
- 1【Python基础】Numpy使用指南_python中numpy模块使用
- 29.Symbol
- 3php7.4源码安装_configure: error: package requirements (libxml-2.0
- 4Oracle创建数据库(采用DBCA)_oracle dbca图
- 5云计算系列之阿里云OSS云存储实战解析
- 6百度文字转语音免费接口使用实例_百度文本转语音sdk
- 7Web API学习_web api 入门
- 8【golang项目-GeeCache】动手写分布式缓存 day1 - 实现LRU算法_go 实现分布式缓存
- 9kafka producer metrics
- 10基于TIA搭建西门子PLC仿真环境及通信方案
阿里开源语音大模型:SenseVoice 识别,语音识别效果和性能强于 Whisper,还能检测掌声、笑声、咳嗽等!
赞
踩
阿里开源语音大模型:语音识别效果和性能强于 Whisper,还能检测掌声、笑声、咳嗽等!
原创 kakuqo AI真好玩 2024年07月06日 10:21 福建
语音识别技术在人工智能(AI)领域扮演着至关重要的角色,它不仅是人机交互的基石,也是推动智能系统发展的关键驱动力。以下是语音识别在AI领域的一些主要作用:
-
改善用户体验:通过语音识别,用户可以与智能设备进行自然语言交流,无需手动输入,这极大地提升了用户体验的便捷性和直观性。
-
数据收集与分析:语音识别可以自动转录语音数据,为企业提供大量的自然语言数据,这些数据可用于市场研究、消费者行为分析等。
-
智能助手和虚拟助手:语音识别是智能助手(如 Siri、Google Assistant 等)的核心功能,允许用户通过语音指令获取信息、设置提醒或控制智能家居设备。
-
医疗和健康领域:在医疗领域,语音识别可以帮助医生在诊断过程中记录患者信息,减少手动输入的时间,同时也可以辅助听力受损的患者与医疗人员沟通。
-
教育和培训:语音识别技术可以用于语言学习和语音反馈,帮助学习者提高语言能力,同时也可以用于远程教育和在线课程。
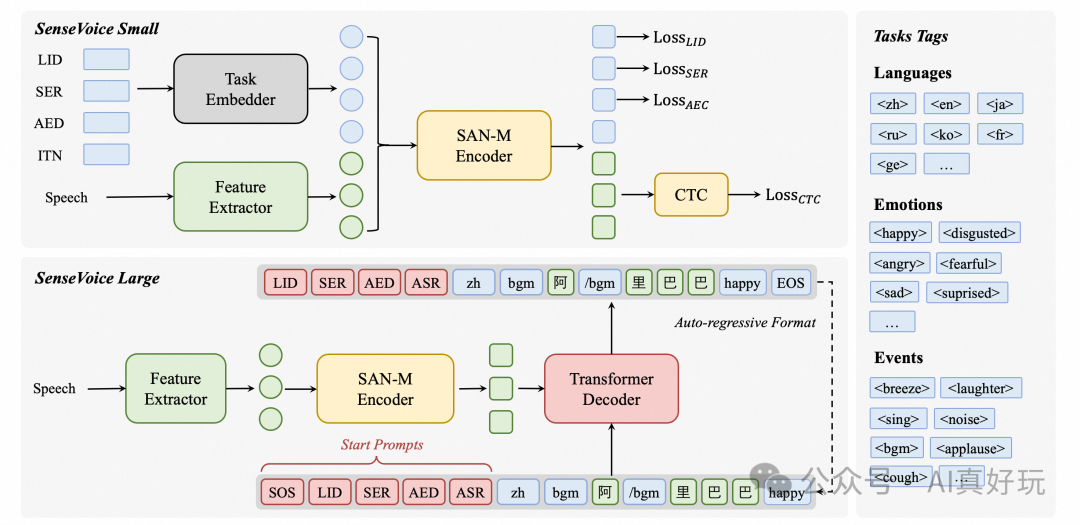
本文我将介绍 SenseVoice,它是由阿里开源的具有音频理解能力的音频基础模型,该模型拥有以下能力:
-
语音识别(ASR)
-
语种识别(LID)
-
语音情感识别(SER)
-
声学事件分类(AEC)
-
声学事件检测(AED)
近期热文
SenseVoice 主要功能
-
支持中、粤、英、日、韩语等 50 多种语言,识别效果优于 Whisper 模型。
-
情感识别技术在测试数据上的表现,超过了现有的最佳模型。
-
能够检测多种声音事件,包括音乐、掌声、笑声、哭声、咳嗽和喷嚏等常见的人机交互声音。
-
拥有完善的服务部署流程,能够处理多并发请求,并且支持多种客户端语言,包括 Python、C++、Java 和 C# 等。
-
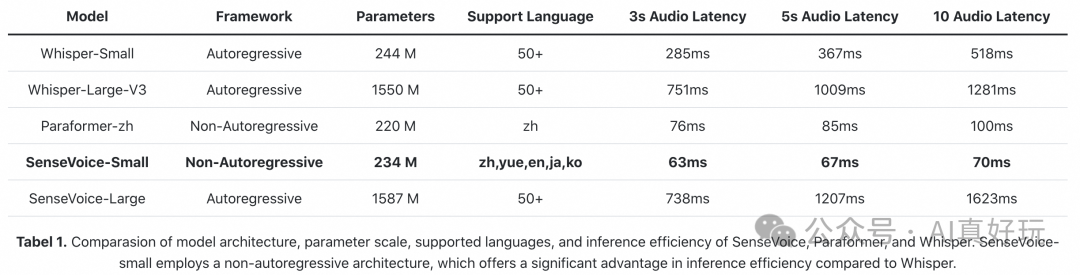
推理速度极快,10 秒音频的推理时间仅需 70 毫秒,性能是 Whisper-Large 的 15 倍。
SenseVoice 使用示例
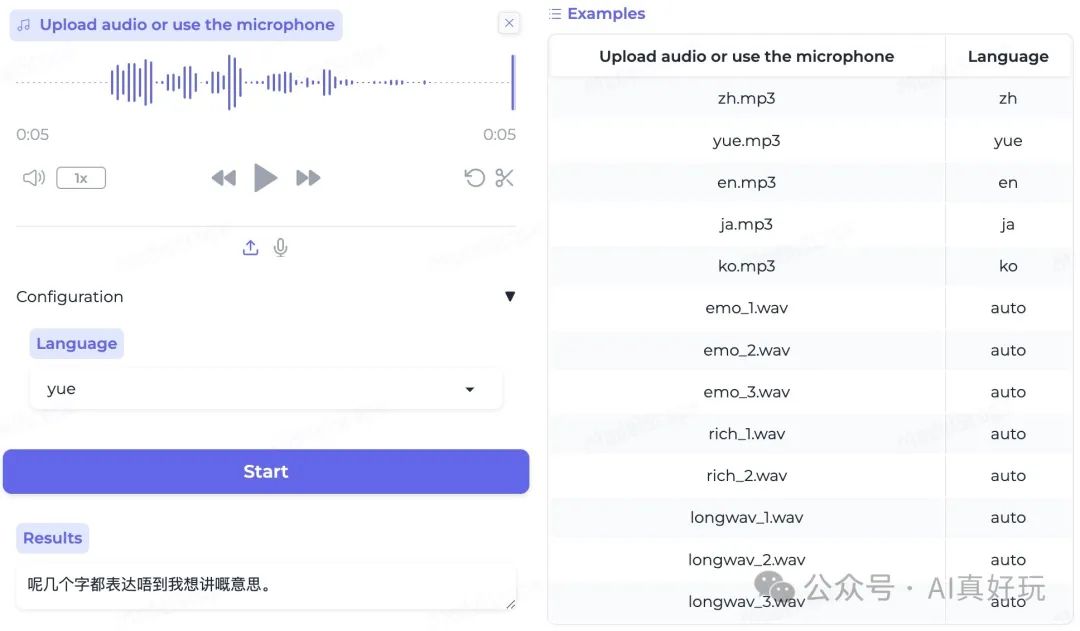
粤语识别
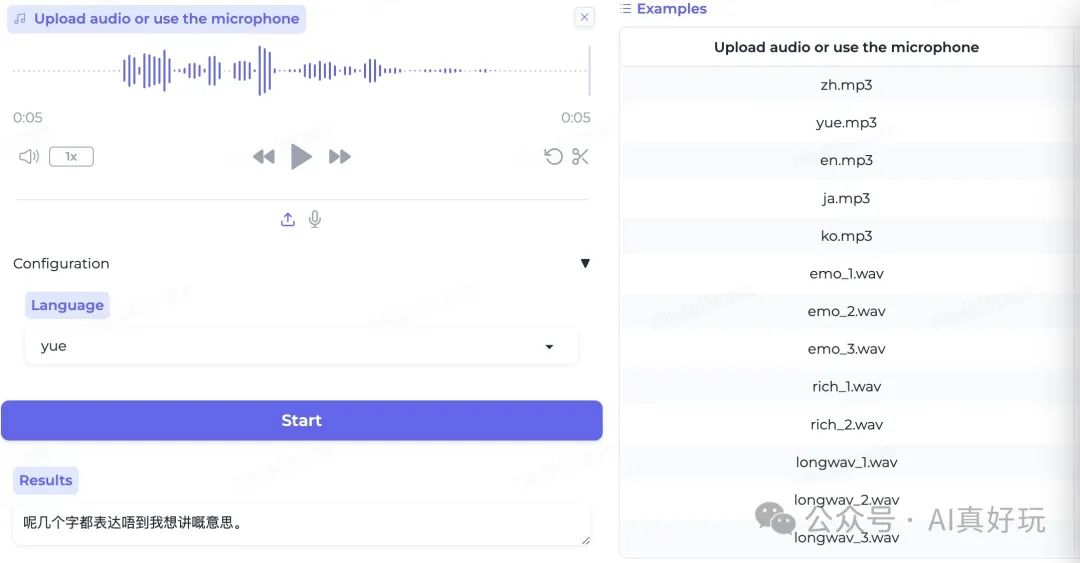
英语识别
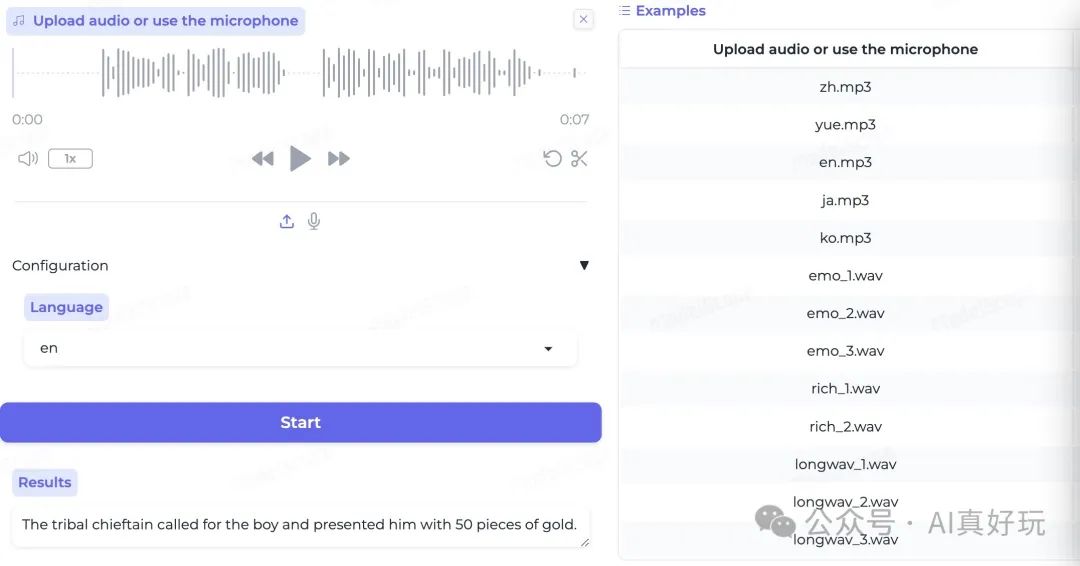
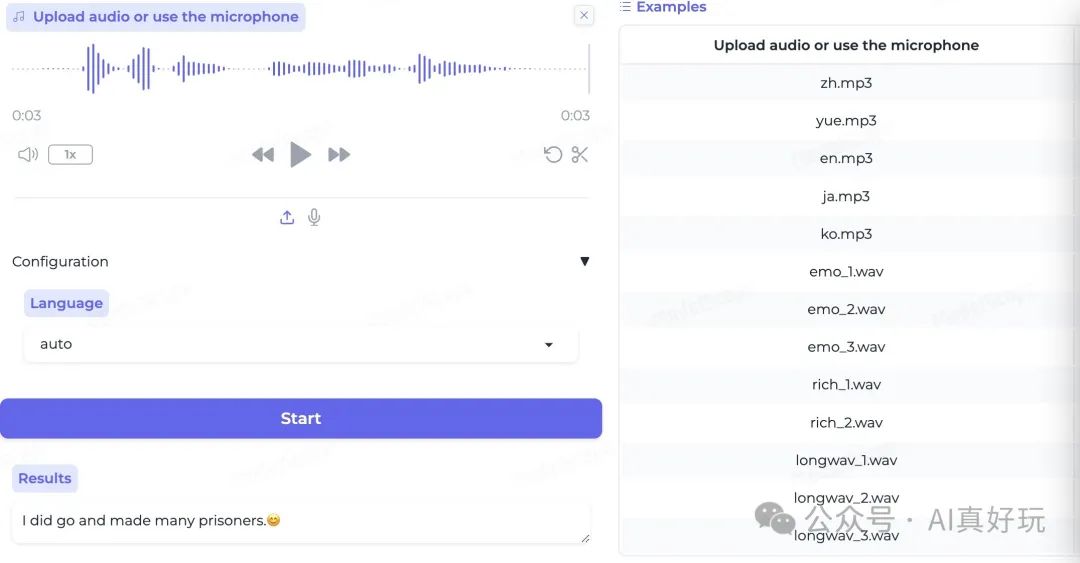
语音情感识别
能够识别音频中的情感,比如,积极和消极等。
声学事件检测
能够识别音频文件中的掌声(
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

