
- 1Kubernetes — Flannel CNI_flannel v0.11.0队员cni plugin版本
- 2数字人解决方案——LivePortrait实现表情姿态极速迁移
- 3马赛克与目标清除工具分享(lama-cleaner)
- 4Git常用命令show和status和config_git show
- 5国产AI之光!KIMI大模型详细使用入门指南(非常详细)零基础入门到精通,收藏这一篇就够了_kimi从零基础到精通
- 6Zookeeper+Dubbo集成基本准备环境搭建
- 7python ERA5 画水汽通量散度图地图:风速风向矢量图、叠加等高线、色彩分级、添加shp文件、添加位置点及备注_python绘制水汽通量图
- 8Spring Security6.x的登录验证_spring-security 6 配置userdetailsservice
- 945、SpringBoot文件上传到指定磁盘路径 及 上传成功后的文件回显_springboot上传文件到指定文件夹
- 10Redis 作为缓存服务器的配置
Python贝叶斯、transformer自注意力机制self-attention个性化推荐模型预测课程平台学生数据|代码分享...
赞
踩
全文链接:https://tecdat.cn/?p=37090
分析师:Kung Fu
近年来,在线课程凭借便捷的网络变得越来越流行。为了有更好的用户体验,在线课程平台想要给用户推荐他们所感兴趣的课程,以便增大点击率和用户黏性(点击文末“阅读原文”获取完整代码数据)。
相关视频
解决方案
任务/目标
根据学生所选的历史课程(查看文末了解数据、代码免费获取方式),预测出学生接下来可能选择的课程。
数据源准备
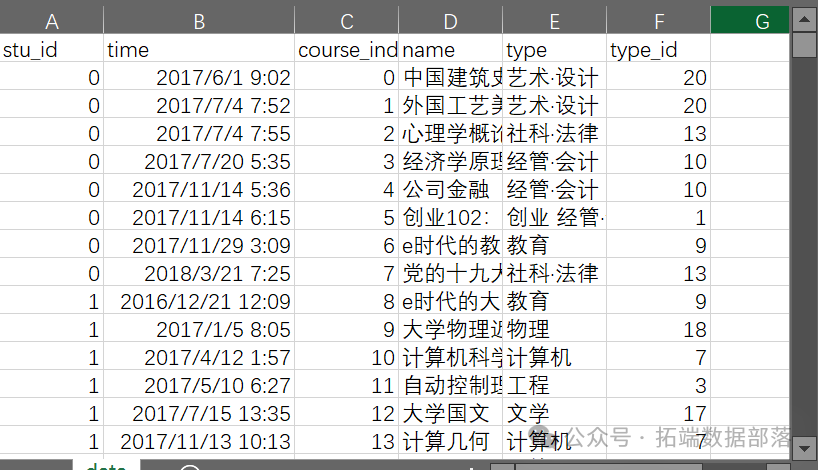
数据说明:
stu_id:学员证。
时间:学生首次报名相应课程的时间。
course_index:课程 ID。
名称:课程名称。
类型:课程的类型。
type_id:类型 id。
构造
这个是我所用到的数据集。在所给的数据特征中,我们需要用到的是学生的ID和课程的ID,每个学生所选的课已经按照时间顺序排列好了。
df = pd.read_csv("data.csv", encoding="gbk")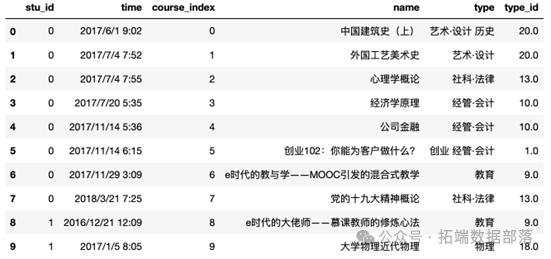
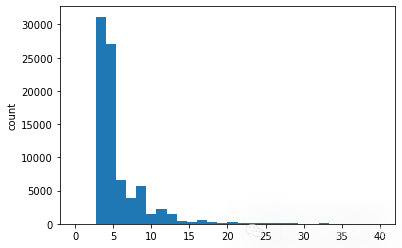
用户选择的课程的分布
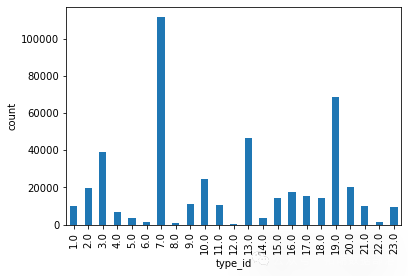
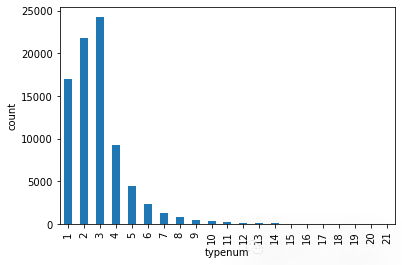
用户选择的类型的分布
- top_course = top_course.sort_values('choosen_times', ascending = False)
- top_course.head(20)
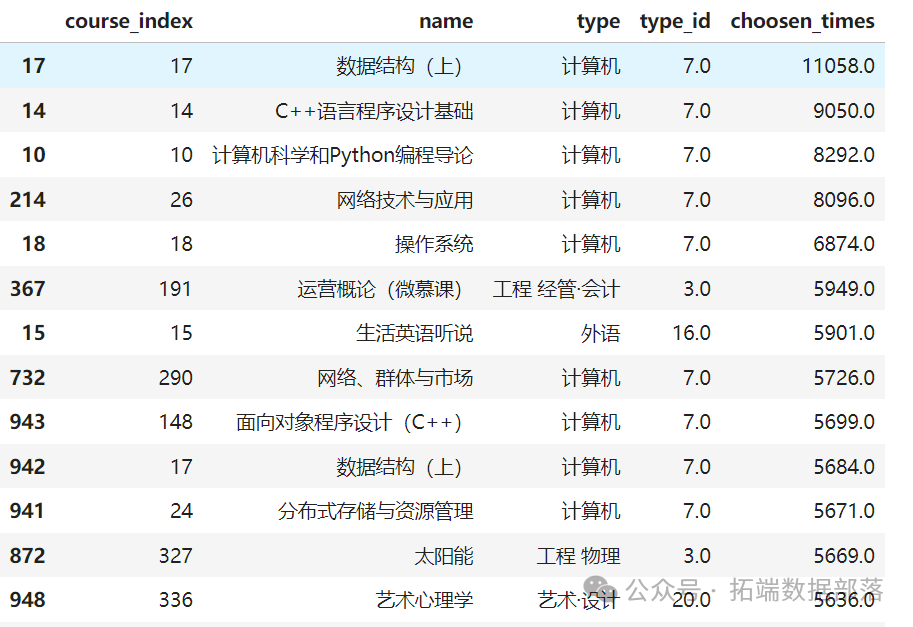
用户选择的类型的分布
划分训练集和测试集和评价指标
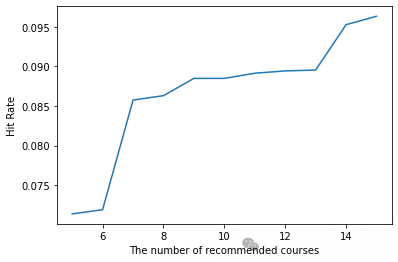
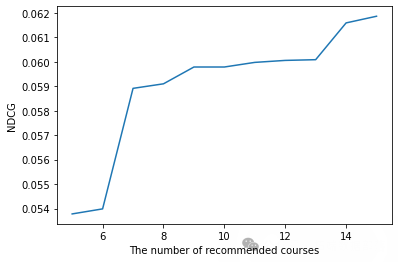
我们是这样划分训练集和测试集的,把每个学生选的最后一门课作为测试集,剩下的课程作为训练集。Hit rate@10(推荐10门课程的命中率)和NDCG@10(推荐10门课程的归一化折损累计增益)是我们对模型的评价指标。Hit rate是指训练集是否在推荐的10门课程里,NDCG则是更关注推荐的课程在10门课程当中的具体位置,越是靠前,NDCG越大。
建模
非个性化推荐模型
这个模型是我们的baseline,采用非个性化的方式,也就是说,所有学生会收到一样的课程推荐,在这里,推荐的课程是基于课程的受欢迎程度,我们挑选出最受欢迎的10门课推荐给所有学生。
计算并绘制命中率与推荐课程数量的关系
计算并绘制 NDCG 与推荐课程数量的关系
- plt.ylabel("NDCG")
- plt.show()
贝叶斯个性化排序推荐模型
在这个算法中,我们将任意学生所选的课进行标记,如果一个用户u在选择j课程之前选择了i课程,我们得到一个三元组<u,i,j>,说明u更喜欢i。如果对于用户u来说我们有m组这样的反馈,那么我们就可以得到m组用户u对应的训练样本。然后这个算法基于矩阵分解的方式得到用户对于不同课程的排序,选出前10名。
创建稀疏学生-课程交互矩阵
- def create_matrix(data, stu_col, courses_col, ratings_col):
- """
- creates the sparse student-course interaction matrix
- """
-
- for col in (courses_col, stu_col, ratings_col):
- data[col] = data[col].astype('category')
-
- ratings = csr_matrix((data[ratings_col],
- (data[stu_col].cat.codes, data[courses_col].cat.codes)))
- ratings.eliminate_zeros()
- return ratings, data
将日期拆分为训练集和测试集
通过删除每个学生的一些交互,将学生与课程交互矩阵拆分为训练集和测试集,并假装我们从未见过它们
构造 BPR 类
贝叶斯个性化排名(BPR)来源于个性化排名,为用户提供排名项目列表的项目推荐。排名项目列表是根据用户的隐式行为计算得出的。BPR 基于矩阵分解。所选课程可以看作是正数据集,而其余课程可以是负值和缺失值的混合体。通常,课程推荐人会输出个性化分数Xin和
- b站视频下载 ...
赞
踩
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

