
- 1java商城答辩_毕业答辩-基于Java的网上购物商城的设计与实现.ppt
- 2边缘计算平台原理、关键功能以及技术优势_边缘端可实现哪些功能
- 3阿里云学习笔记_阿里云 个人学习
- 4【 Spark编程基础 】实验1_spark实验一
- 5这是我裸辞接单第一个月的收入
- 6《十堂课学习 Flink》第九章:Flink Stream 的实战案例一:CPU 平均使用率监控告警案例_flink内存cpu任务监控告警
- 7损失次数模型-负二项分布_负二项分布的概率密度函数
- 8怪物猎人物语游戏加载慢、卡加载解决方法一览
- 9图纸识别自动生成BOM清单的方法_图纸的ai自动识别、分析拆解
- 10Ubuntu介绍、与centos的区别、基于VMware安装Ubuntu Server 22.04、配置远程连接、安装jdk+Tomcat_centos ubuntu
4、最详细教程(Hadoop安装和配置)_hadoop基础教程
赞
踩
本文章为hadoop、hive安装系列第4/6个步骤,安装配置hadoop
目录
(10-1)start-dfs.sh和stop-dfs.sh
(10-2)start-yarn.sh和stop-yarn.sh
(1)上传hadoop安装包
上传方式介绍2种,一种是通过finallshell上传,一种是使用scp上传,我的是上传到/opt目录下了
(1-1)finalshell上传,此上传方式参考finallshell使用说明那篇文章
(1-2)scp -r hadoop-3.2.4.tar.gz root@地址:/opt,此上传方式参考scp使用那篇文章
(2)解压文件
使用tar命令解压安装包,解压到/opt目录下
- #解压文件
- tar -zxvf /opt/hadoop-3.2.4.tar.gz -C /usr/local/src/
(3)centos基础配置
在正式配置hadoop配置文件之前,需要先对centos系统进行基础配置
(3-1)关闭防火墙
- #关闭防火墙
- systemctl stop firewalld
- #禁止防火墙开机启动
- systemctl disable firewalld.service
(3-2)关闭selinux
- #通过vi编辑器打开配置文件
- vi /etc/selinux/config
- #将文件中SELINUX=enforcing中 enforcing 改为disabled
- SELINUX=disabled
- #重启centos
- reboot
- #查看selinux状态 状态应为Permissive或者disabled说明设置成功
- getenforce
(3-3)编辑hosts映射文件
#修改主机域名映射,IP地址根据自己设置的固定地址填写,我电脑配置比较低我设置了一个从节点slave1
- #使用vi编辑器打开配置文件
- vi /etc/hosts
- #添加主机域名映射等信息,根据自己设置的固定IP填写,从节点有几个就写几个
- 192.168.100.128 master
- 192.168.100.129 slave1
(3-4)修改主机名称
- #修改主机名
- hostnamectl set-hostname master
- #重启生效
- reboot
(4)修改Hadoop配置文件
Hadoop配置文件放在 /usr/local/src/hadoop-3.2.4/etc/hadoop/目录下,我的Hadoop解压目录为/usr/local/src/,进入配置文件目录开始编辑配置文件
- #进入hadoop配置目录
- cd /usr/local/src/hadoop-3.2.4/etc/hadoop/
(4-1)core-site.xml
在core-site.xml文件中添加设置信息
- #使用vi编辑器打开配置文件
- vi core-site.xml
- #把以下内容添加到core-site.xml文件的<configuration></configuration>之间
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://master:9000</value>
- </property>
- <property>
- <name>io.file.buffer.size</name>
- <value>131072</value>
- </property>
- <!-- 指定hadoop缓存文件存放位置 -->
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/usr/local/src/hadoop-3.2.4/tmp</value>
- </property>
(4-2)hdfs-site.xml
- #使用vi编辑器打开配置文件
- vi hdfs-site.xml
- #把以下内容添加到hdfs-site.xml文件的<configuration></configuration>之间
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/usr/local/src/hadoop-3.2.4/dfs/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/usr/local/src/hadoop-3.2.4/dfs/data</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
(4-3)mapred-site.xml
- #使用vi编辑器打开配置文件
- vi mapred-site.xml
- #把以下内容添加到mapred-site.xml文件的<configuration></configuration>之间
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>master:10020</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>master:19888</value>
- </property>
(4-4)yarn-site.xml
- #使用vi编辑器打开配置文件
- vi yarn-site.xml
- #把以下内容添加到yarn-site.xml文件的<configuration></configuration>之间
- <!-- Site specific YARN configuration properties -->
- <property>
- <name>yarn.resourcemanager.address</name>
- <value>master:8032</value>
- </property>
- <property>
- <name>yarn.resourcemanager.scheduler.address</name>
- <value>master:8030</value>
- </property>
- <property>
- <name>yarn.resourcemanager.resource-tracker.address</name>
- <value>master:8031</value>
- </property>
- <property>
- <name>yarn.resourcemanager.admin.address</name>
- <value>master:8033</value>
- </property>
- <property>
- <name>yarn.resourcemanager.webapp.address</name>
- <value>master:8088</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>

(4-5)hadoop-env.sh
- #使用vi编辑器打开配置文件
- vi hadoop-env.sh
- # 添加以下内容
- export JAVA_HOME=/opt/jdk
(4-6)yarn-env.sh
- #使用vi编辑器打开配置文件
- vi yarn-env.sh
- # 添加以下内容
- export JAVA_HOME=/opt/jdk
(4-7)编辑Slaves
#vi slaves(hadoop3点多版本是进入 workers ) 我用的hadoop版本是Hadoop3.2.4所以使用vi workers
- #使用vi编辑器打开配置文件
- vi workers
- #删除原本的localhost
- master
- slave1
(5)新建缓存目录
- #新建缓存目录
- mkdir /usr/local/src/hadoop-3.2.4/tmp
- mkdir /usr/local/src/hadoop-3.2.4/dfs/name -p
- mkdir /usr/local/src/hadoop-3.2.4/dfs/data -p
(6)编辑环境变量
- #使用vi编辑器打开配置文件
- vi /etc/profile
- #配置文件中添加以下内容
- export HDFS_NAMENODE_USER=root
- export HDFS_DATANODE_USER=root
- export HDFS_SECONDARYNAMENODE_USER=root
- export YARN_RESOURCEMANAGER_USER=root
- export YARN_NODEMANAGER_USER=root
- #保存退出后生效环境变量
- source /etc/profile
(7)克隆节点
需要几个从节点就克隆几个从节点,我仅仅克隆了一个,如果克隆多个步骤一样
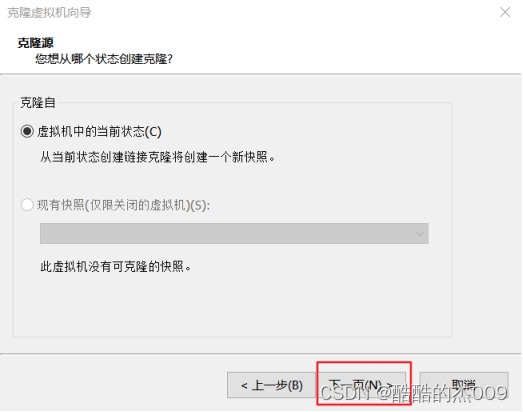
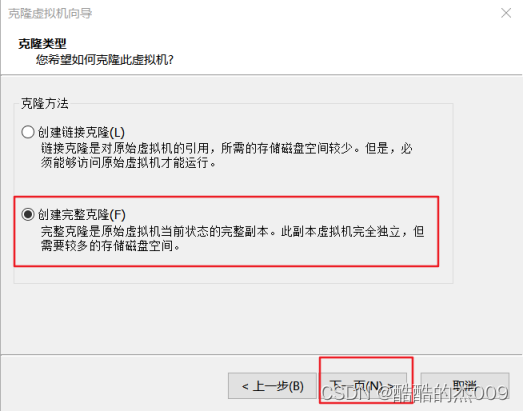
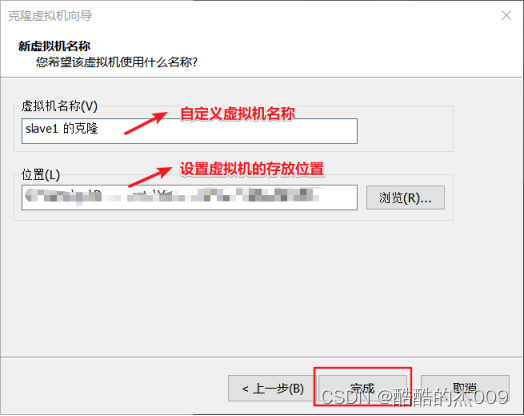
(7-1)克隆节点
【虚拟机】-【管理】-【克隆】
(7-2)修改从节点网络配置文件
本步骤在从机中操作,如果未写在从机还是主机,都在主机中操作
- #进入ens33网络配置文件的目录
- cd /etc/sysconfig/network-scripts/
- #打开配置文件
- vi ifcfg-ens33
根据基础设置部分/etc/hosts主机映射修改IPADDR,修改完成后重启服务并测试
- #重启network服务
- systemctl restart network
- #ping baidu 测试
- ping baidu.com
(7-3)修改虚拟机名称
本步骤在从机中操作,如果未写在从机还是主机,都在主机中操作
根据基础设置部分/etc/hosts主机映射名称修改,我的从节点为slave1,所以修改为slave1
- #修改主机名称
- hostnamectl set-hostname slave1
- #重启生效
- reboot
(8)设置ssh免密登录
- #生成密钥#默认回车到最后
- ssh-keygen
- #将密钥传给其他机器master slave1
- ssh-copy-id master
- yes
- #输入密码
- #测试是否成功
- ssh master
- ssh-copy-id slave1
- yes
- #输入密码
- #测试是否成功
- ssh slave1
(9)格式化hdfs
- #hdfs格式化
- hdfs namenode -format
(10)编辑配置文件
进入配置文件所在目录
- #进入配置文件所在目录
- cd /usr/local/src/hadoop-3.2.4/sbin
(10-1)start-dfs.sh和stop-dfs.sh
a:编辑start-dfs.sh
- #打开配置文件
- vi start-dfs.sh
- #添加以下
- HDFS_DATANODE_USER=root
- HDFS_DATANODE_SECURE_USER=hdfs
- HDFS_NAMENODE_USER=root
- HDFS_SECONDARYNAMENODE_USER=root
b:编辑stop-dfs.sh
- #打开配置文件
- vi stop-dfs.sh
- #添加以下
- HDFS_DATANODE_USER=root
- HDFS_DATANODE_SECURE_USER=hdfs
- HDFS_NAMENODE_USER=root
- HDFS_SECONDARYNAMENODE_USER=root
(10-2)start-yarn.sh和stop-yarn.sh
a:编辑start-yarn.sh
- #打开配置文件
- vi start-yarn.sh
- #添加以下
- YARN_RESOURCEMANAGER_USER=root
- HADOOP_SECURE_DN_USER=yarn
- YARN_NODEMANAGER_USER=root
b:编辑stop-yarn.sh
- #打开配置文件
- vi stop-yarn.sh
- #添加以下
- YARN_RESOURCEMANAGER_USER=root
- HADOOP_SECURE_DN_USER=yarn
- YARN_NODEMANAGER_USER=root
(10)启动hadoop
- #启动hadoop
- start-all.sh
- #使用jps查看hadoop服务启动情况
- jps

