
- 1mysql:通过INFORMATION_SCHEMA数据库查询表的元信息_查看数据库指定表元信息
- 2数据结构 - Map 和 Set_set 和 map 数据结构
- 3大模型和数据要素赋能家装行业数字化转型建设和实施方案
- 4android 网络实时监听网络状态变化 及 网络类型判断,2024年您应该知道的技术之一_android 监听网络状态
- 5Android使用adb命令查看CPU信息_adb查看cpu型号
- 6B/S架构:手术室麻醉信息管理系统源码
- 7MicrosoftEdge浏览器打开网页出现“此网站被人举报不安全”问题时解决办法_此网站已被人举报不安全
- 8gradio 摄像头视频流获取_gradio 获取摄像头
- 9打不开GitHub解决方法(一)_打不开github上的代码
- 10redis 连接idea一直被拒绝
MATLAB、R用改进Fuzzy C-means模糊C均值聚类算法的微博用户特征调研数据聚类研究...
赞
踩
全文链接:http://tecdat.cn/?p=30766
本文就将采用改进Fuzzy C-means算法对基于用户特征的微博数据进行聚类分析。去年,我们为一位客户进行了短暂的咨询工作,他正在构建一个主要基于微博用户特征聚类研究的分析应用程序(点击文末“阅读原文”获取完整代码数据)。
首先对聚类分析作系统介绍。其次对改进Fuzzy C-means算法进行文献回顾,对其概况、基本思想、算法进行详细介绍,再是应用了改进Fuzzy C-means算法,本文的数据是由所设计地软件在微博平台上获取的调研数据,最后得到相关结论和启示。
相关视频
改进Fuzzy C-means 聚类算法是由 Steinhaus1955 年 Lloyd195年Ball&Hall1965 年 McQueen1967 年分别在各自的不同的科学研究领域独立的提出。改进Fuzzy C-means聚类算法被提出来后,在不同的学科领域被广泛研究和应用 并发展出大量不同的改进算法。它是研究比较多且应用比较广泛的一种基于划分的聚类算法。具有算法简单、易于实现、品于扩展,并且能够处理大数据集的特点。
聚类分析法概述
目前文献中存在着大量的聚类算法,大体上,聚类分析算法主要分成如下几种,图显示了一些主要的聚类算法的分类。
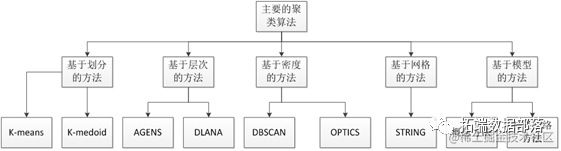
改进 Fuzzy C-means 算法
Fuzzy C-means算法概述
Fuzzy C-means算法是聚类算法中主要算法之一,它是一种基于划分的聚类算法,是最为经典的,同时也是使用最为广泛的一种基于划分的聚类算法,它属于基于距离的聚类算法。1967年,J.B.MacQueen提出的Fuzzy C-means算法是目前为止在工业和科学应用中一种极有影响的聚类技术。Fuzzy C-means 算法实现非常简单,运算效率也非常的高,适合对大型数据集进行分析处理。缺点是聚类结果不能重复,聚类结果跟初始点的选择有很大的关系,且不能作用于非凸集的数据。Fuzzy C-means算法对类球形且大小差别不大的类簇有很好的表现,但不能发现形状任意和大小差别很大的类簇,且聚类结果易受噪声数据影响。
应用
为了进一步验证改进Fuzzy C-means算法,本文将采集一批微博数据,通过根据微博用户特征属性对其进行聚类,并得出结论。
数据采集
新浪微博,作为中国的较大的用户使用较受欢迎的微博使用平台之一,从其平台上抽取的微博一定程度上可以反映国内微博平台用户的好友圈子情况。本文收集了发布微博用户特征数据,借鉴已有的相关研究和理论,进一步对数据进行标准化,数据中指标的取值如表所示。
| 指标 | 取值范围 |
|---|---|
| 您的朋友中大部分属于 | 同性或异性 |
| 你觉得自己个性如何 | 内向或者开朗 |
| 你是否愿意和兴趣相投的人成为朋友 | 愿意或者不愿意 |
| 您一般选择交什么样的朋友 | 0或1 |
| 你是否经常参与学生会或者社团组织的活动 | 经常或者偶尔 |
根据本文需求,采用编程软件在新浪微博平台上收集到的相关数据,具体样本实例如图所示,其中,对数据进行标准化
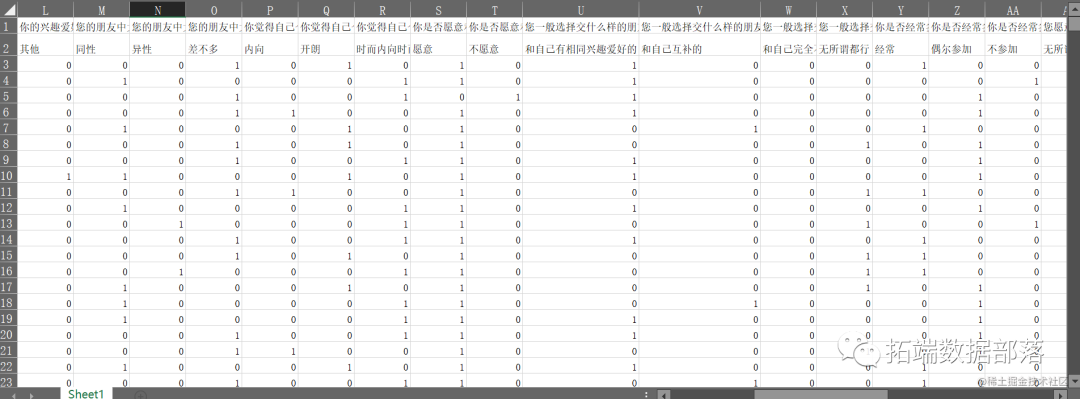
改进 Fuzzy C-means
本文采用MATLAB软件对数据进行改进Fuzzy C-means聚类分析。
数据挖掘是一个三级过程: 读入数据:通过一系列操作运行数据:把数据送到目的地。操作的这个顺序被称为数据流,通过每次操作数据流都会随着相关操作发生相关变化,最后,令那些目标数据输出一个模型或者可视化的结果。在MATLAB中,所有流程都与创建和修改数据流有关。本文具体过程如图所示。
仿真结果
具体结果如图所示,将该数据集分为了三类。
- [center,U,obj_fcn] =FCMClu(data,4);
- plot(data(:,1), data(:,2),'o');
- hold on;
- index1 = find(U(1,:) == maxU);
- index2 = find(U(2,:) == maxU);
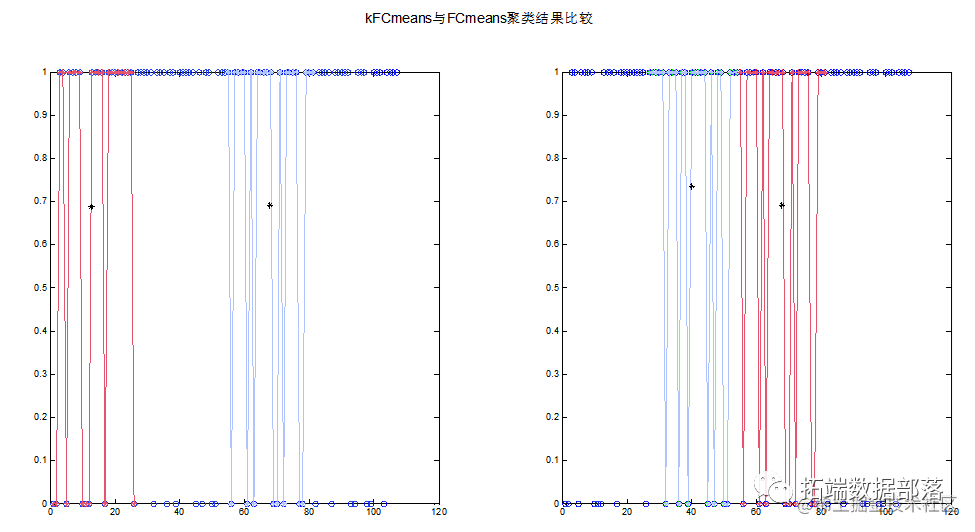
改进Fuzzy C-means算法将该样本集分为三类,其中最多的为cluster-3,其次是cluster-2,再者是cluster-1。为了验证该结果的可行性,又采用了R统计软件对样本进行了聚类分析。
点击标题查阅往期内容

数据分享|R语言分析上海空气质量指数数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法

左右滑动查看更多
01

02

03

04

具体代码如下所示:
- > x=read.table("clipboard"):
-
-
- > c<-hclust(dist(x),"single")
-
- > plot(c):
得到聚类结果如图所示。
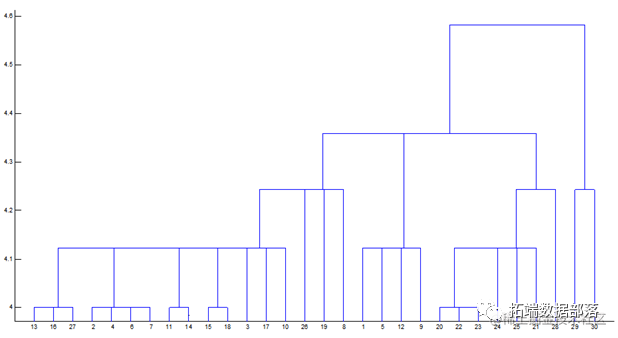
结论
本文研究了数据挖掘的研究背景与意义,讨论了聚类算法的各种基本理论包括聚类的形式化描述和定义,聚类中的数据类型和数据结果,聚类的相似性度量和准则函数等。同时也探讨学习了基于划分的聚类方法的典型的聚类方法。本文重点集中学习了研究了 改进Fuzzy C-means聚类算法的思想、原理以及该算法的优缺点。并运用改进Fuzzy C-means算法对所采集的数据进行聚类分析,深化了对该算法的理解。
但是本文也存在非常多的不足,例如未对较多的对改进Fuzzy C-means的改进算法作深刻剖析,对改进Fuzzy C-means实验的结果分析还并不到位。在后期中,这些都是值得深刻挖掘的。
参考文献
[1] 中国互联网络信息中心(CNNIC).第33次中国互联网络发展状况统计报告[EB/OL].
[2] 郭宇红,童云海,唐世渭等.数据库中的知识隐藏 [ J ].软件学报,2007, 11 (18) : 278222797.
[3] hehroz S.Khan,Amir Ahmad.Cluster center initialization algorithm for Fuzzy C-means clustering[J].Pattern Recognition Letters 25(2004): 1293-1302.
[4] 王春风,唐拥政.结合近邻和密度思想的K-均值算法的研究[J] 计算机工程应用.2011 年,47(19).147-149.

本文中分析的数据分享到会员群,扫描下面二维码即可加群!


点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《MATLAB、R用改进Fuzzy C-means模糊C均值聚类算法的微博用户特征聚类研究》。
点击标题查阅往期内容
数据分享|R语言分析上海空气质量指数数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法
R语言分布滞后非线性模型(DLNM)空气污染研究温度对死亡率影响建模应用
Python中的ARIMA模型、SARIMA模型和SARIMAX模型对时间序列预测
Python用RNN神经网络:LSTM、GRU、回归和ARIMA对COVID19新冠疫情人数时间序列预测
数据分享|PYTHON用ARIMA ,ARIMAX预测商店商品销售需求时间序列数据
Python用RNN神经网络:LSTM、GRU、回归和ARIMA对COVID19新冠疫情人数时间序列预测
【视频】Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析|数据分享
深度学习实现自编码器Autoencoder神经网络异常检测心电图ECG时间序列
Python中TensorFlow的长短期记忆神经网络(LSTM)、指数移动平均法预测股票市场和可视化
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言深度学习Keras循环神经网络(RNN)模型预测多输出变量时间序列
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类

![]()


