
- 1文盲的Python入门日记:第二十八天,封装一个自定义爬虫类,用来执行日常的采集(二)_可自定义采集规则的爬虫
- 2从零到阿里的三年_java架构师-十项能力修炼
- 3React,antd-Form自定义正则校验_在react中如何写正则
- 4AI多模态教程:Mini-InternVL1.5多模态大模型实践指南_多模态 渐进式 高质量 噪声 编码器 internvl1.5
- 5pynput实现自动化_python pynput库
- 6px4固件源码分析(文件夹作用以及总体架构)_px4程序分析
- 7智能体入门-智谱清言_智谱清言 智能体 只回答知识库存
- 8QML动画和过度_default animation as behaviors
- 9华为云AI加速型(昇腾Ascend310)Ubuntu18.04系统下使用msame模型推理工具
- 10Python 报错 ImportError: cannot import name xxx from partially initialized module xxx_importerror: cannot import name 'yolo' from partia
四、深度学习计算机视觉算法的优化_计算机视觉算法调优方法有哪些
赞
踩
深度学习计算机视觉算法的优化
1、过拟合问题
1.1衡量模型的表现
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ehTve9Ea-1645866869178)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220225212405562.png)]](https://img-blog.csdnimg.cn/ea3fb821709f4645baf40667c3573481.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAd2VpeGluXzQ1NDA4ODcz,size_9,color_FFFFFF,t_70,g_se,x_16)
只使用Accuracy的不足:
- 如果正品99个,次品1个,而分类器把所有样本都预测为正品,Accuracy也能获得99%的准确率,但是却没有检测出次品。
- 当不同类别的样本比例非常不均衡时。占比大的类别往往成为影响准确率的最主要因素。
应当将以下三个公式结合使用:
Accuracy = (TP+TN)/(TP+FP+FN+TN)
Precision = TP/(TP+FP)
Recall = TP/(TP+FN)
1.2过拟合问题优化
-
过拟合问题是指过于完美拟合了训练集数据,而对新的样本失去了一般性,不能有效预测新样本,这个问题也叫做高方差(high variances)。
-
如图所示,真实曲线是绿色的直线。但是训练结果却是红色曲线将点分成了两类,并且准确率还达到了100%。这是因为受到了噪声点(黄色圈起来的)的影响。

过拟合原因
- 数据量太小
这个是很容易产生过拟合的一个原因。设想,我们有一组数据很好的吻合3次函数的规律,现在我们局部的拿出了很小一部分数据,用机器学习或者深度学习拟合出来的模型很大的可能性就是一个线性函数,在把这个线性函数用在测试集上,效果可想而知肯定很差了。
- 训练集和验证集分布不一致
训练集训练出一个适合训练集那样分布的数据集,当你把模型运用到一个不一样分布的数据集上,效果肯定大打折扣。这个是显而易见的。
- 模型复杂度太大
在选择模型算法的时候,首先就选定了一个复杂度很高的模型,然后数据的规律是很简单的,复杂的模型反而就不适用了。
- 数据质量很差
数据还有很多噪声,模型在学习的时候,肯定也会把噪声规律学习到,从而减小了具有一般性的规律。这个时候模型用来预测肯定效果也不好。
- 过度训练
这个是同第4个是相联系的,只要训练时间足够长,那么模型肯定就会吧一些噪声隐含的规律学习到,这个时候降低模型的性能是显而易见的。
优化方法
1.2.1训练验证集划分/交叉验证
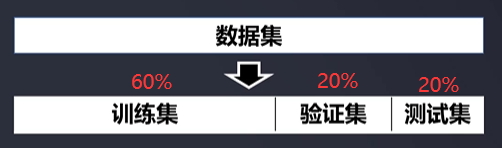
训练验证集划分
- 将数据集分为训练集、验证集、测试集。根据验证集的表现来优化模型,最终在测试集上看模型最终的表现。有时验证集和测试集也可以合二为一。
- 大部分会按60%、20%、20%随机划分
**交叉验证 **
把数据集切成等比例的几份,每个时间段用不同的数据进行验证,其余部分用于训练。这样所有的数据既当过验证数据,又当过训练数据。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jZ8OlEaR-1645866869183)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220225221108705.png)]](https://img-blog.csdnimg.cn/ecf97170e9d74d44a9568c675f8d6a1c.png)
1.2.2扩大数据集和代表性/数据增强Data augmentation

1.2.3正则化Regularization
从下图中的线性回归和逻辑回归的拟合曲线上我们可以发现,高阶项(函数复杂度)越多就会对数据的拟合能力越强,特征数目越多对数据的拟合能力越强。



正则化思路:
-
保留所有特征,但减少参数θj
-
当特征很多,但很多对于预测贡献量仅一点点时,工作的很好
用损失函数来解释:

从上图中,我们可以看到左面的曲线高阶项没有右边高阶项次数高,明显右侧有点过拟合了,但是这时候我们不想丢弃特征,那么我们对高阶项施以惩罚,使得θ3,θ4 非常小,用一个有惩罚的高阶项(可能高阶项不同程度的减小),来达到保留了高阶项(特征)又避免过拟合的基础上,又不至于因为丧失某些特征之后出现欠拟合。
如果我们想高阶项系数尽可能的小,那么就给一个很大的常数,如1000,如果高阶项系数很大那么整个loss就会很大。那么上面式子在梯度下降的过程中就会使得高阶项系数不断的减小。这时候比较小的高阶项系数就会使得高阶项起作用的影响变小,就会一定程度解决过拟合的问题。

上图中第二个粉色的项就是把所有的需要的起作用的参数 θ 都考虑进来,并对他们进行惩罚 。粉丝中括号中的前一项代表的是数据拟合程度,后一项表示模型复杂度。

讨论 λ :

所以我们可以看出来 λ 实际就是惩罚的程度,λ 越大 θ 的作用程度越低,拟合程度越低,模型复杂度越低; λ 越小 θ 起作用的程度越大,拟合程度越高,模型复杂度越大。例如:

假如上图 λ 非常大,那么为了保证带 λ 一项足够小就会使得所有惩罚的系数都会很小接近于 0,这时候拟合曲线就是一条直线,明显是欠拟合。同理,反之过拟合。
L(Y,f(x))=||Y-f(x)||2+α||w||2,下标指的是范数
L0范数:向量中非零元素的个数,记为||W||0
L1范数:绝对值之和,记为||W||1
L2范数:平方和或者说模,记为||w||2
1.2.4随机失活Dropout
Dropout的意义在于,减小了不同神经元的依赖度。有些中间输出,在给定的训练集上,可能发生只依赖某些神经元的情况,这就会造成对训练集的过拟合。而随机关掉一些神经元,可以让更多神经元参与到最终的输出当中。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vEaJd6wP-1645866869187)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220226105113191.png)]](https://img-blog.csdnimg.cn/6b07b40a71ee4d80a6ceba61e7fa8c60.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAd2VpeGluXzQ1NDA4ODcz,size_20,color_FFFFFF,t_70,g_se,x_16)
2、梯度消失/爆炸问题
梯度消失和梯度爆炸的本质都是因为神经网络的层数太深。
优化方法 :
- 残差神经网络连接方式
- 非饱和的激活函数(如 ReLU)
- 梯度截断(Gradient Clipping)
- 好的参数初始化方式
- 批量规范化(Batch Normalization)
- 更快的优化器
- LSTM
2.1非饱和的激活函数(ReLU)与梯度截断(Gradient Clipping)
非饱和的激活函数:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TCRkgvx6-1645866869188)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220226133453700.png)]](https://img-blog.csdnimg.cn/026f4e0f18104cc884af4c64af01dbcf.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAd2VpeGluXzQ1NDA4ODcz,size_20,color_FFFFFF,t_70,g_se,x_16)
梯度截断:
T
0
(
v
i
,
θ
)
=
{
0
,
if
∣
v
i
∣
≤
θ
v
i
,
otherwise
T_0(v_i,θ)= {0,if |vi|≤θvi,otherwise
T0(vi,θ)={0,vi,if ∣vi∣≤θotherwise
2.2网络参数的初始化
初始化的方法:
-
所有的参数初始化为0或者相同的常数
全0初始化最为简单,但不适合采用。因为如果将神经网络中参数全部初始化为0,那么每个神经元就会计算出相同的结果,在反向传播的时候也会计算出相同的梯度 ,最后导致所有权重都会有相同的更新。换句话说,如果每个权重都被初始化成相同的值,那么权重之间失去了不对称性。
-
随机初始化
我们希望权重初始化的时候能够尽量靠近0,但是不能全都等于0 ,所以可以初始化权重为一些靠近0的随机数,通过这个方式可以打破对称性。这里面的核心想法就是神经元最开始都是随机的、唯一的,所以在更新的时候也是作为独立的部分,最后一起合成在神经网络当中。
一般的随机化策略有高斯随机化 、均匀随机化等,需要注意的是并不是越小的随机化产生的结果越好,因为权重初始化越小,反向传播中关于权重的梯度也越小,因为梯度与参数的大小是成比例的,所以这会极大地减弱梯度流的信号,容易导致梯度消失问题。 -
Xavier初始化
W ∼ U [ − 6 n j + n j + 1 , 6 n j + n j + 1 ] W\sim U[-\frac{\sqrt6}{\sqrt{n_j+n_{j+1}}},\frac{\sqrt6}{\sqrt{n_j+n_{j+1}}}] W∼U[−nj+nj+1 6 ,nj+nj+1 6 ]
-
条件:正向传播时,激活值的方差保持不变;反向传播时,关于状态值的梯度的方差保持不变。
-
假设激活函数关于0对称,且主要针对于全连接神经网络。适用于tanh和softsign
-
-
He初始化
-
条件:正向传播时,状态值的方差保持不变;反向传播时,关于激活值的梯度的方差保持不变。
-
适用于ReLU的初始化方法:
W ∼ N [ 0 , 2 n ^ i ] W∼N[0, \sqrt{\frac{2}{\hat{n}_i}}] W∼N[0,n^i2 ] -
适用于Leaky ReLU的初始化方法:
W ∼ N [ 0 , 2 ( 1 + a 2 ) n ^ i ] W\sim N[0,\sqrt{\frac{2}{(1+a^2)\hat{n}_i}}] W∼N[0,(1+a2)n^i2 ]n ^ i = h i ∗ w i ∗ d i \hat{n}_i=h_i*w_i*d_i n^i=hi∗wi∗di
其中,hi、wi分别表示卷积层中卷积核的高和宽,而di是当前层卷积核的个数
-
-
Pre-train初始化(迁移学习)
就是指之前被训练好的Model, 比如很大很耗时间的model, 你又不想从头training一遍。这时候可以直接download别人训练好的model进行微调
2.3批量规范化
对深层神经网络来说,即使输入数据已做标准化,训练中模型参数的更新依然很容易造成靠近输出层输出的剧烈变化。这种计算数值的不稳定性通常令我们难以训练出有效的深度模型。
BN的提出正是为了应对深度模型训练的挑战。在模型训练时Batch Normalization利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使整个神经网络在各层的中间输出的数值更稳定。
BN层也是像全连接层,卷积层,池化层这些网络层一样,同样属于网络中的一层。
note:可以对某层做单独的normalization,看哪层效果最好
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ErBPgQys-1645866869189)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220226143317274.png)]](https://img-blog.csdnimg.cn/6c377b66449f41ee833028354ae662d7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAd2VpeGluXzQ1NDA4ODcz,size_6,color_FFFFFF,t_70,g_se,x_16)
3、训练的优化
3.1批训练
不是一次性把所有数据给模型进行训练,而是将训练数据切成很多batch,一个batch一个batch喂给模型。
好处:
-
提高训练速度
-
对训练过程引入随机性,帮助找到全局最优解
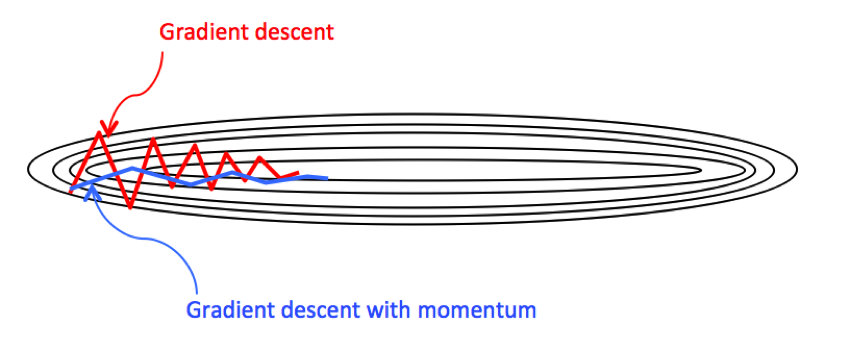
3.2动量梯度下降法优化器
gradient descent with momentum
-
通常情况我们在训练深度神经网络的时候把数据拆解成一小批一小批地进行训练,这就是我们常用的mini-batch SGD训练算法,然而虽然这种算法能够带来很好的训练速度,但是在到达最优点的时候并不能够总是真正到达最优点,而是在最优点附近徘徊。
-
另一个缺点就是这种算法需要我们挑选一个合适的学习率,当我们采用小的学习率的时候,会导致网络在训练的时候收敛太慢;当我们采用大的学习率的时候,会导致在训练过程中优化的幅度跳过函数的范围,也就是可能跳过最优点。我们所希望的仅仅是网络在优化的时候网络的损失函数有一个很好的收敛速度同时又不至于摆动幅度太大。
-
Momentum优化器刚好可以解决我们所面临的问题,它主要是基于梯度的移动指数加权平均。假设在当前的迭代步骤第 步中,那么基于Momentum优化算法可以写成下面的公式:
v d w = β v d w + ( 1 − β ) d W v d b = β v d b + ( 1 − β ) d b W = W − α v d w b = b − α v d b {v_{dw}} = \beta {v_{dw}} + (1 - \beta )dW\\ {v_{db}} = \beta {v_{db}} + (1 - \beta )db\\ W = W - \alpha {v_{dw}}\\ b = b - \alpha {v_{db}} vdw=βvdw+(1−β)dWvdb=βvdb+(1−β)dbW=W−αvdwb=b−αvdbdW和db分别是损失函数反向传播时候所求得的梯度,α是网络的学习率,β是梯度累积的一个指数,这里我们一般设置值为0.9,vdw和vdb分别是损失函数在前t−1轮迭代过程中累积的梯度梯度动量。
Momentum优化器的主要思想就是利用了类似与移动指数加权平均的方法来对网络的参数进行平滑处理的,让梯度的摆动幅度变得更小。
3.3RMSProp优化器
RMSProp算法的全称叫 Root Mean Square Prop,是Geoffrey E. Hinton在Coursera课程中提出的一种优化算法,在上面的Momentum优化算法中,虽然初步解决了优化中摆动幅度大的问题。所谓的摆动幅度就是在优化中经过更新之后参数的变化范围,如下图所示,蓝色的为Momentum优化算法所走的路线,绿色的为RMSProp优化算法所走的路线。

为了进一步优化损失函数在更新中存在摆动幅度过大的问题,并且进一步加快函数的收敛速度,RMSProp算法对权重 W 和偏置 b 的梯度使用了微分平方加权平均数。
其中,假设在第 t轮迭代过程中,各个公式如下所示:
s
d
w
=
β
s
d
w
+
(
1
−
β
)
d
W
2
s
d
b
=
β
s
d
b
+
(
1
−
β
)
d
b
2
W
=
W
−
α
d
W
s
d
w
+
ε
b
=
b
−
α
d
b
s
d
b
+
ε
{s_{dw}} = \beta {s_{dw}} + (1 - \beta )d{W^2}\\ {s_{db}} = \beta {s_{db}} + (1 - \beta )d{b^2}\\ W = W - \alpha \frac{{dW}}{{\sqrt {{s_{dw}}} + \varepsilon }}\\ b = b - \alpha \frac{{db}}{{\sqrt {{s_{db}}} + \varepsilon }}
sdw=βsdw+(1−β)dW2sdb=βsdb+(1−β)db2W=W−αsdw
+εdWb=b−αsdb
+εdb
算法的主要思想就用上面的公式表达完毕了。在上面的公式中 sdw和 sdb分别是损失函数在前 t−1轮迭代过程中累积的梯度动量, β是梯度累积的一个指数。所不同的是,RMSProp算法对梯度计算了微分平方加权平均数。这种做法有利于消除了摆动幅度大的方向,用来修正摆动幅度,使得各个维度的摆动幅度都较小。另一方面也使得网络函数收敛更快。(比如当dW 或者db 中有一个值比较大的时候,那么我们在更新权重或者偏置的时候除以它之前累积的梯度的平方根,这样就可以使得更新幅度变小)。为了防止分母为零,使用了一个很小的数值ϵ来进行平滑,一般取值为 10−8。
3.4Adam优化器
有了上面两种优化算法,一种可以使用类似于物理中的动量来累积梯度,另一种可以使得收敛速度更快同时使得波动的幅度更小。那么讲两种算法结合起来所取得的表现一定会更好。Adam(Adaptive Moment Estimation)算法是将Momentum算法和RMSProp算法结合起来使用的一种算法,我们所使用的参数基本和上面讲的一致,在训练的最开始我们需要初始化梯度的累积量和平方累积量。
v
d
w
=
0
,
v
d
b
=
0
;
s
d
w
=
0
,
s
d
b
=
0
{v_{dw}} = 0,{v_{db}} = 0;{s_{dw}} = 0,{s_{db}} = 0
vdw=0,vdb=0;sdw=0,sdb=0
假设在训练的第 t轮训练中,我们首先可以计算得到Momentum和RMSProp的参数更新:
v
d
w
=
β
1
v
d
w
+
(
1
−
β
1
)
d
W
v
d
b
=
β
1
v
d
b
+
(
1
−
β
1
)
d
b
s
d
w
=
β
2
s
d
w
+
(
1
−
β
2
)
d
W
2
s
d
b
=
β
2
s
d
b
+
(
1
−
β
2
)
d
b
2
{v_{dw}} = {\beta _1}{v_{dw}} + (1 - {\beta _1})dW\\ {v_{db}} = {\beta _1}{v_{db}} + (1 - {\beta _1})db\\ {s_{dw}} = {\beta _2}{s_{dw}} + (1 - {\beta _2})d{W^2}\\ {s_{db}} = {\beta _2}{s_{db}} + (1 - {\beta _2})d{b^2}
vdw=β1vdw+(1−β1)dWvdb=β1vdb+(1−β1)dbsdw=β2sdw+(1−β2)dW2sdb=β2sdb+(1−β2)db2
由于移动指数平均在迭代开始的初期会导致和开始的值有较大的差异,所以我们需要对上面求得的几个值做偏差修正。
v
d
w
c
=
v
d
w
1
−
β
1
t
v
d
b
c
=
v
d
b
1
−
β
1
t
s
d
w
c
=
s
d
w
1
−
β
2
t
s
d
b
c
=
s
d
b
1
−
β
2
t
v_{dw}^c = \frac{{{v_{dw}}}}{{1 - \beta _1^t}}\\ v_{db}^c = \frac{{{v_{db}}}}{{1 - \beta _1^t}}\\ s_{dw}^c = \frac{{{s_{dw}}}}{{1 - \beta _2^t}}\\ s_{db}^c = \frac{{{s_{db}}}}{{1 - \beta _2^t}}\\
vdwc=1−β1tvdwvdbc=1−β1tvdbsdwc=1−β2tsdwsdbc=1−β2tsdb
通过上面的公式,我们就可以求得在第 t轮迭代过程中,参数梯度累积量的修正值,从而接下来就可以根据Momentum和RMSProp算法的结合来对权重和偏置进行更新。
W
=
W
−
α
v
d
w
c
s
d
w
c
+
ε
b
=
b
−
α
v
d
b
c
s
d
b
c
+
ε
W = W - \alpha \frac{{v_{dw}^c}}{{\sqrt {s_{dw}^c} + \varepsilon }}\\ b = b - \alpha \frac{{v_{db}^c}}{{\sqrt {s_{db}^c} + \varepsilon }}
W=W−αsdwc
+εvdwcb=b−αsdbc
+εvdbc
上面的所有步骤就是Momentum算法和RMSProp算法结合起来从而形成Adam算法。在Adam算法中,参数 β1所对应的就是Momentum算法中的β值,一般取0.9,参数 β2所对应的就是RMSProp算法中的 β值,一般我们取0.999,而 ϵ 是一个平滑项,我们一般取值为 10−8,而学习率 α则需要我们在训练的时候进行微调。
4、其他优化策略
4.1贝叶斯极限

降低训练误差
- 更复杂的模型
- 更长时间的训练和优化
- 更优的超参数
降低验证/测试误差
- 更多更全面的数据
- 解决过拟合的策略
- 简化的模型结构/参数组合
4.2满足指标和优化指标


设置一个优化指标,其它为满足指标
4.3输出层的考量
- Linear
- Sigmoid
- Softmax
- One-hot-coding
4.4非对称数据训练和优化
-
数据增强扩大比例较低的样本的数量
比如99个良品、1个次品中可以扩大次品的样本数量
-
修改损失函数赋予比例较低样本更高的权重

