
- 1Windows系列:【Git】‘git‘ 不是内部或外部命令,也不是可运行的程序以及解决GitHub开启双重验证问题(包括GitHub注册)_git' 不是内部或外部命令,也不是可运行的程序 或批处理文件。
- 2(解决方案)docker could not select device driver |Docker 无法成功分配或访问GPU资源_docker: error response from daemon: could not sele
- 3MySQL 并发事务问题和隔离级别 (事务篇 三)_在mysql中,如果一个事务读取了一些数据行,而在同一个事务中,另一个事务可能删除了
- 4多线程环境下输出流混乱问题_多线程执行时一开始执行流冲突 打印乱
- 5数电(第一章 数制和码制)_数电第一章
- 6Linux基础命令
- 7业余电子试验的用电安全之我的建议
- 8渗透神器:burpsuit教程_渗透工具bp
- 9springboot 实现机器学习_SpringBoot 实现热部署(3种方式)
- 10植物大战僵尸杂交版 2.0.8 Mac畅玩详细教程_mac如何玩植物大战僵尸
并行程序设计期末复习纲要_并行程序设计期末考试
赞
踩
并行程序设计复习纲要
Parallel Programming Review
两天速成并行!汇总了(部分)2023Spring谷老师的并行程序设计PPT内容。
基础知识
当代并行计算机体系结构
均匀存储访问模型 UMA
物理存储器被所有处理器均匀共享,所有处理器访问任何存储字取相同的时间。
非均匀存储访问模型 NUMA
被共享的存储器在物理上是分布在所有的处理器中的,其所有本地存储器的集合就组成了全局地址空间;处理器访问存储器的时间是不一样的。
全高速缓存存储访问 COMA
全部高速缓存组成了全局地址空间;就用缓存!就用缓存!数据开始时可任意分配,因为在运行时它最终会被迁移到要用到它们的地方
高速缓存一致性非均匀存储访问模型 CC-NUMA
分布共享存储的DSM多处理机系统;自动在各节点分配数据
是非远程存储访问模型 NORMA
所有存储器是私有的;绝大数NUMA都不支持远程存储器的访问
并行编程模式
主从式:将一个待求解的任务分成一个主任务和一些从任务
单程序多数据流SPMD:并行运行的进程均执行相同的代码段,但处理的数据不同。
数据流水线:将计算进程组织成一条流水线,每个进程执行特定的计算任务
分治策略:将一个大而复杂的问题分解成若干个特性相同的子问题分而治之
PCAM
划分Partitioning、通信Communication、组合Agglomeration、映射Mapping

共享数据访问
共享内存系统并行编程最基本的挑战是:当多个线程需要更新共享资源时,结果可能是不可预知的

但互斥锁降低并行性,solution是:
- 为每个线程定义私有变量
- 该段代码不再是临界区,可以并行访问
- 定义私有变量后累积
- 指定某个线程进行累积
Barrier
所有线程都抵达此路障,线程才能继续运行下去,否则会阻塞在路障处
Pthreads(POSIX线程库)
支持 创建并行环境、同步、隐式通信

Π计算
long my_rank = (long)rank;//当前线程的序号
double factor;
long long i;
long long my_n = n/thread_count;//每个线程执行的计算数
long long my_first_i = my_n * my_rank;//当前线程的第一个数字
long long my_last_i = my_first_i + my_n;//当前线程最后一个数字
- 1
- 2
- 3
- 4
- 5
- 6
-
使用标志变量
flag,实现sum的有序加和,为减少临界区执行次数(增加并行性),给每个线程配置私有变量my_sum存储各自的计算结果
-
pthread_mutex_t
需要先初始化,结束后回收空间
pthread_mutex_lock和pthread_mutex_unlock
线程执行临界区的顺序是随机的
-
信号量
需要先初始化,结束后回收空间
sem_wait(信号量–)和sem_post(信号量++)
同步
-
忙等待和互斥锁实现路障
锁一个counter记录执行到此处的线程数量
-
信号量实现路障
对前count-1个线程sempost(count_sem)并且sem_wait(barrier_sem),对最后一个线程sempost(count_sem)并且sem_post(barrier_sem)count-1次。
线程被阻塞在sem_wait 不会消耗CPU 周期,所以用信号量实现路障的方法比用忙等待和互斥锁实现的路障性能更好。
-
条件变量
共享变量,需要与互斥锁一起使用
//唤醒一个阻塞的线程 int pthread_cond_signal(pthread_cond_t* cond_p) ; //唤醒所有阻塞的线程 int pthread_cond_broadcast(pthread_cond_t* cond_p) ; //使用互斥锁阻塞线程 int pthread_cond_wait(pthread_cond_t* cond_p, pthread_mutex_t* mutex_p ) ;- 1
- 2
- 3
- 4
- 5
- 6
数据依赖
如果两个存储访问操作访问相同的存储位置(同一个变量),其中一个访问是写(或更新)操作,则两个操作间存在数据依赖
距离向量

最左边为正数或所有元素都为0时字典序非负,此时依赖关系合法
[1,1]的方向向量是[<,<](左边<=合法)
循环转换
原循环不可能存在[>,\*][=,>]
[<,>]也不合法
循环分块
循环分块的本质是在外层循环探索内层循环时间上和空间上的重用
循环展开
 增加了循环内部的并行度;减少了循环次数即减少了控制语句,提升性能
增加了循环内部的并行度;减少了循环次数即减少了控制语句,提升性能
Questions
-
好吧,为什么quiz没有依赖?
还真没有。无语
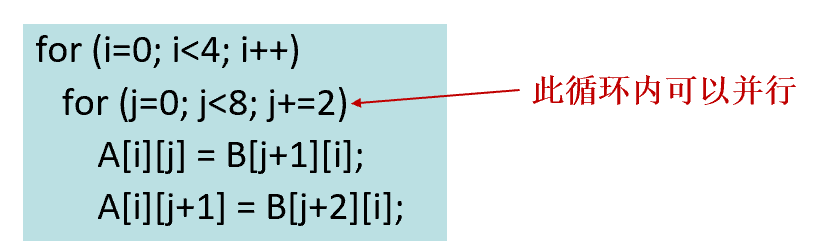
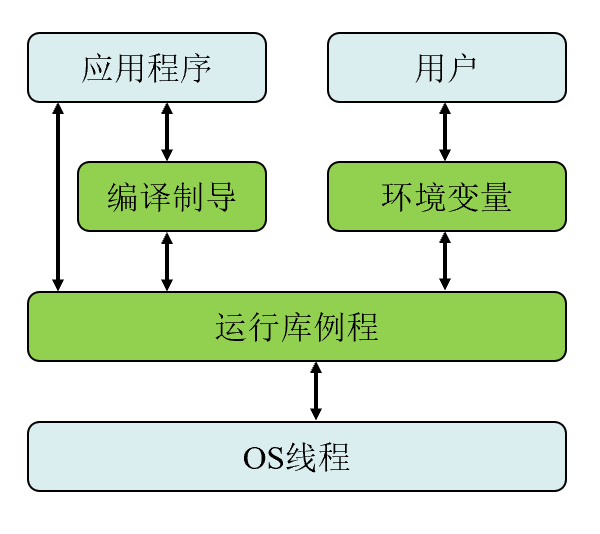
OpenMP (Open Multi-Processing)
针对共享内存的应用编程接口(API)-多线程、共享内存
三个主要API组件:编译器指令、运行时库函数、环境变量
#pragma omp parallel private(nthreads, tid)
{
tid = omp_get_thread_num(); /*获得线程id*/
printf("Hello World from OMP thread %d\n", tid);
/*主线程工作*/
if (tid==0) {
nthreads = omp_get_num_threads(); /*获得线程数量*/
printf("Number of threads %d\n", nthreads);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 一个线程执行到一个并行指令时,Fork一组线程并成为该线程组的主线程(线程号为0)
- 从并行区域开始,代码被复制,一组线程都执行该代码
- 并行区域出口隐含barrier,只有主线程继续执行
数据范围属性子句

if子句
parallel后,表达式为真才创建线程组,否则该区域由主线程串行执行
num_threads子句
用于设置运行并行区域的线程数量

使用限制
-
并行区域不能是跨越多个程序或代码文件的结构化块
-
从一个并行区域只能有一个入口和一个出口,任何转入和转出都是非法的
–不能包含break语句
-
只允许一个if子句和一个num_threads子句
-
程序运行结果不能依赖于子句的顺序
for指令
必须由线程组并行执行
#pragma omp for [[clause[[,]clause]…]
for-loops
- 1
- 2
schedule子句
schedule(kind[,chunk_size]) 描述循环迭代如何划分给多个线程
kind:
static:循环迭代被划分成小块,静态的分配给线程,chunk_size若不指定则迭代均匀连续划分给线程
dynamic:在线程间动态调度,在线程间动态调度
guided:动态分配块大小和num_iterations_remain/num_threads成正比
runtime:运行时确定,最后使用以上三种之一
auto:由编译器或者运行时系统决定调度类型
ordered子句和nowait子句
- ordered[ (n) ]:指定区域的循环迭代将按串行顺序执行,只能用在for或parallel for中
- nowait:忽略并行区域隐含barrier的同步等待
collapse子句
collapse(n):指定嵌套循环中的n个循环折叠到一个大的迭代空间中,同时线程化接下来的n层循环
使用collapse子句时要保证循环之间没有数据依赖关系
负载不够的问题是指每个线程的计算量比较小,导致线程的计算时间相比线程的建立、销毁时间不够长,从而影响程序的效率
使用限制
- 对于所有线程,循环控制参数(i++)必须相同
- 跳转或跳出循环是非法的
- schedule、ordered和collapse子句只可以出现一次
section指令
#pragma omp section
structured-block
- 1
- 2
sections指令指定所包含的代码段被分配给各个线程执行,不同section部分可以由同一个 / 不同线程执行
使用限制
- sections指令的末尾有隐含的barrier,可以使用nowait子句忽略
- 不能跳转或跳出section代码块
single指令
#pragma omp single
structured-block
- 1
- 2
single指令指定所包含的代码仅由一个线程执行,通常用于处理非线程安全的代码段,例如I/O
合并结构
parallel for指令 / parallel sections指令
除了nowait子句外,所有parallel和for / section适用的子句和规范也都适用
线程间互斥访问和同步的指令
-
master指令:指定一个代码区域由主线程执行,其他线程跳过这个区域;
没有barrier,不能跳转跳出
-
critical指令:指定一个代码区域每次只能由一个线程执行(互斥访问),可以实现临界区访问;name是可选项,使不同的cirtical区域共存
-
barrier指令:指定线程组所有的线程在此指令处同步
-
atomic指令:指定以原子方式访问特定的存储位置,该指令仅适用于其后的单个语句,可以实现一个最小临界区的访问;#pragma omp atomic [atomic-clause],参数可以是read,write,update,capture
-
flush指令:标识一个数据同步点,将线程的变量写回内存,实现内存数据更新,nowait子句使flush失效
-
ordered指令:指定循环迭代以串行执行顺序执行,只能出现在for或者parallel for的动态范围内
运行时库函数
| 函数 | 功能 |
|---|---|
| void omp_set_num_threads(int num_threads) | 设置下一个并行区域使用的线程数量 |
| int omp_get_num_threads(void) | 返回当前并行区域线程组中的线程数量 |
| int omp_get_max_threads(void) | 返回可通过调用omp_get_num_threads函数返回的最大值 |
| int omp_get_thread_num(void) | 返回在线程组中执行此处代码的线程号 |
| int omp_get_num_procs(void) | 返回程序可用的处理器数量 |
| void omp_set_dynamic(int dynamic_threads) | 启动或禁用线程数的动态线程调整 |
| int omp_get_dynamic(void) | 用于确定是否启动动态线程调整 |
| void omp_set_schedule(omp_sched_t kind, int chunk_size) | 在指令中将“runtime”作为调度类型时,设置循环调度类型 |
| void omp_get_schedule( omp_sched_t *kind, int *chunk_size) | 在指令中将“runtime”作为调度类型时,返回循环调度类型 |
| void omp_init_lock(omp_lock_t *lock); | 初始化锁 |
| void omp_destroy_lock(omp_lock_t *lock) | 结束锁变量与锁的绑定 |
| void omp_set_lock(omp_lock_t *lock) | 获得锁的所有权 |
| void omp_unset_lock(omp_lock_t *lock) | 释放锁 |
| double omp_get_wtime(void) | 返回一个程序点的时间值(s) |
| double omp_get_wtick(void) | 返回一个程序点的时钟周期的时长(s) |
常见环境变量
OMP_SCHEDULE:只适用于for和parallel for指令的schedule子句设置为runtime时,决定如何在处理器是调度循环迭代:
OMP_NUM_THREADS:设置执行期间使用的最大线程数
OMP_DYNAMIC:启动(true)或禁用(false)线程数的动态调整
OpenMP并行编程实例
奇偶排序
- parallel for实现:fork-join2次(判断i是否为偶数)
for (i = 0; i < n; i++) {
if (i % 2 == 0) {
#pragma omp parallel for
for (j = 1; j < n; j += 2) {
if (a[j-1] > a[j]) {
temp = a[j];
a[j] = a[j-1];
a[j-1] = temp;
}
}
}
else {
#pragma omp parallel for
for (j = 1; j < n-1; j += 2) {
if (a[j] > a[j+1]) {
temp = a[j];
a[j] = a[j+1];
a[j+1] = temp;
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
-
parallel和for实现
略
生产者-消费者
我的作业里是这么写的:(错的真离谱 小崩溃)
#pragma omp parallel num_threads(2 * n) // 创建2n个线程,并进入并行区域。
{
#pragma omp for nowait schedule(static, 1) ordered
for (int i = 0; i < n; i++) {
#pragma omp ordered
{
printf("线程%d是生产者,负责读取文件%s\n", omp_get_thread_num(), filenames[i]);
produce(filenames[i]);
}
}
#pragma omp for nowait schedule(static, 1) ordered
for (int i = 0; i < n; i++) {
#pragma omp ordered
{
printf("线程%d是消费者\n", omp_get_thread_num());
consume();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
需要:共享队列、出队操作、入队操作(单位是一行文本)、互斥锁,每次生产消费者都调用
生产者函数打开文件,每插入一句文本就要加锁解锁;消费者函数每取一个文本行就要加锁解锁,一直到队列为空,然后输出单词
加锁解锁可以用**#pragma omp critical**代替
MPI(Message-Passing Interface,MPI)
分布式内存系统,不同于OpenMP的共享内存,进程间采用显式的消息传递进行通信:一个进程调用消息发送函数,另一个进程调用消息接收函数
是一个消息传递接口标准
基本函数
int MPI_Init( int *argc, char * * * argv ) //初始化
int MPI_Finalize(void) //退出MPI环境
int MPI_Comm_rank(MPI_Comm comm, int *rank)//获取进程的编号
int MPI_Comm_size(MPI_Comm comm, int *size)//获取指定通信域的进程个数
int MPI_Send(void *buf, int count, MPI_Datatype dataytpe, int dest, int tag, MPI_Comm comm) //消息发送
int MPI_Recv(void *buf, int count, MPI_Datatype datatyepe,int source, int tag, MPI_Comm comm, MPI_Status *status)//消息接收
- 1
- 2
- 3
- 4
- 5
- 6
MPI消息
消息缓冲(消息的内容 )由三元组**<起始地址,数据个数,数据类型>**标识
消息信封由三元组**<源/目标进程,消息标签,通信域>**标识

数据类型
消息类型:预定义 / 派生数据类型(Derived Data Type)
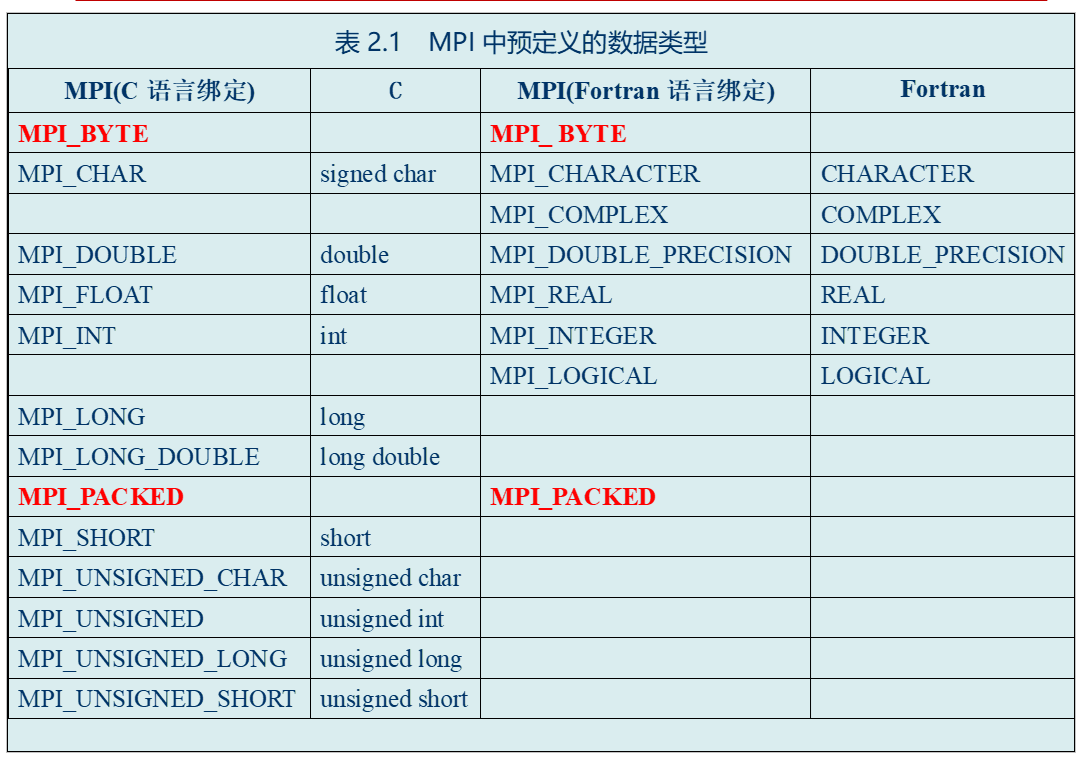
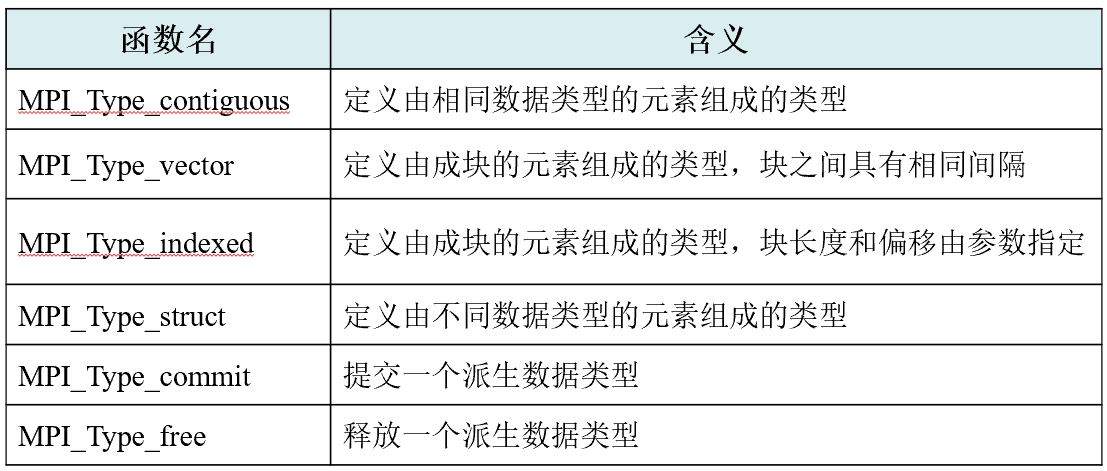
MPI_PACKED:预定义数据类型被用来实现打包传输地址空间不连续的数据项

MPI_Type_vector:构造函数
MPI_Type_vector(count, blocklength, stride, oldtype, &newtype)
连续数据块,每块长度,每两块之间的跨度,每一小块数据类型,&newtype
消息标签
区分相同类型消息,使得服务进程可以对两个不同的用户进程分别处理
通信域
包括进程组和通信上下文,用于描述通信进程间的通信关系。
组内通信域 / 组间通信域
通信上下文:安全的区别不同的通信以免相互干扰,不是显式的对象,只作为通信域的一部分出现
dup后创建新的通信域,与原通信域包含相同进程组但通信上下文不同
split的第二个参数Color是划分标准,第三个参数Key是划分后的进程编号
组间通信域函数:
消息状态
MPI_Status *status,MPI_Recv的最后一个参数
消息的源进程标识--MPI_SOURCE;消息标签--MPI_TAG;错误状态--MPI_ERROR;其他--包括数据项个数等,但多为系统保留的。
点对点通信
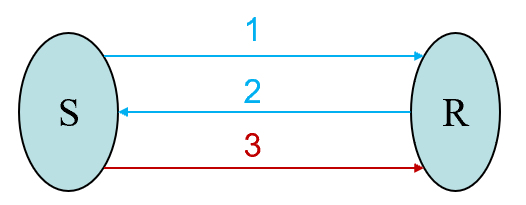
同步 / 缓冲 / 标准 / 就绪
-
同步:启动接收,发送才正确返回
-
缓冲:发送不管接收操作是否已经启动都可以执行,缓冲区用MPI_Buffer_attch实现,用MPI_Buffer_detach回收
-
标准:由MPI决定是否缓冲(可以是同步 / 缓冲)
-
就绪:发送在接收操作开始才发送,比同步少一步2传
阻塞 / 非阻塞:在于返回后的资源可用性
- 阻塞通信返回:通信操作已完成;调用的缓冲区可用
- 非阻塞通信返回:MPI_Wait函数和MPI_Test函数(对通信完成的检测)
MPI发送支持4*2=8种操作,接收只有阻塞和非阻塞
非阻塞通信解决阻塞通信的资源浪费:重叠计算与通信
send_handle和revc_handle分别用于检查发送接收是否完成(Irevc等函数的参数之一),MPI_Wait直到handle指示操作完成才返回,MPI_Test只是测试,不会被阻塞,只是可能返回的值不太一样(ovo
MPI_Sendrecv(
sendbuf, sendcount, sendtype, dest, sendtag,
//以上为消息发送的描述
recvbuf, recvcount, recvtype, source, recvtag,
// 以上为消息接收的描述
comm, status)
给一个进程发送消息,从另一个进程接收消息
集合通信
进程组中所有进程都参加。实现三个功能:通信、聚集和同步
没有消息标签参数
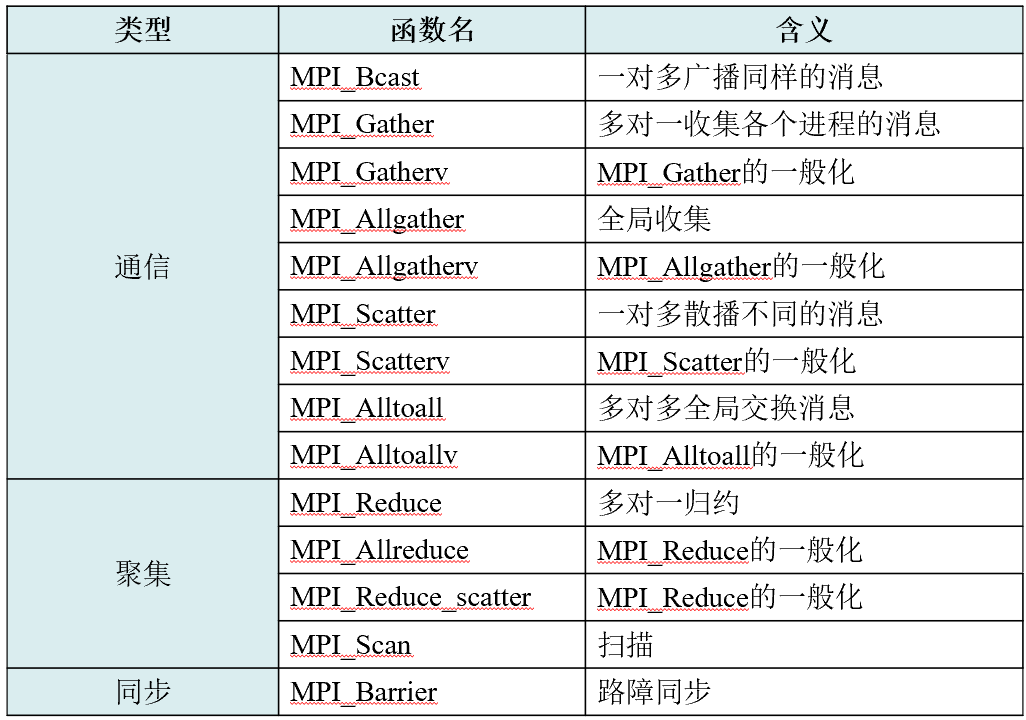
广播(一对多)
MPI_Bcast(Address, Count, Datatype, Root, Comm)
由Root发送,Address定义发送缓冲和接收缓冲
收集(多对一)
MPI_Gather(SendAddress, SendCount, SendDatatype, RecvAddress, RecvCount, RecvDatatype, Root, Comm)
Root从Comm的所有进程(包括自己)接收消息,接收到的消息按进程标识rank排序并拼接,放在root的接收缓冲中。
散播(一对多)
MPI_Scatter(SendAddress, SendCount, SendDatatype, RecvAddress, RecvCount, RecvDatatype, Root, Comm)
与Gather相反,在root发送缓冲中存放n个不同的消息
作业2中把数组打散发送的MPI_Scatter:
MPI_Scatter(arr, local_n, MPI_INT, local_arr, local_n, MPI_INT, 0, MPI_COMM_WORLD);
非Root进程忽略发送缓冲
全局收集&全局交换(多对多)
MPI_Allgather(SendAddress, SendCount, SendDatatype, RecvAddress, RecvCount, RecvDatatype, Comm)(没有Root参数)
每个进程都作为Root进程执行了一次Gather调用
MPI_Alltoall(SendAddress, SendCount, SendDatatype, RecvAddress, RecvCount, RecvDatatype, Comm)
这很难说。就大概是这样,你发的和收的数据量一定要是一样的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HFhXPqtO-1687001074067)(C:\Users\59980\AppData\Roaming\Typora\typora-user-images\image-20230615172006612.png)]
(原来是[0,0,0,0] [1,1,1,1] [2,2,2,2] [3,3,3,3])
路障
MPI_Barrier(Comm)
调用返回后可以保证组内所有进程已经把之前的操作都执行完了。
聚合操作:归约和扫描
归约
MPI_Reduce(SendAddress, RecvAddress, Count, Datatype, Op, Root, Comm) Op是归约操作,可以是预定义或者自定义的,可以提供向量值(长度Count)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iHRMhqwM-1687001074068)(C:\Users\59980\AppData\Roaming\Typora\typora-user-images\image-20230615172435484.png)]
| 操作 | 含义 | 操作 | 含义 |
|---|---|---|---|
| MPI_MAX | 最大值 | MPI_LOR | 逻辑或 |
| MPI_MIN | 最小值 | MPI_BOR | 按位或 |
| MPI_SUM | 求和 | MPI_LXOR | 逻辑异或 |
| MPI_PROD | 求积 | MPI_BXOR | 按位异或 |
| MPI_LAND | 逻辑与 | MPI_MAXLOC | 最大值且相应位置 |
| MPI_BAND | 按位与 | MPI_MINLOC | 最小值且相应位置 |
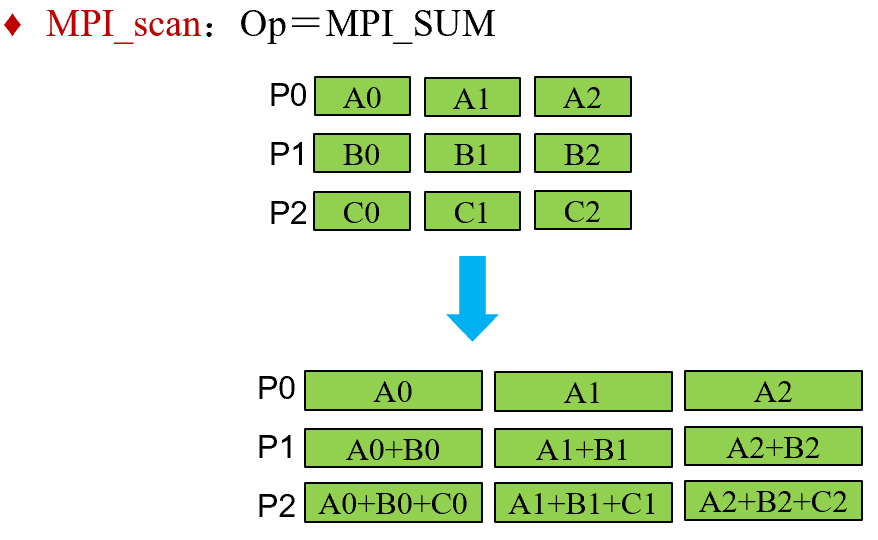
扫描
MPI_scan(SendAddress, RecvAddress, Count, Datatype, Op, Comm)
特殊的归约,每一个进程都对排在它前面的进程(0…i)进行归约操作。
MPI并行编程实例
梯形积分法
感觉思路和我本人差不多,具体代码还是要好好琢磨琢磨,我也prefer用集合通信替代点对点通信
#include <stdio.h>
#include <string.h>
#include <mpi.h>
double Trap(double left_endpt,double right_endpt,int trap_count,double base_len);
double func(double x); // f(x) = 2x +10
int main(void)
{
int my_rank,comm_sz,n = 1024, local_n;
double a = 0.0, b = 3.0, h, local_a, local_b, local_int, total_int;
int source;
MPI_Init(NULL,NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
h = (b - a) / n;
local_n = n / comm_sz;
local_a = a + my_rank * local_n * h;
local_b = local_a + local_n * h;
local_int = Trap(local_a,local_b,local_n,h);
//归约所有线程的total_int到0号线程的local_int
MPI_Reduce(&local_int,&total_int,1,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_WORLD);
if(my_rank == 0){
printf("With n = %d trapezoids, our extimate\n",n);
printf("of the integral from %f to %f = %.15e\n",a,b,total_int);
}
MPI_Finalize();
return 0;
}
//具体计算a到b面积的函数
double Trap(double left_endpt,double right_endpt,int trap_count,double base_len)
{
double estimate,x;
int i;
estimate = (func(left_endpt) + func(right_endpt)) / 2.0;
for(i = 1;i < trap_count -1 ;i++){
x = left_endpt + i *base_len;
estimate += func(x);
}
estimate = estimate * base_len;
return estimate;
}
//f(x)的函数
double func(double x) // f(x) = 2x +10
{
return 2 * x + 10.0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
奇偶排序
PPT伪代码:
Sort local keys;
for (phase = 0; phase < comm_sz; phase++) {
partner = Compute_partner(phase, my_rank); if (I’m not idle) {
- 1
- 2
- 3
Send my keys to partner;
Receive keys from partner;
if (my_rank < partner)
Keep smaller keys;
else
Keep larger keys;}
}
MPI树形搜索问题
TSP旅行商问题
访问每个城市仅一次,并且回到出发的城市。
非递归的DFS
伪代码如下:
Push_copy(stack, tour);/*初始tour只有一个城市*/
while (!Empty(stack)) {
curr_tour = Pop(stack);
if (City_count(curr_tour) == n) {//测试单个回路是否结束
if (Best_tour(curr_tour))
Update_best_tour(curr_tour);//更新开销最小的回路
}else {
for (nbr = n-1; nbr >= 1; nbr--)
if (Feasible(curr_tour, nbr)){
Add_city(curr_tour, nbr);
Push_copy(stack, curr_tour);
Remove_last_city(curr_tour);
}
}
Free_tour(curr_tour);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
静态划分树
大致逻辑:线程0BFS搜索树,直到回路数量至少为comm_sz,然后MPI_Scatterv给线程组;每个线程发现一个新的最佳回路就MPI_Bsend给其他进程(Why);目的进程可以周期性地检查新的最佳回路代价的到达——让每个进程存储自己的局部最佳回路,在所有进程完成搜索后都调用MPI_Allreduce ,拥有全局最佳回路的进程才可以把它发送给进程。(没懂)
–关闭MPI 前,可以调用MPI_Iprobe 尝试接收那些未被接收的消息
动态划分树
解决静态划分可能存在的负载不均衡的问题
在计算的过程中动态分配,当一个进程完成任务后,它进入忙等待,等待接收更多的工作或者接收到程序终止的信号;一个有任务可做的进程可以划分它的栈,把自己的工作分配给一个空闲进程
为了分配这个栈,首先要测试一下自己能不能分走栈;分离栈函数Split_stack由Fulfill_request函数调用,会打包新栈的内容发给接收者;接收者解包;没有适合分配的工作时用Send_rejects拒绝
((我趣什么是分布式中止检测,不看了跳过了
Terminate函数判断进程是否终止,此时会拒绝其他请求任务消息
CUDA(Compute Unified Device Architecture)
最后随便看看吧,,夹人们。
基于并行计算架构的CUDA是一种将GPU作为计算设备的软硬件体系
典型CUDA程序执行流程
-
分配host内存,并进行数据初始化;
-
分配device内存,并从host将数据拷贝到device上;
-
调用CUDA的内核函数在device上完成指定的运算;
-
将device上的运算结果拷贝到host上;
-
释放device和host上分配的内存。
两层并行模型:
网格中线程块间并行、线程块中线程并行
使用nvcc编译器
内核函数
- 在不同线程中同时执行,有线程ID,只能在host端代码调用
- 通过_global_函数执行空间限定符定义
//kernel定义
_global_ void VecAdd(float *A, float *B, float *C){
int i=threadIdx.x;
C[i]=A[i]+B[i];
}
int main()
{
//kernel调用
VecAdd<<<1,N>>>(A,B,C);//VecAdd<<<grid,block>>>(A,B,C)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
内置坐标变量blockIdx(线程在grid中的位置)和threadIdx(线程在block中的位置)为Uint3类型
设备中的空间管理与数据传输
主机和设备拥有各自独立的存储空间
kernel中用到的数组或变量必须在CUDA程序执行前分配足够的内存空间;kernel执行完需要及时释放空间
设备中开辟/释放空间:
cudaMalloc(void pointer, size_t size)**
cudaFree(pointer)
数据传输:
cudaMemcpy(dst,src,size,type)//复制目的地址指针,复制源地址指针,数据大小,涉及存储器类型(有4种)
线程结构 grid→block→thread
一个kernel启动的所有线程形成一个grid(线程网格),grid由一组block(线程块)构成
每个block由一组线程组成(一般是32的倍数),block间不能通信且并行执行;同一block内线程间共享内存可以通信。
对一张30*37的图片进行处理,使图片中每个像素点的值扩大2倍。分析得出,假设采用8*8的线程块,那么需要4*5=20个线程块。
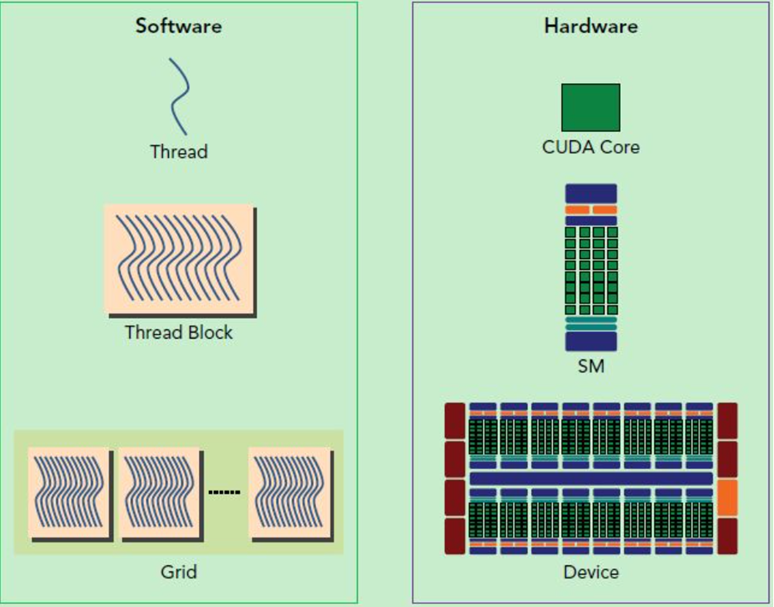
硬件映射
Thread在SP(Streaming processor,thread运行的基本单位)也就是CUDA Core上执行
一个线程块的thread只能在一个SM(Streaming Multiprocessor)上调度
SM上可以同时执行多个Block,这些Block可以来自不同的kernel函数
Warp(线程束)
GPU的基本执行单元,大小一般为32
存储器类型
每个thread拥有自己的寄存器和局部存储器;每个block拥有共享存储器
grid中所有的线程都可以访问同一个全局存储器
Constant常数存储器和Texture纹理存储器是只读存储器,可以被所有线程访问
全局存储器、常数存储器、纹理存储器中的值在一个kernel函数执行完后可以继续保持,可以被同一个程序中的其他kernel函数调用
寄存器是GPU片上的高速缓存器,每个SM都有32位的寄存器组。
局部存储器:片外,访问慢;共享存储器:片内,访问快
共享内存上的变量通过**_shared_**修饰符定义
全局存储器可分配释放内存、_device_关键词
常数存储器(有缓存机制,访问比全局存储器快)上的变量通过**_constant_**关键词定义
纹理存储器
一种当数据的访问具有特定的模式的时候能够加速程序执行,并减少显存带宽的只读存储器
“纹理引用”texture<>
texture <float, 1, cudaReadModeElementType> textureRef;//在纹理内存里定义的纹理变量(。
- 1
cudaArray类似于普通的数组,是纹理专用数组,kernel函数只能读取
cudaBindTextureToArray()将纹理引用和CUDA数组进行绑定
通信机制
Block内通信:
同一个block中的线程通过共享存储器交换数据,并通过barrier同步保证线程间能够正确地共享数据
同步函数:
**__syncthreads():**只有当整个线程块都走向相同分支时,才能在条件语句中使用syncthreads()
Memory fence函数:_threadfence_block(),__threadfence()
cudaThreadSynchronize():用于GPU与CPU线程同步,主机端确认所有device端线程已结束

