
- 1Linux kernel权限提升漏洞(CVE-2024-1086)
- 2【ai】livekit:Agents 3 : pythonsdk和livekit-agent的可编辑模式下的安装_live kit agent
- 3Redis Stack 安装部署_redis-stack-server
- 4【OD统一考试(C卷)考生抽中题】悄悄话花费的时间,用 C++ 编码,速通_给定一个二叉树,每个节点上站一个人,节点数字表示父节点到该节点传递悄悄话需要花
- 5每天一道大厂SQL题【Day31】腾讯QQ(二)按类别统计QQ号相关信息
- 6ICLR 2022 | Transformer不比CNN强!Local Attention和动态Depth-wise卷积
- 7带宽和网速的关系
- 8集成ECharts到若依框架:原理与使用方法详解_若依 echarts
- 9Python基础————19、日期和时间_python什么模块有很广泛的方法用来处理年历和日历
- 10数据结构之堆_堆分为大根堆和小跟堆
浅谈Attention与Self-Attention,一起感受注意力之美_attention和self-attention区别
赞
踩
浅谈Attention与Self-Attention的前世今生
前言
2017年的某一天,Google 机器翻译团队发表了《Attention is All You Need》这篇论文,犹如一道惊雷,Attention横空出世了!(有一说一,这标题也太他喵嚣张了,不过人家有这个资本(o゚▽゚)o )
很快Attention就被推上了神坛,搭载着犹如核弹的Transformer,Bert出现了,在NLP的各个任务上屠榜,后来预训练模型遍地开花,在NLP的各个领域大放异彩。让人一度觉得NLP只需要一个Transformer就够了。让他们火的一塌糊涂的正是Attention,今天就来浅谈一下Attention。
Attention是什么?
Attention机制翻译过来叫作注意力机制,Self-Attention叫作自注意力机制。它的思想很简单,起初灵感就来源于人眼和人脑。我们人用眼睛观察东西的时候,大脑会有意识或无意识地观察某些地方,这就是人的注意力。更形象点描述注意力,可以找找下图的感觉。
根据万物皆可AI的原理,我们也想让计算机get到这种能力。那些个天才研究员就去捣鼓,最后捣鼓出了计算机版的注意力机制,就叫Attention机制。
Attention和Self-Attention的计算过程?
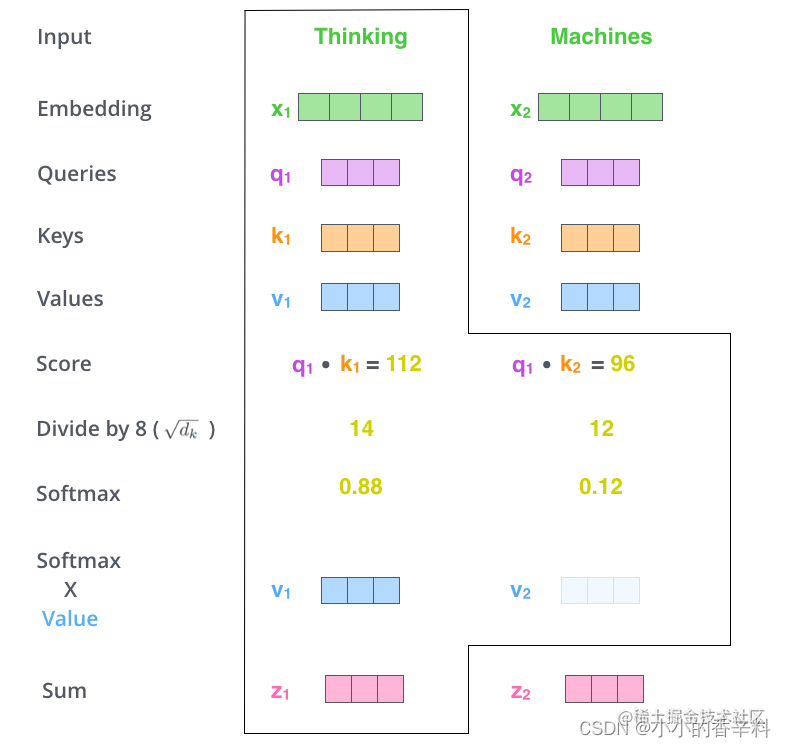
对于计算机来说,想要表达一个东西的重要程度,最直观的方式就是用数字来表示。如果一个数越大,可以认为它越重要,Attention就是这样的。在一些任务中,我们会通过矩阵的数学运算得到某两个东西之间的值,它反映了这两个东西之间的相关程度,或者说“注意程度”,这个值就是注意力权重。再把这个注意力权重乘上对应的值就得到了某个东西关注另一个东西的程度,这就是注意力分数。计算机就是通过这个分数实现注意力机制的。
下面举个例子上说明一下注意力和自注意力,可能不够严谨,但足以说明注意力和自注意力是什么了。
首先我们不去考虑得到注意力分数的细节,而是把这个操作认为是一个封装好的函数。比如定义为attention_score(a,b),表示词a和b的注意力分数。现在有两个句子A=“you are beautiful”和B=“你很漂亮”,我们想让B句子中的词“你”更加关注A句子中的词“you”,该怎么做呢?答案是对于每一个A句子中的词,计算一下它与“you”的注意力分数。也就是把
attention_score(“you”,“你”)
attention_score(“are”,“你”)
attention_score(“beautiful”,“你”)
都计算一遍,在实现attention_score这个函数的时候,底层的运算会让相似度比较大的两个词分数更高,因此attention_score(“you”,“你”)的分数最高,也相当于告诉了计算机,在对B句子中“你”进行某些操作的时候,你应该更加关注A句子中的“you”,而不是“are”或者“beautiful”。
以上这种方式就是注意力机制,两个不同的句子去进行注意力的计算。而当句子只有一个的时候,智能去计算自己与自己的注意力,这种方式就是自注意力机制。比如只看A句子,去计算
attention_score(“you”,“you”)
attention_score(“are”,“you”)
attention_score(“beautiful”,“you”)
这种方式可以把注意力放在句子内部各个单词之间的联系,非常适合寻找一个句子内部的语义关系。
关于严格的数学公式推导,推荐看源论文《Attention is All You Need》,对注意力分数计算的可视化展示感兴趣的童鞋推荐Jay Alammar的图解Transformer系列:https://jalammar.github.io/illustrated-transformer/
下图就浓缩了Attention的计算过程
Attention和Self-Attention的区别?
说完了Attention的计算方式,下面我想谈谈我自己对Attention与Self—Attention的理解。
在我看来,他们都是针对Encoder-Decoder结构的。在经典的seq2seq机器翻译任务中,根据源句子与目标句子是否相同,分成了Attention和Self-Attention。
其中,Attention是应用在源句子与目标句子不同时,是为了解决rnn的一些问题的。使用rnn的缺点在于,通常的rnn结构由于是单向传导,时序性太强,会导致从Encoder出来的信息太过拥挤,全都集中在Encoder最后一个词这里了。而Decoder翻译的时候其实更需要当前 要翻译的这个词的(中英)信息 ,我们实际上不希望从Encoder的最后一个位置拿到信息。并且当要翻译的句子越长,解码的效果越差。
举个例子,中英翻译 “我爱你” -> “I love you”。
我们期望Decoder在翻译“I”的英文的时候,把注意力放在中文的“我”身上,而不希望从“你”身上拿到信息。实际上,这个操作叫作单词对齐。
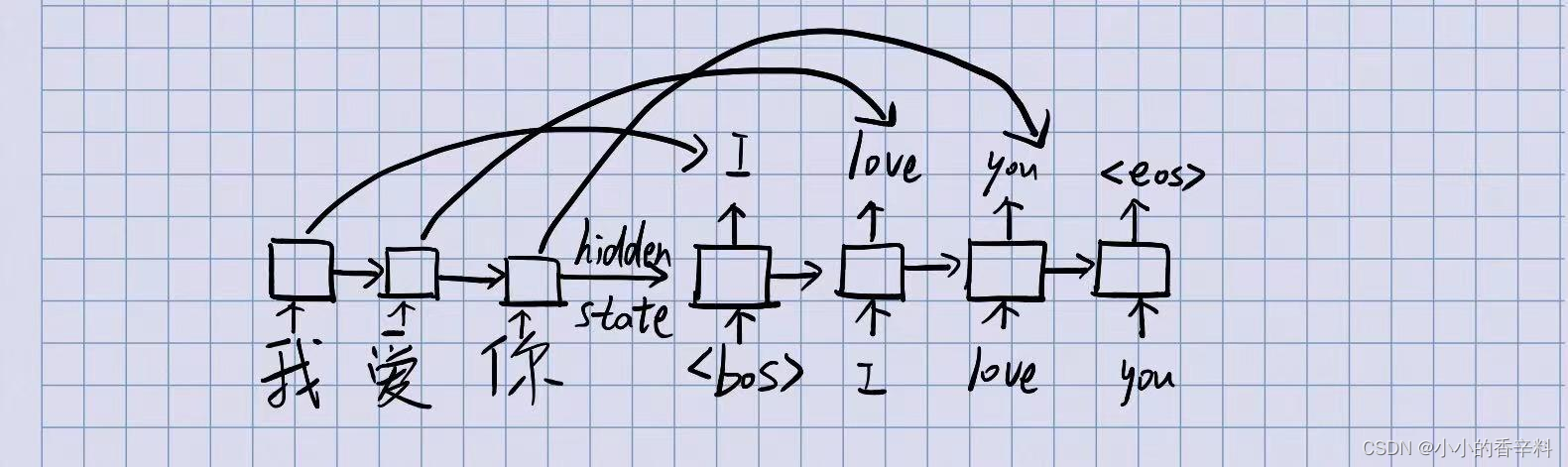
使用传统rnn不能实现这一点,而用注意力机制就可以很好的实现这一点,因为注意力的计算不依赖于上一个单词。除此之外,Attention的相比rnn还大大增加了计算效率,不同距离的单词也可以很快的完成计算,不管被计算的这两个单词距离多远,计算注意力花的时间是一样的,这样就可以实现并行计算了。
注意力机制发生在Target的元素Query和Source中的所有元素之间。
而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而已。
怎么理解自注意力呢?比如这句话“这只蝴蝶真漂亮,停在花朵上,我很喜欢它”,我们怎么知道这个“它”指的是“蝴蝶”还是“花朵”呢?答案是用自注意力机制计算出这个“它”和其他所有输入词的“分数”,这个“分数”一定程度上决定了其他单词与这个联系。可以理解成越相似的,分就越高。通过计算,发现对于“它”这个字,“蝴蝶”比“花朵”打的分高。所以对于“它”来说,“蝴蝶”更重要,我们可以认为这个“它”指的就是蝴蝶。
通过上面的例子,你会发现整个过程没有涉及翻译的过程,也就没有从“源句子”转化成“目标句子”这一个过程,或者说此时“源句子”=“目标句子”。这种情况就是对输入(也就是”源句子“)自身去计算注意力,称为自注意力。
总结一下,区别与联系主要在以下几点:
- 在翻译任务中,如果源句子 ≠ \neq =目标句子,那么你用目标句子中的词去query源句子中的所有词的key,再做相应运算,这种方式就是Attention;如果你的需求不是翻译,而是对当前这句话中某几个词之间的关系更感兴趣,期望对他们进行计算,这种方式就是Self-Attention。
- 从范围上来讲,注意力机制是包含自注意力机制的。注意力机制给定K、Q、V,其中Q和V可以是任意的,而K往往等于V(不相等也可以);而自注意力机制要求K=Q=V。
以上就是本文的全部内容了,科研期间更博不易,如果您觉得写的还不错,欢迎点赞关注,让我们一起变得更强~

