'].notnull()] #仅读取非空评论
- comment['words'] = comment['rateContent'].apply(cw) #评论分词
- d2v_train = pd.concat([pn['words'], comment['words']], ignore_index = True)
- w = [] #将所有词语整合在一起
- for i in d2v_train:
- w.extend(i)
- dict = pd.DataFrame(pd.Series(w).value_counts()) #统计词的出现次数
- del w,d2v_train
- dict['id']=list(range(1,len(dict)+1))
- get_sent = lambda x: list(dict['id'][x])
- pn['sent'] = pn['words'].apply(get_sent) #速度太慢
- maxlen = 50
- print("Pad sequences (samples x time)")
- pn['sent'] = list(sequence.pad_sequences(pn['sent'], maxlen=maxlen))
- x = np.array(list(pn['sent']))[::2] #训练集
- y = np.array(list(pn['mark']))[::2]
- xt = np.array(list(pn['sent']))[1::2] #测试集
- yt = np.array(list(pn['mark']))[1::2]
- xa = np.array(list(pn['sent'])) #全集
- ya = np.array(list(pn['mark']))
- print('Build model...')
- model = Sequential()
- model.add(Embedding(len(dict)+1, 256))
- model.add(LSTM(256, 128)) # try using a GRU instead, for fun
- model.add(Dropout(0.5))
- model.add(Dense(128, 1))
- model.add(Activation('sigmoid'))
- model.compile(loss='binary_crossentropy', optimizer='adam', class_mode="binary")
- model.fit(xa, ya, batch_size=16, nb_epoch=10) #训练时间为若干个小时
- classes = model.predict_classes(xa)
- acc = np_utils.accuracy(classes, ya)
- print('Test accuracy:', acc)

