
热门标签
热门文章
- 1iOS 18(macOS 15)Vision 中新增的任意图片智能评分功能试玩
- 2Java 区块链BLOCKCHAIN中区块BLOCK的hash值的计算_通过blockchain计算哈希值
- 3【MATLAB UAV Toolbox】使用指南(一)
- 4【每日AI】什么是机器学习(ML)?
- 5ElasticSearch[八]:自定义评分功能、使用场景讲解以及 function_score常用的字段解释_通过esjavaapi实现自定义评分功能 es评分算法
- 6Web Scraper 网络爬虫零基础详细使用教程,爬取京东商品搜索结果、商品价格、规格参数等,爬取二级网页、滚动加载网页,京东安全验证小技巧
- 72023年03月 Python(六级)真题解析#中国电子学会#全国青少年软件编程等级考试_2023年3月份python六级
- 8Elasticsearch基础(六):使用Kibana Lens进行数据可视化_elasticsearch可视化
- 9怎么像在finalshell上一样方便地传送与编辑甲骨文vps上的文件_甲骨文vps工单怎么提
- 1003 pytorch 验证指标工具 torchmetrics_torchmetrics安装包
当前位置: article > 正文
[深度学习]使用python转换pt并部署yolov10的tensorrt模型封装成类几句完成目标检测加速任务_yolov10n.pt
作者:喵喵爱编程 | 2024-08-07 18:29:49
赞
踩
yolov10n.pt
【简单介绍】
使用Python将YOLOv10模型从PyTorch格式(.pt)转换为TensorRT格式,并通过封装成类来实现目标检测加速任务,是一个高效且实用的流程。以下是该过程的简要介绍:
- 模型转换:
- 利用官方提供导出命令,将训练好的YOLOv10模型(.pt格式)转换为tensorrt模型。
- 利用NVIDIA的TensorRT框架,将ONNX模型转换为TensorRT引擎,以优化在NVIDIA GPU上的运行速度。
- TensorRT模型封装:
- 创建一个Python类,该类负责加载TensorRT引擎、处理输入数据、执行推理以及解析输出结果。
- 封装类中包含模型加载、预处理、后处理以及推理执行等关键步骤,提供简洁的API供用户调用。
- 目标检测加速:
- TensorRT通过算子融合、量化、内核自动调整等技术,显著减少数据流通次数和显存使用,最大化并行操作,从而加速目标检测任务。
- YOLOv10模型本身的轻量级设计和高效性能,在TensorRT的加持下,能够实现更快的推理速度和更高的检测精度。
通过上述流程,我们可以将YOLOv10模型高效地部署到NVIDIA GPU上,实现快速且准确的目标检测任务。
【实现流程】
1、首先安装好anaconda环境然后开始安装yolov10环境
- conda create -n yolov10 python=3.9
- conda activate yolov10
- pip install -r requirements.txt
- pip install -e .
2、下载好tensorrt8.6.1.6版本安装包进行安装,并将tensorrt安装到yolov10环境中
3、导出模型
- yolo export model=jameslahm/yolov10{n/s/m/b/l/x} format=engine half=True simplify opset=13 workspace=16
- # or
- trtexec --onnx=yolov10n/s/m/b/l/x.onnx --saveEngine=yolov10n/s/m/b/l/x.engine --fp16
- # Predict with TensorRT
- yolo predict model=yolov10n/s/m/b/l/x.engine
您也可以直接使用我封装的转换接口:
- #pt转tensorrt
- detector = Yolov10Detector(weights='weights/yolov10n.pt')
- detector.pt_to_engine()
转换注意:由于tensorrt依赖于硬件,也就是不同电脑可能无法使用同一个tensorrt模型,因此需要在自己电脑本地首先转换pytorch模型为tensorrt模型,而不是直接拿别人转换好的tensorrt模型,否则可能会出现检测不到目标或者无法加载模型情况。
【封装调用】
推理图片:
- #推理图片
- detector = Yolov10Detector(weights='weights/yolov10n.engine')
- frame = cv2.imread('E:\person.jpg')
- result_list = detector.inference_image(frame)
- result_img = detector.draw_image(result_list, frame)
- cv2.imshow('frame', result_img)
- cv2.waitKey(0)
推理视频:
- #推理视频
- detector = Yolov10Detector(weights='weights/yolov10n.engine')
- detector.start_video(r'D:\car.mp4')
推理摄像头:
- #推理视频
- detector = Yolov10Detector(weights='weights/yolov10n.engine')
- detector.start_camera()
【效果展示】
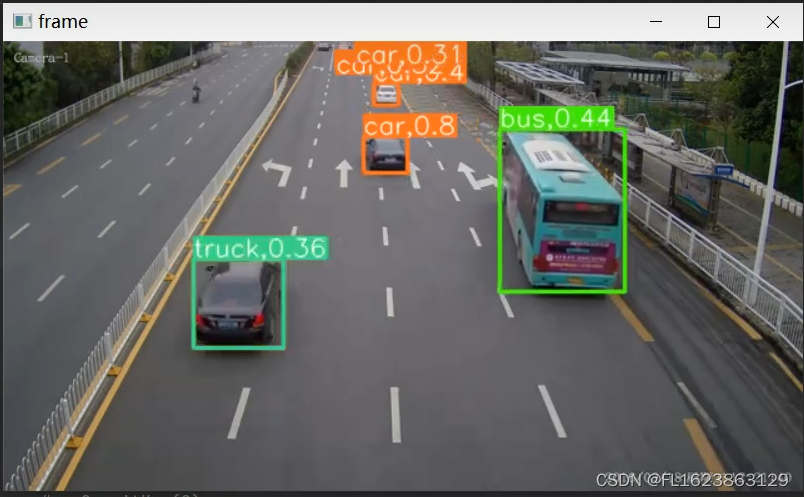
【视频演示】
【测试环境】
torch==2.0.1 tensorrt==8.6.1.6 cuda==11.7.1 cudnn==8.8.0
【源码下载】 https://download.csdn.net/download/FL1623863129/89426162
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/943914
推荐阅读
相关标签

