
- 1递归算法大全_常见递归算法
- 2c++-封装案例-设计学生类
- 3今日招生通知+9!中科大网安+中科院*2+国科大*3+…夏令营招生通知发布!_中国科学院信息工程研究所2024年“网络空间安全技术”全国优秀大学生夏令营
- 4【docker】 单机模式安装nacos 2.x_docker nacos2
- 5Failure [INSTALL_FAILED_NO_MATCHING_ABIS: Failed to extract native libraries, res=-113]
- 6被GPT带飞的In-Context Learning发展现状如何?这篇综述梳理明白了
- 7测试——Selenium
- 8Spring源码分析-Bean生命周期循环依赖和三级缓存_spring三级缓存与bean生命周期
- 9LLMs之AutoKG:《大型语言模型在知识图谱构建和推理中的应用:近期能力与未来机遇LLMs for Knowledge Graph Construction and Reasoning: Rece_本文全面定量与定性评估了大型语言模型(llms)在知识图谱(kg)构建和推理方面的应用
- 10Alibaba Druid数据库连接池直接起飞
万字长文总结多模态大模型最新进展(Modality Bridging篇)
赞
踩

本文大约17000字,建议阅读20分钟本文介绍了多模态大规模的最新进展。多模态大型语言模型(MLLM)最近已成为一个新兴的研究热点,它将强大的大型语言模型(LLMs)作为大脑来执行多模态任务。MLLM 的惊人新能力,如基于图像撰写故事和无 OCR 的数学推理,在传统方法中很少见,这表明了通向通用人工智能的潜在路径。
通常人们会在 pair 数据上进行大规模(相对于 instruction tuning)的预训练,以促进不同模态之间的对齐。对齐数据集通常是图像文本对或自动语音识别(ASR)数据集,它们都包含文本。
更具体地说,图像文本对以自然语言句子的形式描述图像,而 ASR 数据集包含语音的转录。对齐预训练的常见方法是保持预训练模块(例如视觉编码器和 LLMs)冻结,并训练一个可学习的接口,本文调研了到近期位置不同的接口设计以及学习方法相关的文章。
01 Flamingo
论文标题:
Flamingo: a Visual Language Model for Few-Shot Learning
论文链接:
https://arxiv.org/abs/2204.14198
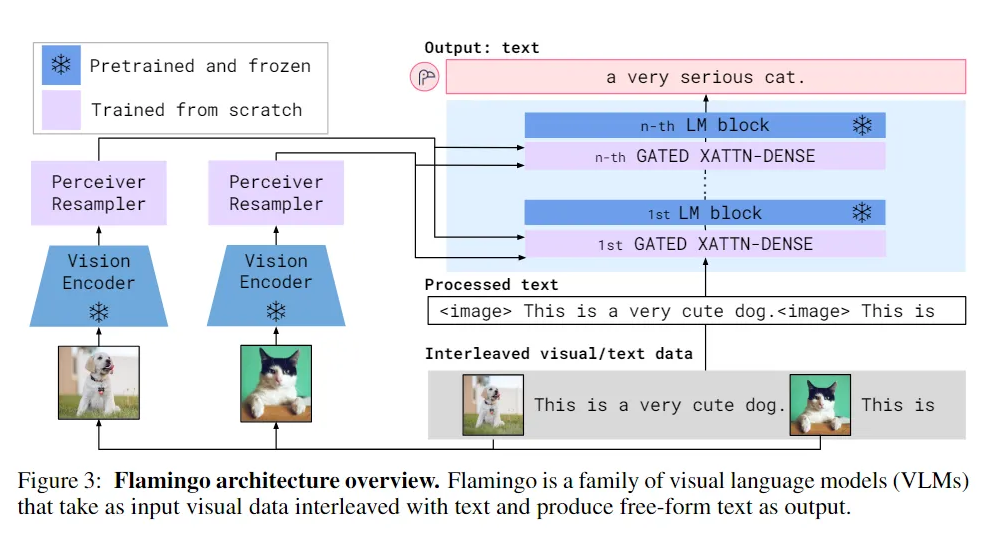
总的来说,首先,Perceiver Resampler 接收来自视觉编码器的时空特征(从图像或视频获取),并输出固定数量的视觉标记。其次,这些视觉标记用于通过新初始化的交叉注意力层对冻结的语言模型进行条件化,这些层被插入到预训练的语言模型层之间。这些新层为语言模型提供了一种表达方式,以便将视觉信息纳入到下一个标记预测任务中
1.1 Visual processing and the Perceiver Resampler
视觉编码器:是一个预训练并冻结的 Normalizer-Free ResNet(NFNet),使用 Radford 等人提出的 two-term contrastive loss,在图像和文本对数据集上对视觉编码器进行对比目标的预训练。使用最终阶段的输出,即一个二维空间网格的特征,将其压平为一个一维序列。
对于视频输入,帧以 1 FPS 进行采样并独立编码,以获得一个三维时空特征网格,然后将学习到的时间嵌入添加到其中。特征然后被压平为一维,然后输入到 Perceiver Resampler 中。
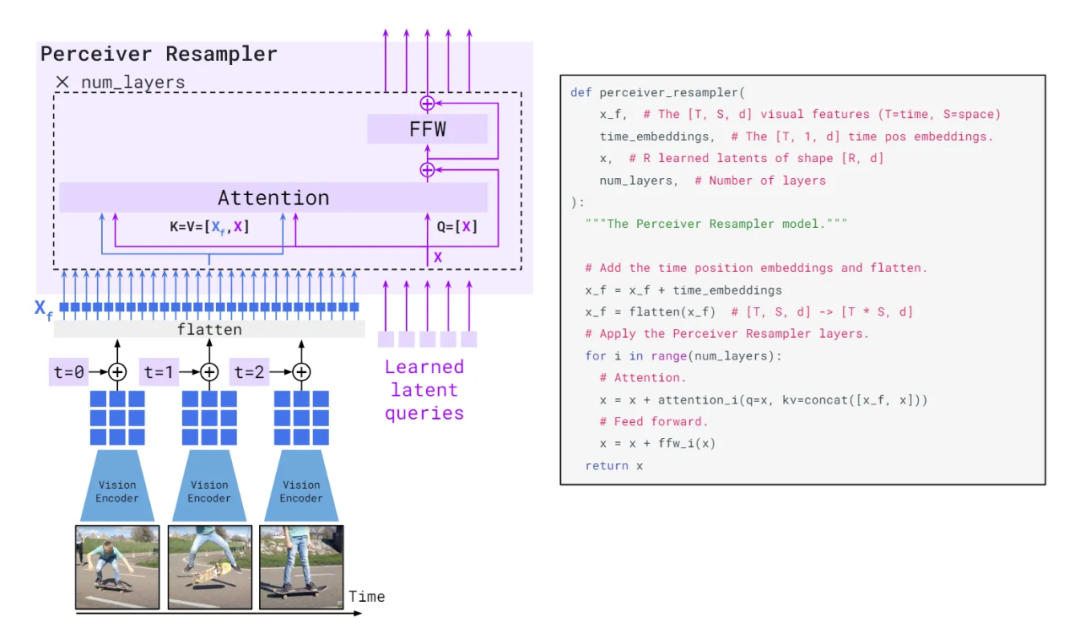
Perceiver Resampler 模块将由 Vision Encoder 输出的可变大小的时空视觉特征网格映射到固定数量的输出标记(图中为五个),与输入图像分辨率或输入视频帧数无关。这个 transformer 具有一组学习到的潜在向量作为查询,而键和值则是由时空视觉特征与学习到的潜在向量的连接组成。
Perceiver Resampler:从不同大小的大型特征图到少量视觉标记。这个模块将视觉编码器连接到冻结的语言模型,如上图所示。它以视觉编码器中的图像或视频特征的可变数量作为输入,并产生固定数量的视觉输出(64 个),从而降低了视觉-文本交叉注意力的计算复杂度。
类似于 Perceiver 和 DETR,本文学习了预定义数量的潜在输入查询,这些查询被输入到一个 Transformer 中,并对视觉特征进行交叉关注。消融研究中展示了使用这样一个视觉-语言重采样模块优于一个普通的 Transformer 和一个 MLP。
1.2 GATED XATTN-DENSE details
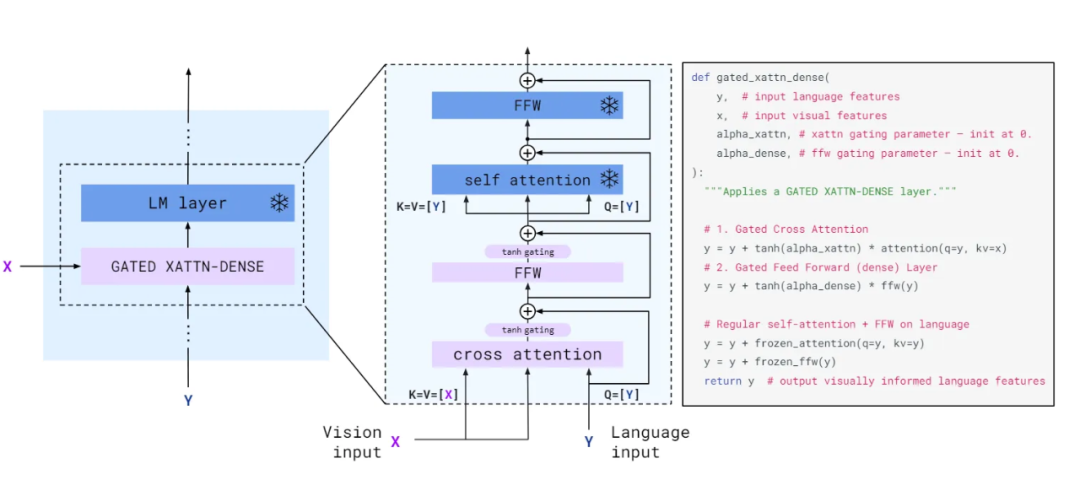
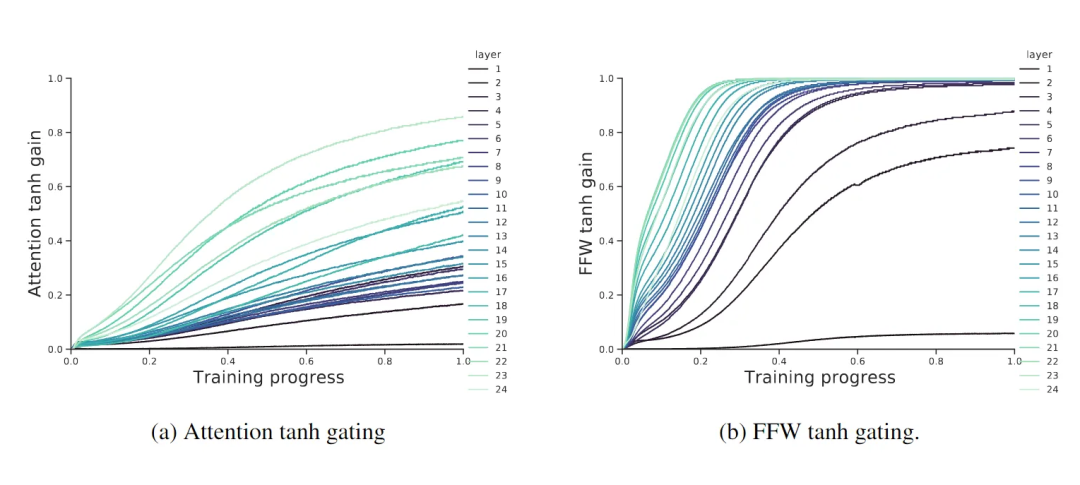
上图提供了一个 GATED XATTN-DENSE 块的示意图,以及它与一个冻结的 LM 块的连接方式,同时附上了伪代码。下图绘制了 Flamingo-3B 模型的 24 个 LM 层在训练过程中(从 0% 到 100%)不同层中 tanh 门控值的绝对值的演变。冻结的 LM 堆栈的所有层似乎都利用了视觉信息,因为 tanh 门控的绝对值从其 0 初始化中迅速增长。
我们还注意到,绝对值似乎随着深度增加而增加。然而,从这个观察中很难得出强有力的结论:门控之前的激活的规模也可能随着深度变化。未来的工作需要更好地理解这些添加层对优化动态和模型本身的影响。
1.3 Multi-visual input support
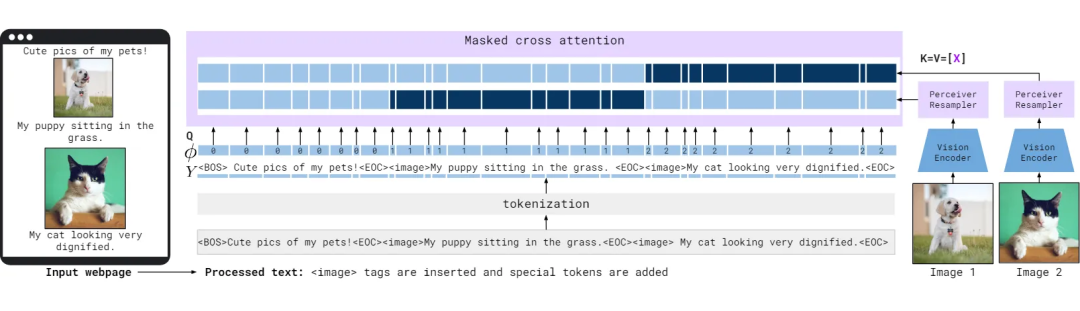
首先通过在文本中的视觉数据位置插入 image 标签以及特殊标记 BOS 表示“序列开始”或 EOC 表示“块结束”)来处理文本。图像由 Vision Encoder 和 Perceiver Resampler 独立处理,以提取视觉标记。在给定的文本标记处,模型仅与最后一个前导图像/视频对应的视觉标记进行交叉关注。声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

