
热门标签
热门文章
- 1推荐一款正基AP6255/AP6256代替型号CW2455-44_s912 ap6255
- 2数据结构与算法-顺序表_顺序表的每个元素占8个存储单元
- 3Debezium MySQL源连接器配置属性_inconsistent.schema.handing.mode
- 4一篇文章带你彻底了解【模拟器过检测】_蓝叠过检测
- 5数据结构进阶实训二_看到这一关的任务你是不是想到这样子做呢? for(int i = 0; i< 10; i++){ s
- 6基于Quartus Prime18.1的安装与FPGA的基础仿真(联合Modelsim)教程_intel庐 quartus庐 prime lite edition design software
- 7GPT-4:从纠正错误代码中揭示成熟大模型的涌现能力_大模型代码纠错
- 8西门子1500PLC机器人焊接程序:智能化与高效能的西门子PLC+西门子触摸屏实现的综合控制系统_机器人焊接plc程序
- 9mvn install:install-file maven手动安装第三方jar包报错的一种情况_mvn install:install-file报错
- 10html5边界是什么意思,边界感是什么意思
当前位置: article > 正文
参数高效微调方法(Parameter-Efficient Fine-Tuning,PEFT)概述
作者:喵喵爱编程 | 2024-07-20 19:37:43
赞
踩
参数高效微调
参数高效微调是指通过在预训练模型上仅微调部分参数来实现微调的策略。相较于全量微调,该方法节省计算资源和时间,特别适用于数据量有限、资源有限的情况。它也算是一种迁移学习的方法,但是与传统的迁移学习方法不同的是,它是专门针对大模型设计的,通常会保持原有模型的参数不变,以某种方式添加少量新的参数,通过调整这些新的参数使模型适应特定任务,同时保留底层通用的语义表示。而传统的迁移学习方法一般要达到比较好的效果,都不得不调整一部分原有模型的参数。同时,在保存或移植模型时,PEFT只要维护添加的那些参数,而传统的迁移学习方法需要保存整个调整后的模型,当需要微调很多任务时,通过PEFT微调模型可以大幅节省存储空间。
目前,参数高效微调因其调整的参数占比很小(小于10%甚至0.1%),所需运算资源少,在同时需要出来很多下游任务时,节省大量存储空间,在目的单一的较小的样本集里(小于预训练语料的10%),已逐渐成为主流的微调方法。近年来,参数高效微调发展迅速,已出现30种以上的参数高效微调方法,如所示,它们可以分为3大类:
- 选择性方法(selective):只微调原始LLM参数的子集。
- 添加性方法(additive):通过添加一些可训练的层或参数来调整基础模型。它又可以分为2个小类:
- 适配器(adapters):通过在基础模型中加入一些可调整参数的组件、模块来使模型适应下游任务。
- 软提示词(soft prompts):通过某种方式达到给输入加入提示词的效果,从而适应下游任务。
- 重新参数化方法(reparameterization-based):通过创建原始网络权重的新低秩转换来减少要训练的参数数量。
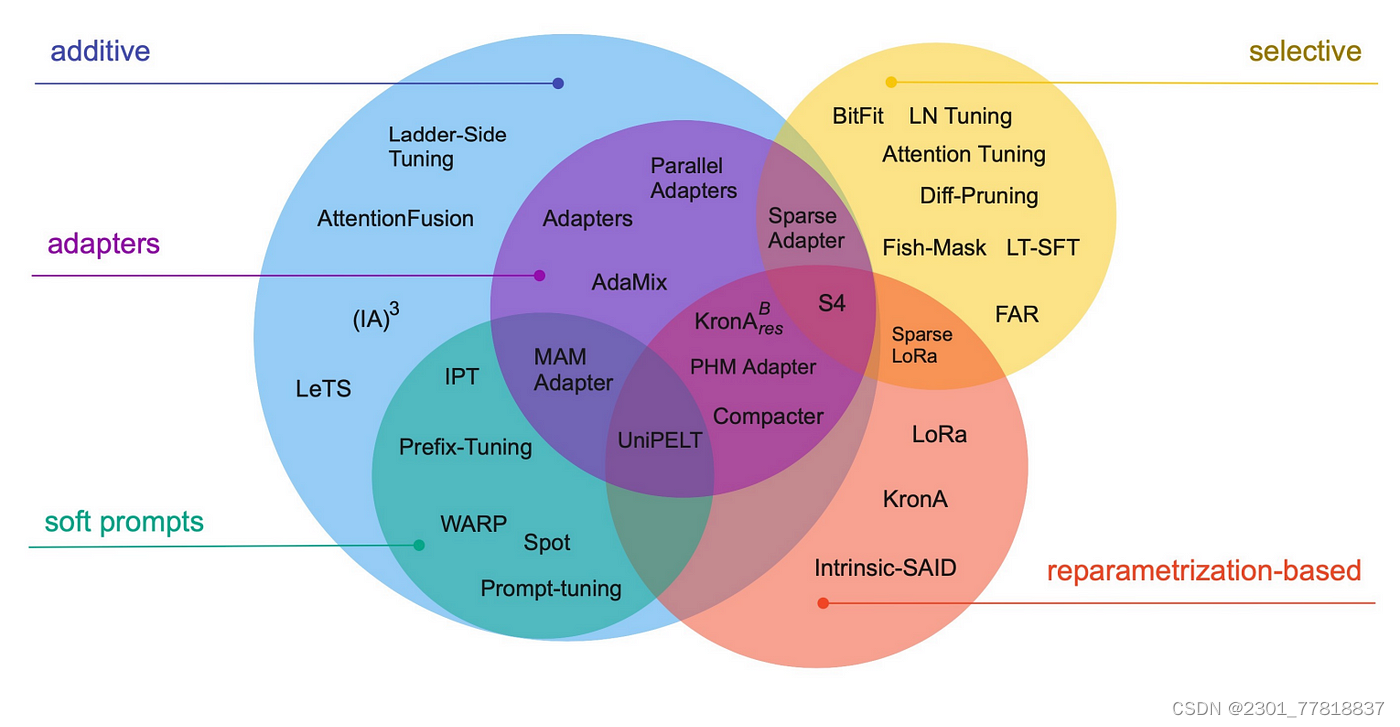
参数高效微调方法这么多,后续文章将会介绍几种比较有代表性的参数高效微调方法,如:适配器微调(Adapters tuning)、LoRA、前缀微调(Prefix tuning)、提示词微调(Prompt tuning)、P-tuning等。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/858119
推荐阅读
相关标签

